At the MySQL Summit Day in Redwood Shores, California, we’re announcing new MySQL HeatWave AutoML capabilities, expanding the machine learning use cases for MySQL HeatWave, as well as new capabilities for MySQL HeatWave on AWS, and price-performance improvements for MySQL HeatWave on OCI.
New MySQL HeatWave AutoML capabilities
MySQL HeatWave provides native, in-database machine learning. Customers don’t need to move data to a separate machine learning service, they can easily and securely apply machine learning training, inference, and explanation to data stored inside MySQL HeatWave. HeatWave AutoML automates the machine learning lifecycle. Benchmarks demonstrate that, on average, HeatWave AutoML produces more accurate results than Amazon Redshift ML, trains models 25X faster, and scales as more nodes are added. It is available at no additional cost to MySQL HeatWave customers.
So far, customers could automatically train regression, classification, and univariate time series forecasting models. We are now announcing the extension of MySQL HeatWave AutoML’s lifecycle automation to support for multi-variate time series forecasting, unsupervised anomaly detection, and recommender systems. These capabilities are not offered by other competitive cloud database services like Redshift and Snowflake. The machine learning capabilities are now available via an interactive console that makes it easier for business analysts to build, train, run, and explain ML models without help from IT.
Multi-variate time series forecasting
Time series forecasting is a technique for predicting future values of key metrics based on past events. It involves using time-ordered events from the past as well as other variables to predict future values. Multivariate time series forecasting can predict multiple time-ordered variables, where each variable depends both on its past value and the past values of other dependent variables. For example, it is used to build forecasting models to predict electricity demand in the winter considering the various sources of energy used to generate electricity.
While analyzing time series, it is important to exploit temporal dependency and internal structure comprising elements such as seasonality, trends, and residuals. There are many time series forecasting algorithms available, each best suited to different characteristics. The choice of the optimal algorithm typically requires a statistician trained in time-series analysis. Given the complexity involved, an automated approach for time series forecasting is highly desirable, and this is precisely what MySQL HeatWave now delivers. MySQL HeatWave AutoML will automatically pre-process the data to select the best algorithm for the ML model and automatically tune the model.
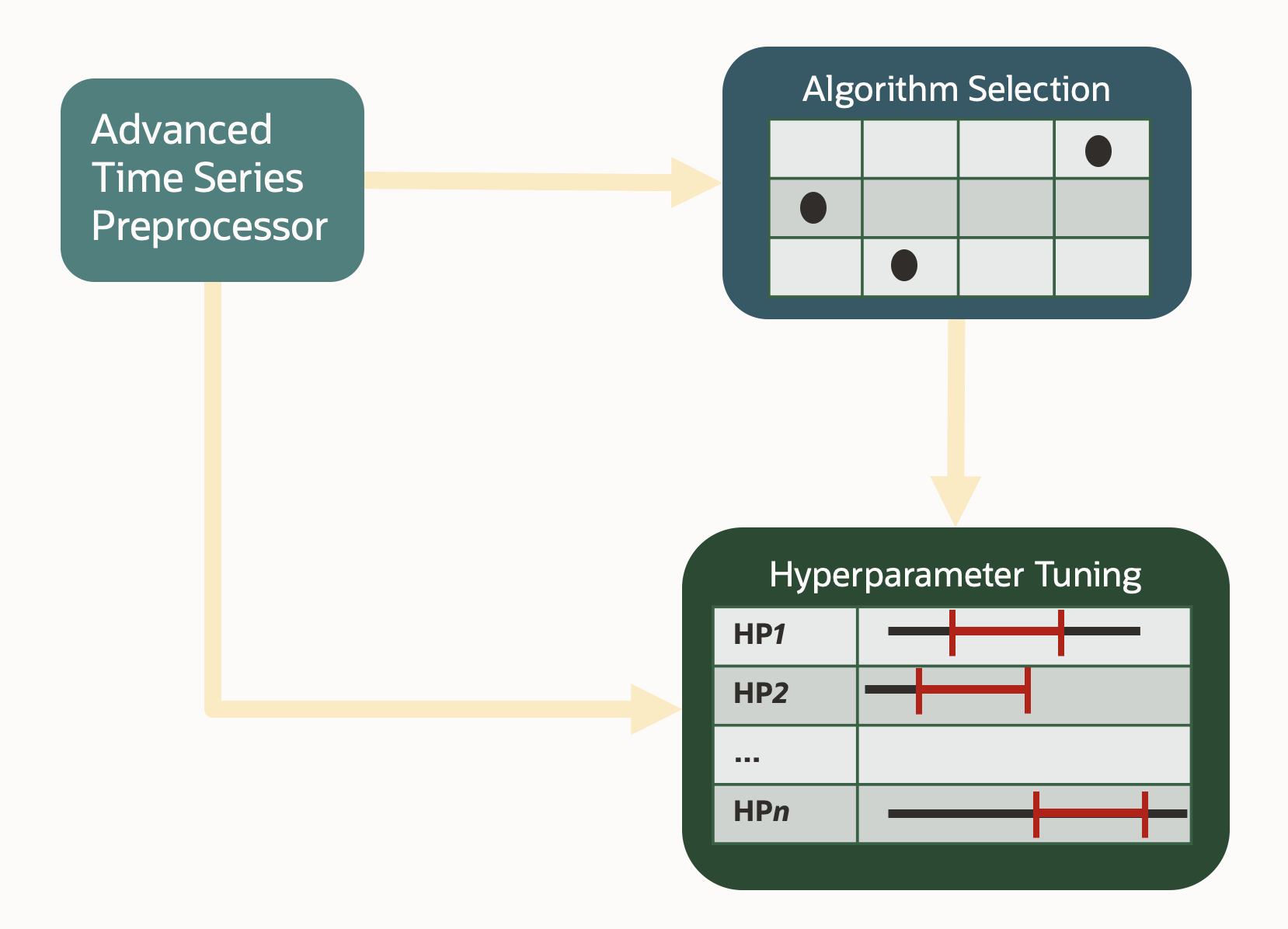
The HeatWave AutoML automated forecasting pipeline uses a patented technique that consists of stages including advanced time-series preprocessing, algorithm selection and hyper parameter tuning. The advanced time-series stage estimates the basic time-series characteristics (seasonality, trend, etc…) and these estimates are then used during the algorithm selection and hyperparameter tuning stages. The algorithm selection stage determines the best algorithm for a given time-series dataset from the set of supported algorithms. The hyperparameter tuning stage tunes the hyperparameters for the algorithm in a range suggested by the preprocessor. Thanks to this automation, customers save significant time and effort, and they don’t need to have highly trained statisticians on staff.
Unsupervised anomaly detection
Anomaly detection is the data mining task of finding unusual patterns in data. It is used in a wide variety of fields including fraud detection in finance, network intrusion detection in cyber-security, and detecting of life-threatening medical conditions
Multiple distance-based machine learning algorithms, using nearest-neighbor distances to detect anomalies, can be adopted. However, these algorithms are often designed to detect specific anomaly types, so choosing an algorithm can be problematic if the user does not know which anomaly types are in the dataset.
In MySQL HeatWave, we have implemented a novel unsupervised parsimonious ensemble algorithm that can detect different types of anomalies from unlabeled data sets without requiring any randomization. This algorithm provides high performance on the Unsupervised Anomaly Detection Benchmark (UADB) datasets, out-performing some of the most widely utilized algorithms such as k-th Nearest Neighbor (kNN) and Local Outlier Factor (LOF).
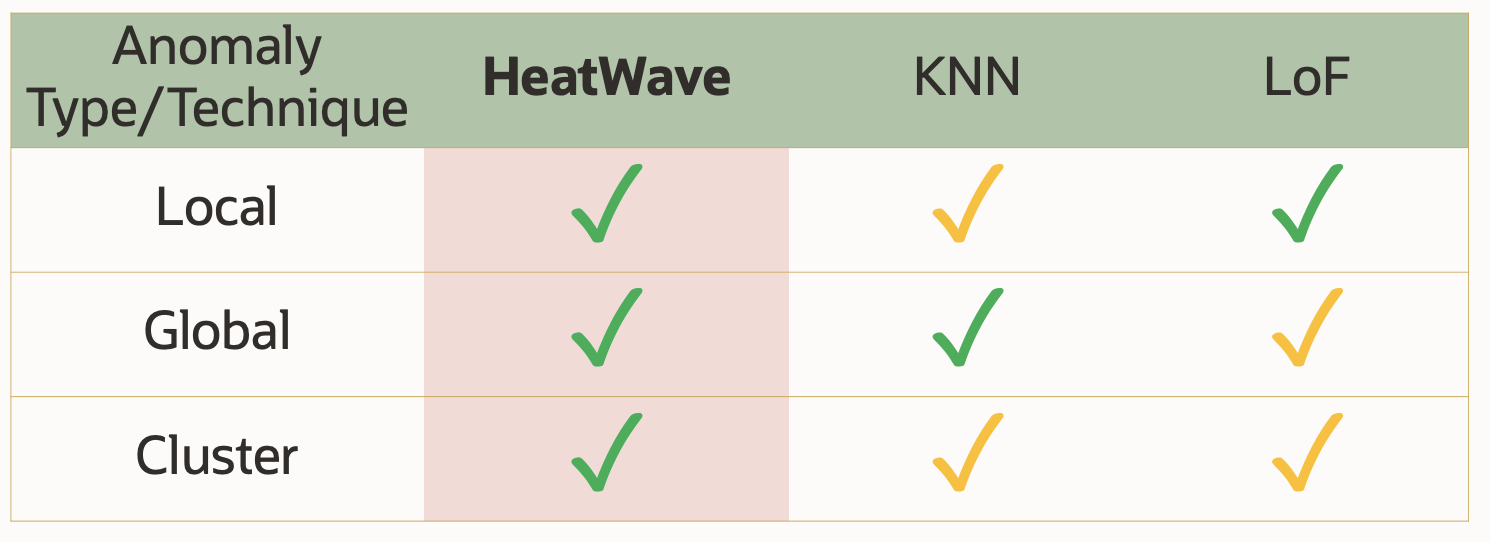
The model generated by HeatWave AutoML provides high accuracy for all types of anomalies: local, cluster, and global. The process is completely automated, eliminating the need for data analysts to manually determine which algorithm to use, which features to select, and the optimal values of the hyperparameters to identify those 3 types of anomalies from unlabeled data sets.
Recommender systems
Recommender systems provide personalized recommendations based on users’ search activities and prior activities. For example, within the context of an online shop, to predict the top items that a user will like, the rating a user will give an item, and the top number of users that will like a specific item being sold. Movie recommendations based on users’ viewing history is another common example.
MySQL HeatWave now supports recommender systems and fully automates the process for customers, including algorithm selection, feature selection, and hyperparameter optimization — saving data analysts significant time and effort. By comparison, other cloud services only recommend algorithms, putting the burden on users to select the most appropriate one, and manually tune it
With MySQL HeatWave, users can invoke the ML_TRAIN procedure, which automatically trains the model that is then stored in the MODEL_CATALOG. To predict a recommendation, users can invoke ML_PREDICT_ROW or ML_PREDICT_TABLE
New Interactive MySQL HeatWave AutoML console
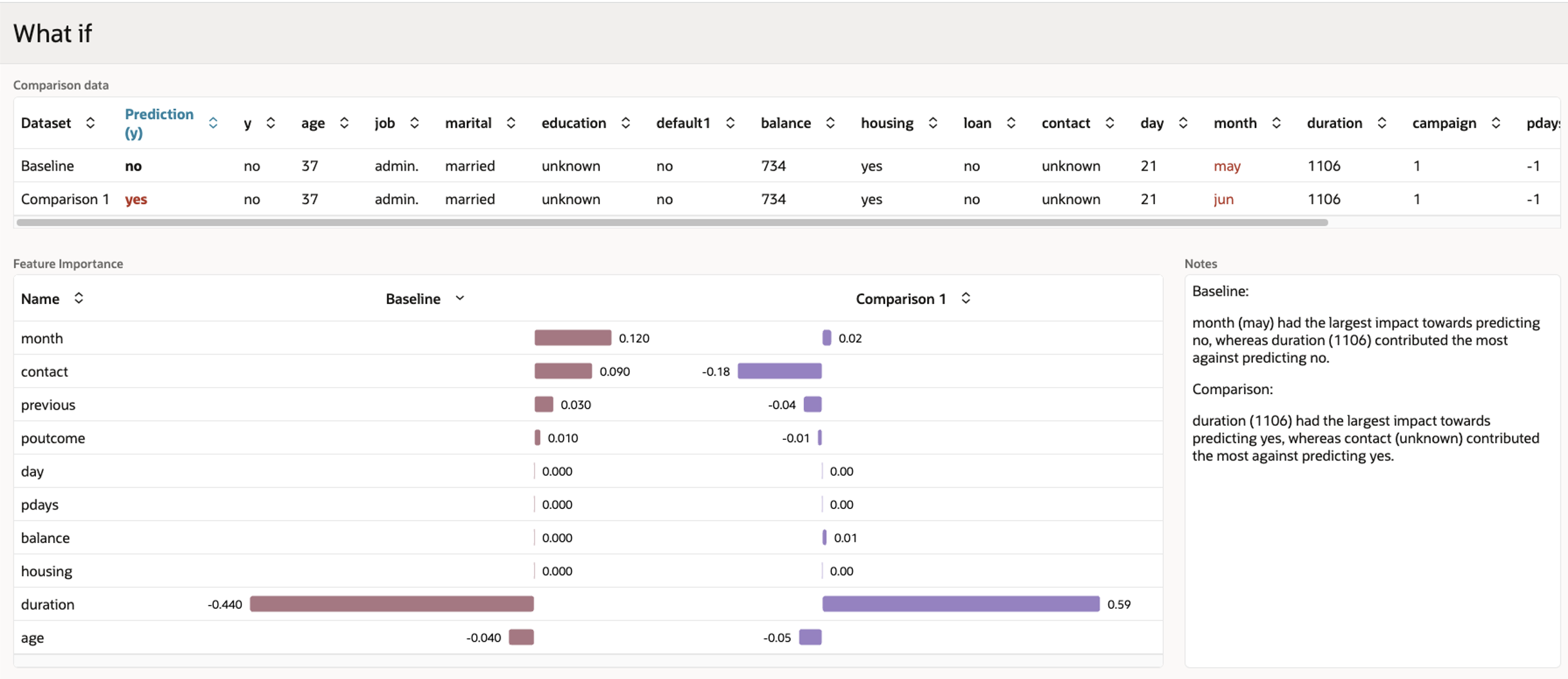
The new interactive console lets business analysts build, train, run, and explain ML models using the visual interface — without using SQL commands or any coding. The console also makes it easy to explore what-if scenarios to evaluate business assumptions — for example, “How would investing 30% more in paid social media advertising affect both revenue and profit?” The console is initially available for MySQL HeatWave on AWS.
New capabilities for multi cloud
MySQL HeatWave on AWS
MySQL HeatWave runs natively on AWS, enabling customers to access the database with very low latency and avoid exorbitant AWS data egress fees for applications deployed on AWS. We are making several enhancements to the MySQL HeatWave service on AWS.
Scale Out Data Management
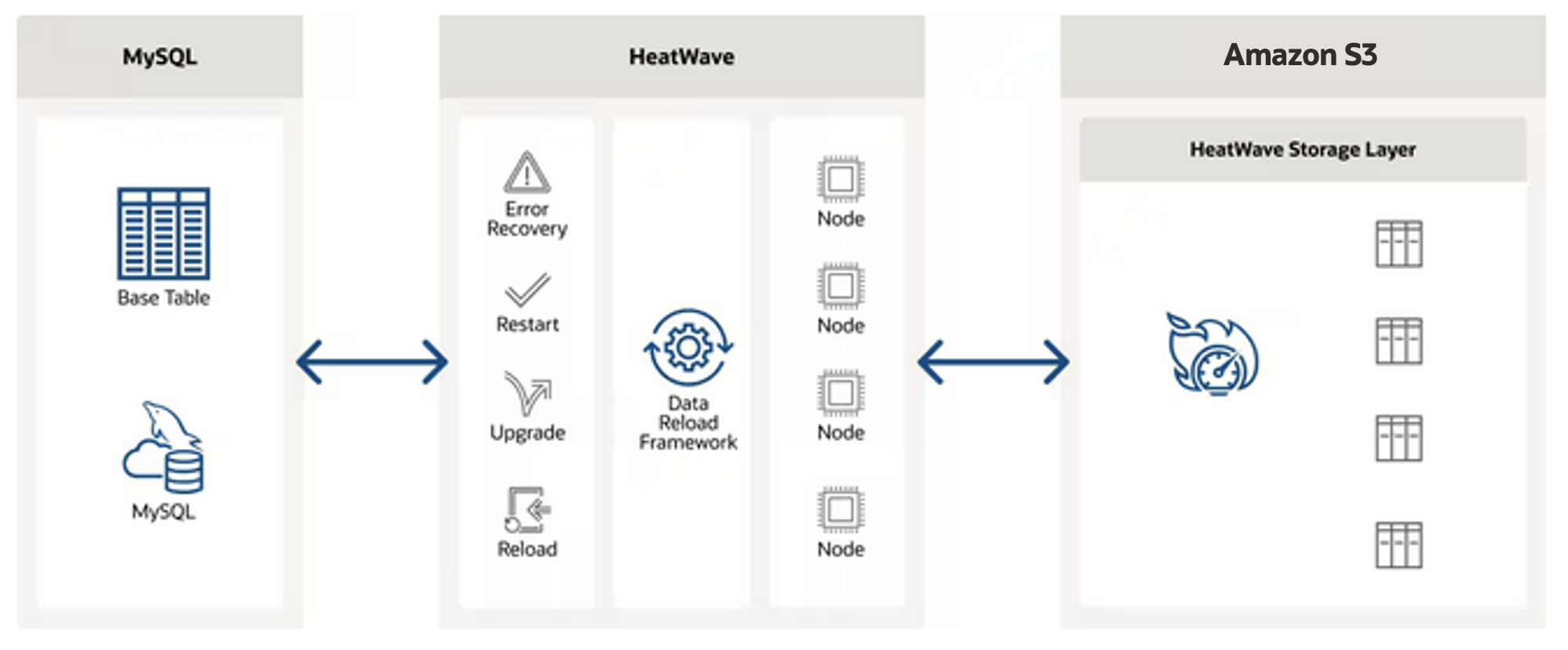
MySQL HeatWave on AWS now provides an optimized storage layer built on Amazon S3 to store HeatWave hybrid columnar representation. When data is loaded from MySQL (InnoDB storage engine) into HeatWave, a copy is made to the scale-out data management layer built on S3. When an operation requires reloading of data to HeatWave, such as during error recovery, data can be accessed in parallel by multiple HeatWave nodes and the data can be directly loaded into HeatWave without the need for any transformation. This results in a significantly faster recovery and improves the availability of the service. For example, for a 4TB HeatWave cluster, the time it takes to recover and reload data from S3 vs. reloading from MySQL improves from 140 minutes to 3.5 minutes — without impacting OLTP performance>
Support for MySQL Autopilot Auto-shape prediction in the console
MySQL Autopilot provides workload-aware, machine learning-powered automation of various aspects of the application lifecycle, including provisioning, data loading, query execution, and failure handling. It also provides capabilities designed for OLTP workloads.
Within the interactive console, database users can now access the MySQL Autopilot Auto shape prediction advisor that continuously monitors the OLTP workload to recommend with an explanation the right compute shape at any given time — allowing customers to always get the best price-performance. The visual representation within the console makes it easy for database users to upsize or downsize their database shape. Recommendations are supported by visual analyses of historic performance trends, including throughput and buffer pool hit rate.
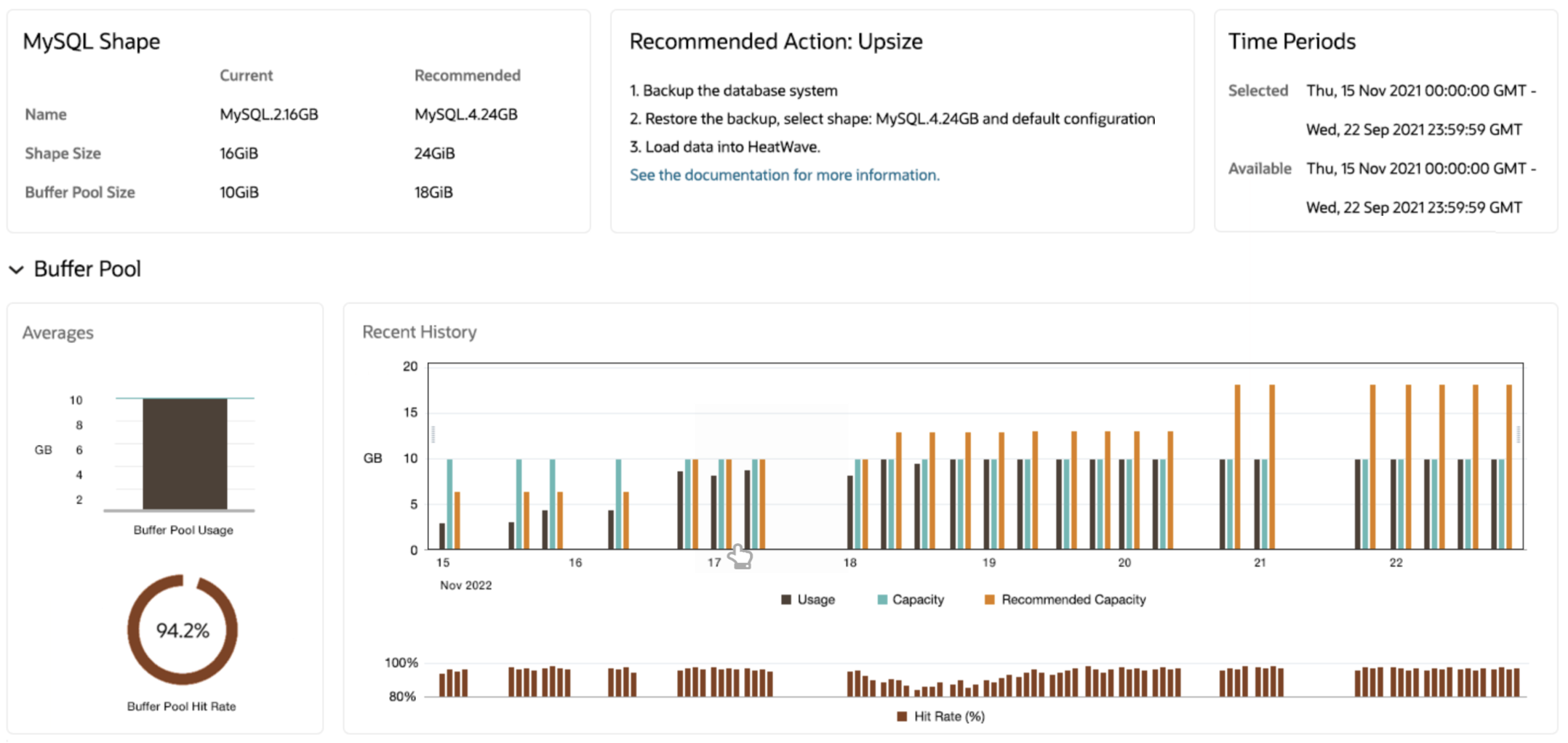
Pre-defined MySQL HeatWave configurations
MySQL HeatWave on AWS provides a set of pre-defined and optimized MySQL configurations based on the MySQL shape and workload. MySQL HeatWave on AWS supports OLTP only workloads and OLAP/mixed workloads.
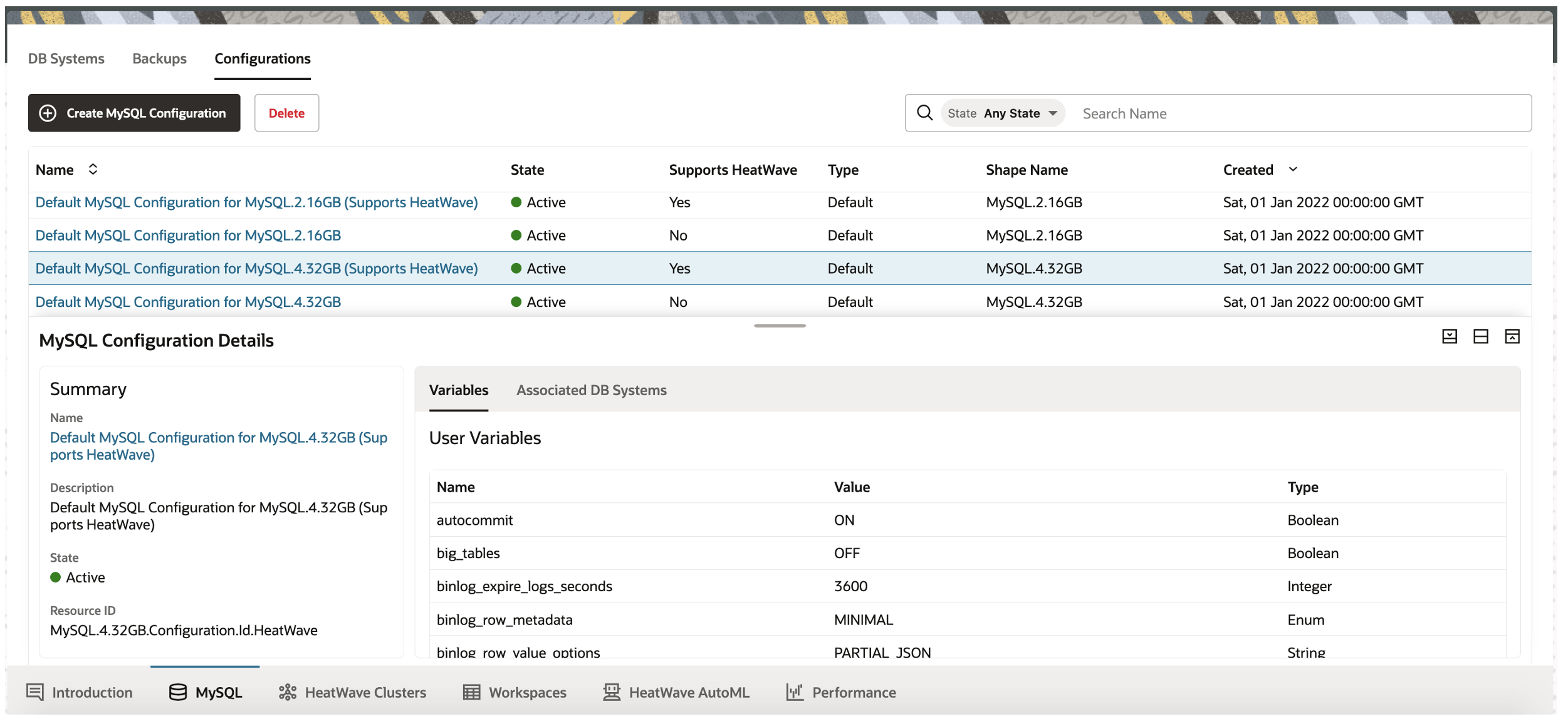
Users can also create custom configurations for new systems
MySQL HeatWave on OCI
Introducing a new small shape for HeatWave
Until now, the size of a HeatWave node was 512GB. Many customers with smaller data sizes expressed the desire to use HeatWave without provisioning such a large node. We now introduce a new small 32GB shape. It can process up to 50GB of data and only costs $16 per month.
Improved price performance
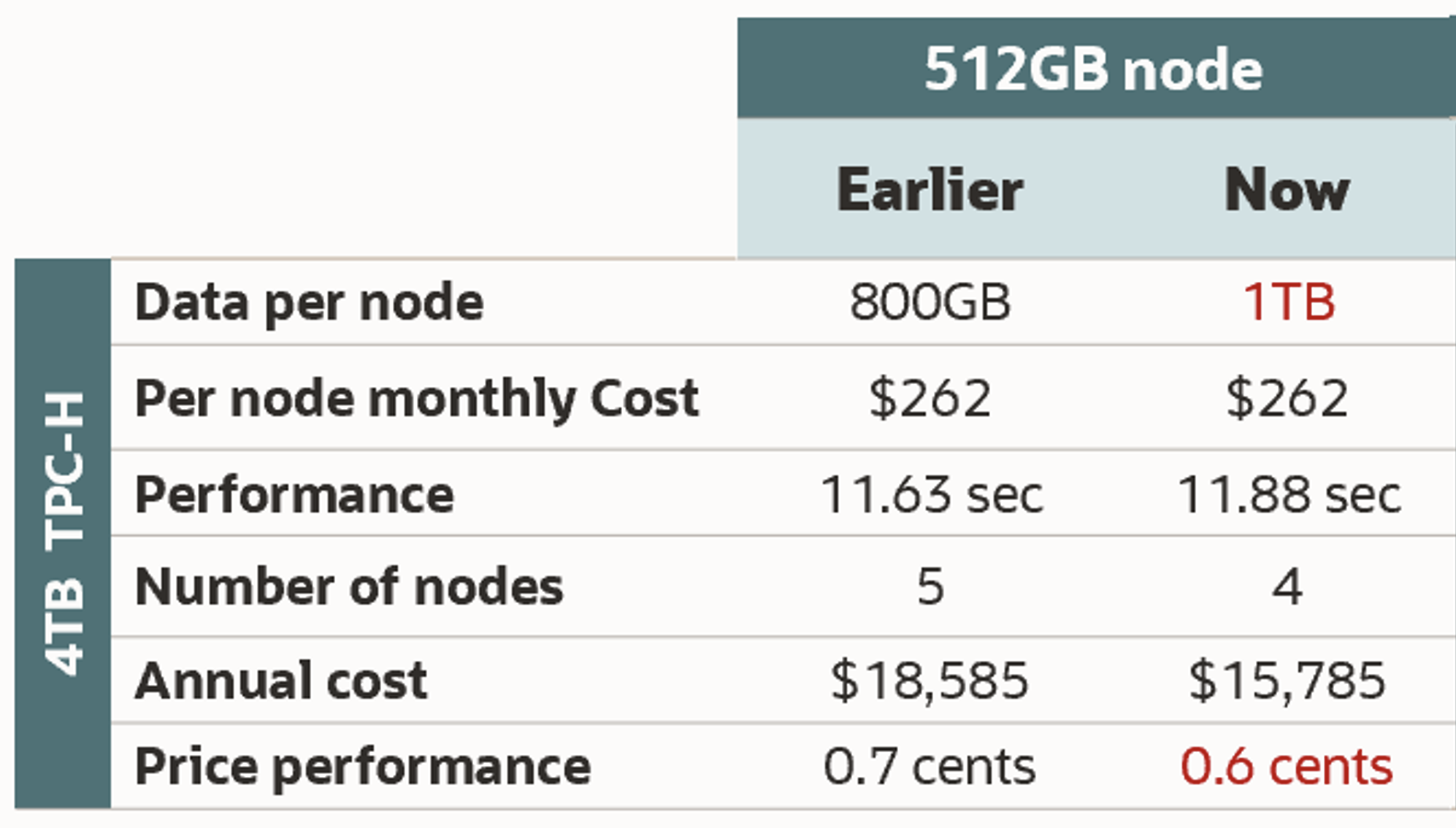
The amount of data that can be processed by a HeatWave node (512GB) is now increased to 1TB from 800GB (note that the exact amount of data processed depends upon the data and workload characteristics). With this increase and other query performance improvements, the price performance benefit of HeatWave has further increased by 15%.
Oracle introduces the MySQL Autopilot auto unload feature. With this capability, users can determine which tables in memory have not been used recently based on system recommendations and are candidates for being purged. Freeing up memory reduces the size of the cluster required to run a workload and saves cost.
For more information about MySQL HeatWave or details about these new capabilities, please refer to our technical briefs on oracle.com/mysql.
