HeatWave is the only fully managed MySQL database service that combines transactions, analytics, machine learning, and GenAI services, without ETL duplication. HeatWave also includes HeatWave Lakehouse, allowing users to query data stored in object storage, MySQL databases, or a combination of both. Users can deploy HeatWave MySQL–powered apps on a choice of public clouds: Oracle Cloud Infrastructure (OCI), Amazon Web Services (AWS), and Microsoft Azure.
Companies ranging from e-commerce platforms, media outlets, financial services, and tech firms, use Google Analytics to gain insights into their audience, optimize marketing strategies, and enhance user experience, enabling data-driven decisions that improve online presence and drive growth.
While Google Analytics offers valuable insights, there are some challenges in using the tool. Users often face limitations in customizing reports and tracking specific user behaviour without advanced configuration. This includes setting up complex tracking codes, handling large datasets, and ensuring data accuracy when dealing with multiple sources or platforms. Interpreting data can be difficult without a strong understanding of analytics, and privacy concerns, such as GDPR compliance, which require careful attention.
For handling large datasets, running complex queries, and performing detailed analysis that go beyond the standard reports provided by Google Analytics, people often interface Google Analytics with a data warehouse solution. Data warehouse allows users to write custom SQL queries for in-depth analysis, enabling more flexibility and precision than basic reporting options in Google Analytics. Data warehouse also allows you to combine Google Analytics data with data from other sources, providing a holistic view of performance.
HeatWave is an ideal choice for a data warehouse focused on analytics, especially when speed, heavy analytics query processing, cost-efficiency, and scalability are top priorities. BigQuery, typically used alongside Google Analytics for handling large datasets, can become expensive and slow when managing complex queries, especially as data volume and user concurrency increase. Ad hoc queries in BigQuery may lead to unpredictable costs, particularly if they are not optimized or if users aren’t aware of the data being processed.
This blog provides a guide on how to seamlessly transfer data from Google Analytics to HeatWave, a high-performance data warehouse designed for analytics. It walks through the necessary steps to connect both platforms, explaining how to extract, transform, and load your Google Analytics data into HeatWave for optimized processing and analysis.
How its Done: Overview
To export Google Analytics data, BigQuery is required as an intermediary to transfer the data to external systems. Without BigQuery, users are restricted to predefined reports and data sampling within Google Analytics. This is because the Google Analytics 360 BigQuery Export connector is available exclusively for Google Analytics 360 users, enabling the export of raw, detailed event data into BigQuery. From there, the data can be directed to HeatWave, which serves as a data warehouse. Once in HeatWave, business intelligence tools or custom applications can access the data, allowing for seamless integration and deeper insights. In this setup, data exists in both GCP and HeatWave, offloading reporting and analytics to HeatWave for improved performance and scalability.
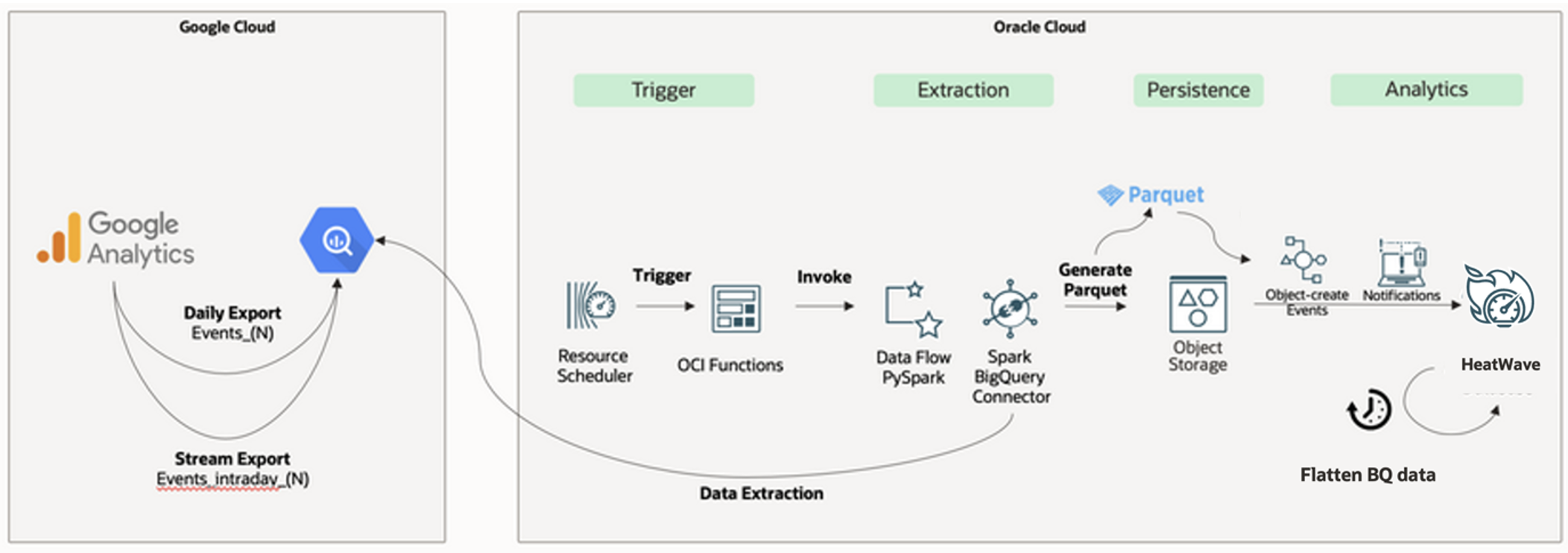
The architecture diagram illustrates serverless data replication from Google Analytics and BigQuery to HeatWave using OCI Data Flow and Lakehouse:
- A PySpark job, powered by the Spark BigQuery Connector, runs through Data Flow to extract data from BigQuery and store it as a Parquet file in Object Storage, optimizing cost efficiency by terminating resources post-completion.
- HeatWave Lakehouse reads the Parquet file from Object Storage as a table for analytical queries, processing data in HeatWave’s in-memory node.
The HeatWave Lakehouse table functions like an InnoDB table, allowing SQL queries to join data from various sources, positioning HeatWave as a central data repository.
Let’s get started!
Obtain the GCP Service Account credential and Check Source Table in BigQuery
First, create a service account in GCP and assign it the BigQuery Data Viewer and BigQuery Read Session User roles. These permissions are necessary for the OCI Data Flow job to retrieve data.
Next, obtain the service account key in JSON format. This key will later be included in the dependencies archive zip file, as explained in the following step.
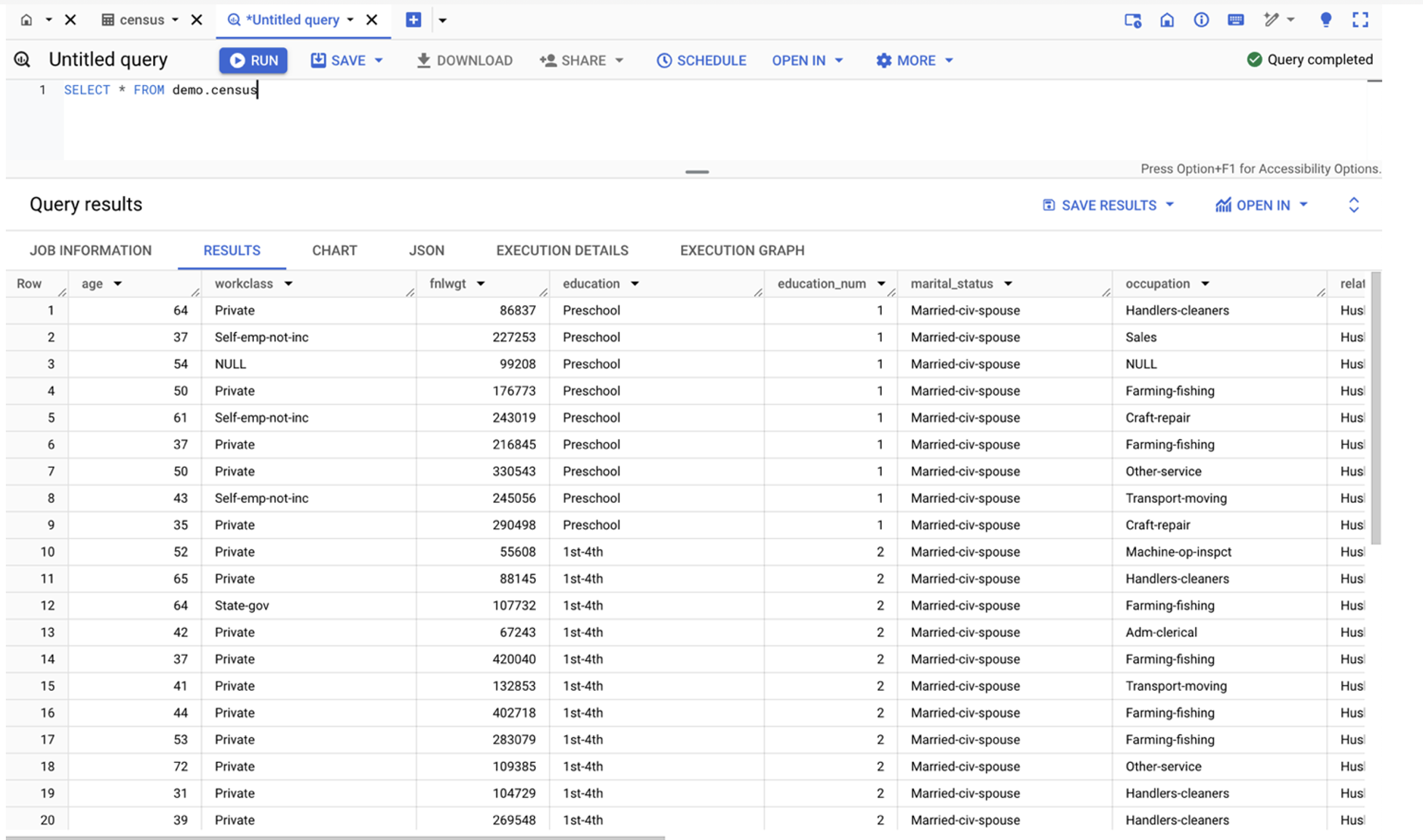
Here is an example of our BigQuery table (table name: demo.census).
Let’s migrate this sample table to HeatWave using OCI Data Flow.
Prepare the OCI Data Flow Dependencies
To run a Spark program in Data Flow, a Dependency Archive (archive.zip) is required to package third-party dependencies, which must be installed on all Spark nodes. Data Flow offers a Docker-based tool to create the archive, which should be stored in Object Storage.
Cloud Shell is ideal for preparing the archive.zip with pre-installed tools. For instructions, visit: https://docs.oracle.com/en-us/iaas/data-flow/using/third-party-provide-archive.htm#third-party-provide-archive.
In Cloud Shell, create a directory called dataflow_archive_dependencies, download the spark-bigquery-connector jar, and create a requirements.txt file as needed.
mkdir dataflow_archive_dependencies
cd dataflow_archive_dependencies
wget https://storage.googleapis.com/spark-lib/bigquery/spark-3.5-bigquery-0.42.0.jar
echo oci > requirements.txt
Cloud Shell defaults to “no preferences,” selecting either x86_64 or ARM architecture based on regional hardware. To confirm it’s running on x86, click “Action” > “Architecture” and choose “x86_64.” Then, run the following command to create the ZIP archive:
docker run --rm --user root -v $(pwd):/opt/dataflow -it phx.ocir.io/axmemlgtri2a/dataflow/dependency-packager-linux_x86_64:latest -p 3.11
After creating the archive.zip, add the service account key (JSON file) by unzipping it and placing the file in python/lib/<service_account>.json. Then, re-zip the folder as archive.zip. Finally, upload the archive.zip to Object Storage using the following command, replacing “bigquery” with the your object storage name and “yournamespace” with your OCI namespace.
oci os object put -bn bigquery --namespace yournamespace --name dependencies/bigquery/archive.zip --file archive.zip
Download the sample PySpark application from https://github.com/oliviadyz/bigquery-to-heatwave/blob/main/dataflow-spark-bq-connector/dataflow-ga4.py and upload it to Cloud Shell. Replace “bigquery” with your object storage name and “yournamespace” with your OCI namespace.
oci os object put -bn bigquery --namespace yournamespace --name dependencies/bigquery/dataflow-ga4.py --file dataflow-ga4.py
This sample PySpark application requires the following mandatory parameters as specified in its main code:
def main(date, credential, bucket, namespace, project, dataset, table)
This means the parameters must be provided as arguments when running with OCI Data Flow, as detailed in the next step. The PySpark job will generate a Parquet file to store the query results from the BigQuery table. The parquet file will be stored in object storage under the folder bigquery/dataset/parquet/date, as shown in our PySpark code below:
# Write to OCI Object Storage in Parquet format
destination = "oci://{0}@{1}/bigquery/dataset/parquet/{2}".format(bucket, namespace, date)
Create the OCI Data Flow Application
Open the Data Flow console by going to “Navigation Menu” > “Analytics & AI” > “Data Flow,” then click “Create Application” to create a new application with the parameters listed below, modifying them as needed.
| Parameter |
Value |
| Name |
Any name (e.g. “ |
| Language |
|
| Object Storage Name |
|
| Select a file |
|
| Argument |
|
| Archive URI |
|
| Application log location |
|
For detailed instructions on creating and running a PySpark application with Data Flow, visit https://docs.oracle.com/en-us/iaas/data-flow/using/dfs_create_pyspark_data_flow_app.htm#create_pyspark_app
Load into HeatWave Lakehouse
It’s good idea to use Resource Principal for HeatWave Lakehouse. Using a Resource Principal allows HeatWave to authenticate to the object storage bucket. For details on configuring tenancy for Resource Principal, visit: https://dev.mysql.com/doc/heatwave/en/mys-hw-lakehouse-resource-principal.html.
Afterward, connect to HeatWave with MySQL client and run Auto Load Schema Inference to create the demo.census table and load data. Schema Inference analyses the data, infers the table structure, and creates the database and tables automatically.
mysql > SET @dl_tables = '[{"db_name": "demo","tables": [{
"table_name": "census",
"dialect":
{
"format": "parquet"
},
"file": [{"region": "ap-singapore-1", "namespace": "<yournamespace>", "bucket": "bigquery","prefix": "bigquery/"}]}] }]';
mysql > SET @options = JSON_OBJECT('mode', 'normal', 'external_tables', CAST(@dl_tables AS JSON));
mysql > CALL sys.heatwave_load(@dl_tables, @options);
Starting with MySQL version 9.0.0, HeatWave supports Lakehouse Incremental Load, allowing you to refresh loaded data with new Parquet files using the following SQL:
mysql > SET SESSION rapid_lakehouse_refresh = TRUE;
mysql > ALTER TABLE /*+ AUTOPILOT_DISABLE_CHECK */ demo.census SECONDARY_LOAD;
mysql > SET SESSION rapid_lakehouse_refresh = FALSE;
And we’re done !
Let’s query demo.census from HeatWave using MySQL Workbench connected with SSH tunnel.
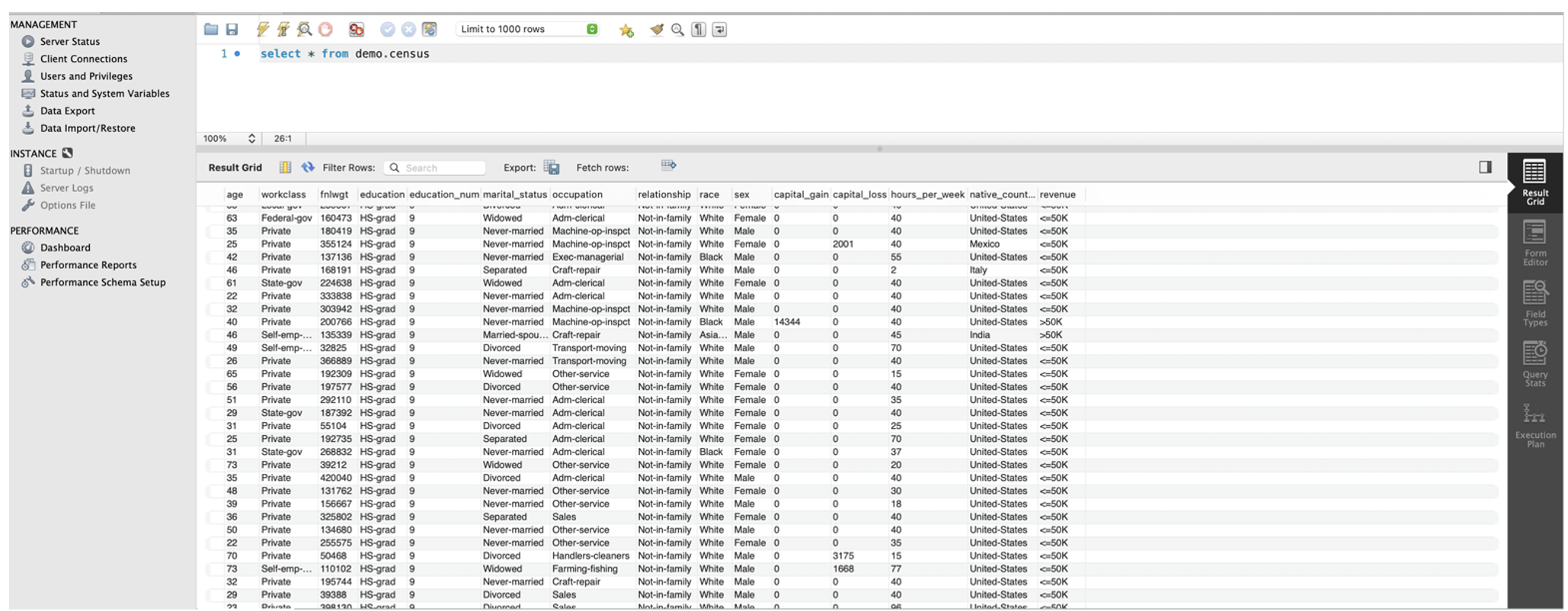
With the data in HeatWave, the user can now query and use all BI/Analytics tools to run analytics on the data.
Sign up for Oracle Cloud today and launch your free-tier HeatWave to unlock powerful analytics at no cost!
More info about the always free instance:
- Always free service
- Run small-scale applications on HeatWave at no cost
- Available features:
- Available now in all OCI accounts
- 1 ECPU, 16 GB Memory with HeatWave node
- MySQL storage 50 GB, Lakehouse storage: 10 GB
Conclusion
HeatWave offers flexibility, high query performance, and scalability for analysing large datasets, making it ideal for consolidating Google Analytics data with other sources. This integration provides businesses with comprehensive insights.
BigQuery is required to extract data from Google Analytics and Data Flow transfers it to HeatWave. With a better price-to-performance ratio, HeatWave is a more cost-effective and efficient choice than BigQuery, especially for businesses focused on speed and cost management.
Feel the burn of excitement – Try HeatWave today!
