MySQL HeatWaveは、トランザクション、分析、機械学習、生成AIサービスを組み合わせた唯一のフルマネージドのMySQLデータベース・サービスです。また、MySQL HeatWave Lakehouseも含まれており、ユーザーはオブジェクト・ストレージ、MySQLデータベース、またはその両方の組合せに格納されているデータを分析できます。ユーザーは、MySQL HeatWaveを利用したアプリケーションを、Oracle Cloud Infrastructure(OCI)、Amazon Web Services(AWS)およびMicrosoft Azureのいずれかのパブリック・クラウドにデプロイできます。
Agentic AIは生成AIを改善し、コンポーネントまたはソフトウェア・エージェントが独立して動作したり、他のコンポーネントと連動してタスクを達成できる自動システムの開発を可能にします。たとえば、ソフトウェア・エージェントは、ドキュメントを取得したり、独自のナレッジ・ベースから情報を収集することで、お客様情報を照会できます。このブログ投稿では、OCIの生成AIエージェント・サービスの使用時に、MySQL HeatWaveのベクトル・ストアをナレッジ・ベースとして使用する方法を示します。
OCIの生成AIエージェント(OCI AIエージェント・プラットフォームとも呼ばれる)は、大規模言語モデル(LLM)を使用してインテリジェントなAIエージェントを構築、デプロイおよび運用できる、フルマネージドなクラウドネイティブのサービスです。これらのエージェントは、コンテキストを維持し、データの取得と実行のためにRAGやSQLなどのツールと対話し、ガードレールとコンテンツ・モデレーションを適用し、オプションの「ヒューマン・イン・ザ・ループ」のワークフローを統合して、セキュアで拡張性のある実装を実現することで、リッチなマルチターンの会話エクスペリエンスを実現します。OCI AIエージェント・プラットフォームからMySQL HeatWaveのベクトル・ストアをナレッジ・ベースとして使用する方法の詳細をご覧ください。
前提条件
- MySQL HeatWaveのインスタンスでLakehouseが有効となっていること
- OCIのデータベース・ツールからHeatWaveのインスタンスにアクセスできること(こちらのステップ5を参照).
Getting Started
AIエージェントがナレッジベースとしてのHeatWaveを利用する手順は以下の通りです:
- AIエージェントを作成する
- ナレッジベースとしてのHeatWaveを作成する:
- MySQL HeatWave上でContext Retreval (コンテキスト検索)のためのプロシージャを作成する
- ナレッジベースを作成しMySQL HeatWaveのインスタンスに接続する
- AIエージェントのRAGツールが新しいナレッジベースを利用するように設定する
- ナレッジベースにデータを登録する
では、実際に各ステップの詳細を見ていきましょう。
ステップ 1: AIエージェントを作成する
新しいナレッジ・ベースを使用するエージェントがすでにある場合は、このステップをスキップできます。
OCIコンソールで、「アナリティクスとAI」に移動し、「生成AIエージェント」を選択します。
次に、「エージェントの作成」ボタンをクリックします。
エージェントの名前およびコンパートメントを選択します。
オプションで、摘要、ようこそメッセージまたはルーティング指示を入力します。「次へ」をクリックします。
次のページでは、「ツールの追加」をスキップします。このステップには後ほど戻ります。
ウィザードに従って、エージェントの作成を完了します。エージェント・エンドポイントも設定してください。

ステップ 2: AIエージェントのナレッジベースとしてのHeatWaveを作成する
ナレッジベースとしてのHeatWaveは、MySQL HeatWaveインスタンスのベクトル検索機能を利用します。最初に、MySQL HeatWaveインスタンスにコンテキスト検索用のストアド・プロシージャを作成する必要があります。このプロシージャは、コンテキストの取得時にAIエージェントが呼び出します。その後、ナレッジベースを作成して、MySQL HeatWaveインスタンスに接続し、コンテキスト検索のプロシージャを使用するように構成します。
ステップ 2.1: Context Retreval (コンテキスト検索)のためのプロシージャを作成する
コンテキスト検索のストアド・プロシージャは、問合せ文字列(p_query)および取得された多数のコンテキスト項目(top_k)を入力パラメータとして受け入れ、取得されたコンテキストを具体的にフォーマットされたJSON (コンテキスト)として返す必要があります。これは、AIエージェント・プラットフォームが期待するインタフェースです。検索プロシージャの目的は、1つ以上のベクトル表でベクトル検索を実行し、コンテキスト上で最も類似した結果を返すことです。同じベクトル空間の埋込みの比較を実行するために、ベクトル・ストアの作成に使用されるのと同じモデルを使用して問合せを埋め込む必要があります。検索プロシージャを実装する方法は複数ありますが、最も簡単なのは、インスタンス上の互換性のあるすべてのベクトル・ストア表を自動的に検出するsys.ML_RAGストアド・プロシージャに基づいています。埋込みモデルを明示的に指定しないため、デフォルトのモデルを使用します。
以下に、使用する実装を示します。ML_RAGにパラメータとしてskip_generate = trueを渡すことに注意してください。このパラメータにより、HeatWave GenAIはレスポンスの生成をスキップし、JSONとしてフォーマットされ、AIエージェントで想定されるSCORE、DOCID、BODYなどのフィールドを含むフェッチされたコンテキストのみが返されます。このプロシージャは、AIエージェントによって起動され、推論およびアクションが実行されます。お気に入りのMySQLクライアントを使用してMySQL HeatWaveインスタンスに接続し、次のコードを実行してコンテキスト検索ストアド・プロシージャを作成します。
CREATE DATABASE IF NOT EXISTS my_vector_store;
DROP PROCEDURE IF EXISTS my_vector_store.context_search;
-- Create the search procedure
DELIMITER $$
CREATE PROCEDURE my_vector_store.context_search( IN p_query TEXT, IN top_k INT UNSIGNED, OUT context JSON )
SQL SECURITY INVOKER
BEGIN
CALL sys.ML_RAG(p_query, @ml_rag_out, JSON_OBJECT('skip_generate', true, 'n_citations', top_k));
SELECT JSON_ARRAYAGG(
JSON_OBJECT('SCORE', JSON_EXTRACT(obj, '$.distance'), 'DOCID', JSON_EXTRACT(obj, '$. document_name'), 'BODY',
JSON_EXTRACT (obj, '$. segment') ) ) INTO context
FROM JSON_TABLE(@ml_rag_out, '$.citations [*]' COLUMNS (obj JSON PATH '$')) as jt;
END $$
DELIMITER ;
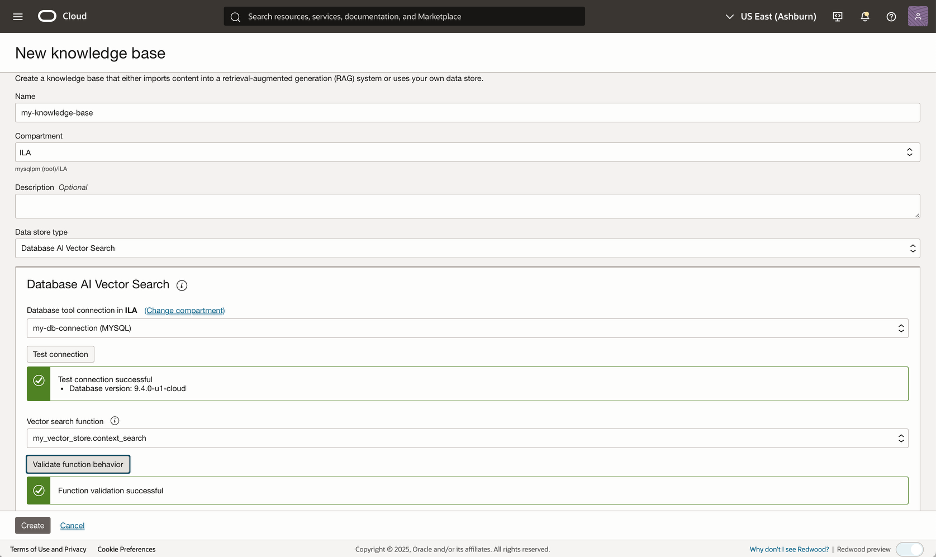
ステップ 2.2: ナレッジベースの作成
OCI Cloudコンソールで「生成AIエージェント」ページに移動し、「ナレッジ・ベース」リンクをクリックしてから、新しいナレッジベースを作成します。
データ・ストア・タイプとして、「Database AI Vector Search」を選択します。
次に、MySQL HeatWaveデータベース用に構成されたデータベース・ツール接続を選択します。接続が機能することをテストします。
次に、ドロップダウン・リストから、ステップ2aで作成したコンテキスト検索プロシージャを選択します。最後に、「作成」ボタンをクリックします。
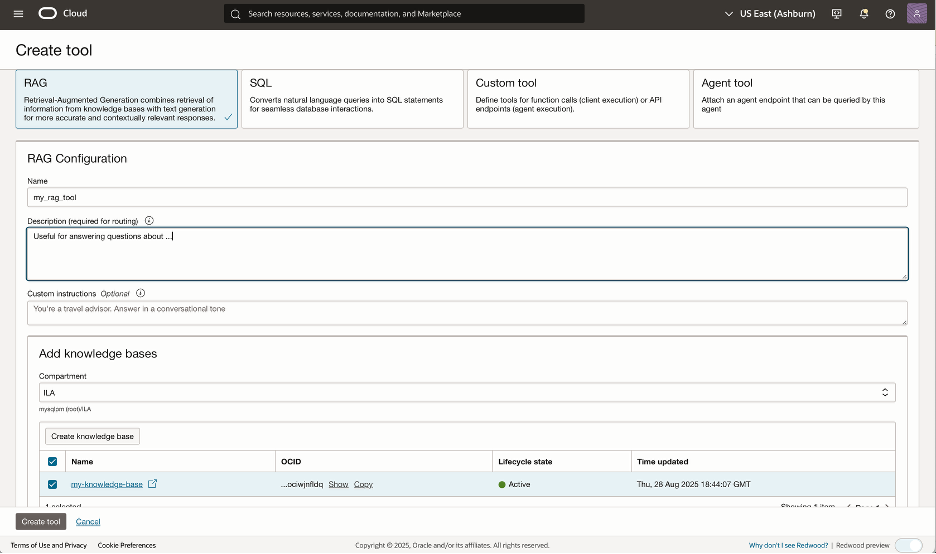
ステップ 2.3: RAGツールの作成
ナレッジベースの作成に成功したら、OCIコンソールでエージェントに移動し、「リソース」ペインをクリックし、「ツール」を選択します。ナレッジベースと対話するためのRAGツールをエージェントに付与する必要があります。
新しいRAGツールを作成するか、エージェントにすでにRAGツールがある場合は変更します。MySQL HeatWaveナレッジベースをRAGツールに関連付けます。
ステップ 3: HeatWaveの非構造ドキュメントの追加
MySQL HeatWaveインスタンスに1つ以上のベクトル・ストア・テーブルがすでにある場合は、このステップをスキップできます。
備考: このステップの残りの部分では、MySQL HeatWaveインスタンスがオブジェクト・ストレージのバケットにアクセスできるようにするポリシーを追加する必要がある場合があります。詳細な手順については、このブログを参照してください。
MySQLクライアントからMySQL HeatWaveインスタンスに接続します。OCI Object Storageからの非構造化ドキュメントの取込みは、sys.vector_store_load ストアド・プロシージャを呼び出すのと同じくらい簡単です。これにより、ドキュメントが自動的に解析され、セグメントに分割され、セグメントがベクトルに埋め込まれます。次の例では、quickstart_bucketという名前のバケットがネームスペースmy_os_nsにあり、ロードするドキュメントがおかれています。

次に、ベクトル表を格納するmy_vector_store というデータベースを作成し、sys.vector_store_loadを呼び出します。
CREATE DATABASE IF NOT EXISTS my_vector_store;
USE my_vector_store;
CALL sys.vector_store_load('oci://quickstart_bucket@my_os_ns/', NULL);
+--------------------------------------+-------------------------------------------------------------------------------+
| task_id | task_status_query |
+--------------------------------------+-------------------------------------------------------------------------------+
| 75812529-7ea2-11f0-b2a4-020017021030 | SELECT mysql_tasks.task_status_brief("75812529-7ea2-11f0-b2a4-020017021030"); |
+--------------------------------------+-------------------------------------------------------------------------------+
データをロードするタスクはバックグラウンドで実行され、戻されたタスクのステータスを問合せてその進行状況を監視できます。正常に完了すると、出力は次のようになります。
SELECT mysql_tasks.task_status_brief("75812529-7ea2-11f0-b2a4-020017021030");
+--------------------------------------------------------------------------------------+
| mysql_tasks.task_status_brief("75812529-7ea2-11f0-b2a4-020017021030") |
+--------------------------------------------------------------------------------------+
エージェントを使う
完了です!エージェントを使用できるようになりました。エージェントでは、ナレッジベースが自動的に利用され、必要に応じてそこから情報を取得できます。エージェントをテストする最も簡単な方法は、「チャット」セクションに移動し、ドロップダウン・メニューからエージェントを選択することです。自由に遊んでください。まずは、MySQL HeatWaveのナレッジベースからの情報を必要とする質問をします。

追加情報
OCIを初めてご利用の方は Oracle Cloud Free Tierにサインアップ して無料で構築
詳しくは:
Oracle Cloud Free Tierで生成AIを始めましょう。シンプルかつ高速、パワフルなMySQL HeatWave GenAIは Always Free で期間無制限で無料でご利用いただけます。


