この記事は Unsupervised Anomaly Detection with MySQL HeatWave の翻訳版です。
異常検知は、データの中で異常な値を発見するための技術です。不正の検出やネットワークへの侵入、生命を脅かす疾患の検出、品質管理など、さまざまな分野で利用されています。
この記事では2つの事例を紹介します: 1つ目は、クレジットカードの使用履歴における不正利用検知の例です。普段は自国でクレジットカードを使用している顧客が、外国でクレジットカードを使用して複数の大きな買い物をした場合、これは通常の利用パターンから逸脱しています。これは所有者が知らないうちにカード番号が盗まれ、悪用されている可能性を示唆しています。もうひとつは自動車の製造工程における、不良部品特定の事例です。 品質上の問題特定にかかわるこの識別は、後工程で修正するとコストが高くなるため、早めに修正するために必要です。
上記の例では、異常検知は通常から外れたなふるまいを感知し、是正措置を講じられるように警告フラグを立てることができます。
異常検知は、ラベル付きデータの不足、異常の発生頻度の低さ、様々な種類の異常に対し1つのソリューションで対応できないなどの困難があり、特に難しい技術です。
異常検知について言及した文献では、最近傍距離を用いて異常を検知する、距離ベースの機械学習アルゴリズムが複数見受けられます。しかしこれらのアルゴリズムは特定の異常タイプを検出するように設計されていることが多く、ユーザーがデータセットにどのような異常タイプがあるかを知らなければ、アルゴリズムの選択が難しい問題となる場合があります。
以下に図示した通り、異常には3つの典型的なタイプがあります。
- 大局的異常
すべての正常点からかけ離れた異常点のこと。例えば「他のすべての取引が特定の国や地域で行われているにもかかわらず、遠く離れた国で行われたクレジットカードの取引」など。
- 局所的異常
最も近い正常点から比較的離れているが、最も近い正常点との距離が他の正常点間の距離とほぼ同オーダーである異常点のこと。例えば「クレジットカードの請求額が正しくない」など。
- クラスター異常
最も近い正常点からは離れているが、他のいくつかの異常点からは近い異常点のこと。例えば「同じ日の、ATMからの連続した最大限の現金引き出し」など。
下図の例では、2つの正常なクラスターがあり、距離ベースでの局所的(Local)、大局的(Global)、クラスター(Cluster)異常が示されています。

HeatWave AutoMLは、Generalized kth Nearest Neighbors (GkNN)と呼ばれる、ハイパーパラメータのチューニングを必要としないアンサンブルアルゴリズムに基づく新規特許技術を用いて、ラベル無しデータの異常を自動検出します。このアルゴリズムは、通常検出のために別のアルゴリズムを必要とする、局所的、大局的、クラスターといった一般的なタイプの異常を識別できます。このアルゴリズムは、一連の異常検出データセットにおいて、k-th Nearest Neighbor (kNN) や Local Outlier Factor (LOF) などの最も広く利用されているアルゴリズムよりも高いパフォーマンスを発揮できます。

HeatWave AutoMLは、他の異常検知技術と比較してトップクラスのAUC (Area under the ROC Curve) スコアを提供しています。AUCスコアは、モデルの効率性を示す指標です。AUCが高いほど、ポジティブ・クラスとネガティブ・クラスを区別するモデルの性能が優れていることを意味します。

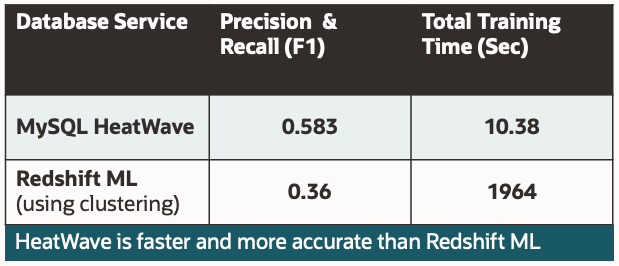
Google BigQuery ML、Redshift ML、Snowflakeなどの競合製品はいずれも、HeatWave AutoMLのような異常検知の完全自動化ソリューションを提供していません。HeatWaveは、一連の異常検知データセットを、Redshift MLと比較してはるかに高速かつ正確に処理できます。
HeatWave AutoMLの例
モデルをトレーニングし、予測を行うための HeatWave AutoML 関数を、以下に提供します。ユーザーに要求される設定値は、データセットに含まれる異常の割合を示す汚染係数 (contamination) のみで、デフォルト値は1%です。詳細は、MySQL HeatWave AutoML のドキュメントを参照してください。
トレーニング
CALL sys.ML_TRAIN ('table_name', NULL, options, model_handle);
options: {
JSON_OBJECT('key','value'[,'key','value'] ...)
'key','value':
|'task', {|'anomaly_detection'}|NULL
| ‘contamination’, float
}
トレーニングデータセットに対して ML_TRAIN 関数を実行すると、学習済みの機械学習モデルが生成されます。
予測
CALL sys.ML_MODEL_LOAD(model_handle, user);
ML_MODEL_LOAD 関数は、モデルカタログからモデルをロードします。モデルは、ML_MODEL_UNLOAD 関数を使ってモデルがアンロードされるか、HeatWave Cluster の再起動によって HeatWave ML が再起動されるまでロード状態が維持されます。
CALL sys.ML_PREDICT_TABLE(table_name, model_handle, output_table_name, options);
options: {
JSON_OBJECT('key','value'[,'key','value'] ...)
'key','value':
|'threshold', float
| ‘topk’, int
}
ML_PREDICT_TABLE は、ラベルのないデータのテーブル全体に対する予測値を生成し、結果を出力テーブルに保存します。
SELECT ML_PREDICT_ROW(input_data, model_handle, options);
options: {
JSON_OBJECT('key','value'[,'key','value'] ...)
'key','value':
| ‘threshold’, float
}
ML_PREDICT_ROW は、ラベルのないデータの1つまたは複数行の予測値を生成します。
まとめると、異常検知はデータの中の異常を発見するための有効な手法です。HeatWave AutoML は、特許取得済みのアルゴリズムに基づく異常検知のための自動機械学習パイプラインを提供し、様々なタイプの異常を検知することができ、他の異常検知技術と比較してより高い精度を提供します。

