MySQL ShellとMySQL Routerのイノベーション・リリース9.2.0では、MySQLデータベース・アーキテクチャにおけるクエリ・ルーティングをよりダイナミックに、より柔軟に、より宣言的にする新機能「ルーティング・ガイドライン」をサポートしました。
この機能は、MySQL Community Edition および Enterprise Editionでサポートされており、特定のアプリケーション・ニーズに合わせたクエリ・ルーティングにより、MySQL InnoDB Cluster、ClusterSet、ReplicaSetのトポロジ間でシームレスなクエリ分散が実現します。ルーティング・ガイドラインを活用することで、管理者はクエリ・フローをより詳細に制御し、スケーラブルで回復力のある方法でパフォーマンスと可用性を最適化することができます。
よりスマートなクエリ・ルーティングの重要性
最新のデータベース・アーキテクチャでは、効率的なクエリ・ルーティングがパフォーマンス、スケーラビリティ、復元力、柔軟性を実現するために不可欠です。
MySQL Router は、クライアント接続を適切な MySQL サーバインスタンスに動的に誘導するミドルウェアとして機能し、MySQL アーキテクチャの中心的な役割を果たします。MySQLの高可用性構成と統合することで、フェイルオーバー、ロードバランシング、クエリ分散を実現しています。
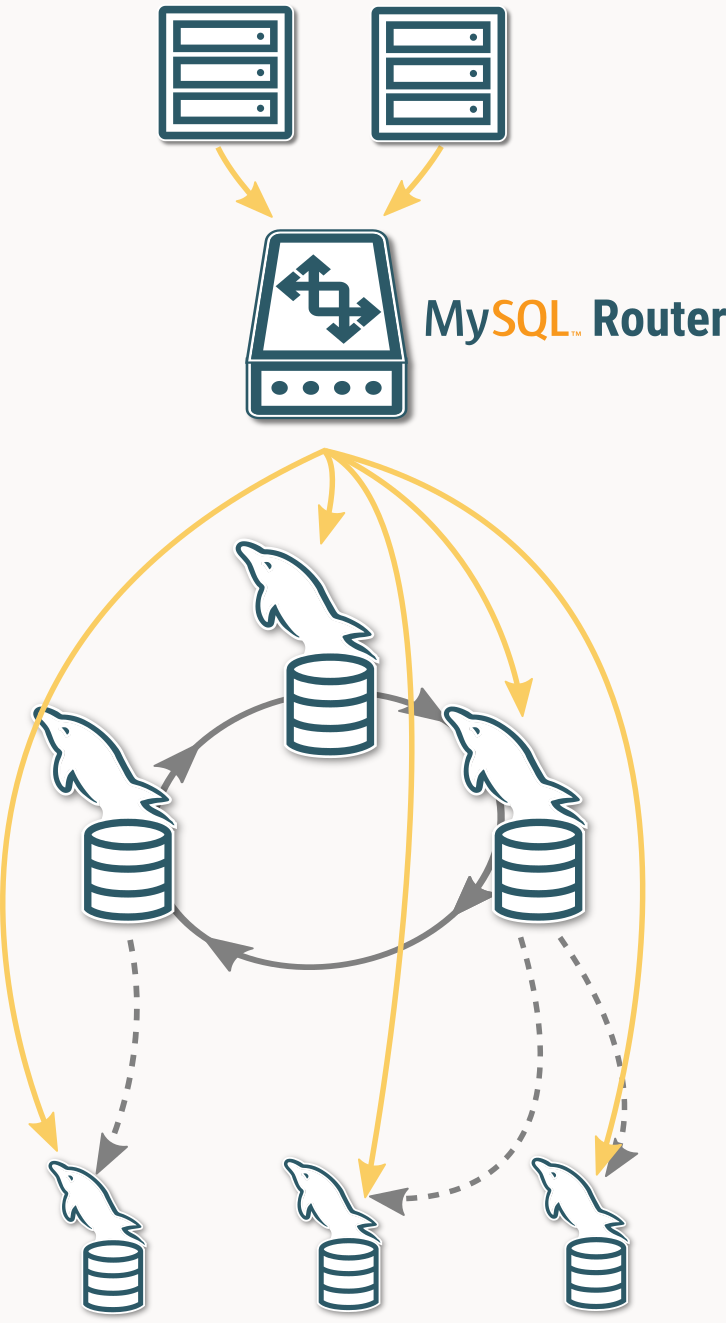
しかし、MySQLのトポロジが複雑になるにつれて、接続ルートをより細かく制御する機能が必要になります。
MySQL Router のデフォルトのルーティング動作は、シンプルなデプロイメントには効果的ですが、多様なシナリオに対応するために必要な要件に対応するには十分ではありません。
従来のルーティングでは不十分なケース
地理的に分散したトポロジ
ある地域にプライマリ・クラスタ、別の地域にレプリカ・クラスタなど、複数の地域にまたがるClusterSet構成を考えてみましょう。

従来のルーティングでは、MySQL Routerは基本的な読み取り/書き込みルールしか適用しないため、クエリのルーティングが最適化されず次のような問題が発生します:
- レイテンシの増加 – クエリが最も近いリージョンに向けられないため
- 非効率なワークロードバランシング – ホットスポットが発生し、一部のノードが十分に利用されない
- インテリジェントなフェイルオーバーの欠如 – 従来のルーティングではワークロードの優先順位が考慮されない
参照系スケールアウトとテスト環境
ここで、複数のリードレプリカを持つInnoDB Clusterで構成されるトポロジを、参照系処理のスケールアウトと新しいMySQLバージョンのテストの両方に使用する場合を考えてみましょう。異なるアプリケーションには、それぞれ異なる要件があります:
- App X – フロントエンドのトラフィックを処理し、低レイテンシでの参照処理が必要
- App Y – リソースが集中するような参照系クエリを実行するため、専用レプリカにオフロードする必要がある。
- App Z – MySQLの新しいバージョンでテストを実行(図では9.2)するため、本番環境のワークロードから分離させる
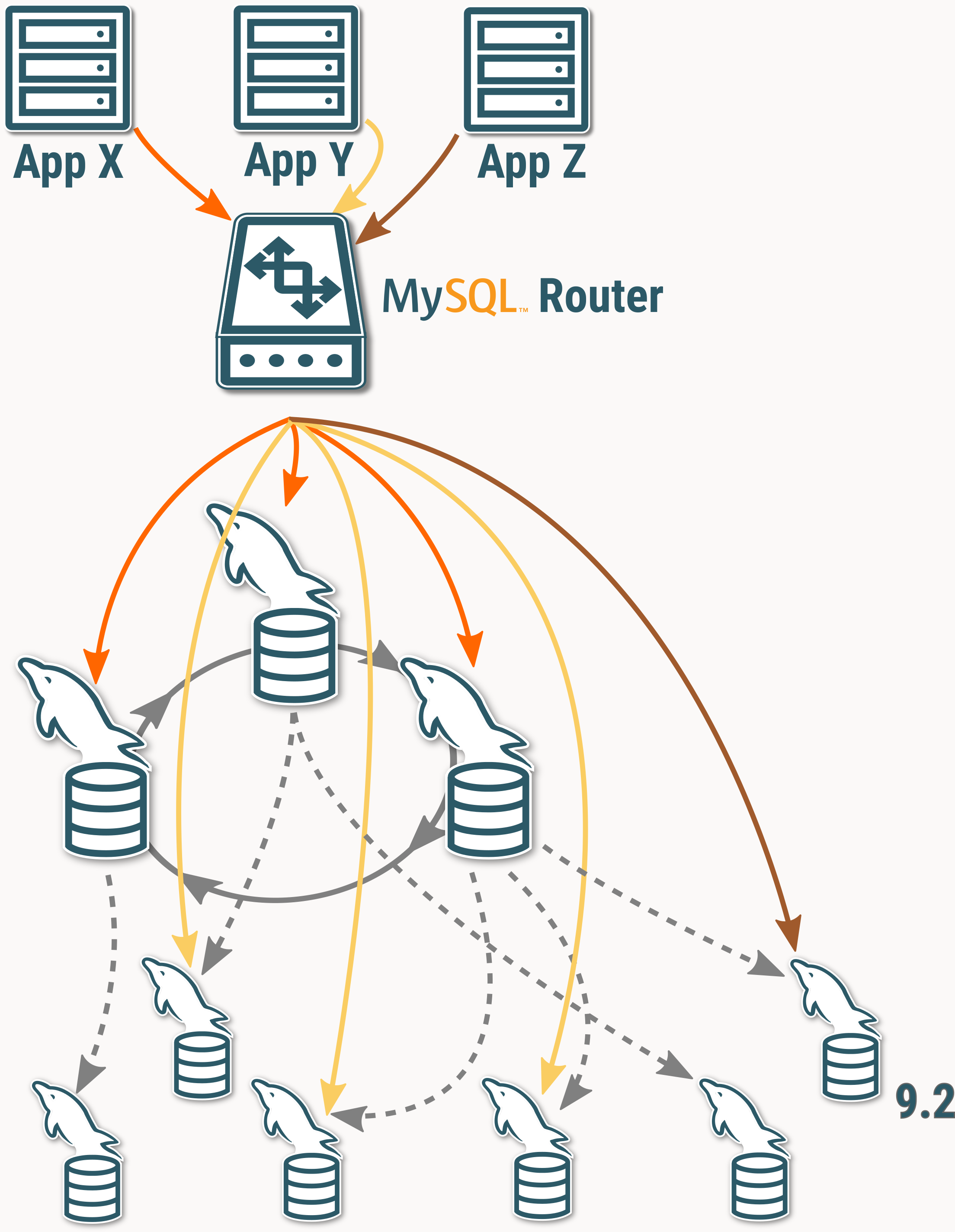
従来のルーティングでは、特定のユーザー、アプリケーション、プラットフォーム、クエリーの種類に基づいたトラフィックの区別は行われていませんでした。
つまり、すべての接続に同じ参照/更新の分類が適用されており、フロントエンドのトラフィックをセカンダリにルーティングしたり、リソースの多いクエリを適切なリードレプリカにルーティングすることやテスト用クエリを本番ワークロードに影響を与えることなく分離させて特定の MySQL バージョンで実行することはできませんでした。
マルチテナント・アプリケーションとシャーディング
別の例として、異なる顧客からのクエリを特定のデータベースまたはスキーマにルーティングする必要があるマルチテナント・アプリケーションがあります。
セッションを認識しない MySQL Router には、アプリケーション側のロジックを使用せずにテナントベースのクエリ・ルーティングを実行する機能がありません。
その他の現実的な問題
実際のところ多くのワークロードには、従来のルーティングでは対応できない次のような特殊なルーティングのニーズがあります:
- ワークロードの優先順位づけ – CPU、メモリ使用量、クエリタイプに基づいてクエリを実行
- コンプライアンス重視のルーティング – 特定の地域からのみ機密データにアクセスできるようにする(GDPR、CCPA対応など)
- ネットワークを考慮したルーティング – 内部トラフィックと外部トラフィックなど、送信元に基づいてクエリを実行
これらは、より柔軟性がありコンテキストを考慮したルーティング機能が必要であることを示しています。
ルーティング・ガイドライン: MySQL におけるクエリ・ルーティングの新機能
![]()
このような課題を解決するために、MySQLデータベースアーキテクチャはルーティングガイドラインを導入しました。ルーティングガイドラインは、様々な要因を考慮した宣言的なルールを使用してクエリ・ルーティングを動的に調整するように設計された機能です。
従来の自動ルーティングとは異なり、ルーティング・ガイドラインでは管理者が宣言的なルールを定義し、それに基づいてクエリを適切なMySQLインスタンスにインテリジェントに分散させることができます:
- サーバーの属性(プライマリーレプリカなど)
- クライアントセッションの属性(スキーマ、ユーザー名、クライアント属性)
- ルータの設定 (Read/Writeポート、ホスト名)
この機能により、カスタマイズ可能なルール駆動型のアプローチが提供され、以下のような様々な目的に使用できます:
- 最も近い、または最も効率的なデータベースノードにクエリをルーティングすることでレイテンシを最小化する。
- クエリーを動的に分散させることにより、ロードバランシングを強化する。
- フェイルオーバー処理を改善し、手動操作なしにクエリが常に利用可能なリソースにルーティングされるようにする。
ルーティングガイドラインはきめ細かな制御を可能にし、MySQL Router がアプリケーションのニーズに合わせて、より高度な決定をすることを実現します。
仕組みについて
ルーティング・ガイドラインは MySQL Shell の AdminAPI を使用して定義され、管理者はルーティングのルールを宣言的に作成し管理することができます。
ルーティング・ガイドラインは 主に2つの要素で構成されます:
- destinations – パターンマッチング式を使用して、トポロジ内の MySQL インスタンスのグループを定義します。destinationsは候補インスタンスのプールとして機能し、クエリが特定の条件に一致するサーバのみにルーティングされるようにします。
- routes – クライアントセッションを適切な宛先にマッチさせる方法を決定します。式を使用して、ルーティングはクライアントセッションを分類し、スキーマ、ユーザ、ワークロードタイプなどの要因に基づいて最適な MySQLインスタンスに誘導します。
ルーティング・ガイドラインの例:
{
"destinations": [
{
"match": "$.server.memberRole = PRIMARY AND $.server.clusterRole = PRIMARY",
"name": "Primary"
},
{
"match": "$.server.memberRole = SECONDARY AND $.server.clusterRole = REPLICA",
"name": "ReplicaClusterSecondary"
},
{
"match": "$.server.memberRole = READ_REPLICA AND $.server.clusterRole = REPLICA",
"name": "ReplicaClusterReadReplica"
}
],
"name": "default",
"routes": [
{
"connectionSharingAllowed": true,
"destinations": [
{
"classes": ["Primary"],
"priority": 0,
"strategy": "round-robin"
}
],
"enabled": true,
"match": "$.session.targetPort = $.router.port.rw",
"name": "rw"
},
{
"connectionSharingAllowed": true,
"destinations": [
{
"classes": ["ReplicaClusterSecondary", "ReplicaClusterReadReplica"],
"priority": 0,
"strategy": "round-robin"
},
{
"classes": ["Primary"],
"priority": 1,
"strategy": "round-robin"
}
],
"enabled": true,
"match": "$.session.targetPort = $.router.port.ro",
"name": "ro"
}
],
"version": "1.0"
}このルーティング・ガイドラインでは:
- destinationsの要素として、メンバの役割に基づいて3つのグループに宛先を分類します:
- プライマリ –
$.server.memberRole = PRIMARY AND $.server.clusterRole = PRIMARY - レプリカ・クラスタ・セカンダリ –
$.server.memberRole = SECONDARY AND $.server.clusterRole = REPLICA - レプリカ・クラスタ・リードレプリカ –
$.server.memberRole = READ_REPLICA AND $.server.clusterRole = REPLICA
- プライマリ –
- routesの要素として、上記の宛先にどのようにマッチさせるかを定義します:
- “rw” ルートは、参照/更新の処理をプライマリに誘導。
- “ro” ルートは、レプリカ・クラスタのセカンダリとリードレプリカを優先し、ラウンドロビン方式でトラフィックのバランスを判断して誘導。どちらも利用できない場合は最後の手段として、プライマリに誘導。
この例は、ルーティング・ガイドラインがどのようにクエリ・ルーティングをきめ細かく制御し、トポロジー全体で効率的なロードバランシングとフェイルオーバー管理を可能にしているかを示しています。
マッチング式: ルーティング・ガイドラインの中核
ルーティング・ガイドラインはクエリ・ルーティングのルールとして機能するマッチング式に依存しています。これらの式により、管理者は以下を行うことができます:
- 論理条件を利用してサーバー、セッション、ルータを定義する
- 変数、演算子、関数、値を指定してマッチングを定義する
- AND、OR、NOTを使って条件を組み合わせ、柔軟性を高める
マッチング式を活用することで、ルーティング・ガイドラインは正確で動的なクエリ・ルーティングを提供し、各クエリが最適な MySQL インスタンスによって処理されるようにします。
一般的なマッチング式と使い方
前述の例では、以下の定義済み変数とマッチング式を使用しています:
| 変数 | 用途 | 例 |
|---|---|---|
| $.server.memberRole | MySQLインスタンスの役割を定義 | PRIMARY, SECONDARY, READ_REPLICA |
| $.server.clusterRole | プライマリ・クラスタとレプリカ・クラスタのどちらに属するかを定義 | REPLICA, PRIMARY |
| $.session.targetPort | セッションタイプによるルーティングを行うためのクライアント・ポート | 3306 |
| $.router.port.rw | MySQL Routerに設定されているRead/Writeトラフィックに割り当てられているポート | 6446 |
| $.router.port.ro | The port assigned to read-only traffic in MySQL Routerの参照専用トラフィックに割り当てられているポート | 6447 |
| … | … | … |
他にもたくさんの定義済み変数や関数が用意されています。
定義済み変数に加えて、ルーティング・ガイドラインはより高度なルーティングロジックを可能にする様々な関数を提供しています。
これらの関数はネットワークサブネットのマッチング、文字列操作、正規表現の評価などを行うことが可能です。
以下に例を示します:
| 関数 | 用途 | 例 |
|---|---|---|
| NETWORK(‘str’, ‘int’) | 指定されたアドレスとビットマスクのネットワークアドレスを計算 ネットワークアドレスを文字列として返却 |
NETWORK('10.1.1.120', 24)10.1.1.0 から 10.1.1.255までの範囲を返却 |
| CONTAINS(‘str1’, ‘str2’) |
|
CONTAINS('foobar', 'foo')trueを返却 |
| REGEXP_LIKE(‘str1’, ‘str2’) | str1 が str2 で定義された正規表現と一致するかどうかを判定大文字と小文字は区別されず、改善されたECMAScriptの正規表現方法を採用 |
REGEXP_LIKE('foobarbaz', 'foo.*baz')trueを返却 |
| … | … | … |
これらは、ルーティング・ガイドラインで利用できる関数の一例に過ぎず、関数一覧にはさらに多くの関数が掲載されています。
マッチング式の実例
以下は、マッチング式の例です:
スキーマに基づくルート検索
"match": "$.session.schema = 'analytics' AND $.session.user = 'reporting_user'"
このルールは、「reporting_user」ユーザーから発行される「analytics」スキーマに対するすべてのクエリが、対応するルーティング・ガイドラインに従ってルーティングされることを示しています。
ネットワークサブネットに基づくルート検索
"match": "NETWORK($.session.sourceIP, 24) = NETWORK('192.168.1.0', 24) OR
NETWORK($.session.sourceIP, 8) = NETWORK('10.0.0.0', 8)"
このルールは、ネットワークサブネットに基づいてクライアントのIPアドレスをマッチングします:
- 1番目の条件は、クライアントのIPが192.168.1.0/24サブネットに属しているかどうか(ローカルオフィスまたはデータセンターのクライアントに一致するか)をチェックします。
- 2番目の条件は、クライアントが10.0.0.0/8サブネットに属しているかどうか(企業VPNまたは内部ネットワークに一致するか)をチェックします。
いずれかの条件が真の場合、クエリは特定のサーバーセットにルーティングされます。
バックアップ操作を専用サーバーにルーティング
"match": "$.session.connectAttrs.program_name = 'mysqldump'"
このルールは、MySQLのバックアップツール (mysqldump) がクライアントとして使用されていることを検出します。mysqldump から発行されたクエリは、プライマリデータベースノードのパフォーマンスに影響を与えないように、特定のサーバー(バックアップサーバーなど)にルーティングされます。
MySQL 9.2.0 が稼動しているステージングサーバーのデスティネーションの定義
"match": "$.server.tags.environment = 'staging' AND $.server.version = 90200"
このルールは、ステージング環境で動作している(タグ付けされた)MySQLサーバーと、MySQLバージョン9.2.0(90200)だけを含むデスティネーション(宛先)を定義します。
ワークフロー
ルーティング・ガイドラインは、リアルタイムの条件に基づいて最適なMySQLインスタンスにクエリが動的にルーティングされるように、構造化されたワークフローを経て動作します。プロセスは以下の一般的なステップで構成されます:
- 宛先の分類
- パターンマッチ式に基づいて MySQL サーバーをデスティネーションクラスにグループ化
- サーバーは複数のデスティネーションクラスに属することが可能(一対多の関係)
- パターンマッチ式に基づいて MySQL サーバーをデスティネーションクラスにグループ化
- ルート・ルールと照合
- クライアントリクエストを分類し、定義済みのルートにマッピング
- ルートは複数のデスティネーションクラス候補を持つことが可能(一対多の関係)
- クライアントリクエストを分類し、定義済みのルートにマッピング
- ルーティング方法の決定
- 選択された宛先間でどのようにクエリが分散されるかを決定
- 2つのルーティング方法がサポートされています:
- first-available – 最初に利用可能になったサーバーにクエリを転送
- round-robin – クエリを利用可能なサーバーに均等に分散
- トポロジの監視
- リアルタイムのトポロジ状態に応じて、サーバーの再分類を継続
- サーバーの可用性の状態に応じて、ルートを動的に更新
- 宛先が利用できない場合、無効な接続を切断
おもな利点
ルーティング・ガイドラインは、クエリ・ルーティングに柔軟で強力なアプローチを提供し、管理者が MySQL アーキテクチャ全体でクエリをどのようにディレクションするかを正確にコントロールできるようにします。おもな利点は以下の通りです:
- 宣言型ルーティング – アプリケーションを変更することなく、構造化された方法でルーティング・ルールを定義できます。
- 動的な適用 – セッション属性に基づくルーティングが可能で、高度なクエリの分散が可能です。
- きめ細かな制御 – クエリ・ルーティングの動作をきめ細かく制御できます。
- MySQL Shell および AdminAPI との統合 – MySQL Shell 経由でルーティング・ガイドラインを簡単に管理できます。
- InnoDB Cluster、ClusterSet、ReplicaSetをサポート – ポートされているMySQLデータベース・アーキテクチャと統合されています。
利用時の注意事項と要件
MySQL Routerは、すべての設定が MySQL に直接保存されるため、ステートレス接続エクステンションとして使用できるように設計されています。
これにより、ルーティング・ガイドラインの柔軟性と一元化が保たれ、設定ファイルには不必要な複雑さが解消されています。
さらに、ルーティング・ガイドラインは、 MySQL Shell と MySQL Router 9.2.0 以降を必要としますが、特定の MySQLサーバーのバージョンに依存しないため、異なる環境でも共通して利用できます。
まとめ
MySQL Community EditionとEnterprise Editionの両方で利用できるルーティング・ガイドラインは、MySQLのクエリ・ルーティングの柔軟性を高いレベルで解放し、異なるMySQL環境間でパフォーマンス、スケーラビリティ、耐障害性をこれまで以上に簡単に最適化できるようにします。
この紹介記事は、ルーティング・ガイドラインを理解するための基礎となるものです。次回は、MySQL Shell の AdminAPI を使用した設定と管理方法について、実践的な例と使用例を交えて説明します。ご期待ください!
詳細については、MySQLの 公式ドキュメント を参照するか、 MySQL Shell と MySQL Router を使用してルーティング・ガイドラインの機能をお試しください。

