この記事は、Introducing Vector Store and Generative AI in MySQL HeatWave の翻訳です。
MySQL HeatWaveはオンライン・トランザクション処理(OLTP)、リアルタイム・イン・メモリ・データ・ウェアハウス、イン・データベース自動機械学習、レイクハウス、および 生成AI(プライベート・プレビュー版)を単一のシステムで提供するフルマネージド・データベース・サービスです。これらのソリューションをETL製品の重複にかかるコストや遅延、複雑さ無しに提供します。また、データ・ウェアハウスとレイクハウスのいずれでも、分析処理については業界最高の性能と費用対効果を発揮します。
MySQL HeatWaveはオブジェクト・ストレージの数百テラバイト級のデータにクエリを実行することができ、またそれを一つのSQLクエリ文でMySQLデーターベースのトランザクション用データと組み合わせることも可能です。
オブジェクト・ストア内のデータはオブジェクト・ストア内に残されMySQLデータベースにコピーされることはないので、MySQLと互換性のあるワークロードだけでなく非MySQLワークロードにもHeatWaveを活用できます。データベースのデータに実行するのとほぼ同等の性能で、オブジェクト・ストレージのデータに行うクエリ実行が高速なのは業界初です。

MySQL HeatWaveに新たに追加される機能を以下にご紹介します。
生成AIとベクトル・ストア
生成AIをサポートすることで、自然言語でMySQL HeatWaveを利用することができるようになります。ユーザーによるクエリ文とシステムからの応答を両方とも大規模言語モデル(LLM)によって自然言語で生成することができます。
LLMは公開されているデータに基づいてトレーニングされています。LLMの機能をビジネス向けデータに利用する場合、LLMのハルシネーション(幻覚)やビジネス関連情報の不足等によって正確な結果を得られない可能性があるという問題があります。MySQL HeatWaveはこの問題を軽減するために、ベクトル・ストアを導入します。

MySQLHeatWaveが導入するベクトル・ストアは言語エンコーダーを使用して、HeatWave Lakehouseに保存される様々な形式のドキュメント(.ppt, .pdf, .textなど)からベクトル埋め込みを作成します。ベクトル埋め込みの作成はユーザによる質問も考慮に入れ、また多次元区間における類似性検索を行います。
ベクトルストアの出力はプロンプト内のユーザの質問と併せて含まれる状況や文脈(コンテクスト)であり、これがLLMの入力になります。LLMはこの情報を使い、MySQLHeatWave内のドキュメントからの独自情報を含む応答を生成します。この機能は現在プライベート・プレビュー版として利用可能です。
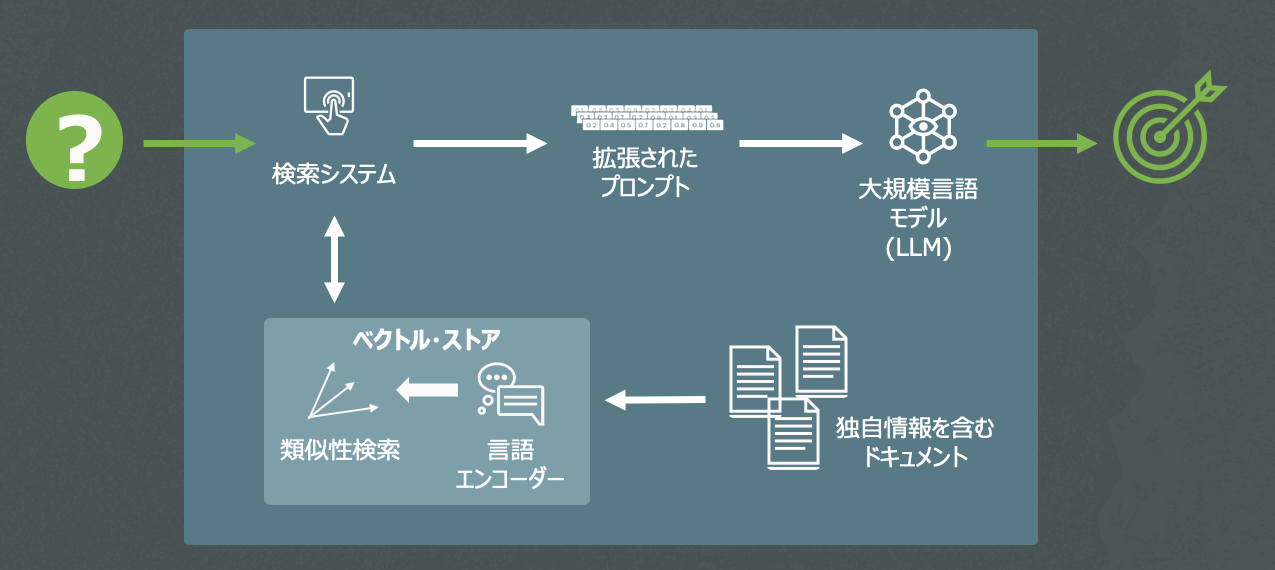
下の図ではベクトル・ストアを使用した場合と使用しなかった場合で異なる生成AIの応答例を示しています。本例では、ベクトル・ストアが取り込んだ.pdf形式ホワイトペーパーのコーパス(自然言語の単語、文章、文法などを収集し整理されたもの)をMySQL HeatWaveに保存しています。


HeatWave LakehouseがAWSで利用可能
MySQL HeatWave Lakehouseはオブジェクト・ストレージから最大500テラバイトのデータをHeatWaveノードにロードし、MySQLデータベースのデータと一緒に標準SQL構文を使用した同一クエリ文でクエリ実行できます。イン・データベース機械学習はMySQLデータベースとオブジェクト・ストアに保存されたデータに対して分類、回帰、推奨(レコメンド機能)、異常検知、予測に関する機械学習モデルのトレーニング、予想、説明が可能です。
MySQL HeatWave Lakehouseは、AWSでも利用できるようになり(一部の機能は制限されています)、Amazon S3オブジェクト・ストレージ内のデータにクエリ実行できるようになります。この機能はAWS内で完結するため、S3のデータとHeatWaveインスタンスが同じアベイラビリティ・ゾーンに属している場合は、データがHeatWave Lakehouseにロードされる際にデータ転送料金がかかりません。
HeatWaveはその優れたスケールアウト・アーキテクチャにより数百ノードに拡張することができ、また数百テラバイトのデータにクエリを実行することができます。 また多くのファイル形式をサポートしています(CSV、Parquet、Avroなど)。さらに、Aurora、Redshift、MySQLなどのデータベースからエクスポートされたデータをユーザはMySQLデータベースにインポートすることなしに、HeatWave に取り込むことができます。
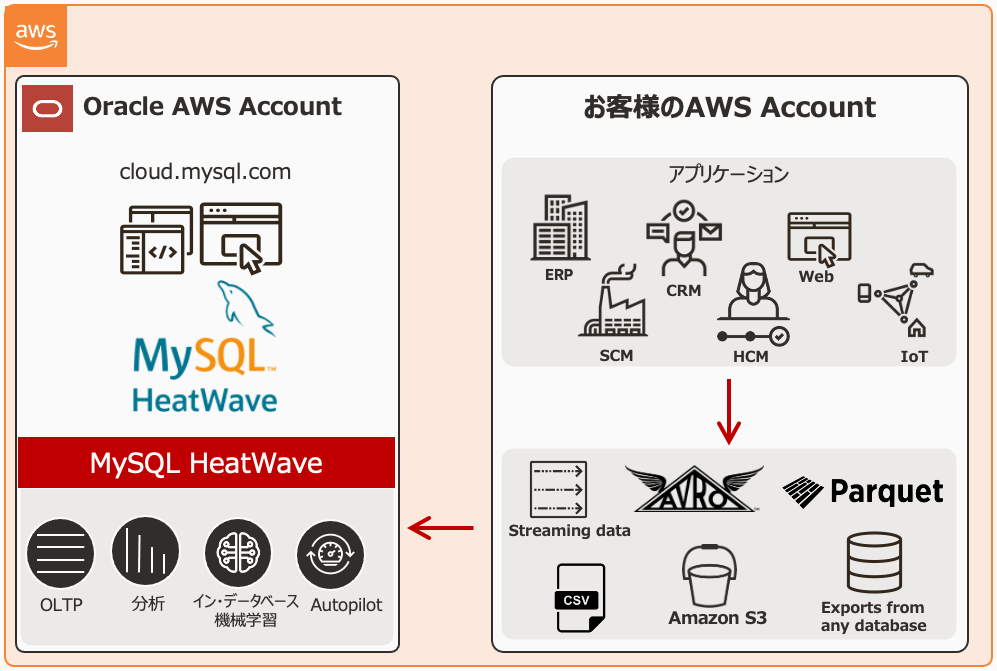
HeatWave Lakehouseによって、使い慣れたSQL構文を使用してAmazon S3ストレージからロードしたデータにクエリを実行し、また必要に応じてMySQLデータベース内に保存しているトランザクション・ データと結合することが可能です。
HeatWave LakehouseのアダプティブなMySQL Autopilotの機械学習を利用した機能によって、大量データを効率的に迅速にロードすることが可能です。 MySQL AutopilotはS3からのネットワーク転送を最適化し、CSVファイルにメタデータが無くてもデータ・スキーマを自動推論し、データのロードに必要な容量と時間を推定します。 本記事ではMySQL Autopilotの機能強化についても詳しく言及していますので、ご参照ください。
S3にデータを保存していても、S3からのデータ移動や法外な額になるかもしれないデータ転送料金なしに、OCIで提供されているのと同様に使いやすく、性能に優れ、費用対効果の高いHeatWave Lakehouseを利用することができます。
直感的に操作できるビジュアル・コンソールを使って4つのステップで、S3からHeatWaveへデータをロードすることができます。
- HeatWaveインスタンスをプロビジョニング
- S3バケット内のデータを読み取れる適切なIAM権限をHeatWaveに付与します
- MySQL Autopilotによって、S3のオブジェクト・ストレージ内データをHeatWave Lakehouseスキーマにマッピング
- S3からHeatWaveにデータをロード
HeatWave Lakehouseにおける機械学習
HeatWave AutoMLを使用して、OCIおよびAWS上のオブジェクト・ストレージからロードしたデータに対して機械学習の操作を実行できます。機械学習モデルで予測と説明を実行し、回帰、分類、予測、異常検出を行い、パーソナライズした推奨事項(レコメンド)の生成や時系列予測を生成します。

HeatWave AutoML使用すれば、データを別の機械学習サービスに移動する必要はありません。また、MySQLデータベースとオブジェクト・ストレージいずれのデータにも安全かつ簡単に、機械学習のトレーニング、推論、説明を適用できます。HeatWave AutoMLはお客様に下記のような利益を提供します。
- 完全自動: HeatWave AutoMLは学習済みモデル、推論、説明の生成を完全に自動化しています。したがって、データ・サイエンスの専門家ではない方にも使っていただけます。
- SQLインターフェイス: なじみのある使い慣れたMySQLインターフェイスで機械学習の機能を使用できます。
- 優れた性能と拡張性: HeatWave AutoMLによるトレーニング・モデルの性能は、Redshift MLなどの他の類似サービスよりもはるかに優秀です。モデルのトレーニングが高速なので、データの変更に応じたモデルの更新を頻繁に行えます。
- 簡単にアップグレード: HeatWave AutoMLは最新のオープン・ソースPython MLパッケージを使用しているため、新しいバージョンの機械学習ライブラリを継続的かつ迅速に利用することができます。
- 優れた費用対効果: MySQL HeatWave AutoMLの優れた機能は、追加機能無しで利用していただけます。SageMakerとS3ストレージの組み合わせや、Redshift MLに個別の追加料金を課すAWSとは大きく異なります。
従来データ・サイエンティストが長い時間と労力かけて行っていたタスクを、HeatWave AutoMLは以下の順序で処理します。
- データの前処理
- 機械学習モデル作成のために、いくつかの候補の中からアルゴリズムを選択
- 過学習の低減およびパイプライン高速化のために、関連する機能のみを選択
- 最適化された代表的なデータ・サンプルを選択
- 手順2.で選択したアルゴリズムのハイパーパラメータをチューニング
- 学習などで使用していない未知のデータに対し、機械学習モデルが適切に動作することを確認 (一般化)

HeatWave AutoMLによる機械学習パイプライン
MySQL HeatWaveのJavaScriptサポート
JavaScriptは最も人気のあるプログラミング言語の一つです。ウェブサイトやサーバーサイド・プログラミングに使われるほかに、データベースにおいて手続き型プログラミング言語としても使われます。そのためコードの移植性が高く、またサードパーティのツールやライブラリを使用しやすいという利点があります。
MySQL HeatWaveはJavaScriptストアド・プログラムおよびプロシージャをサポートするようになりました(一部利用制限あり)。JavaScriptで書かれたストアド・プロシージャを呼び出すクエリをHeatWave が高速化し、複雑な操作の実行を簡単にします。

JavaScript関数は、SELECT文、WHERE句およびORDER BY句、DML文、DDL文、ビューなどの SQLステートメントから呼び出すことができます。この新機能では、JavaScript内でSQLクエリを発行するインターフェイスも提供するようになるので、例えばSELECT文、DML文、DDL文内で呼び出せないJavaScriptストアド・プロシージャに便利です。
単純なSQL文とPREPARE文の両方がフル・パラメータ・バインディング・サポートでサポートされています。
JavaScriptランタイムはGraalVMで統合されているため、追加料金なしでコンパイラの最適化、性能、セキュリティ機能などのGraalVMのEnterprise Edition(EE)の機能を使用できます。
HeatWaveは以下の機能をサポートしています。
- ECMAScript 2023に基づいたJavaScript
- utf8mb4に対応した整数、浮動小数点、日付・時間、VARCHAR、CHAR型の全バリエーションのMySQLデータ型
- MySQL Shell JavaScript XDevAPIに基づいたデータ・アクセス・API
MySQLで作成したJavaScript ストアド プロシージャの例: 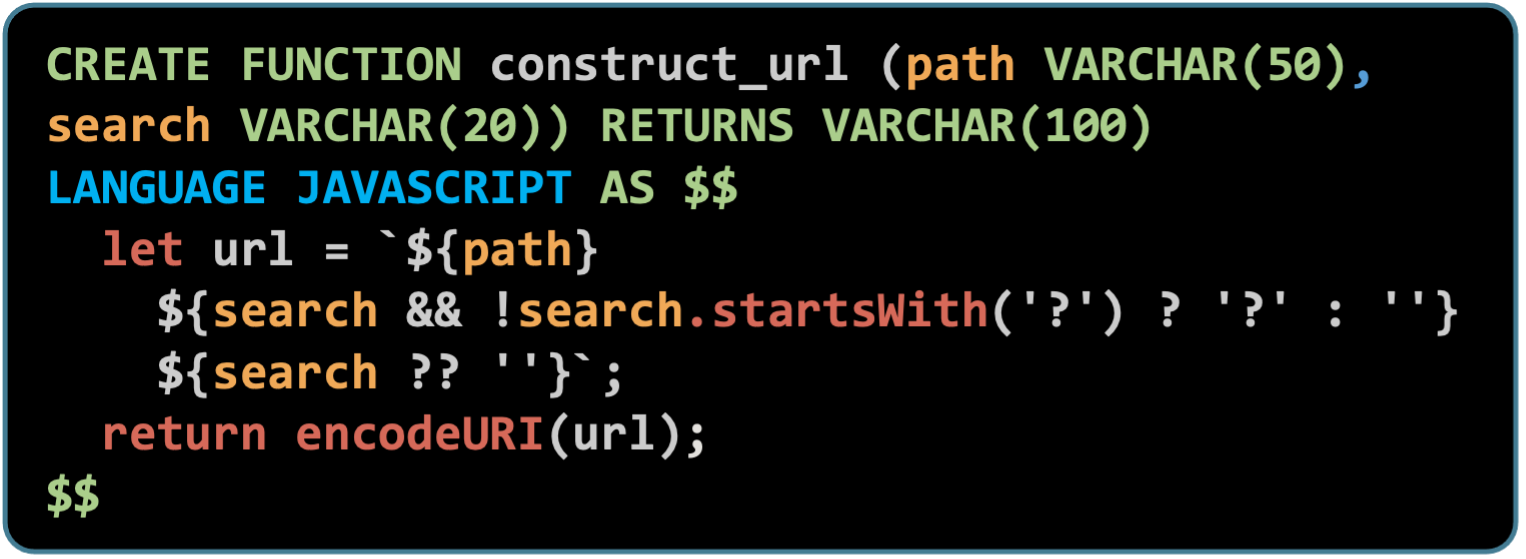
LANGUAGE句はストアド・ファンクションの言語を指定するために使用しています。
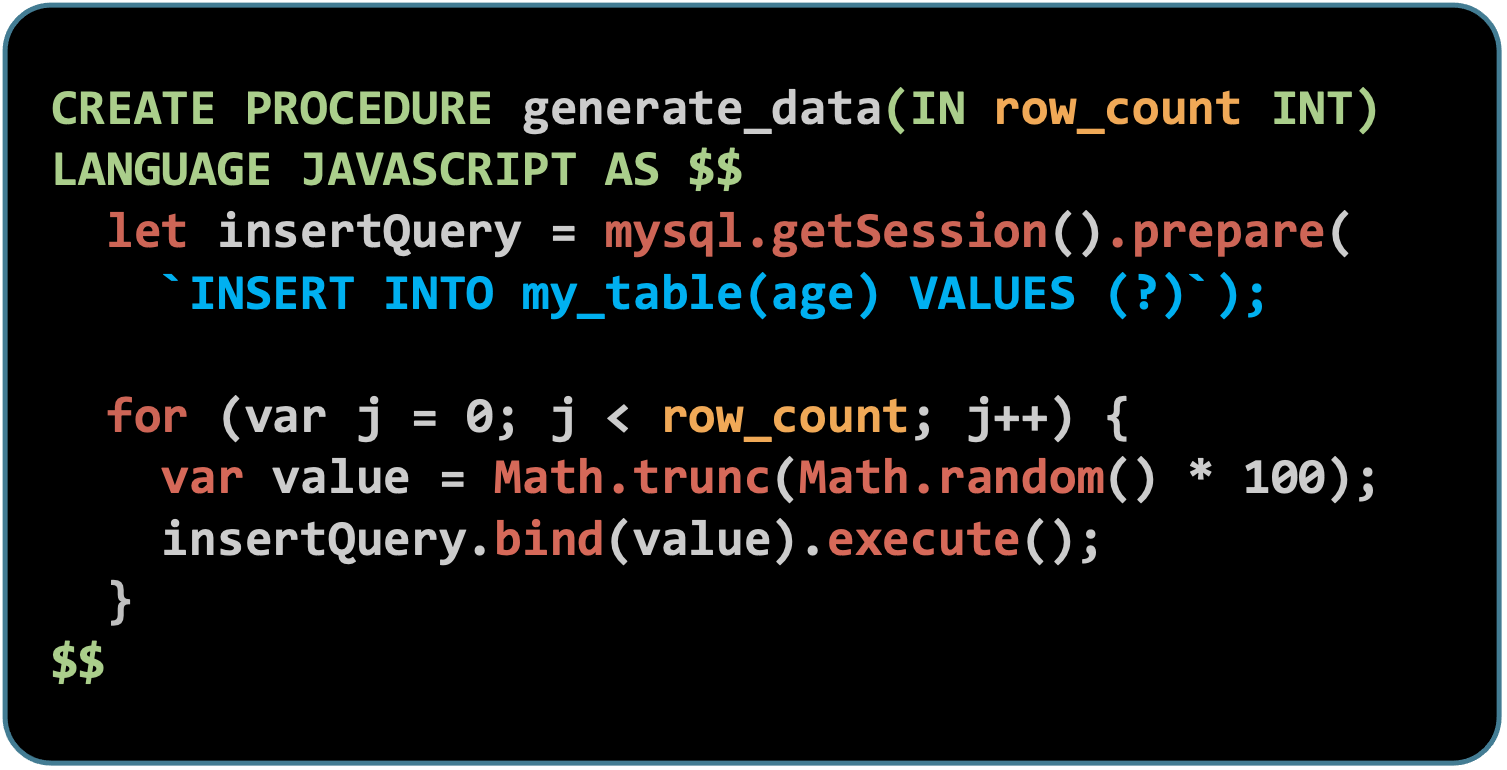
以下の例では、まずPREPARE文が年齢データを生成し、テーブルに挿入します。次に単純なステートメントを使用して行を繰り返し、年齢を合計します。
MySQL Autopilot Indexing
MySQL Autopilotはワークロードに対応し、機械学習に基づいた自動化を提供します。例えば適切なクラスター・サイズのプロビジョニング、データのロード、データのクエリ、障害の対処など、大規模クエリ性能を実現するのに欠かせない重要な機能が自動化されます。MySQL Autopilotはデータベース管理の専門知識なしに性能と拡張性の向上が可能で、開発者やDBAの生産性に寄与し、人為的ミスの低減に役立ちます。
Autopilot IndexingはMySQL Autopilotに追加された新しい機能です(一部制限あり)。機械学習をベースにした機能で、インデックスの作成・削除を推奨することでデータベースをさらに最適化し、性能向上とコスト削減を実現します。この機能によって、OLTPワークロードに最適なインデックスの作成および、ワークロードの変化に応じた長期に渡るメンテナンスなどに費やしていた労力や時間を大幅に低減できます。
作成するインデックスが少なすぎると、クエリ性能は上がりません。インデックスが多すぎると、インデックスのメンテナンスが過剰なオーバーヘッドとなり、システムの性能に悪影響を与える可能性もあります。そのためDBAの方々はストレージ、システム、クエリの性能にインデックスが与える影響を理解し、WHERE、JOIN、ORDER BY句などのクエリ構成にインデックスがどれほど関わるかを知ることが求められます。またクエリとデータのワークロードに変更があれば、DBAはインデックスの選択を再検討する必要に迫られます。
InnoDBストレージ内のテーブルには既に主キーのインデックスがあるため、Autopilot Indexingはセカンダリ・インデックス作成を推奨します。Autopilot Indexingは、現在のワークロードをもとにセカンダリ・インデックスの推奨を自動的に生成し、その際にはクエリ性能とインデックスのメインテナンスに費やすコストが考慮されます。そして性能とストレージ見積もり、生成された推奨事項の説明を提供します。ユーザーは、インタラクティブなコンソール・インターフェイスを使って、推奨されたインデックスが性能とストレージに及ぼす影響を表示し分析することができます。したがってAutopilot Indexingによる推奨を適用する前に、データベース・システムへの変更の影響を確認することができます。

MySQL Autopilot Indexingを使用する前と後のサンプル・ユーザー・ワークロードとインデックス
データベース・システムの性能を調節できるように、Autopilot Indexingは以下の包括的な機能セットを提供しています。
- クエリとDML文の性能(インデックスのメンテナンスに費やすコスト)の両方を考慮
- インデックスの作成・削除の推奨
- インデックスの作成・削除のDDL文の生成
- クエリごと、および合計ワークロードごとの性能予測
- 推奨インデックスに必要なストレージの予測
- 推奨事項に関する説明
- ユーザ・エクスペリエンスを向上させるコンソールの統合
Autopilot Indexingの呼び出し
最少のクエリが実行されると、Autopilot Indexingによりインデックス作成に関する推奨事項が作成されます。Autopilot Indexingはそのクエリを評価し、そのクエリ実行が最適か不適当か、インデックスにメリットあるかないかを判断します。インデックスの推奨は、推定ストレージと性能への影響、推奨事項の説明とともに提供されます。ワークロード・データセットが非常に小さい場合や、現在のインデックス・セットで十分な場合にはAutopilot Indexingはインデックス推奨をしないことがあります。Autopilot Indexingは、AWSのコンソールまたはOCIのコマンドラインで使用できます。
Autopilot Indexingのユーザ・インターフェイス
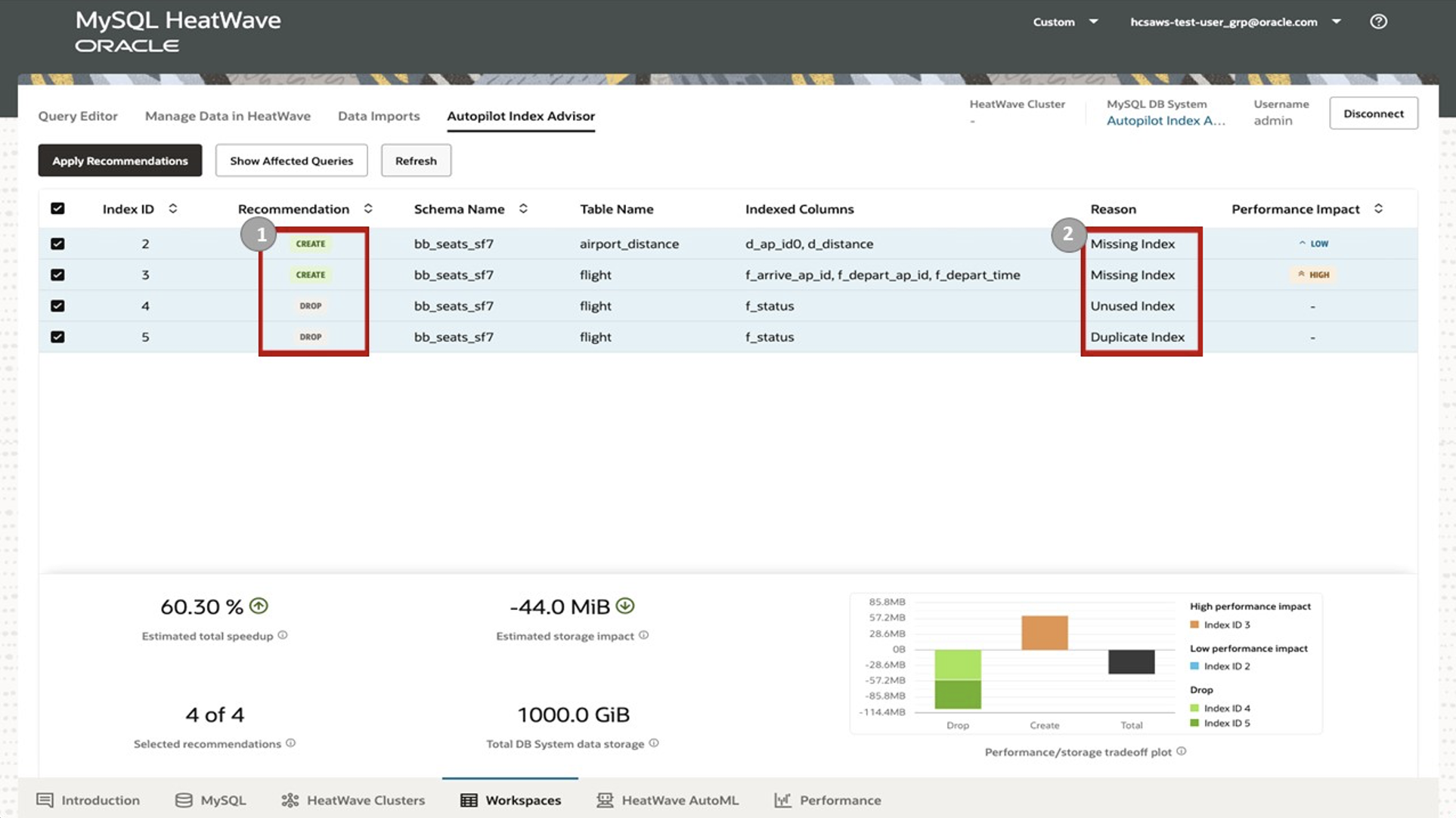
下の図は、AWSで利用できるAutopilot Indexing Advisorのコンソールです。Recommendation列に4つの推奨事項(インデックスの作成に関して2つ、削除に関して2つ) と、Reason列に各推奨事項の理由が表示されます。最後のPerformance Impact列はインデックスの作成・削除などの各アクションの評価を表示します。このように、コンソールに表示される推奨事項にしたがって、データベースをメンテナンスすることができるようになります。
MySQL HeatWaveによるJSONアクセラレーション
JSON(JavaScript Object Notation)とは、JavaScriptのオブジェクト構文に基づいてデータを構造化して表現するための標準のテキストベースのフォーマットで、最も一般的なデータ交換形式の一つです。
MySQL HeatWaveは、JSONデータ型を参照するクエリの高速化をサポートするようになり、性能が数桁規模で向上します。このクエリ高速化のために、アプリケーションの変更やインデックス作成の必要はありません。

上記の表が示す通り、HeatWaveのJSONアクセラレーションにより、シンプルなフィルターを使用したクエリと集計を使用したクエリは約20倍高速なり、大規模な結合を使用したクエリは144倍高速になります。
HeatWaveはJSONをネイティブにサポート
JSONデータを効率的に保存・理するために、HeatWaveは独自にネイティブなJSONデータ型フォーマットを提供しています。これはJSON のバイナリ圧縮表現で、JSONカラムは標準のカラムと同様に管理され、HeatWaveメモリ内のハイブリッド・カラムナー表現で保存されます。MySQLに保存されているJSONデータは変更があれば、ユーザの操作を必要とせず自動的にHeatWaveノードに反映されます。クエリ処理において、JSON演算子はJSONデータ構造の圧縮バイナリ表現に対して直接実行されます。
下記のJSON関数は現在HeatWaveでサポートされています。
- JSON_EXTRACT()
※ JSON_UNQUOTE(JSON_EXTRACT()) と同等 - JSON_UNQUOTE(JSON_EXTRACT())
※ JSON_EXTRACT() と同等 - JSON_OBJECT()
- JSON_UNQOUTE()
- JSON_ARRAY()
- JSON_LENGTH()
- JSON_DEPT()
このような機能強化によってOracleはMySQL HeatWaveの改良をさらに進め、お客様が抱えるビジネスの課題を解決していきます。

関連情報もあわせてご覧ください。
