When a consumer defaults on a debt, a third-party debt collector often collects the debt obligation rather than the lender to whom the debt is originally owed. As per Congressional research services (https://sgp.fas.org/crs/misc/R46477.pdf) as of 2020, there are nearly 7,000 collection agencies in the United States, and the industry’s annual revenue is about $13.4 billion.
Just for understanding, a debt becomes a bad debt when a regular sales transaction is not paid as scheduled and, after some attempts to recover it, the financial institution decides to hand the debt collection over to specialized companies. In this article, we focus on unsecured debt or the debts that are not supported by collaterals, in particular credit card debts. In the US, a creditor will mark a debt as a charged-off (uncollectible or difficult to recover) when past-due debts become 180-days old. (https://ecollect.org/wiki/debt-collection-process/).
Debt Collection Process
The debt collection process follows a predefined schedule of letters, emails, and phone calls to communicate with debtors. If the debtor does not pay even after the preceding communication methods, legal action can be taken. In all this process, we want to identify which debtors should be contacted first and understand the criteria by which to prioritize these, such as debtors that have huge debts, have recently defaulted, or meet some other criteria.
In this study, we will use data for credit card defaulters and build a model to score the debtors with high probability of paying. This model should provide a better ROI to debt collection companies as the data-driven approach would let them know where to spend their time and money for better recovery of debts.
Data
The dataset is for more than 40k customers. The attributes are in the following categories – demographic data, payment balance, bank accounts of credit card customers, and others. The response variable collectible is a binary variable (0,1) where 0 means non – defaulter and 1 means defaulter.
There are 19 variables and more than 60k records in the dataset.
- Cust ID: ID of each client
- DAYS_PLACED: Days since the account is placed for collection (Number of days)
- DAYS_OPEN: Days since the balance is due (Number of days)
- DAYS_CHRGOFF: Days since the bank put the account in bad debt accounts (Number of days)
- DAYS_LASTATTEMPT: Days since the last attempt to contact the customer (Number of days)
- DAYS_LASTCONTACT: Days since the customer was last contacted (Number of days)
- CURCHRGOFFAMT: The current amount of the account placed in bad debt (Dollars)
- CURORIGBALANCE: The original amount when the account was placed in bad debt (Dollars)
- AGE: Age of the customer (Years)
- EMP_STATUS: The variable will have a value of 1 if the customer has an employment else it is 0 (1=yes, 0=no)
- ASSET_BANK: It’s a binary variable whether a customer has a bank account (1=yes, 0=no)
- ASSET_BANK_COUNT: Number of Bank assets held by Customer ( Number of bank assets)
- DEBTOR_PHONE: It’s a binary variable whether a customer has a phone
- NCBRSCORE: It represnts a Credit Bureau score
- BANKRUPTCY: It’s a binary variable whether a customer has filed bankruptcy (1=yes, 0=no)
- BDISABLED: It’s a binary variable whether a customer has disability (1=yes, 0=no)
- HEADOFHOUSEHLD: It identifies if the customer is head of the household (1=yes, 0=no)
- LIMITEDINCOME: It is a boolean flag which identifies that this debtor is on limited income (1=yes, 0=no)
- COLLECTIBLE: It’s a binary variable which identifies if the debt is collectible (0=yes, 1=no)
Tools
We will use the tools in Oracle Cloud Infrastructure to build the predictive model. The options we can use are Big Data services, Data Science Service, or Oracle Machine Learning (OML) to build the model and Object Storage or Autonomous Data Warehouse (ADW) to store the data. The combination we will use is Autonomous Data Warehouse and OML AutoML UI for machine learning modeling. The AutoML UI is part of the OML suite on Autonomous Data Database. We selected this combination to simplify the ML process.
OML AutoML UI automates the machine learning modeling experience. It replaces the laborious and time-consuming tasks typically undertaken by data scientists, including:
- Select one or more algorithms for building viable candidate models.
- Select the most predictive features to speed up the pipeline and potentially increase model quality.
- For each model, tune the hyperparameters.
- Provide metrics to assess how the model performs on unseen data (also called generalization).
The below diagram (Figure 1) depicts the workflow of data scientist.

Figure 1: High-level workflow
OML AutoML UI uses the concept of an experiment to create a machine learning pipeline that automates several time-consuming and repetitive tasks taken by data scientists: algorithm and feature selection, data sampling, model building and evaluation, and hyperparameter tuning (Figure-2).
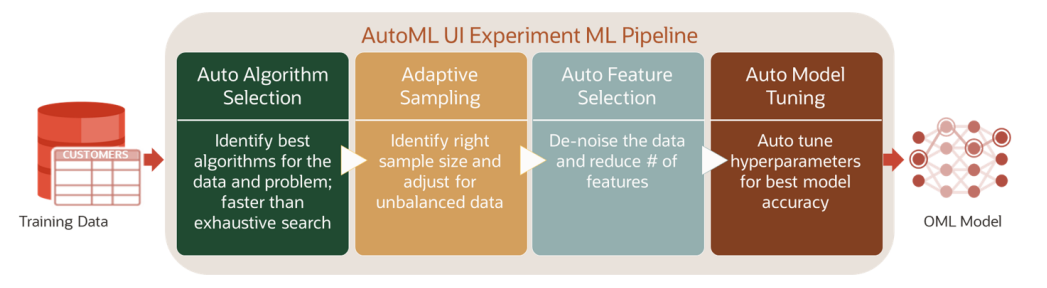
Figure 2: OML AutoML UI Experiment Pipeline
Once, we have selected the machine learning tool, the next task is to upload the data. The data is in a csv file. We will upload it to ADW with Data Load (part of the ADW suite under “Database Actions”). Once the data is in ADW, we create an experiment in AutoML, select the data source, select the predicted variable and the prediction type whether it is classification or regression. After specifying the settings, we run the experiment. AutoML, as the name suggests, supports automated machine learning, but does so through a no-code user interface – there is no need to write code. The user does not have to run different models, check for features, or worry about model tuning and understanding algorithm hyperparameters. It does all on its own. The diagram below (Figure-3) shows the different algorithms the AutoML UI ran to produce models and the accuracy of the resulting models.
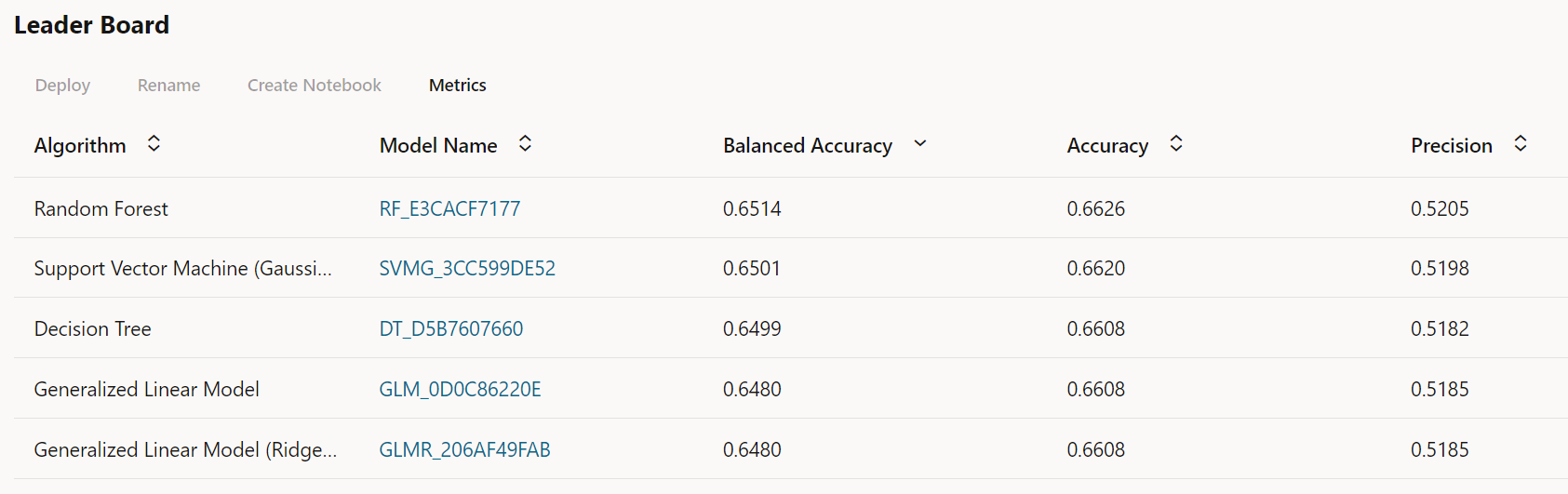
Figure 3: Model Leaderboard
The figure also shows that Random Forest provides us the best balanced accuracy at 0.6514, and overall accuracy of 0.6626. Since, our response variable (Collectible) is binary, AutoML automatically selects classification technique to build the model. Further, we see the confusion matrix (Figure 4), where Actual value 0 means correctly categorized as non- defaulter and Actual value 1 means a defaulter. The matrix shows 44.54% were correctly identified as non-defaulters and 20.01% were actual defaulters but were categorized as non-defaulters. Similarly, for the defaulters with Actual: 1.
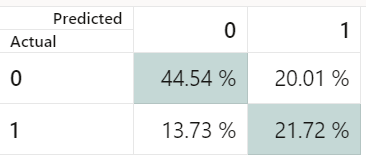
Figure 4: Confusion Matrix
We would further like to see which variables contribute most to determining the defaulters. AutoML gives us the list of variables (Figure-5) in decreasing order of significance along with their contribution to the variation in predicting defaulters.
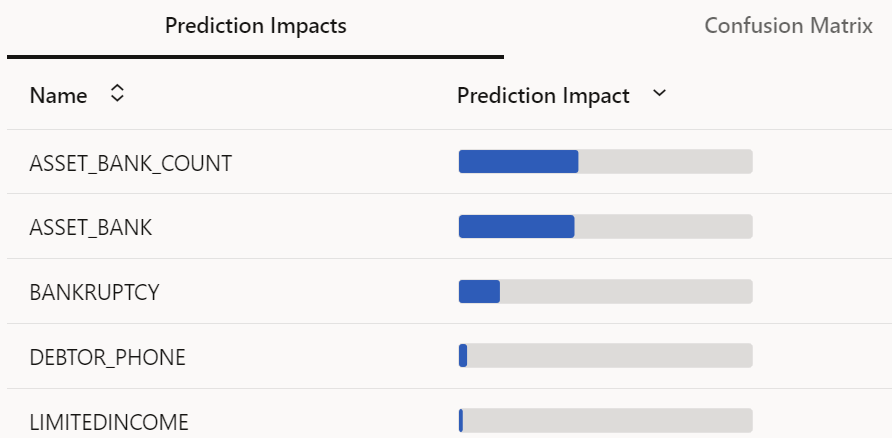
Figure 5: Prediction Impacts
The figure above shows the variable Asset Bank Count and Asset Bank has the maximum impact on the outcome by a significant margin. Since the Random Forest model provide us the maximum balanced accuracy, we select and deploy it. Deploying the model is again with the click of the button and adding few parameters like name, version, URI, etc. The deployed model can be used in applications from REST scoring endpoints. In this study, to show the results for the new data, the model was deployed in a notebook and the classification (prediction) and the probability scores for the some of the customers are shown in Figure 6.
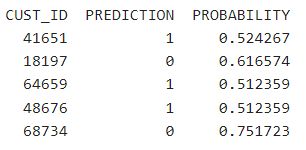
Figure 6: Predicted records for debt collection with probability
It is that simple with AutoML. Financial institutions just have to prepare and upload the data and AutoML will select the best model, which can be further used to score debtors. Financial institutions can save lot of cost and time by using a data-driven approach using AutoML (part of Oracle Autonomous Datawarehouse through Oracle Machine Learning) from OCI to recover the debts and achieve better ROI.
