As a developer or data science enthusiast, you know that enhancing enterprise applications with AI is a valuable and exciting prospect. In my previous blog post, Enhance your AI/ML applications with flexible Bring Your Own Model options, I introduced the various types of models you might use, including traditional machine learning models, transformers (embedding models), and large language models (LLMs). Such models can be sourced from native in-database options, third-party Python and R packages, and various AI providers. But what type of model is the right fit for your project?
In this blog, I explore when to use traditional machine learning, semantic similarity search, or generative AI. For each of these, I’ll guide you through several dimensions to consider when choosing among these AI technologies to enhance your applications, including:
- Use case selection
- Performance and accuracy
- Data requirements
- Development effort and skills
- Explainability and interpretability
- Security
With generative AI, I’ll also touch on techniques like retrieval augmented generation (RAG), use of traditional machine learning combined with generative AI, and AI agents. I’ll wrap up with a discussion of using models in production settings.
When to use traditional machine learning
I should clarify that when I refer to “traditional machine learning” I’m referring to the range of techniques that includes classification, regression, clustering, association rules, anomaly detection, and time series forecasting, among others. These techniques employ specific machine learning algorithms. For examples of such algorithms, the figure below depicts the techniques and corresponding algorithms supported by Oracle Machine Learning in Oracle Database 23ai.

A machine learning “model” is a representation of the patterns extracted from data by an algorithm. That model may be used for inferencing, that is, making predictions or scoring data, or for the patterns themselves. Such patterns may include cluster definitions, human interpretable rules, or predictor variable coefficients.
I won’t be discussing specific algorithms, but rather broader aspects of using traditional machine learning. Many online resources exist to dive into these techniques or algorithms in detail.
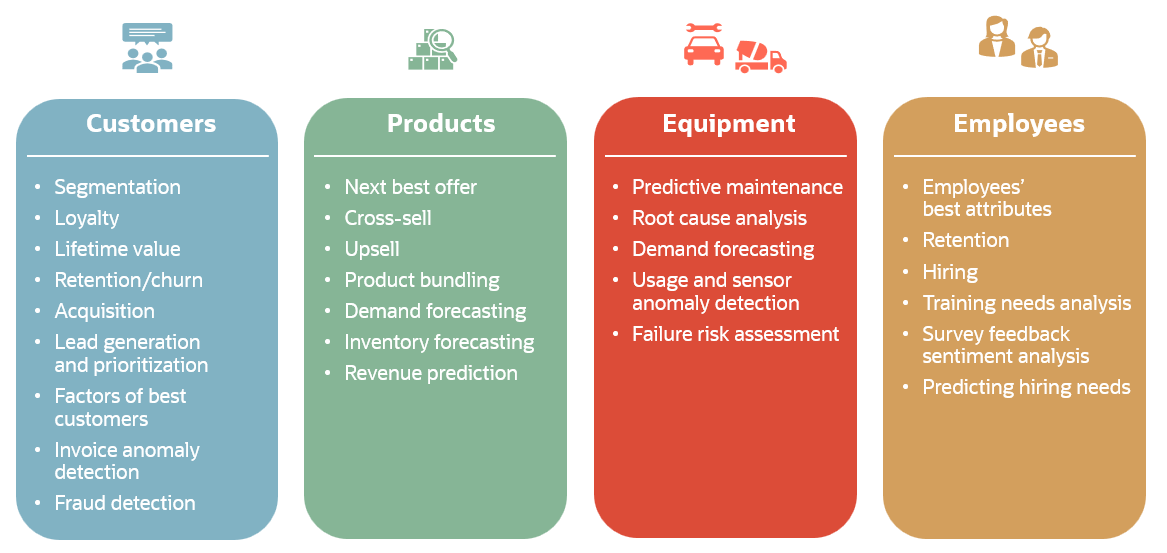
Use case selection: Traditional machine learning is versatile and applicable to numerous use cases. In many enterprises, such use cases revolve around customers, products, equipment, and employees and are applicable across industries. For customers, we may want to understand the characteristics of our best customers, or which are likely to churn or accept our offer. For products, we may want to identify products to upsell or cross-sell, or to forecast demand and revenue. For equipment, predictive maintenance helps avoid bringing equipment in for maintenance too soon, which wastes money, or too late, which incurs expensive repairs or even the need to replace equipment. For employees, we might want to understand the characteristics of our best employees, which help individuals to thrive in a given environment, and so on.
Traditional machine learning, however, requires relevant historical data to address your specific business problem. You select an algorithm, or even multiple algorithms, build models using your historical data, and then deploy the solution to make predictions or provide insights. For example, using customer demographic data, you can employ a K-means clustering model to identify customer segments, or using product sales over time, you can forecast sales using an exponential smoothing algorithm.
It’s important to note that traditional machine learning models are typically tailored to a specific use case, so you can’t use a model built for one purpose (e.g., customer segmentation) for a different purpose (e.g., predicting which equipment requires maintenance).
Performance/scalability: Traditional machine learning models offer efficiency and potentially high accuracy. Model size – the number of bytes the model requires to represent its patterns – is typically smaller due to their problem-specific nature. They are also generally faster (and computationally cheaper) to build compared to training or fine-tuning generative AI model.
For most use cases, these models can be produced using CPU computing resources. See Machine Learning: Performance on Autonomous Database for more details. Additionally, they excel at inferencing, often providing real-time responses in milliseconds for individual scores or batch inferencing in seconds to minutes. See Machine Learning: Scoring Performance on Autonomous Database for more details.
As data volumes increase, the time to build models may exceed required time windows or cost parameters. Similarly, scoring data for thousands of concurrent users or batch scoring hundreds of millions of records may also exceed time window requirements. Runtime performance is especially enhanced if the underlying algorithms are designed to take advantage of multi-threading, multiple processors, and multiple compute cluster nodes. Scalability implies that increasing compute power reduces runtime – optimally, this is a linear relationship. The Oracle Machine Learning in-database algorithms have been designed to take advantage of hardware clusters and the Exadata platform to help achieve high performance and scalability.
Memory utilization is another scalability factor. Some algorithm implementations require that all data must be resident in memory at once for training models. Some datasets are too large to be loaded into memory and require sampling or other techniques to build models or perform inferencing. The Oracle Machine Learning in-database algorithms bring data into memory incrementally, as needed, to mitigate this concern.
Data requirements: Traditional machine learning models typically work with structured data found in enterprise databases. Data scientists often engage in feature engineering, creating handcrafted features to improve model accuracy. Further, this data is then transformed to meet the requirements of the chosen algorithm. For example, neural network algorithms require normalized numeric data while the Naïve Bayes algorithm works with binned data. With suitable data preparation, even unstructured text data can be used, for example, by tokenizing the text and providing it as input to algorithms.
When using supervised learning techniques, like classification and regression, a specific target variable – what you’re trying to predict – must be provided. Selecting and preparing the target can be a challenging task. For example, consider predicting customer churn. If you simply choose a target that indicates if the customer terminated their service, that doesn’t provide any lead time to intervene, address service concerns, or entice the customer to stay. In this churn example, the target and corresponding predictor data must consist of data available perhaps a month or so in advance to identify customers likely to churn, but before they actually churn. Such lead time provides an opportunity for the business to attempt to retain such customers.
Another aspect of data for traditional machine learning models is that the structure and values of data used for inferencing must align with the training data. For example, if your model was built using the columns age and income, you cannot expect to provide gender and account balance when inferencing. Further, a model built using data from customers in the age range 25-45 is not likely to perform as well if inferencing involves customers aged 50-70. Similarly, if the training data includes a column using a rating scale of 1 to 3, but data used during inferencing use a scale of 1 to 5, what the model learned as the high value (3) is now the middle value, so model accuracy will also likely suffer.
Additionally, data quality is crucial—outliers, mislabeled data, missing values, and inconsistent representations can impact model performance. The adage “garbage in, garbage out” is quite applicable to machine learning. The better the quality of data, the better the chance of producing a more accurate model.
As we’ll see, this rigidity of requirements on data are greatly reduced, if not eliminated, with generative AI models.
Reproducibility: Traditional machine learning models typically provide reproducible results during inferencing. However, creating an identical model using the same training data and settings depends on whether the algorithm relies on random behavior. For example, neural networks use randomly initialized weights, so training the model the same data may yield different results. In other cases, algorithm parallelism and data sampling can also affect reproducibility.
Development effort/skills: Training machine learning models often requires specialized knowledge in problem formulation, data preparation, and model tuning, including understanding hyperparameters for specific algorithms. This process can involve significant iteration and experimentation, for example, trying different combinations of hyperparameters, data transformations, or even acquiring additional data. This is often the domain of data scientists.
Automated machine learning (AutoML) tools are increasingly available and can automate various tasks, such as algorithm selection and hyperparameter tuning. Oracle Machine Learning supports AutoML through a Python API and no-code user interface to help make machine learning more accessible to non-experts.
Explainability/interpretability: One of the significant advantages of traditional machine learning models is their explainability and interpretability. Many types of models provide insights into how they produce results, enabling users to understand the models themselves and the factors contributing to individual predictions. For example, decision tree models can generate rules explaining all possible predictions, while generalized linear models can provide coefficients capturing the impact of each feature on predictions. However, not all models offer the same level of transparency. Neural networks, on the other hand, often fall into the category of less interpretable, or “black box” models.
In addition to understanding the model itself, it is important to understand what factors (data values) most contribute to individual predictions or inferences. For example, is the customer’s age and income most influential on whether they will churn. This type of information can be important – if not required – in certain industries like finance or healthcare where it’s not enough to know what the prediction is, but why that prediction is being made – on what basis in the data. Oracle Machine Learning algorithms support prediction detailslike this to enable this level of understanding.
Security: Possible concerns for data security for traditional machine learning models arise at several levels: data used to produce the model, the models themselves, and using models for inferencing. If you rely on a third-party machine learning service to produce models, you must be comfortable shipping your enterprise data to that service provider. When data leaves the security protocols of your database, you must rely on other protocols to achieve your desired level of data security. Similarly, the models produced can contain business-proprietary information—for example, your customer segments, why customers churn, product demand for the coming periods, etc. Having adequate security measures in place for each of these can be business critical.
In contrast, when using in-database machine learning, the data, model, and inferencing can all occur directly within the database environment, secured by the database’s protocols. In addition, the models are part of your database schema, so standard database backup and recovery protocols typically apply.
Traditional machine learning takeaways
Here’s a summary of factors to consider if traditional machine learning is the right choice for your application:
- Your business problem aligns with specific use cases that can be addressed using traditional machine learning algorithms.
- You have relevant data available to train models to address your specific use case.
- Your team possesses the necessary skills for effective data preparation, model training, and model evaluation.
- You need efficient and reproducible inferencing.
- Explainability is important—you need to understand the model and interpret individual predictions.
When to employ semantic similarity search
As the name suggests, semantic similarity search goes beyond simple keyword matching. It involves understanding the semantic context of unstructured data, such as text, images, or audio, and retrieving relevant content based on that understanding. This type of search is particularly useful when dealing with data that doesn’t follow a structured format and where traditional search methods, like exact or fuzzy match, aren’t effective at finding similar content.
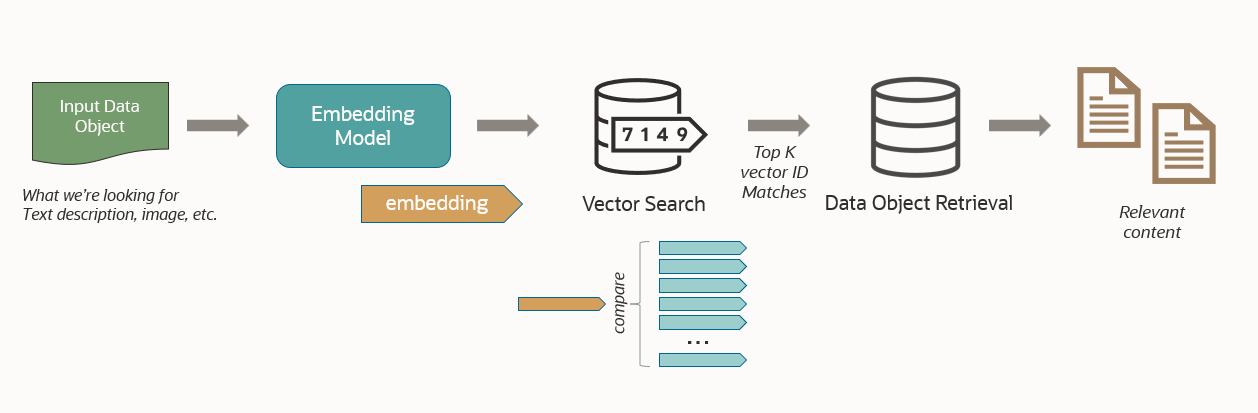
Semantic similarity search is typically enabled by using a transformer (embedding model) to produce one or more vectors per document. These vectors are stored in a vector store or vector database. A vector consists of an array of numerical dimensions that form an abstract representation of the content’s semantics. By computing the distance between two vectors (produced from the same transformer), you can determine how similar the corresponding data items are.
When it comes time to search for similar content, a data item is vectorized into one or more vectors. Then, these vectors are compared with those in the vector store to identify those closes. You can then retrieve the content corresponding to the closest vectors, as illustrated below. With Oracle Database 23ai, Oracle AI Vector Search supports semantic similarity search directly in your database – along with vector indexing for fast and scalable search.
Use case selection: Semantic similarity search can be used for a wide range of use cases, including information retrieval, recommendation systems, content-based filtering, anomaly detection, and healthcare/medical imaging, among others. Semantic similarity search shines in information retrieval scenarios where exact match and fuzzy match are inadequate. For instance, searching corporate policy documents for “maternity leave” when the documents only refer to “parental leave.” It also enhances recommendation systems, as seen in retail applications where you can find matching images based on a description or another image.
Performance/scalability: There are several factors to consider regarding performance and scalability: training or fine tuning a transformer, generating vectors from your original content, producing vector(s) for the content you’re searching for, and the actual search.
- Training a transformer from scratch is often expensive (in terms of time and money) and often requires GPU resources. Users typically rely on prebuilt transformers either through an AI provider or repositories like Hugging Face. However, not all prebuilt models are equally good for specific domains or use cases. Empirical testing is necessary to assess how well a given transformer performs. If a transformer doesn’t produce adequate results, fine-tuning or even building a custom model may be necessary.
- Populating a vector store involves converting documents into vectors, and larger documents are typically divided into smaller sections or “chunks” for more precise encoding and accurate retrieval. Each chunk must be processed by the model. As such, the size and complexity of the model, floating-point precision, and the number of vector dimensions all impact its runtime performance. GPU resources are likely beneficial (if not essential) to vectorize a large corpus of documents efficiently.
- When producing vectors, it’s important to consider the number of concurrent accesses to the transformer, the size of individual chunks, and the size of the user prompt as each will influence runtime performance and scalability. These factors will determine hardware requirements to achieve desired performance and scalability. Keep in mind also that, other things being equal, providing text with a few words to a sentence transformer producing a vector with a few hundred dimensions will be faster than providing a large image to an image transformer producing a vector with a few thousand dimensions.
- Another aspect of performance and scalability involves the actual search, that is, computing distances between vectors to find the closest. Using brute force search, where the distance between a vector for your search content is computed for every vector in your vector store, doesn’t scale well. For this, vector stores, like Oracle AI Vector Search, use powerful indexing technology for both performance and scalability, while maintaining acceptable accuracy.
Data requirements: Training high-quality models demands substantial amounts of data. Text-based models may require gigabytes to terabytes of text, while image and audio models need millions of images or thousands of hours of audio, respectively. Fine-tuning prebuilt transformers reduces data requirements, focusing on specific domain examples, such as X-rays or audio with specific dialects.
Reproducibility: While transformer models aim for consistent embeddings for the same input, some variability may occur due to floating-point precision differences. If such differences could impact your use case, consider maintaining a database of input-vector pairs to help ensure the same input consistently uses the same vector representation.
Model building, however, is another matter as many factors affect the final model. Even if using the same data and algorithm settings (hyperparameters), factors such as random initialization of neural network weights, optimization techniques that introduce randomness, and floating-point precision can all impact the resulting model. While setting a random seed can help with reproducibility, it seldom eliminates it.
Development effort/skills: The manual effort and skill needed to use transformer models is minimal, which is what makes them so appealing. Once you have a model – of which there are many pre-built models to choose from – the basic workflow is straightforward: convert each document (text, images, etc.) into one or more vectors and store those vectors in a table that maps to the source document. To search for content, use the same transformer model on your input and compute the distance between each of the vectors in your table and your input. Sort these by distance and select the top ones, that is, those with the shortest distances, as these are the most similar.
Oracle AI Vector Search in Oracle Database 23ai enables using transformer models to generate vectors, creating powerful vector indexes, and performing distance computations, among other features. Select AI in Oracle Autonomous Database goes even further to help automate the processing of vectorizing your content, producing a corresponding vector index, and automating the retrieval augmented generation (RAG) process, which I’ll discuss below.
While creating and using a vector index can be straightforward and even automated, training transformer models from scratch demands significant data science expertise, and most users opt for pre-built models or fine-tuning existing ones.
Explainability/interpretability: One challenge with transformer models is interpretability —understanding why a particular vector was generated. The abstract nature of vector dimensions, while useful for computations, can make it difficult for humans to comprehend the underlying process or “reasoning” behind vector generation.
At one level, a transformer either produces vectors that enable finding similar content effectively (against some objective metric), or it doesn’t – making it a kind of “black box.” However, techniques like attention visualization, saliency maps, and layer-wise relevance propagation (LRP) can provide insight into a transformer’s behavior, but such techniques don’t typically provide a full explanation or interpretation of results.
Security: Security is another concern, especially when dealing with sensitive data. These can arise at several levels: the content to be searched, the vectors and vector indexes produced from that content, the transformer(s), and the vectorization of content being searched for. Most vector database providers focus on storing, managing, and searching vectors that you generated in a separate environment. So, if you host the transformer model yourself, the content remains under your control – you’re sharing only vectors. If you rely on a third-party hosted transformer, you send content to that provider to generate vectors, which could introduce potential security concerns.
Oracle AI Vector Search in Oracle Database 23ai addresses security by helping to allow you to keep your content within the database or accessing it from Oracle Object Storage. Further, the transformer can reside in the database, enabling that content and vectors remain under your control and minimizing potential security gaps.
Semantic similarity search takeaways
Here’s a summary of factors to consider if semantic similarity search is right for your application:
- You work with unstructured data, like natural language text, images, or audio, and need to find content that is similar based on semantics (not exact or fuzzy match).
- You can use a prebuilt transformer model as is or fine-tune a transformer with domain-specific content to improve results.
- You need efficient and scalable search.
- Consider your security requirements and potential security gaps when deploying a semantic.
When to use generative AI
Generative AI is a branch of artificial intelligence that focuses on creating or generating new content. This content can take various forms, including text, code, images, audio, and even video. It can produce highly realistic and complex content that mimics human creativity and often works across industries and problem domains. Generative AI enables conversational user interfaces like chatbots and interacting with databases through natural language-to-SQL (NL2SQL) query generation.
One of the most popular forms of generative AI is the Large Language Model (LLM), which can generate human-like responses to natural language prompts. Here, we largely focus on LLMs.
Use case selection: LLMs are incredibly versatile and can be applied to a multitude of use cases. They can, for example, excel at automating tedious tasks, improving productivity, and enhancing customer support. Common applications include content generation for marketing, responding to customer queries, and software development assistance. LLMs are also capable of code generation, language translation, and sentiment analysis, among others.
However, it’s important to be aware of the challenges facing LLM use. These include hallucination, where the model provides factually incorrect responses due to a lack of context or insufficient training data. Additionally, and perhaps obviously, LLMs cannot know about information that was not present in the training data or was created after the model was trained. However, that won’t stop the LLM from producing a response, which can potentially result in false, outdated, or incomplete responses. You may try to specify in your prompt that the LLM should indicate if it doesn’t know an answer, but this does not guarantee such a response.
In general, users need to assess the quality and accuracy of generated results before using them, especially in mission critical areas. The retrieval augmented generation (RAG) technique can help reduce hallunications, as we discuss below.
Performance/scalability: When using hosted generative AI models from AI providers, performance is generally not a concern. The AI providers typically can meet interactive, and even real-time, objectives and can handle a large volume of requests. As examples, consider recent advances in voice-interactive chatbots that can carry on real-time conversations or real-time translations, as well as image and video generation tools. However, if you choose to host your own model, factors such as hardware, software environment, and model size will impact performance and scalability.
Creating generative AI models from scratch requires substantial computing power and memory to process vast amounts of data. As a result, developing such models is typically undertaken by large organizations with significant resources. These pre-trained models are then made available for fine-tuning or immediate use by other users..
Data requirements: When using pre-trained generative AI models, there are minimal input data constraints relative to the type of model, such as whether the model supports text, image, audio, or video, or is multimodal. However, it’s important to consider other limitations of specific models. Consider LLMs. Some LLMs have stricter token limits on input and output than others. Some may perform better on certain tasks, like code generation, due to their training data. Providing prompts or data that make requests that are outside a given model’s scope will likely result in poor or subpar results.
To train an LLM from scratch, large volumes (petabytes) of text data from diverse sources, such as books, news, code, blogs, among others, are typically required. This data undergoes curation and preparation to help enable its usefulness, including removing duplicates, formatting, and tokenization. Similarly, image generation models require potentially millions of images and audio models require thousands of hours of audio.
Reproducibility: Due to the inherent randomness during training and inferencing, Generative AI models may yield reproducible results. Even with the same input, successive invocations may yield different outputs. This is a known feature of the technology, and while parameters, such as temperature, can be set to reduce variability, they cannot be entirely relied upon. Randomness can also result from hardware and software environments that handle floating-point operations and task parallelism/scheduling differently.
Development effort/skills: Developing high-quality generative AI models is a complex task that requires specialized skills and significant development effort. Prebuilt models, such as those provided by major AI providers, may be adequate for many tasks out of the box. However, if you have specific domain or industry requirements, a given generative AI model may have insufficient knowledge to respond to your prompts. This is where fine-tuning can help.
Fine-tuning takes an existing model and uses additional training data such that the model itself assimilates this new data to be better able to respond to prompts. However, fine-tuning also requires specialized skills and careful validation to help the resulting model meet objectives.
In contrast, using generative AI models is much simpler and accessible thanks to no-code interfaces and APIs. LLMs, for example, provide an intuitive natural language interface for users. Getting good results, however, often involves prompt engineering, where prompts are designed and optimized to generate the desired results. Prompt engineering helps a generative AI model better “understand” what the user is asking for. An engineered prompt may include relevant examples to help the LLM produce better results. There are many online resources with guidance on prompt engineering. Other techniques such as retrieval augmented generation (RAG) can also be employed to enhance the performance of LLMs.
It’s important to note that a key challenge in developing generative AI-based solutions is effectively integrating them into existing business processes and tools with adequate human oversite and feedback on the quality of results produced.
Explainability/interpretability: Older generative AI models, especially LLMs, are often considered “black boxes.” While we can use their output, the inner workings and decision-making processes are typically not clear or explainable. This is a trade-off that comes with their creative capabilities.
More recent LLMs strive to allow users to see the reasoning or decision process they undertake when processing a user’s prompt. This can shed significant light on how or why the LLM produced its result and offer guidance for refining your prompt if certain “mistakes” are identified.
Security: Data security is a crucial consideration when using generative AI. Possible concerns for data security occur at several levels: the content used to train or fine-tune the model, the generative AI model(s) themselves, and the prompts supplied to those models.
When working with pre-trained models, the AI provider typically handles the training data. If you choose to train a model from scratch or fine-tune an existing model, you must consider the security of the data used for training and tuning. For example, are you sending data to a third-party environment to train the model.
Protecting the integrity of model themselves is essential to prevent tampering by malicious actor. Use trusted AI providers or host LLMs in trusted environments. Ensure that models themselves are secure and verifiably free from unintended changes.
When using third-party AI providers, consider the sensitivity of the data you are sending with your prompts. If necessary, opt for self-hosting or secure environments to maintain data privacy. AI provider data use policies differ, so verify whether your AI provider will use data for training models.
Enhancing LLMs with Retrieval Augmented Generation (RAG)
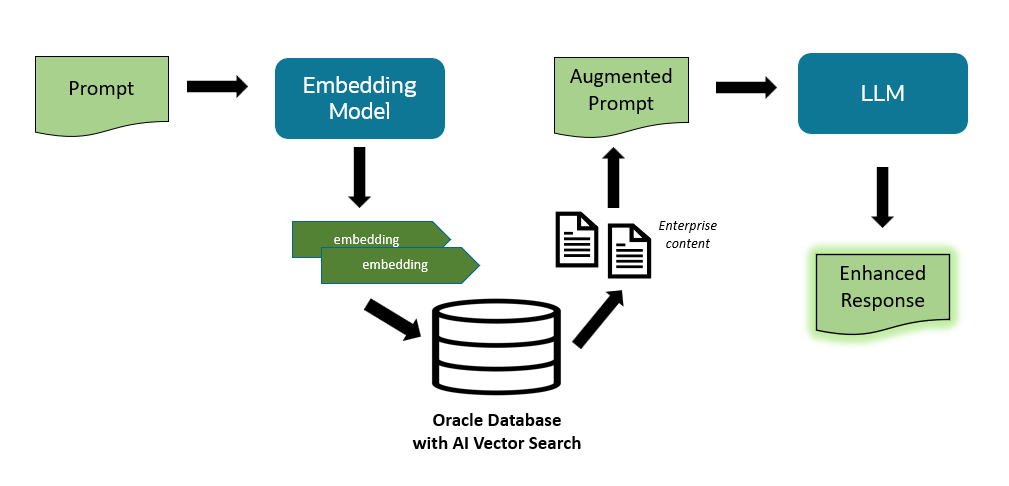
I mentioned retrieval augmented generation (RAG) a few times above for possibly reducing LLM hallucinations and improving LLM responses. Since LLMs have general knowledge – not information specific to your business or you as an individual – you may want to provide such information for the LLM to consider. RAG helps bridge the gap between an LLM’s knowledge and your enterprise data without modifying the LLM itself. RAG combines semantic similarity search with generative AI for more accurate and up-to-date responses from LLMs. The RAG technique involves augmenting the user’s prompt with relevant content retrieved through semantic similarity search to help address the hallucination problem and improve the relevance of LLM responses. The general workflow using Oracle Database 23ai is illustrated below.
As an example, consider the call center optimization use case. Operators can ask questions in natural language based on their customer interaction and quickly receive answers using internal data involving past issue-resolution call logs and product documentation. This enables more accurate and faster resolution, which can lead to increased customer satisfaction. Operators can also potentially handle a higher volume of calls since issue research time can be dramatically reduced.
Combining traditional ML and generative AI
Generative AI can also be combined with traditional machine learning to help create powerful solutions for business problems. For example, you can use clustering models to identify customer segments and then use LLMs to generate targeted messaging for each segment based on cluster centroid definitions. Then, use a classification model to predict which customers are likely to churn. Knowing which customers are likely to churn and the segment each belongs to, the LLM can use this information along with customer demographic data to generate custom e-mails with offers to entice potential churners to stay.
AI Agents
An AI agent is software that can autonomously perform tasks by receiving data to make decisions and take actions toward a specific goal. You can use a variety of AI techniques to implement an agent, which can include LLMs, machine learning, and computer vision.
AI agents range from simple to complex. Simple reflex agents, like “intelligent” thermostats, rely on static rules and inputs and result in specific actions being taken. Goal-based agents evaluate options and actions to determine next steps, possibly using one or more tools that enable taking specific actions, like making a restaurant reservation. Learning agents improve their performance over time by updating their knowledge base – either with data or experience – like a movie recommendation system for common commercial streaming services or medical diagnosis assistants.
Consider a restaurant reservation agent. It may use an LLM to a plan the steps necessary to make a reservation and choose among available tools for carrying out individual steps. Basic input includes date, time, and number of guests as input. The generated steps may include retrieving your preferences for cuisine and cost, identifying relevant restaurants in your area, and sorting those restaurants based on your preferences. Then, it checks each restaurant in sort order if a table is available – stopping when one is found – and asking you to confirm before making the reservation.
Agents are enabled to take real-world online actions to the extent that users are comfortable granting access. Security checks and human-in-the-loop confirmation steps in a solution are needed to minimize errors or unintended consequences of AI actions.
As just discussed above, a key feature of agentic AI systems is that they can operate partially or fully autonomously – be proactive, plan next steps, and adapt to new situations. In contrast, your basic LLM-based chatbot is reactive – requiring a human operator to submit questions and engage in conversation.
AI agents offer potential business benefits, including enhanced efficiency and productivity through automating repetitive tasks – freeing up human workers to address more complex tasks. For example, customer support AI agents can help answer common questions or process refunds. Such agents offer 24/7 availability and scalability as workloads increase. AI agents can also offer the possibility for greater personalized experiences based on individual customer preferences and behaviors.
You can build custom AI agents using programming languages like Python and PL/SQL or frameworks like Phidata, OpenAI Swarm, LangGraph, CrewAI, among others.
Generative AI takeaways
Here is a brief summary of factors to consider when deciding if generative AI is right for your application:
- You require content generation, understanding, or summarization using pre-built models.
- You are more concerned with enhancing application user experience through dynamic, natural language interactions, than hard accuracy, reproducibility and explainability.
- You are open to using a third-party AI provider to host the generative AI model and send your prompts/data to that provider. Alternatively, where data security and model integrity are essential, you can host a generative AI model yourself and provide adequate hardware resources to meet application performance requirements.
- Techniques like RAG and combining traditional machine learning with LLMs can expand the set of use cases you can address with generative AI to achieve business objectives.
Generative AI offers a wide range of opportunities for innovation and improvement across industries. By understanding its capabilities, limitations, and best practices, you can make informed decisions about when and how to leverage this technology to drive value in your specific use cases.
Using models in production
In this section, I’ll discuss various ways of producing and deploying models, along with model representation options and common use cases. When it comes to solution deployment, some approaches are more effective than others when considering application environment, languages/interfaces, or model formats.
Let’s explore three main approaches – each of which can be used in or through your Oracle Database instance:
Native in-database models: These are models built using in-database machine learning algorithms, such as those offered by Oracle Database. This option is ideal when your data resides primarily in the database and the required techniques or algorithms are available in the database. By avoiding data movement between the database and external analytical engines, you can achieve better scalability and performance for model building and batch inferencing. Additionally, reduced solution complexity and fewer potential points of failure make using native in-database ML models a compelling choice. However, depending on data volume, data mapped as external tables or available through DBLINKs can also be used.
In-database ML models offer scoring functions and model detail views from SQL queries. Via SQL, you can combine machine learning with other database analytics – like spatial and graph – to yield scalable and high-performance results without separate analytical engines for each. Through the Oracle Machine Learning for Python and Oracle Machine Learning for R APIs, you can also build and use in-database models from the convenience of Python and R.
If your applications, tools, and dashboards are already integrated with Oracle Database, extending it to include ML models is a natural fit. If you have concerns about resources required to support a team of data scientists against your main database, consider using a database clone with Oracle Database or Oracle Autonomous Database. This allows data science teams to have separate database instances with the same data and their own compute so as not to affect production systems.
ONNX-format models: These are models typically built or obtained elsewhere that, once converted to ONNX format, can be imported to the database as first-class database model objects for use in SQL queries – just like the in-database ML models cited above. The Open Neural Network Exchange, or ONNX, is an open standard for machine learning interoperability.
ONNX specifies a portable model representation or format that enables models converted to ONNX format to run in the ONNX Runtime engine. Oracle supports the ONNX Runtime in Oracle Database 23ai and, on Autonomous Database, OML Services.
You can import ONNX-format embedding models such as text and image transformers, as well as classification, regression, and clustering models, directly to the database. Such models require bundling additional pre- and post-processing steps to enable in-database use.
You can also import classification, regression, clustering, and feature extraction ONNX-format models to OML Services. It’s worth noting OML Services enables importing in-database models using the same REST API, which simplifies and unifies application code.
OML Services is included with and pre-provisioned in Autonomous Database, providing lightweight inferencing via REST endpoints for real-time and streaming applications. Being pre-provisioned, users pay only for actual inferencing compute – no separate VM provisioning or management is involved.
Native Python or R models: Native models built in Python or R can be used through database APIs. This option is attractive when specific techniques, algorithms, or functionalities that are not available in the database but are available through the extensive Python and R ecosystems. By augmenting your database with third-party packages, you can enhance its capabilities and extend the set of possible use cases.
Choose this option when you want to leverage Python or R to build models – whether through the database or using external environments. You can use those models seamlessly within your Oracle Database. Using OML4Py and OML4R, you can store Python and R models in the database using the datastore feature and use these models via embedded execution from Python or R.
In other cases, you may want to build models using the database infrastructure to eliminate data movement but deploy models to non-database environments, such as offline Python or R engines. Or you may need to use GPU compute resources to build models but then bring those models to the database for inferencing from SQL, or on Autonomous Database, also via REST endpoints.
Transformer models can also be used from languages like Python. To vectorize data in batch at scale, you can use the OML Notebooks GPU capability for Python paragraphs and store the resulting vectors in the database for direct use from SQL with Oracle AI Vector Search.
Summary
We’ve covered a lot of ground in this blog. Let’s summarize using a few questions and answers.
Do I need generative AI or traditional machine learning?
Generative AI is a powerful tool for helping to generate creative content, personalize content, summarize documents, and translate text, among other use cases, but currently has limited reasoning capabilities and results often lack explainability or reproducibility.
Traditional machine learning is a more focused, problem-specific approach with better reproducibility and explainability. It supports use cases from customer segmentation and demand forecasting to root cause analysis and predictive maintenance.
When do I use a transformer, and do I need to use it with an LLM?
A transformer is sufficient for information retrieval tasks when combined with semantic similarity search tools like Oracle AI Vector Search. LLMs come into play when you need a unified text response, achieved through the combination of an LLM and a transformer, as enabled via RAG.
How should I deploy my model?
If your application leverages Oracle Database and SQL, deploying ML models directly in the database can be a natural choice, offering a wide range of model types and seamless integration. If your application requires real-time response rates, consider Oracle Machine Learning Services on Autonomous Database Serverless, which provides a REST API.
Text and image transformers can be deployed in Oracle Database to avoid provisioning and managing separate resources or sending data to third-party AI providers.
For large generative AI models like LLMs that require GPU compute for inferencing, using a suitably configured GPU VM compute instance or third-party AI provider can often provide required performance.
If you require native R or Python models, such models can be deployed using (1) a custom VM, possibly leveraging GPU compute for certain types of models, (2) OML Notebooks, again possibly using GPU compute for certain types of Python-accessible models, and (3) embedded execution via OML4Py and OML4R.
Is there a cost/performance difference with LLMs versus traditional machine learning?
Traditional machine learning models are typically significantly smaller and more computationally efficient than LLMs. Costs, however, should be considered at several levels: data acquisition and preparation, model training and evaluation, ease of deployment, and the skills to achieve each of these. Pre-trained LLMs can avoid many of these costs if they align with your use case, but traditional machine learning – serving a targeted use case with adequate project-specific data – can yield more accurate results.
For more information…
See the following resources:
- Blog: Enhance your AI/ML applications with flexible Bring Your Own Model options
- Oracle Machine Learning: documentation, webpage, blogs, LiveLab
- Oracle Select AI: documentation, webpage, blogs, LiveLab
- Oracle AI Vector Search: documentation, webpage, blogs, LiveLab
