We’re excited to introduce the availability of Select AI with support for Retrieval Augmented Generation (RAG) – making it easy to use LLMs to gain insight or generate innovative content based on your private data using natural language prompts. With Select AI RAG, get more relevant responses and responses with up-to-date information to your natural language prompts and queries, while helping to reduce the risk of hallucination. By leveraging Select AI to augment your prompt with your enterprise data, you can bridge the knowledge gap between what the large language models (LLMs) knows and the knowledge in enterprise databases.
Select AI already simplifies and automates using generative AI in combination, whether generating, running, and explaining SQL from a natural language prompt or chatting with the LLM. Now with RAG, you can take your use of generative AI to the next level, conveniently from SQL:
- Create and populate vector stores using your private data via the built-in automated AI pipeline
- Automatically augment your prompt or query with vector store content retrieved through semantic similarity search
- Send this augmented prompt to your specified AI provider and LLM and returning generated results
In this release, Select AI supports RAG using Oracle AI Vector Search, which is a new feature of Oracle Database 23ai.
Select AI RAG
LLMs are built using data from a snapshot in time from a wide range of internet sources. However, they have little or no knowledge of your enterprise, especially if that knowledge is considered private or proprietary. RAG makes this information available to the LLM without requiring model fine-tuning, which can be costly and time consuming.
Select AI RAG integrates vector database content to help deliver more accurate results from large language models (LLMs). Through semantic similiarity search on vectors produced using embedding models, also referred to as transformers, vector databases support fast retrieval of unstructured data such as text and other data formats.
Select AI RAG automates the orchestration steps of transforming a prompt into one or more vectors and performing semantic similarity search on the content in the vector database. Further, use Select AI RAG to automate creating and populating your vector database using your raw data to help get started using this powerful feature.
Contrast Select AI with individual orchestration frameworks like LangChain. Such frameworks allow you to hand-craft techniques like RAG in applications. Select AI simplifies and automates enabling RAG in applications with minimal additional specification – not explicitly coding the RAG technique.
For example, Select AI allows employees to ask questions and get insights from multiple sources across their company through natural language conversations. Select AI RAG performs semantic similarity search between the user’s request and the vectors corresponding to documents in your enterprise data. This may include, for example, your product documentation, competitive analysis reports, annual reports, customer call transcriptions, customer representative interaction notes, and corporate policy documents, among others.
Select AI simplifies each RAG step:
- Connecting to an existing vector store or creating a new vector store
- Populating and updating the vector index with objects for Object Storage on a recurring schedule or triggering events
- Using that vector store to augment the prompt automatically with relevant content, which is then sent to the specified AI provider
- Returning results from the LLM to the user
Next, we’ll look at Select AI RAG in more detail.
Build your vector store
Select AI automates populating your vector store with your content. It chunks documents into appropriate sizes and applies the specified transformer model to produce vector embeddings. Documents can come from data sources such as Object Storage.
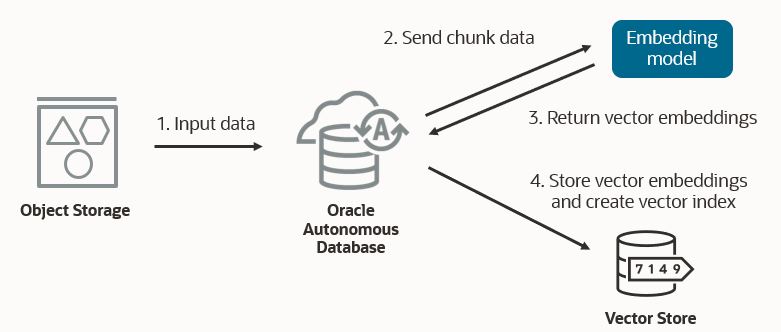
An important feature of Select AI RAG is the integrated automatic update of new data from Object Storage into the vector store. As new data arrives in Object Storage, it is automatically added to the corresponding vector store and the vector index is updated.
Retrieval Augmented Generation
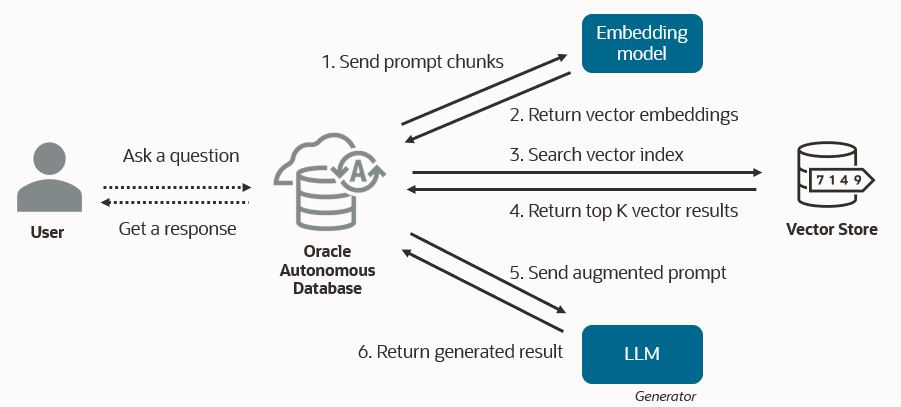
Select AI enables RAG using the ‘narrate’ action in combination with the new vector index specification in the AI Profile. For SQL generation, ‘narrate’ retrieves structured database information using the LLM-generated SQL query and then asks the LLM to generate a natural language description of that result – itself a form of “retrieval augmented generation.” When RAG is enabled with vector indexes, ‘narrate’ instead automatically augments the prompt with vector search results based on the user prompt. It then sends the augmented prompt to the LLM to generate a response using the content retrieved via semantic search.
To see the content retrieved from the vector store upon which the LLM based the response from ‘narrate’, use Select AI’s ‘runsql’ action instead of ‘narrate’ with the same prompt. There is a symmetry between ‘runsql’ and ‘narrate’ for both natural language to SQL generation and the use of RAG. In both cases, ‘runsql’ retrieves data – whether from database tables or the vector store – based on the prompt. Then ‘narrate’ takes that result and sends it to the LLM for a generated natural language response.
Given the prompt, Select AI uses the embedding model and the vector database specified in the AI Profile to perform semantic similarity search for the top k similar vectors. Then, the corresponding document chunks and the original prompt are combined into an augmented prompt, which is sent to the LLM. Select AI handles the full orchestration of the RAG technique.
Using Select AI RAG
The package DBMS_CLOUD_AI has a new procedure CREATE_VECTOR_INDEX, which takes an index name and a set of attributes. These attributes include the vector database provider, a location in Object Storage where the content is stored, the Object Storage credential name, the name of the AI profile that specifies the embedding model, the vector size, distance metric, and your desired chunk overlap and size.
Note that just like the AI Profile has a default LLM, the vector index has a default transformer model. As a best practice, you may create an AI Profile specific to the transformer model you want to use. However, if both the LLM and transformer come from the same AI Provider, you may include both in the same AI Profile object, using a single AI Profile for both.
BEGIN
DBMS_CLOUD_AI.CREATE_PROFILE(
profile_name => 'OPENAI_TEXT_TRANSFORMER',
attributes => '{"provider": "openai",
"credential_name": "OPENAI_CRED",
"embedding_model": "text-embedding-ada-002" }');
END;
BEGIN
DBMS_CLOUD_AI.CREATE_VECTOR_INDEX(
index_name => 'MY_VECTOR_INDEX',
attributes => '{"vector_db_provider": "oracle",
"location": "https:.../my_namespace/my_bucket/my_data_folder",
"object_storage_credential_name": "OCI_CRED",
"profile_name": "OPENAI_TEXT_TRANSFORMER",
"vector_dimension": 1536,
"vector_distance_metric": "cosine",
"chunk_overlap":128,
"chunk_size":1024}');
END;
The CREATE_VECTOR_INDEX procedure creates a pipeline using DBMS_CLOUD_PIPELINE, which triggers the creation of the vector embeddings in a table in the user schema along with the vector index. You can view and monitor the pipeline in the USER_CLOUD_PIPELINES view with the name <vector_index_name>$PIPELINE.
Once the vector index is available, specify the vector index name in your AI profile. Note that in this example the embedding model is explicitly specified in the attributes JSON string. Select AI also allows you to list the sources retrieved from the vector store. This is enabled by default but shown below to highlight.
Create the AI profile with the vector index.
BEGIN
DBMS_CLOUD_AI.CREATE_PROFILE(
profile_name => 'OPENAI_GPT',
attributes => '{"provider": "openai",
"credential_name": "OPENAI_CRED",
"vector_index_name": "MY_VECTOR_INDEX",
"temperature": 0.2,
"max_tokens": 4096,
"model": "gpt-3.5-turbo",
"embedding_model": "text-embedding-ada-002",
"enable_sources": true }');
END;
Now, you can use the ‘narrate’ action. If we had a vector database that contained weather information, we might see results as follows when asking about the maximum temperature in 2023:
EXEC DBMS_CLOUD_AI.SET_PROFILE('OPENAI_GPT');
SELECT AI NARRATE what was the maximum temperature in 2023;
RESPONSE
--------------------------------------------------------------------------------
The maximum temperature in 2023 was 82.1 in August.
Sources:
- SOP_Weather_Current.csv (<bucket>/SOP_Weather_Current.csv)
Notice that Select AI also provides the source document(s) that were retrieved from the vector database and used by the LLM to produce the response.
The corresponding ‘runsql’ invocation provides output:
SELECT AI RUNSQL what was the maximum temperature in 2023; DATA SOURCE URL SCORE ------------------- ---------------- -------------------------------- ----- SOP – This file SOP_Weather_Current.csv <bucket>/SOP_Weather_Current.csv 0.67 contains weather data for 2021-2024 ...
Note that the columns returned from ‘runsql’ when using RAG are always the same.
Key benefits
Select AI RAG offers the following benefits:
- Democratize data access: Remove barriers to using enterprise data. Instead of relying on SQL experts to access and query corporate data stores, simply provide questions in natural language and leverage powerful vector search.
- More relevant results: LLMs can produce more accurate and relevant responses when provided with sufficient context from enterprise data. This helps to reduce LLM hallucinations.
- Current results: The ease of updating vector stores means the data provided to the LLM can be as current as required. There are no cut-off dates on training data sets or costly or time-consuming model fine tuning.
- Simplicity: Select AI automates key steps in the process. Developers don’t need to be experts in generating vector indexes, encoding data, populating a vector store, or developing RAG pipelines. Simply specify where the private data is stored (e.g., html files in object storage) and the transformer model to use when producing vector embeddings.
- Understandable contextual results: Get the list of sources retrieved from vector stores and provided to the LLM. This provides grounding for greater confidence in the LLM results by knowing what source material the response was based on. View the results in natural language text or JSON format to make it easy to extract response components, like sources, for developing applications.
Enables more use cases
RAG enables new use cases across industries and organizations.
- IT: Technicians can get answers to system troubleshooting issues such as “What are likely causes to database error ORA-xxxxx?” faster by querying knowledge bases conversationally instead of combing through support websites and manuals.
- Customer service: Using customer history and product information, respond to questions like “How do I fix a broken feature on my newly purchased item?” with personalized, relevant responses that can improve customer experience.
- Finance: Based on market movements, analyst reports, and other economic indicators, provide tailored snapshots of key developments to financial advisers who manage customer relationships.
Summary
Select AI RAG transforms how you can get answers to pressing business questions. Where data-driven decision making is more important than ever, Select AI RAG helps to make valuable and current enterprise data available with generative AI and can improve productivity and support developing AI-powered applications.
Resources
For more information, see the following and try Select AI RAG through Oracle LiveLabs today!
Blogs
- Introducing Select AI Natural Language to SQL on Autonomous Database
- Announcing Select AI with Azure OpenAI Service on Autonomous Database
- Announcing Select AI on Autonomous Database with OCI Generative AI Service
- How to help AI models generate better natural language queries
- Conversations are the next generation in natural language queries
- Accelerate innovation with enterprise data, OCI Generative AI, and enhanced security
- What is Retrieval Augmented Generation (RAG)?
Documentation
LiveLabs
