Previous Articles of the series:
From Chaos to Order
Have you ever wondered how databases can ensure data consistency in a concurrent environment? Optimistic and pessimistic concurrency control are two fundamental approaches that tackle this challenge head-on. With optimistic concurrency control, the system assumes that conflicts between transactions are rare and allows them to proceed concurrently until they attempt to commit changes. On the other hand, pessimistic concurrency control takes a cautious approach by acquiring locks on resources before any operations can be performed. In this article, we will delve into the intricacies of these two concurrency control models, exploring their advantages and disadvantages while examining different implementation strategies.
Optimistic concurrency control (OCC)
Optimistic concurrency control (OCC, also called optimistic locking) is commonly used in the database world to handle concurrent transactions. Unlike pessimistic concurrency control, which locks data resources before performing any operation, OCC takes a more lenient approach by allowing multiple transactions to proceed simultaneously, assuming that conflicts are unlikely to occur. Subsequently, a record is locked only when changes are committed to the database. This technique relies on the idea that conflicting updates can be detected and resolved at a later point in time.
One of the main advantages of OCC is its ability to achieve higher scalability and performance compared to the pessimistic approach. Since it allows multiple transactions to operate concurrently without acquiring locks, it minimizes contention over shared resources and reduces the chances of causing deadlock situations. Additionally, this approach avoids unnecessary delays caused by locking mechanisms, resulting in improved overall system throughput.
However, being inherently optimistic also comes with its downsides. OCC might lead to many aborts and retries when conflicts frequently occur between concurrent transactions. This can impact application performance and introduce overhead due to additional processing required for conflict resolution. Moreover, relying solely on post-detection conflict management means inconsistent data may be present temporarily during transaction execution.
Pros of optimistic concurrency
- Higher levels of scalability and performance;
- Great for scaling applications;
- Access for multiple users.
Cons of Optimistic Concurrency
- It does not guarantee deadlock avoidance;
- This might lead to a significant number of aborts and retries (Which could lead to loss of revenue);
- Inconsistent data may be present temporarily during transaction execution;
- It requires manual implementation of concurrency handling systems (in other words, your application needs to be changed to handle all concurrency conflicts instead of the database handling them; we will talk more about this later in the post).
Optimistic concurrency implementation
In practice, OCC relies on a mechanism called optimistic locking. Each transaction accessing shared data maintains a version number or timestamp of the data it reads. When a transaction wishes to write back its changes, it checks whether the versions of the data objects have been modified since they were read. If no updates have occurred, the changes are committed successfully; otherwise, the transaction is rolled back and re-executed with fresh copies of the conflicting data.
When to use optimistic concurrency
As mentioned before, one key advantage of optimistic concurrency is its ability to enhance system throughput. By allowing transactions to operate concurrently without unnecessary blocking, OCC reduces the time spent waiting for locked resources. This can significantly improve a database system’s efficiency and responsiveness, especially when contention levels are relatively low.
Furthermore, OCC offers greater flexibility compared to pessimistic methods. With OCC, conflicts are detected only when transactions attempt to commit changes rather than during execution. In cases where conflicts occur infrequently or have a limited impact on data consistency, this approach can provide better performance as it avoids unnecessary overhead associated with locking and unlocking shared resources.
In conclusion, while optimistic concurrency control offers numerous benefits, such as improved scalability and reduced contention, it has drawbacks. Its effectiveness heavily depends on specific use cases and workloads within an application’s context. By considering these factors carefully when designing databases or applications handling concurrent operations, developers can make informed decisions about whether or not adopting this technique will yield optimal.
Pessimistic concurrency control (PCC)
Pessimistic concurrency control (PCC, also called pessimistic locking) is widely adopted in handling concurrent database operations. It aims to prevent conflicts among concurrent transactions by acquiring locks on data items before use. This technique assumes that conflicts are likely to occur and, therefore, takes a cautious approach. Although it ensures data consistency, pessimistic concurrency control comes with its own set of challenges.
One primary challenge of pessimistic concurrency control is the potential for increased latency due to lock contention. When multiple transactions hold locks on the same data item, other transactions that require access to this item must wait, leading to performance degradation. Moreover, if a transaction fails or gets terminated before releasing its lock, it can result in deadlocks where conflicting transactions indefinitely wait for each other’s resources.
Despite these challenges, PCC has its strengths. It guarantees serializability by preventing conflicts between read and write operations and ensuring strict isolation levels between transactions. Additionally, it allows explicit resource locking and predictable behaviour during high-concurrency scenarios. With careful management and consideration of application requirements, pessimistic concurrency control can efficiently handle database operations and maintain data integrity in highly concurrent environments.
Note: Perfection is a myth when discussing technologies, as trade-offs are always required. For example, those that need the best performance and scalability often have to compromise consistency and integrity. Performance, scalability, availability, and consistency are also routinely scoped in the context of specific applications and use cases, such as different failure scenarios (i.e., instance failure versus massive power outage). You must constantly evaluate the cost-benefit of any technology and decide on the correct one per your business needs (i.e., SLAs – Service Level Agreements, RTOs – Recovery Time Objectives and RPO – Recovery Point Objectives) and overall requirements.
As mentioned before, the PCC method introduces locks in transactions to protect data integrity, so what are the types of locks within it?
The two main different lock types with PCC are:
- Shared locks – A lock used to block write operations for data that was read to be changed (updated). These locks do not impact other read operations;
- Exclusive locks – A lock that blocks both read and write operations, forcing all transactions to be executed in sequential order.
Pros of pessimistic concurrency control:
- Integrated database support (The database, not the application, manages concurrency control);
- Blocks conflicts when the transaction is initiated;
- Prevents conflicts between read and write operations;
- Ensure strict isolation levels between transactions;
- Simple and easy to implement.
Cons of pessimistic concurrency control:
- Performance issues may occur if lock time is high;
- Deadlocks may occur; the application and data models must be correctly implemented;
- Application scalability may be limited;
- Not supported by databases across the board;
- Resource consumption can be high due to locking and downtime;
- It cannot be used in a stateless model.
Implementing pessimistic concurrency control
By placing locks on the data items, PCC guarantees that conflicts will not occur if transactions follow specific protocols. However, this approach may decrease system performance as transactions might have to wait for locks to be released by other processes.
Another important consideration when using PCC is deadlocks – situations where two or more transactions wait for each other to release their locks and cannot proceed further. Dealing with deadlock detection and resolution can add complexity to the system and require careful design choices.
Implementing PCC ensures strong data integrity by preventing conflicting access to shared resources. However, developers must carefully assess its impact on performance and make appropriate design decisions considering potential deadlocks.
When to use pessimistic concurrency control
Pessimistic concurrency control is excellent for applications with challenging data requirements (i.e., simultaneous manipulation of data accessed by multiple users) because it prevents conflicts when initiating transactions. Therefore, transactions will not have to be recalled after making substantial progress, which could be problematic for many applications. In simpler terms, pessimistic concurrency control is routinely recommended when the cost of implementing locks is less than losing a transaction (rollback).
Looking at it from another perspective, pessimistic concurrency control methods don’t scale quite as quickly as the focus is on ensuring the data records are not changed during the transaction process, so you’ll need to ensure that the selected database has integrated functionality to scale with pessimistic concurrency control enabled. For example, the Oracle Database has Real Application Cluster (RAC), which has evolved over the years to ensure scalability and high availability while still providing the benefit of pessimistic concurrency control with built-in automation. This is a situation where a particular database can provide both, but the solution is not without some complexity regarding the deployment. The bottom line is that innovation is required to allow the application to “have its cake and eat it, too, ” so to speak.
Choosing a concurrency control mechanism
Please remember that your choice requires trade-offs between balancing performance and consistency when deciding between pessimistic and optimistic concurrency control. Optimistic concurrency control is often considered faster. It provides elevated performance activity if you are willing to restart transactions if data integrity conflicts occur. Pessimistic concurrency control is excellent for an application with many updates and users using the application simultaneously attempting to update data frequently (maintaining consistency). Pessimistic concurrency manages all conflicts and automatically maintains your data integrity for both reads and writes.
So, optimistic concurrency control is excellent if the chances for conflicts run low (for example, if there are several data records but a small number of simultaneous users or minimal updates in combination with multiple read operations) or rolling back (losing) a transaction is not expensive for your business.
Most DBMSs (Database Management Systems) can run transactions using OCC and/or PCC. Always check the default concurrency control mode in use, and also remember to check the isolation being used, as this combination can seriously affect your application behaviour and impact many of your business goals.
Complementing the previous information in my last article about the four transaction isolation levels defined by ANSI/ISO SQL, it is also essential to understand that the outcomes for a transaction scenario could change based on the isolation level used, as the isolation level determines the degree to which one transaction is isolated from the effects of other concurrent transactions.
The four isolation levels defined by ANSI/ISO SQL can be impacted by three circumstances that are either permitted or not at a given isolation level, they are:
- Dirty reads: occurs when a transaction reads data that another uncommitted transaction has modified. This can lead to inconsistent and incorrect results as data integrity is compromised, foreign keys are violated, and unique constraints are ignored;
- Non-repeatable reads: this is where a transaction retrieves a set of data, and when it tries to retrieve the same data again, it finds that another transaction has modified or deleted it, leading to potential data integrity issues;
- Phantom reads: occurs when a transaction reads a set of rows that satisfy a specific condition. Still, that condition is no longer satisfied when the transaction tries re-reading the same row set later; for example, somebody added new data, and now more data satisfies the transaction query criteria than before.
Below, you can find a matrix table based on each SQL isolation level and whether they permit the occurrence of any of the circumstances mentioned above.
| The 4 Isolation Levels |
Dirty Reads (1) |
Non-repeatable Reads (2) |
Phantom Reads (3) |
| READ UNCOMMITTED |
Permitted |
Permitted |
Permitted |
| READ COMMITTED |
— |
Permitted |
Permitted |
| REPEATABLE READ |
— |
— |
Permitted |
| SERIALIZABLE |
— |
— |
— |
It is important to note that the SQL standard doesn’t impose a specific locking scheme or mandate particular behaviours. Instead, it describes these isolation levels against the previously mentioned circumstances, allowing many different locking/concurrency mechanisms to exist (like OCC and PCC).
Oracle’s continuous innovation, a non-stop effort
Continuing its mission to make operating and securing the Oracle database simpler, the recently released 23c database has incorporated two essential new, less well-known features that are relevant to the topic of this post, which you should be aware of including:
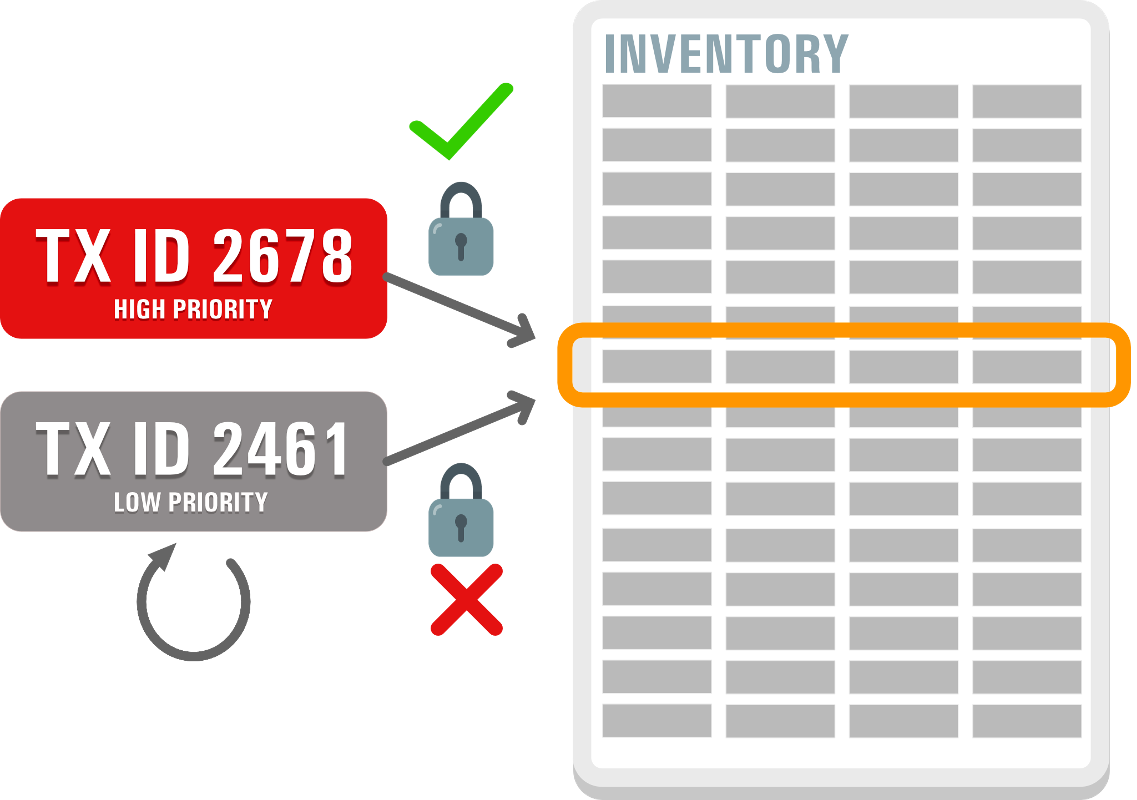
Priority Transactions:
Priority Transactions automate aborting a low-priority transaction that holds a row lock that blocks a high-priority transaction.
How it works:
- A new parameter sets the priority (HIGH, MEDIUM, LOW) of a user transaction;
- Users can configure the maximum time a transaction will wait before aborting a lower-priority transaction holding a row lock.
Benefits:
- Reduces the administrative burden for DBAs ;
- Maintains response time and transaction throughput for high-priority transactions.
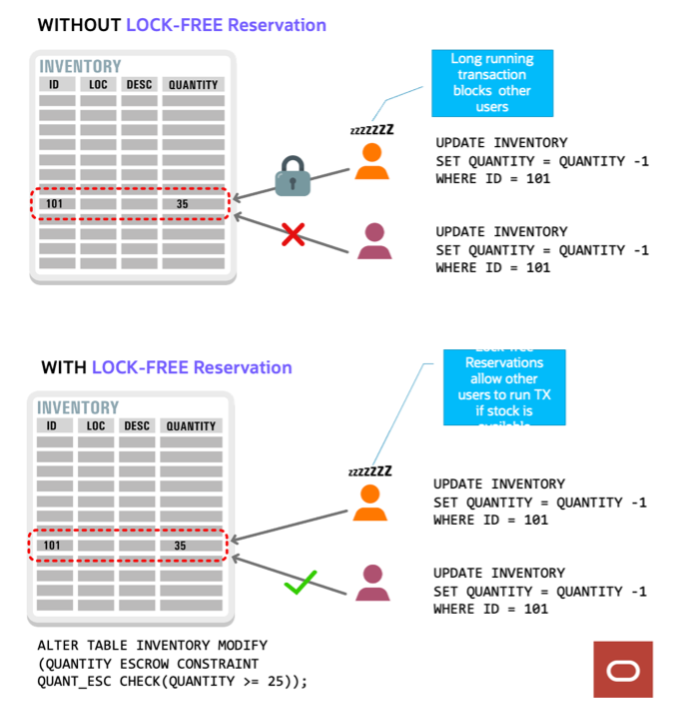
Lock-free Column Value Reservations:
With Lock-free Reservations, multiple transactions can make reservations to the same column value, like:
| For example, a shopping app can reserve inventory for an item when the item is put in a shopping basket without preventing other shoppers from purchasing the item;
|
|
Summary
When we look at optimistic concurrency control, we see a practical, reliable system. It works well with loose isolation levels such as a “repeatable read” isolation level; however, issues can be introduced, such as phantom reads, unlike pessimistic concurrency control. Optimistic concurrency control requires the application to be designed to manage potential read and write conflicts, which may require significantly more development effort. The most common conflict types are:
- Read-Write conflict: When transaction A reads data in a row, another transaction (B) modifies data in the same row or updates data in a row, and then transaction A reads the data in the same row. In this case, the data read by transaction A would be different. This type of conflict may lead to a non-repeatable and dirty read.
- Write-Read conflict: The cause of this type of conflict is the same as the read-write conflict, and it may lead to a possible dirty read.
- Write-write conflict happens when two operations try to write to an object in sequence. The result of the latter operation would determine the final writing result, and it could lead to an update being lost (The mystery of the lost update).
An example would be a situation where a data system using optimistic concurrency control spurs a recall or rollback when it catches an OptimisticLockException, which routinely happens at the point where the commit is attempted. All work done by the currently running transaction is lost when this occurs. The application often has no option but to request that the user try again later.
With more conflicts comes a higher chance of transactions failing; repeals and rollbacks cost the business reliant on such systems money due to the lost transactions (that could also lead to lost customers and brand impact), as when asked to re-attempt the interrupted and lost transaction, users may assume the application is not explicitly designed to deal with these situations. In addition, a data system using this approach often depends on many table rows and index records to compensate. Therefore, the best choice is to use the appropriate concurrency control that fits the application’s requirements, as indicated in the previous sections.
What’s Next
This is the second series of articles that clarifies critical concepts before discussing some interesting emerging technologies. In the following article, I will discuss the “speed of the light” scenario and its impact on your data integrity, availability and recoverability.

