The IT business and the database market evolve in cycles with a tendency to form an upward spiral. Every once in a while, an idea or a technology, which is not entirely new, moves back into the focus but has evolved since the first time it appeared. The recent tendency of certain primarily cloud vendors to offer database solutions based on a database-aware infrastructure, in which “intelligent storage” processes database-specific IO, is an example of such an idea. The question is, are we at the cycle’s beginning or end?
An Overview of a Resurfaced Idea
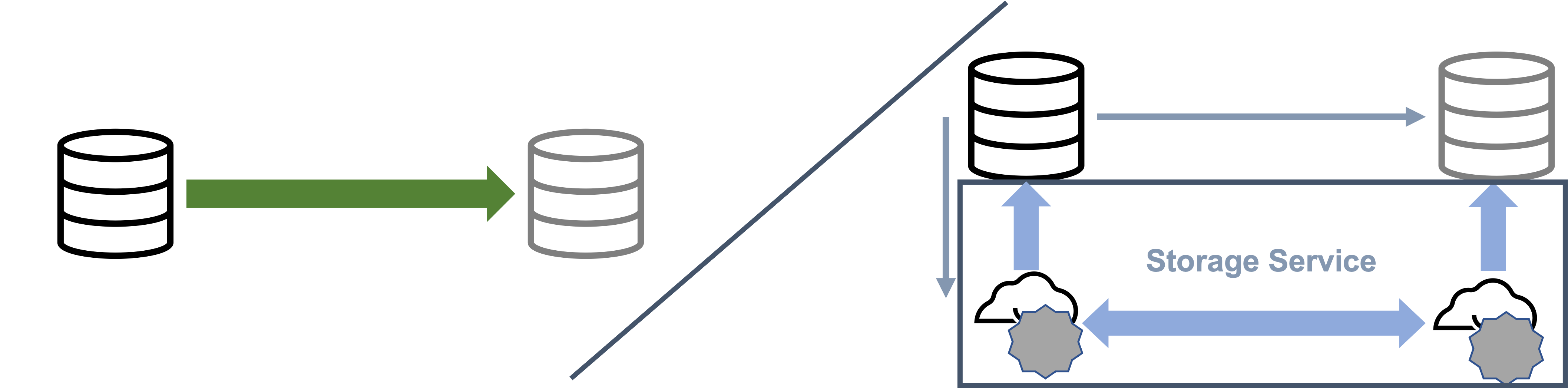
The motivation for the new trend, as stated in Amazon Aurora: Design considerations for high throughput cloud-native relational databases is: “In modern distributed cloud services, resilience and scalability are increasingly achieved by decoupling compute from storage and replicating storage across multiple nodes.” The idea is to “Move logging and storage off the database engine.” The simplified summary is “The log is the database.”
Interestingly, the same idea has been picked up by two primarily cloud vendors, Amazon and Google. In contrast, database vendors do not seem to embrace the concept, as Google indicated when announcing: “AlloyDB for PostgreSQL: Free yourself from expensive, legacy databases,” which, not surprisingly, uses “Intelligent, database-aware storage“. Perhaps database vendors know something that Google and Amazon have yet to find out?
The commonality between both solutions is that they make the Write Ahead Log (WAL) the primary persistence layer of the database so that they can use a dedicated, specialized storage service to materialize data changes on demand. While this arguably helps make writes faster in the one instance allowed to make changes, it certainly makes them less valuable. In such an approach, writes will only be meaningful on read replicas “on-demand,” which is a friendlier way of saying that the actual pages of data will be assembled when requested. On-demand materialization creates an overhead, especially in the case of high-frequency changes. Both solutions send the WAL directly to the read replicas, which amplifies writes and often requires caches on the replica side to enable a suitably fast on-demand data materialization.
According to Google and Amazon, the purpose of the WAL application in the storage tier is to provide read replicas faster and enable storage-based backups (as if this was not possible otherwise). Both vendors also see a benefit in streamlined IO as full-page writes are not required at the moment of a low-latency WAL write (which is the case for Oracle Database, too). Instead, the WAL write is synchronously replicated on storage level across “different storage zones” to increase availability and then asynchronously applied to the respective page(s) later.
Sounds familiar? Of course, it does: To mirror, or not to mirror, that’s the question – although it is not a question, as all Oracle Database users will know. The best Disaster Recovery protection (based on Oracle’s Maximum Availability Architecture (MAA) experience) is provided by database-inherent replication in which the database layer is used to manage redo generation, shipment, and application, as this ensures the most efficient and secure (protection against data corruption) means of replication.
Database Vendors Disagree
It is not often that competitors agree, but for what it’s worth, MariaDB’s Curt Kolovson made some excellent points when arguing that: “The problem that both Aurora and AlloyDB must deal with when having to retrieve a piece of the database that is not already materialized in cache is that it must be reconstructed from the WAL. This is a costly operation that requires fetching a block from the WAL based on a log sequence number (LSN) and data page number.” He even called Amazon’s Aurora and Google’s AlloyDB “LemmingDB’s – the blind leading the blind, joining a long list of database products that position themselves as “PostgreSQL-compatible” in one way or another.”
From a pure Oracle perspective, having invented the poster child example of “intelligent storage”, Oracle Exadata Storage, the idea to offload certain IO-bound operations is not new. However, the main idea of IO offloading in the case of Exadata Storage is not to offload redo log apply, as this has never been an issue on either generic or Engineered Systems.
There is only one feature designed to optimize redo log writes in Exadata – Exadata Smart Fusion Block Transfer – and this feature has a very different purpose. With Smart Fusion Block Transfer, the latency of redo log writes at the sending node is eliminated. The block is transferred as soon as the IO to the redo log is issued at the sending node without waiting for it to complete, which increases throughput by about 40% and decreases response times by 33% for RGI (Right Growing Index) workloads.
In other words, Exadata Smart Fusion Block Transfer is a performance optimization feature to avoid write bottlenecks in an active-active Oracle Real Application Clusters (RAC) database in which case such optimization makes sense. It does not jeopardize either High Availability (HA) or Disaster Recovery (DR) (usually provided by Data Guard), nor does it prevent independent storage scaling, as it works very well in the context of Oracle Exadata, including the independent scaling of storage and compute.
Compared to Aurora’s and AlloyDB’s approach, however, it provides an optimization for fully active-active environments, in which each database instance is capable of writing and reading data. The Buffer Caches (in-memory data buffers) are updated immediately should a change in one instance require invalidation. At the same time, reads and even writes can easily be scaled by adding additional nodes or storage to the cluster (depending on the scaling needs) utilizing Oracle RAC’s Cache Fusion protocol as discussed in “Scaling Paypal OLTP workloads with Oracle Real Application Clusters.”
Not Worth the Hassle
Overall, it is unclear what additional benefits Amazon’s Aurora and Google’s AlloyDB using the “intelligent storage approach” provide over traditional solutions. Not only are they databases that only claim to be Postgres-compatible (they are arguably not, but others can make that point), but they also seem to provide a solution that the PostgreSQL community hasn’t necessarily waited for, as the benefits they offer are already and more flexibly available via existing add-on solutions.
From a general point of view, these databases are “not worth the hassle”. They are not worth the hassle of moving to a database that inherits the disadvantages of any storage mirroring solution, but only serves a Postgres-compatible database that is so cloud-native that it cannot be ported to any other cloud, as it would be missing the storage services required to run it (which seems to be against the paradigm of an open-source database). If one then considers that there are several well-proven database solutions available on the market for customers to choose instead, one wonders why customers would consider such proprietary solutions in the first place.
Take Data Guard, for example. Oracle Data Guard and Active Data Guard have long provided answers for the Oracle Database to problems Amazon’s Aurora and Google’s AlloyDB try to solve with the new approach. Data Guard uses an over-the-network and in-memory application of redo information in addition to persisting redo on disk. This allows users to configure a balance between data protection, including an option to configure a “zero data loss guarantee”, and performance. Using Far Sync, the same performance can be guaranteed independently of distance. This approach is proven to work for Disaster Recovery and allows for offloading backups and read-only workload to a replication site. Since Oracle Active Data Guard 19c, even updates on standby are supported.
In addition, Oracle Cloud has already solved the scaling problem that Aurora and AlloyDB address using “intelligent storage”. For “ad-hoc scaling of reads” that cannot be addressed with database caches (also in Oracle’s portfolio), Oracle Data Guard can be set up to benefit from cloud scaling. Cloud scaling allows a Data Guard Standby database on Oracle Cloud to be “scaled up” as demand requires it, even in different regions. The initial Data Guard Standby database is set up in this configuration to receive and apply redo information. If disaster strikes, cloud capacity is increased to handle the complete production workload on the cloud as a Disaster Recovery system. However, any time in between, cloud scaling can be used to accommodate reporting and testing on the standby database in the cloud.
Regarding “testing”, Oracle Data Guard also enables spontaneous, complete application testing, including writes. Using Data Guard Snapshot standby, a Data Guard physical standby database can be temporarily and via a 1-click operation, converted into a test database that is open read/write. Once testing is done, changes made to the standby database while open read/write are discarded and regular operation (redo log apply) is resumed. The redo information from the primary archived on the standby during testing will then be applied until the standby database has fully caught up. To allow for Disaster Recovery during such operations, more than one standby database can be linked to a primary Data Guard database.
Both and more use cases are covered in “Oracle Active Data Guard: Disaster recovery tips and tricks“.
Conclusion
The idea to offer database solutions based on a database-aware infrastructure in which (an) “intelligent storage” (service) is used to process database-specific IO is not new. Using this idea to apply redo in the storage tier seems misapplied, given the risk it entails and the fact that use cases that would benefit from this approach are minimal, especially given the number of proven, alternative solutions that can be used instead. As far as certain primarily cloud vendors offering such a solution are concerned, the idea is part of an early cycle that will lead to a new level of database solutions. As far as database vendors are concerned, this idea adds to a late-cycle that has already introduced cloud-native databases that cannot be ported and are otherwise limited in their compatibility.
