In this blog, the third in a series of three, Oracle Linux developer Jag Raman analyzes the performance of the disaggregated QEMU.
Performance of Separated LSI device
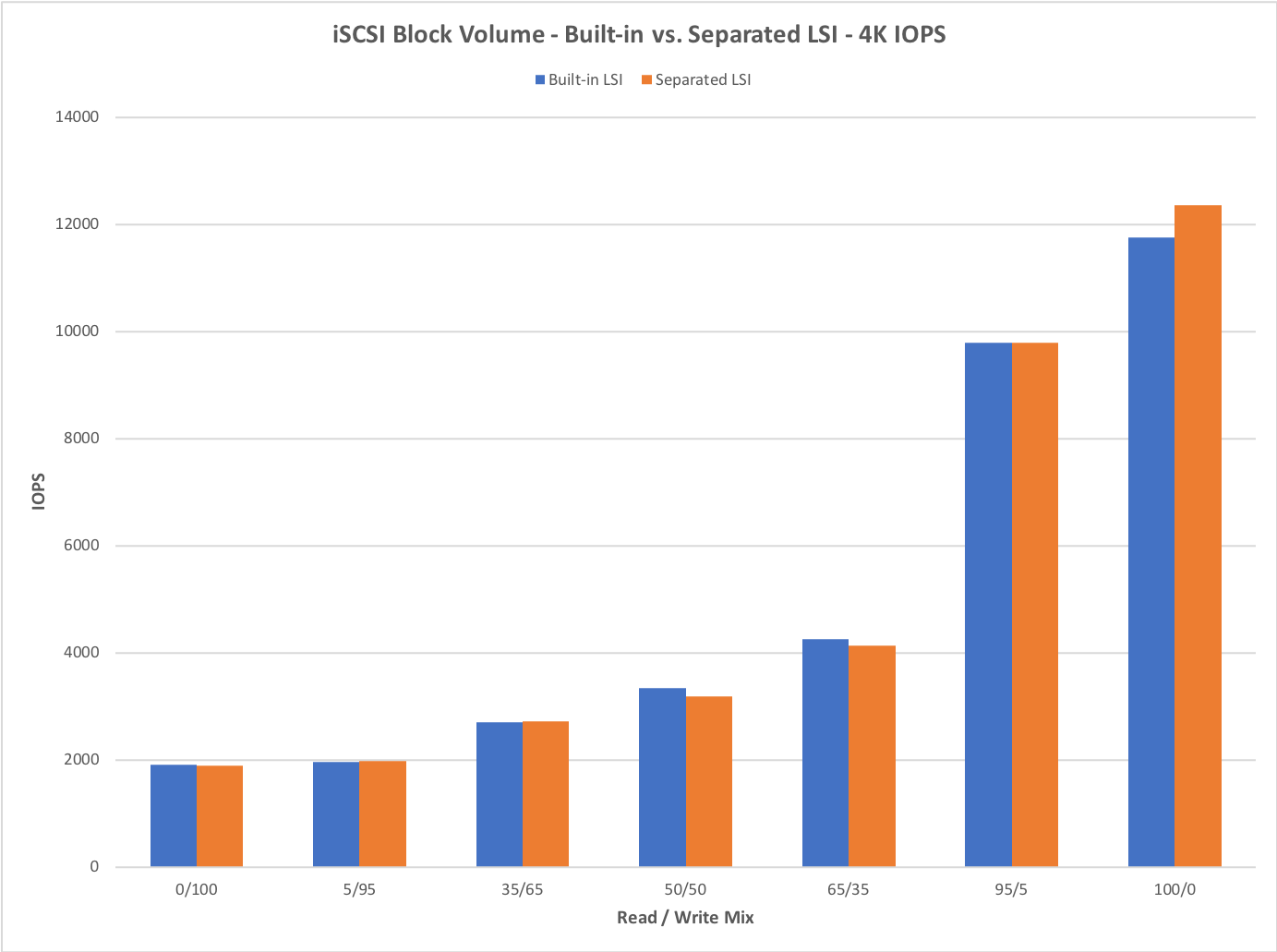
It is essential to check how the Separated LSI device performs in comparison with the LSI device built into QEMU. For this purpose, we ran CloudHarmony block-storage benchmark on both. We ran this benchmark on a BareMetal instance in Oracle Cloud. The results are summarized below.
CloudHarmony results
For detailed CloudHarmony report, see the following performance reports:please follow the links below:
- Performance of Built-in LSI device (pdf)
- Performance of Separated LSI device (pdf)
- Built-in LSI vs. Separated LSI
Analysis of Performance
The Separated LSI device performs very similarly to the Built-in LSI device. There are some cases where there is a gap between them. We are working on improving our understanding of why this is the case, and have detailed proposals available to bridge the gap. Following is a technical discussion of the performance problem and plans to fix it.
Message passing overhead
The current model for multi-process QEMU uses a communication channel with Unix sockets to transfer messages between QEMU & the Separated process. Since MMIO read/write is also passed as a message, there is a significant overhead associated with the syscall used to move the MMIO request to the Separated device. We believe that this overhead adds up, especially in the cases where the IOPS are large, resulting in a noticeable performance drop. The following proposal tries to minimize this overhead.
MMIO acceleration proposal
The majority of data transfer between the VM & Separated process happens over DMA (which has no overhead). However, MMIO writes are used to initiate these transfers, and MMIO reads are used to monitor the status/completion of IO requests. We think that in some cases, these MMIO accesses could contribute to the IO performance. Even small overhead per MMIO could cumulatively result in a performance drop, especially in the case of high IOPS devices. As a result, it is essential to reduce the amount of this overhead, as much as possible. We are working on the following proposal to accelerate MMIO access.
The proposal is to bypass QEMU and forward all the MMIOs trapped by Kernel/KVM directly to the Separated process. Secondly, a shared ring buffer would be used to send messages to the Separated process, instead of using Unix sockets. These two changes are expected to reduce the overhead associated with MMIO access, thereby improving performance.