Journals are critical for ensuring the consistent state of filesystems – we do not want a crash or shutdown to render our filesystem unusable. To avoid this, a journal is employed. A journal restores a filesystem to its last consistent state in case of a crash. It maintains an on-disk log of changes that are made to the filesystem. Changes are initially written to the journal log, and only after a successful write, they are then checkpointed to their final destinations. In the event of a crash, the journal log is replayed to recover the filesystem.
JBD2 (Journaling Block Device 2) is a journaling layer employed in filesystems like ext4 and ocfs2.
JBD2 operates in three different modes:
data=orderedmodedata=journalmodedata=writebackmode
The default behavior is data=ordered, where only the metadata is journaled. In this case, it is not gaurenteed that file data blocks will be in a consistent state after a crash. In data=journal mode, both the data and metadata are journaled. Finally, in data=writeback mode, dirty data is not written to the disk until the metadata is checkpointed to the disk through the journal.
In this blog, we will go through the on-disk layout of the JDB2 journal log and the associated data structures.
JDB2 High-Level Design
In general, the journal is placed in the middle of the disk. The size of the journal log depends on the filesystem size. The larger the filesystem, the larger its journal log size.
For an ext4 filesystem, the table below gives the journal size for various filesystem sizes.
Table 1
Any block in the journal log can be identified as one of the following:
- Journal Superblock
- Descriptor Block
- Data Block
- Commit Block
- Revocation Block
Leaving data blocks aside, the first 12 bytes of all other blocks in the journal are used by a common header journal_header_s.
typedef struct journal_header_s
{
__be32 h_magic; /* magic number 0xC03B3998 */
__be32 h_blocktype; /* determines type of journal block */
__be32 h_sequence; /* Transaction ID that goes with the block */
} journal_header_t;
This header differentiates various types of blocks.
- The
h_magicfield is used to differentiate the data blocks from other types of blocks. - The
h_blocktypefield determines the block type. - The
h_sequencegives the transaction ID that the block belongs to.
Data blocks contain only data, therefore no header is present in them.
The table below gives the value of h_blocktype corresponding to each block type:
Table 2
Now let’s have a look at each block type in detail.
Journal Superblock
The journal superblock is the 1st block in the journal log, and it holds important metadata information.
typedef struct journal_superblock_s
{
/* 0x0000 */
journal_header_t s_header;
/* 0x000C */
/* Static information describing the journal */
__be32 s_blocksize; /* journal device blocksize */
__be32 s_maxlen; /* total blocks in journal file */
__be32 s_first; /* first block of log information */
/* 0x0018 */
/* Dynamic information describing the current state of the log */
__be32 s_sequence; /* first commit ID expected in log */
__be32 s_start; /* blocknr of start of log */
/* 0x0020 */
/* Error value, as set by jbd2_journal_abort(). */
__be32 s_errno;
/* 0x0024 */
/* Remaining fields are only valid in a version-2 superblock */
__be32 s_feature_compat; /* compatible feature set */
__be32 s_feature_incompat; /* incompatible feature set */
__be32 s_feature_ro_compat; /* readonly-compatible feature set */
/* 0x0030 */
__u8 s_uuid[16]; /* 128-bit uuid for journal */
/* 0x0040 */
__be32 s_nr_users; /* Nr of filesystems sharing log */
__be32 s_dynsuper; /* Blocknr of dynamic superblock copy*/
/* 0x0048 */
__be32 s_max_transaction; /* Limit of journal blocks per trans.*/
__be32 s_max_trans_data; /* Limit of data blocks per trans. */
/* 0x0050 */
__u8 s_checksum_type; /* checksum type */
__u8 s_padding2[3];
__u32 s_padding[42];
__be32 s_checksum; /* crc32c(superblock) */
/* 0x0100 */
__u8 s_users[16*48]; /* ids of all fs'es sharing the log */
/* 0x0400 */
} journal_superblock_t;
The following is a hex dump of the journal superblock:

Note: Contents of logs are written to disk in big-endian order, irrespective of the host filesystem’s endianness.
As already mentioned, the first 12 bytes are used by struct journal_header_s. The value of journal_header_s->h_blocktype is 0x4 indicating that the journal is using V2 of Journal Superblock (See Table 2).
Graphical View of the Journal Log
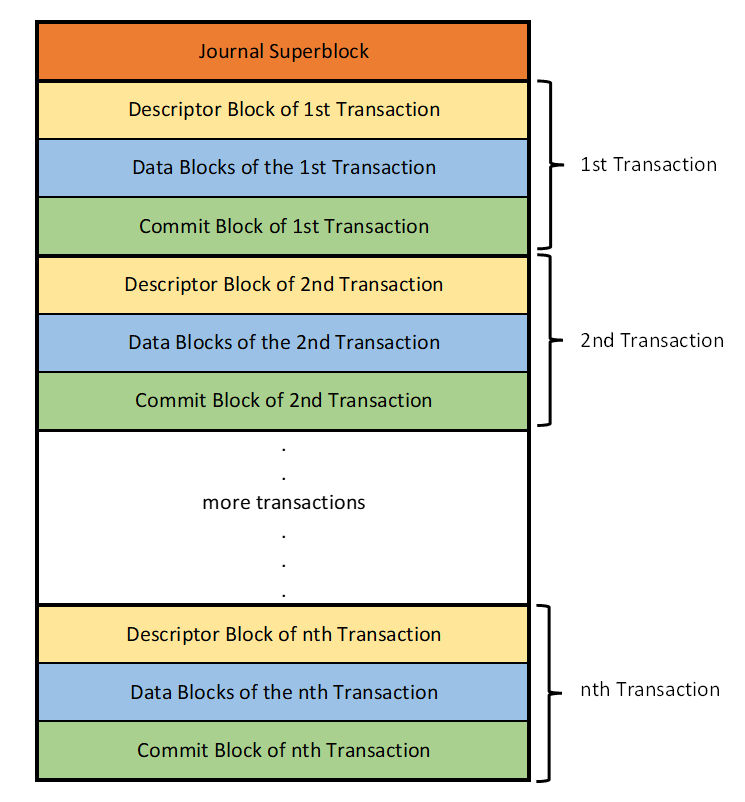
In the journal log, the superblock will be followed by a series of transactions. Each transaction comprises of a descriptor block, data blocks, and a commit block. A transaction starts with a descriptor block, then followed by data blocks, and at the end, one can find a commit block. Commit block marks the end of the transaction.
Note: A transaction can have multiple descriptor blocks (discussed in the next section) and multiple data blocks but only a single commit block.
Descriptor Block
The first thing in a descriptor block is journal_header_s which has the magic number, h_blocktype field in the header is set accordingly to identify the block as the descriptor block. Following the header there will be the array of journal block tags which store the final location of data blocks of the transaction.
If JBD2_FEATURE_INCOMPAT_CSUM_V3 is set in an incompatible feature set, then journal_block_tag3_s will be used otherwise journal_block_tag_s will be used.
typedef struct journal_block_tag3_s
{
__be32 t_blocknr; /* The on-disk block number */
__be32 t_flags; /* See below */
__be32 t_blocknr_high; /* most-significant high 32bits. Only used when INCOMPAT_64BIT is set */
__be32 t_checksum; /* crc32c(uuid+seq+block) */
} journal_block_tag3_t;
typedef struct journal_block_tag_s
{
__be32 t_blocknr; /* The on-disk block number */
__be16 t_checksum; /* truncated crc32c(uuid+seq+block) */
__be16 t_flags; /* See below */
__be32 t_blocknr_high; /* most-significant high 32bits. */
} journal_block_tag_t;
Each data block in the transaction has its corresponding tag in the descriptor block. Therefore, the number of tags in the descriptor block will be equal to the number of data blocks in the transaction. With that said, when a transaction has N number of data blocks, then there will be N tags corresponding to each data block, in case these N tags don’t fit in a single descriptor block then a new descriptor block will be used to hold the remaining tags. In this type of case, a transaction will have multiple descriptor blocks.
The following image depicts a transaction that has two descriptor blocks:
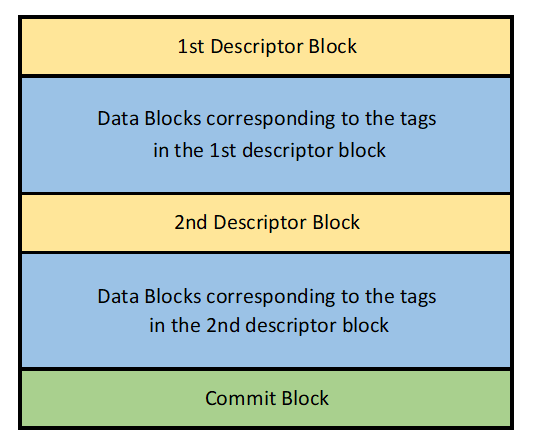
Tags hold the location of the block where the data in its corresponding data block is to be written.
t_blocknr,t_blocknr_highstore the lower 32-bit and upper 32-bit location of the final destination block of data.t_flags: See the table below
t_flags Value
Table 3
Among these flags, the escape flag i.e. 0x1 deserves some explanation. As mentioned earlier data blocks only store data, they do not have any header. So, the magic number in the header differentiates the data block from other journal blocks. One of the rare cases possible is that the 1st 12 bytes of data coincide with the magic number, in that case, the 1st 12 bytes will be zeroed and the escape flag will be set in the t_flags field of the tag.
struct jbd2_journal_block_tail {
__be32 t_checksum; /* crc32c(uuid+descr_block) */
};
jbd2_journal_block_tail will be the last four bytes of the descriptor and revoke blocks.
The following is a hex dump of a descriptor block:

journal_header_t→h_blocktype is 0x1 which implies this is a descriptor block (See Table 2), following the header we have only one tag, which means the transaction associated with this block has only one data block. The flags field of the tag is 0x8 indicating that this is the last tag in the descriptor block (See Table 3). After the tag everything in the block is set to zero except the last four bytes which is jbd2_journal_block_tail.
Data Blocks
Data blocks only store data. They store the contents of journaled data after the modification is done. That means if a file previously accessed on 1st Jan is last accessed on 10th Jan, then the access time will be logged as 10th Jan. Data stored stored in these blocks in data=ordered and data=writeback modes is metadata of the files involved in the transaction, whereas in data=journal mode, it’s both the data and metadata.
Commit Block
Commit block marks the end of a transaction. For any transaction, if we see a commit block logged then we can be sure that the data is successfully written to the journal, and data is ready to be checkpointed.
struct commit_header {
__be32 h_magic;
__be32 h_blocktype;
__be32 h_sequence;
unsigned char h_chksum_type;
unsigned char h_chksum_size;
unsigned char h_padding[2];
__be32 h_chksum[JBD2_CHECKSUM_BYTES]; // JBD2_CHECKSUM_BYTES = (32 / sizeof(u32))
__be64 h_commit_sec; // The time that the transaction was committed, in seconds since the epoch.
__be32 h_commit_nsec; // Nanoseconds component of the above timestamp.
};
The following is a hex dump of the commit block:
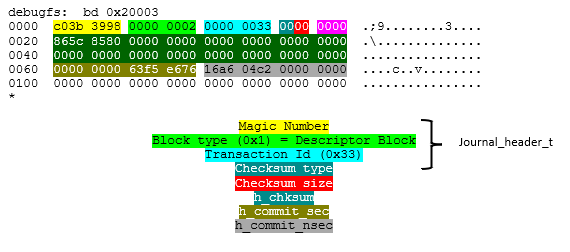
h_blocktype is 0x2 implying that this is a commit block.
If we look at the transaction id which is 0x33, this is the same as the transaction id of the descriptor block showing that these belong to the same transaction, and if we also look at the s_sequence of the superblock which points to the first commit id of the log is also 0x33. As this is the first transaction, s_sequence is holding its commit id.
Revocation Blocks
A block in the journal log is marked as revoked when it is no longer being journaled.
For example: Consider a meta journalling filesystem where a block that used to store some meta information is deallocated and re-allocated as a data block, as a result, a block that was a journaled one is no longer journaled therefore a revocation record will be created marking the block as revoked. This prevents the filesystem from replaying this sort of block during journal recovery.
typedef struct jbd2_journal_revoke_header_s
{
journal_header_t r_header;
__be32 r_count; /* Count of bytes used in the block */
} jbd2_journal_revoke_header_t;
A revocation block uses an entire block, where the 1st 16 bytes will be jbd2_journal_revoke_header_s following it one can find a list of block numbers (4bytes or 8bytes each depending on superblock configuration) of revoked blocks. And the last 4 bytes are left for jbd2_journal_block_tail.
Conclusion
In this blog, we have discussed various block types of journal log, their purposes, and the associated data structures. We have also seen the structure of a transaction and the overall layout of the journal log.