Introduction
Default OCI OKE clusters come with several preconfigured storage classes, enabling you to utilize storage within the same cluster or connect it to OCI Block Volumes (BV) or OCI File Systems (FSS). However, OKE’s flexibility allows for the integration of various storage technologies and providers, making it particularly advantageous for dynamic applications that require speed, low latency, and high disk capacity.
In this blog, we will explore an alternative approach using Object Storage Buckets. Although this option may not be the fastest for write-intensive applications, it offers significant benefits for read operations and can result in substantial cost savings.
To provide context, as of the date this blog was written, OCI Pricing estimates for 1,000 GB across various storage solutions for one month, are as follows:
- File Storage Service (FSS): approximately $300.00 USD
- Block Volumes (BV): about $42.50 for balanced performance and $25.00 USD for the lower cost type option
- Object Storage: around $2.30 USD
These significant cost differences highlight the importance of carefully considering your storage options since application cost tends to increase over time.
Object Storage Bucket as File System
Let’s consider a simple application that serves content via HTTP, with the content stored in an external data source, as an OCI Block Volume or an OCI File System Service, as described in the image below:
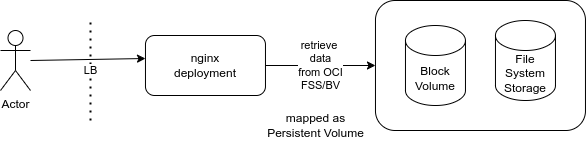
A number of improvements could be made, the application could enhance performance, scalability, availability, and security while effectively leveraging OCI Block Volumes or FSS as an external data source, but introducing OCI Object Storage could provide several key benefits for your application, especially when serving content via HTTP.
Some key points are: Object Storage is typically more cost-effective than Block Volumes or File Systems, particularly for large volumes of data or infrequently accessed content, it offers data redundancy, data replication to different regions, reliable access, lifecycle policies to automatically transition data between different storage classes or delete outdated data, object versioning and so on.
Improving costs using an OCI Object Storage Bucket
Let’s consider a simple modification in the application described above, where OCI Object Storage is introduced to store large files or not so frequent accessed files.
Object Storage is well-suited for serving large unstructured data files, such as images, videos, and backups, which may not be efficient to store in Block Volumes. Custom metadata could be added to objects, enhancing data management and retrieval capabilities.
Leveraging OCI Object Storage for your application not only enhances cost efficiency and scalability but also improves data management and accessibility. By using Object Storage, you can optimize your architecture for performance and reliability while effectively managing growing data needs.
Let’s review the proposal for cost reduction in the previous scenario:
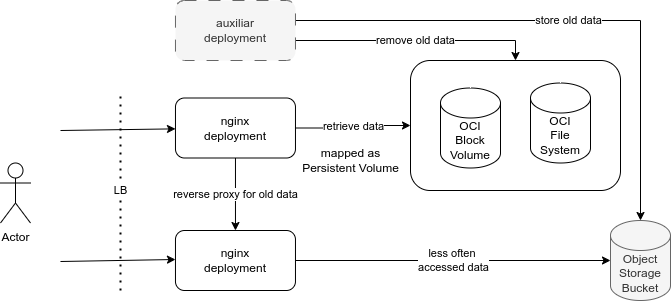
As illustrated in the image above, we have introduced an auxiliary deployment along with an auxiliary HTTP deployment. The auxiliary deployment is responsible for transferring data between different storage solutions, while the auxiliary HTTP deployment serves as a fallback for this specialized data
As a first step, a couple of requirements need to be meet:
- An Oracle Cloud Infrastructure account will be required.
- There are different software packages that allows to map an Object Storage Bucket as a File system, such as s3fs, Goofys, etc., for this example, s3fs will be used.
- An OCI Access Key / Secret token needs to be configured for your account in order to use this feature, you can find the steps in: S3 Compatible API (please feel free to read the page to understand Object Storage S3 compatibility with OCI).
- OCI Kubernetes Engine (OKE) or other K8 engine should be already provisioned in your tenancy and policies to use it should have been properly configured.
- A bucket should be provisioned in the tenancy
- Is assumed that the Nginx deployment is already configured, allowing us to focus on the auxiliary deployment, which will mount to OCI Object Storage.
Let’s create a namespace for all our resources in K8:
$ kubectl create namespace oci-bucket-demo
Let’s create the secret using the CLI to mount it into the container in K8:
$ kubectl create secret generic oci-secret --from-literal=token=<OCI_ACCESS_KEY>:<OCI_SECRET_KEY> -n oci-bucket-demo
In the above example r eplace <OCI_ACCESS_KEY> and <OCI_SECRET_KEY> with your own values.
Let’s define the auxiliar service Dockerfile:
FROM container-registry.oracle.com/os/oraclelinux:9-slim
RUN microdnf install oracle-epel-release-el9 && \
microdnf install s3fs-fuse && \
microdnf clean all
# RUN any custom packages or logic required for auxiliar deployment
COPY entrypoint.sh .
Let’s define the entrypoint file entrypoint.sh:
#!/bin/sh
set -e
mkdir -p "${BUCKET_MOUNT}"
# Mount the file system, customize with your own flags based on the project needs
s3fs "${OCI_BUCKET_NAME}" "${BUCKET_MOUNT}" \
-o url="${BUCKET_URL}" \
-o passwd_file=/etc/.passwd-s3fs/token \
-o endpoint=us-ashburn-1 \
-o nomultipart \
-o use_path_request_style \
-o allow_other \
-o retries=10
# Run forever or run custom logic
while true; do sleep 60; done
The file /etc/.passwd-s3fs/token will be mounted as part of the deployment step and will contain the content access-key:secret as defined during secret creation.
Compile the image and upload to your OCI Container Registry:
$ docker build -t <oci-region>.ocir.io/<oci-tenancy>/ol9-slim-s3fs:latest . $ docker push <oci-region>.ocir.io/<oci-tenancy>/ol9-slim-s3fs:latest
Define and apply the deployment for the auxiliar application:
apiVersion: apps/v1
kind: Deployment
metadata:
name: auxiliar
namespace: oci-bucket-demo
labels:
app: auxiliar
spec:
replicas: 2
selector:
matchLabels:
app: auxiliar
template:
metadata:
labels:
app: auxiliar
spec:
containers:
- name: ol9-s3fs
image: <oci-region>.ocir.io/<tenancy-name>/ol9-slim-s3fs:latest
command: [ "sh", "entrypoint.sh" ]
securityContext:
privileged: true
volumeMounts:
- name: password-file
mountPath: /etc/.passwd-s3fs
- name: oci-bucket
mountPath: /mnt/bucket
env:
# You can use env variables or a K8 config map or helm parametrization
- name: OCI_BUCKET_NAME
value: <your bucket name>
- name: BUCKET_MOUNT
value: <your mount point, e.g.: /mnt/bucket>
- name: BUCKET_URL
value: https://<tenancy-name>.compat.objectstorage.<oci-region>.oraclecloud.com/
volumes:
- name: password-file
secret:
secretName: oci-secret
defaultMode: 384
- name: oci-bucket
emptyDir: {}
In the above example replace <tenancy-name> and <oci-region> with your own tenancy name and deployment region.
Please note the secret defaultMode 384 in decimal corresponds to permission 0600 in octal.
Access the deployment and ensure your Object Storage Bucket was mounted:
# kubectl exec -it auxiliar-demo-dff5cb99-25vdf -n oci-bucket-demo -- bash bash-5.1# mount -v ... s3fs on /mnt/bucket type fuse.s3fs (rw,nosuid,nodev,relatime,user_id=0,group_id=0,allow_other) ...
Important notes
It is important to take into consideration that this scenario does not perform good for operations where metadata for thousands or millions of objects needs to be read. The HTTP service in this example was configured to ignore and reduce operations on metadata for files stored in OCI Block Storage, but performed well for a bucket with + 120,000,000 objects (with 500kb to 1MB average object size), and with an average HTTP response time of ~1-6 seconds for first directory read (e.g.: https-endpoint/my/custom/target/directory), and ~1 second for subdirectories (e.g. https-endpoint/my/custom/target/directory/sub).
Another experiment with a smaller amount of objects stored in an OCI Object Storage bucket (less than 100,000 objects) performed better with HTTP response times (~1 second).
Let’s note the two points above are for directory listing, direct file access was less than 1 second for bucket objects.
Looking forward
As a next step, a custom Kubernetes driver could be configured and used with OCI to mount an Object Storage Bucket as a shared mount point to multiple pods so all data is retrieved from the bucket, which could be useful depending on the application scenario (e.g.: content distribution), which is combined with the flexibility of Oracle Cloud Infrastructure.
There are several options available, including third-party open-source software solutions, that could be explored in the future to further enhance the application deployment.
For more information, see the following resources:
