Introduction
This is the first of a 3-part series about memory compaction in the Linux kernel. Part-1 (this part) describes how memory compaction works; later parts will describe how debug information and tracing can be used to understand and debug compaction problems.
The Linux kernel performs memory compaction to mitigate external fragmentation. Due to the way memory is allocated and freed over time, a system can have internal fragmentation, external fragmentation, or both.
Internal fragmentation happens when the kernel allocates more memory than requested and thus ends up wasting space inside an allocation. The Linux kernel’s lowest-level memory allocator is the buddy allocator and it can hand out memory only in sizes that are powers-of-2 pages (4 KB minimum). But the kernel needs hundreds of thousands of small objects like dentry, inode, file, etc. and giving each such object its own page would waste a lot of memory as shown below:
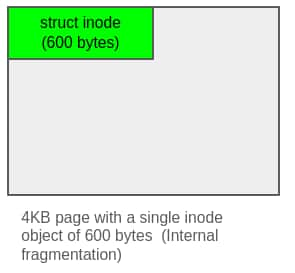
The Linux kernel uses the slab allocator to fix the issue of internal fragmentation. The slab allocator sits on top of the buddy allocator and solves the internal-fragmentation issue by packaging many same-sized objects into each page (or slab) that it gets from the buddy allocator. Within a slab, objects are laid out like shown below:

Each object gets its own cache (sometimes even objects of different types but of the same size use the same cache), from which objects are allocated and once a slab has been totally used, the slab allocator can ask for more pages from the buddy allocator.
On the other hand, external fragmentation happens when free pages are dispersed such that sufficiently large physically contiguous blocks cannot be formed. For example, there may be plenty of 4KB pages scattered around, but the buddy allocator can’t hand out a contiguous 64KB block because no 16 adjacent pages are free together. An example has been shown below:

To address external fragmentation, the kernel relies on memory compaction, which moves movable pages from the lower portion of a memory zone towards its upper portion, so that enough free pages can be coalesced together to create large physically contiguous regions. For example, in the above-mentioned scenario of 64KB allocation, if compaction is successful we can see a free block of 16 adjacent pages as shown below:

While memory reclaim frees up pages outright by evicting them or writing back their contents, memory compaction leaves contents intact but moves them to other pages, to consolidate fragmented free space into contiguous blocks.
About this blog
This blog explains how memory compaction is implemented in the Linux kernel, and is the first in a series that builds on this foundation to describe how compaction-related issues can be debugged using the tracepoints and other data exposed by the compaction subsystem. Some sections of this blog deliberately go into implementation detail — describing kernel data structures and code paths that are not strictly necessary for a conceptual understanding of compaction. This is intentional so that the later blogs in this series can use it as a foundation for interpreting tracepoint output and diagnosing compaction problems in production systems. To accommodate readers with different goals, sections that transition from conceptual description into implementation detail, contain subsections marked as Deep dive. Readers who want a high-level understanding of compaction or are not interested in debugging compaction-related issues can avoid the Deep dive subsections but readers who want to follow the kernel source or understand how to interpret diagnostic data, described in later blogs, should read the sections in full.
This blog first describes the building blocks of compaction flow such as migration types, compaction types, compaction priority, and struct compact_control, and then follows that with an explanation of the compaction core, scanner (migration and free) mechanisms, and page migration in context of memory compaction. This blog covers the general compaction path only and is based on the v6.18 kernel. The alloc_contig path used by CMA (the Contiguous Memory Allocator, which reserves a region of physical memory for runtime large-block allocations) and gigantic hugepage allocations, which shares much of the same infrastructure, is out of scope. The blog assumes prior familiarity with memory management concepts such as NUMA nodes, memory zones, pages, folios and the zoned buddy allocator — see the references section for background material on these topics.
For details on the slab allocator (which addresses internal fragmentation), please see my earlier blog mentioned in the reference section.
Migrate types and pageblocks
In a virtual memory system the users of memory are oblivious of the physical pages where this memory maps and hence this mapping can be moved around by the kernel. But not all mappings are movable.
The kernel uses migrate types to classify pages based on their mobility. Migrate types control whether the kernel can physically relocate a page or not. The migrate types are defined by enum migratetype. For compaction purposes, the following three types are relevant:
MIGRATE_UNMOVABLE — Pages that can’t be migrated, typically kernel allocations
MIGRATE_MOVABLE — Pages that can be migrated, usually user space pages
MIGRATE_RECLAIMABLE — Slab pages. Slab pages are usually of MIGRATE_UNMOVABLE type but in certain special cases (e.g. slab caches with SLAB_RECLAIM_ACCOUNT such as dentry cache, inode cache, or kmalloc with __GFP_RECLAIMABLE) slab pages fall into MIGRATE_RECLAIMABLE category and can be reclaimed if slab does not have any allocated objects.
Since user space pages reach their owners via page-tables which are populated and managed by the kernel, the kernel can move pages and change corresponding page-table mappings without the user noticing any change in the virtual memory they are using. This makes user space pages MIGRATE_MOVABLE in most cases (unless special cases like pinning, hugetlb pages etc. make them MIGRATE_UNMOVABLE). On the other hand most of the kernel memory lives in a linearly mapped region with a fixed 1:1 mapping between physical and virtual addresses and hence it can’t be moved. Even with mechanisms like vmalloc, the kernel portion of the page table is used, hence those pages can’t be moved either. So most of the kernel pages are MIGRATE_UNMOVABLE. There are some special cases (like subsystems that implement struct movable_operations) where kernel pages can be moved.
Classifying pages by mobility alone is not sufficient — compaction’s goal is to produce high-order free contiguous blocks, and this is impossible if movable and non-movable pages are interleaved at fine granularity. To address this, the kernel groups pages of the same migration type together at the pageblock level. A pageblock is a physically contiguous block of pageblock_order (order-9 on x86_64) pages and each pageblock is assigned a single migration type, keeping movable (MIGRATE_MOVABLE) and non-movable (MIGRATE_UNMOVABLE) pages separated at a coarser granularity that makes large contiguous regions achievable.
Linux kernel’s page allocator (also known as the buddy allocator) reinforces this organisation by maintaining separate per-migration-type free lists at every allocation order. Allocations are served from the free list matching their requested migration type. However when a free list cannot satisfy a request, the allocator steals pages from a different migration type’s free list and this stealing can worsen fragmentation over time.
Types of compaction
The Linux kernel performs compaction in different modes and contexts, each with different triggering conditions and targets.
Compaction can be broadly categorised into the following types:
- Direct compaction (happens in context of memory allocator and has a target order)
- Indirect compaction (happens in background)
- with a target order
- with a target fragmentation score (or Proactive compaction)
- Manual compaction (Triggered manually and happens in the context of the triggering task)
Based on the above, compaction can also be categorised as targeted or untargeted. Targeted compaction is aimed at satisfying a specific allocation order, while untargeted compaction aims to improve the overall fragmentation score (described further down) of a node or to complete a manual request for compaction.
Direct compaction
When a high-order allocation fails, the page allocator’s slow path (__alloc_pages_slowpath()) may trigger direct compaction via __alloc_pages_direct_compact(), which attempts compaction first and then retries the allocation. Direct compaction is therefore demand-driven — it targets a specific allocation order and terminates as soon as a page of that order becomes available in the zone’s free lists. It may also terminate unsuccessfully if it exhausts the zone without satisfying the target, or is cut short due to lock contention.
The following diagram summarizes the flow of try_to_compact_pages(), and shows important subroutines invoked from there. try_to_compact_pages() is the main function that performs direct compaction:
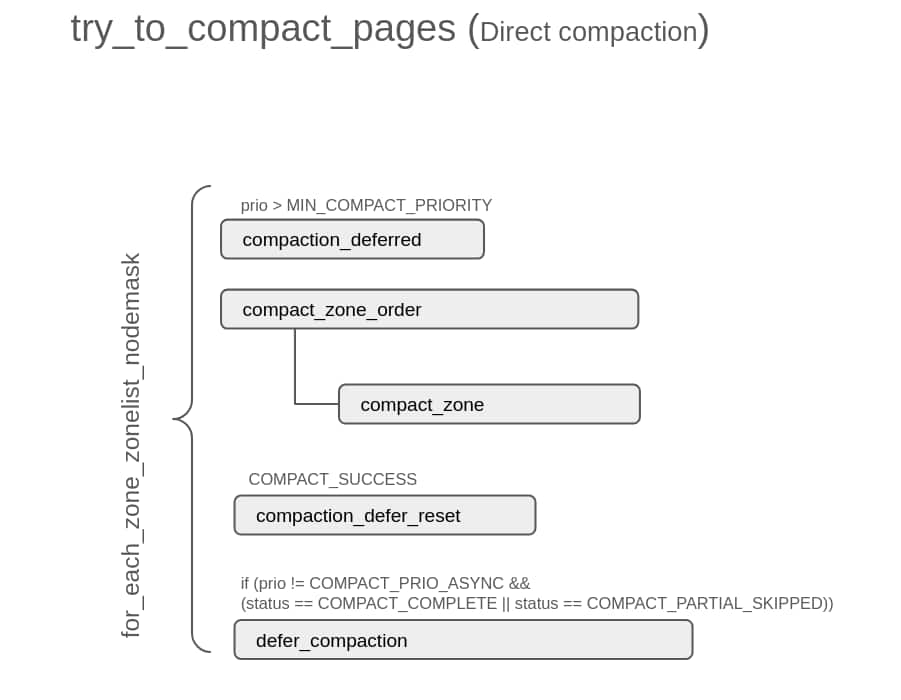
try_to_compact_pages() iterates through all allowed zones via for_each_zone_zonelist_nodemask() and invokes compact_zone_order() on each of them. compact_zone_order(), invokes compact_zone(), which is described later in Per-zone compaction loop (compact_zone()) and is the main engine that performs compaction. The deferral logic (compaction_deferred, defer_compaction and compaction_defer_reset) is used in indirect compactions too and is described in its own dedicated section.
Indirect compaction
Indirect compaction is performed in the background by a per-node kcompactdN thread. The diagram below captures the main block of its thread handler (kcompactd) and shows involved subroutines:
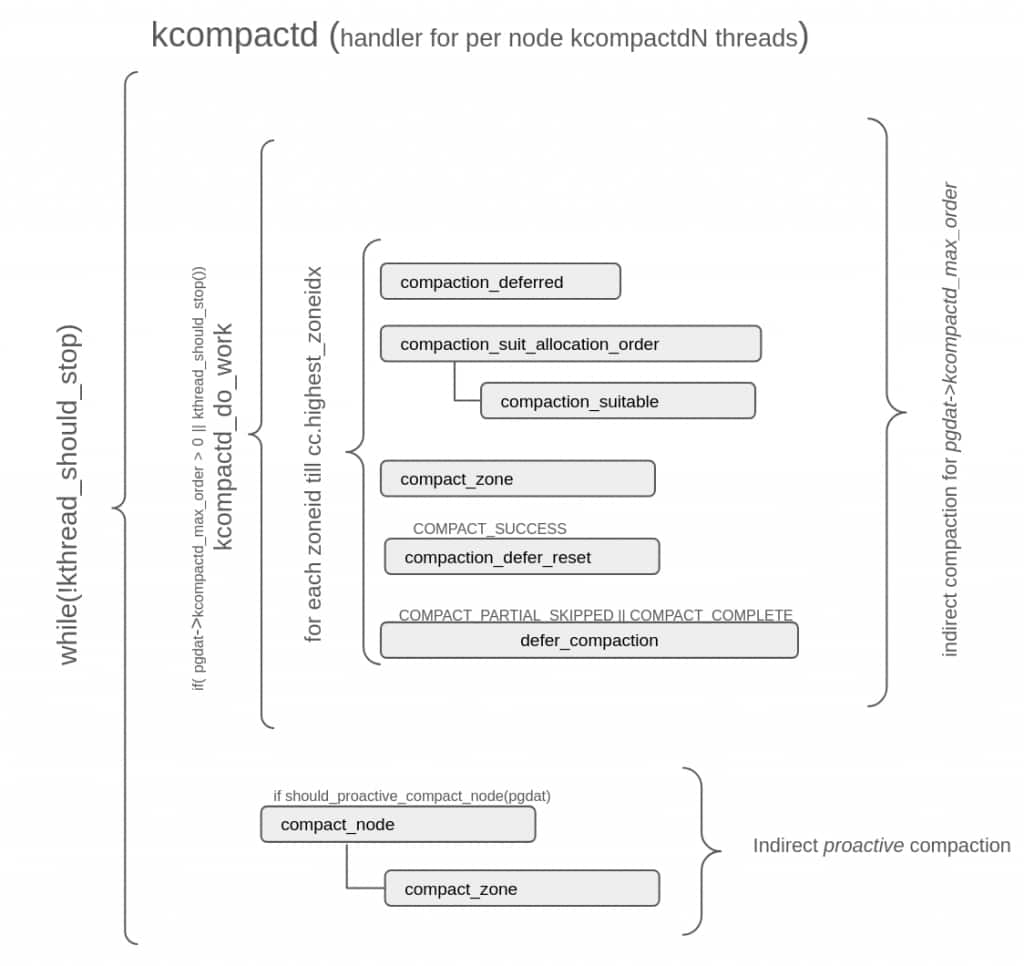
The deferral logic (compaction_deferred, defer_compaction and compaction_defer_reset) shown in both direct and indirect compaction diagrams above, is described later in Deferral of compaction request.
Two variants of indirect compaction are described below: targeted indirect compaction, woken by a failing high-order allocation and aimed at a specific order, and proactive indirect compaction, which runs even when no allocation has failed and aims to lower the node’s overall fragmentation. Both variants share the same overall flow — kcompactdN runs through the allowed zones and invokes compact_zone() on each — and differ mainly in their trigger and their termination criterion.
Indirect compaction with a target allocation order
When a high-order allocation fails, the page allocator may wake kcompactdN on the target NUMA node via wakeup_kcompactd(). Unlike direct compaction where the target order and zone constraints are passed directly into the compactor, kcompactdN runs asynchronously and receives this information through two fields in the per-node pgdat object: kcompactd_max_order, which tells kcompactdN what order to target, and kcompactd_highest_zoneidx, which indicates the highest zone it is allowed to compact.
The allocator/waker passes the current order and highest zone index to wakeup_kcompactd(), which updates these fields conservatively. kcompactd_max_order is updated only if the incoming order is higher than what is already recorded because if kcompactdN is already targeting a higher order, satisfying that may also satisfy the lower-order request. Similarly kcompactd_highest_zoneidx is updated only if the incoming zone index is lower (i.e., more restrictive) than what is recorded, preventing kcompactdN from expanding its zone coverage beyond what the allocation request allows.
Finally, if no thread is parked on the kcompactd_wait waitqueue (typically because kcompactdN is already running) then nothing further is done; otherwise wakeup_kcompactd() calls kcompactd_node_suitable() to verify if the node is suitable for compaction and for suitable nodes to wake up the kcompactdN thread.
Once woken, kcompactdN invokes kcompactd_do_work(), which iterates through the allowed zones and calls compact_zone() on each. As with direct compaction, the flow reaches compact_zone() in this case too.
Indirect compaction with a target fragmentation score (Proactive compaction)
The compaction types described so far cover cases that are triggered when a memory allocation request fails, but in proactive compaction kcompactdN runs even when no allocation request has failed, hence the name proactive. This mode of compaction is not present in older (prior to v5.10) kernels.
Proactive compaction is driven by a per-node fragmentation score (range [0, 100]) with low and high watermarks. The fragmentation score is an indicator of the node’s external fragmentation for COMPACTION_HPAGE_ORDER (order-9 on x86_64), and its watermarks are controlled via the sysctl parameter vm.compaction_proactiveness. kcompactdN periodically invokes should_proactive_compact_node() which checks if the current fragmentation score is higher than the high watermark and if it is then compact_node() gets invoked. compact_node() goes through the zones of the node and invokes compact_zone() on them.
Fragmentation score calculation and usage — Deep dive
The fragmentation score of a node is the sum of weighted fragmentation scores of zones within that node. A zone’s external fragmentation for any order indicates what fraction of that zone’s free memory is unavailable as contiguous blocks of that order. The fragmentation score of a zone is its external fragmentation with respect to order COMPACTION_HPAGE_ORDER. A zone’s fragmentation score is scaled by its share of total node memory to get the weighted fragmentation score. The scaling of a zone’s raw fragmentation score ensures that small zones like ZONE_DMA32 don’t get equal say as large zones like ZONE_NORMAL in triggering proactive compaction. Finally weighted fragmentation scores of all zones are added to get that node’s fragmentation score. But just getting a node’s fragmentation score is not enough, there should be some way to specify the thresholds that can trigger and stop proactive compaction. This threshold is provided by low and high watermarks for the per-node fragmentation score and these watermarks are calculated by fragmentation_score_wmark() based on a sysctl parameter vm.compaction_proactiveness. For example for vm.compaction_proactiveness=20 (default) we have low and high watermarks as 80 and 90 respectively and this means when the fragmentation score of this node crosses 90, proactive compaction is triggered and when it drops below 80 proactive compaction is stopped. Similarly for vm.compaction_proactiveness=40 the watermarks become 60 and 70 and hence proactive compaction gets triggered much earlier. Earlier proactive compaction would get triggered when 90% of free memory is unavailable as contiguous blocks of order-COMPACTION_HPAGE_ORDER and now it would be triggered if 70% of free memory is unavailable as contiguous blocks of order-COMPACTION_HPAGE_ORDER.
So a higher value of vm.compaction_proactiveness triggers proactive compaction more proactively and since compaction has its own overheads, this value should be set based on workloads. The default value of 20 works for most of the cases and of course making it 0 will effectively disable proactive compaction.
Manual compaction
Manual compaction is triggered by a user writing into the procfs or sysfs interfaces. It can be triggered for all nodes in a system via /proc/sys/vm/compact_memory or for a specific node via /sys/devices/system/nodeX/compact. In the first case compact_nodes() invokes compact_node() for each node and in the second case compact_node() is called for the specified node. compact_node() goes through the zones of the node and invokes compact_zone() on each of them. Unlike earlier types, manual compaction does not have any metric (allocation order, fragmentation score) to stop it and it stops after sweeping through all the zones of node(s).
Compaction mechanism
Irrespective of compaction type, all compaction flows eventually perform compaction at zone level (via compact_zone()).
The picture below shows how different compaction paths converge at compact_zone():
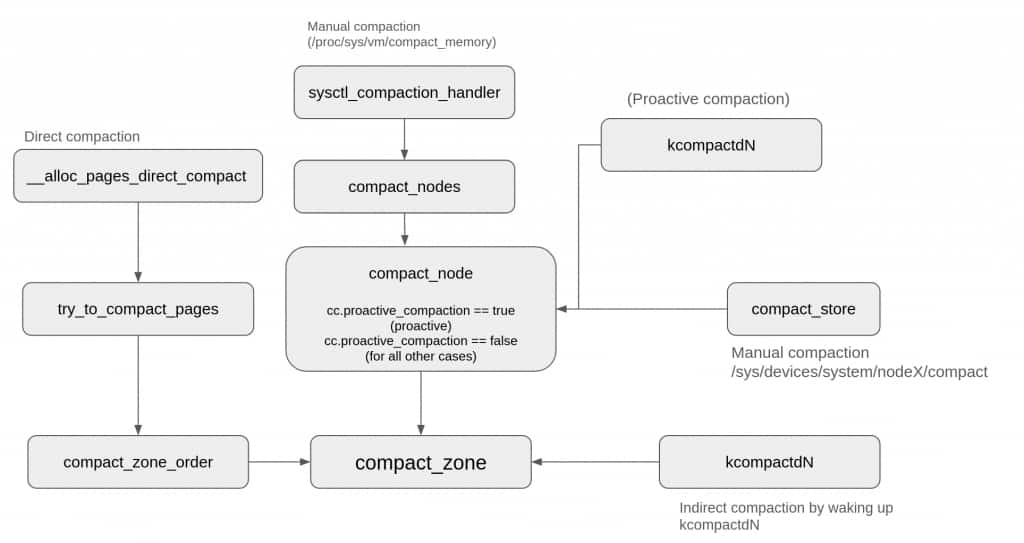
Although compact_zone() is invoked for each type of compaction, depending on the compaction type it is driven by a different set of parameters and objectives.
Before delving into the flow of compaction mechanism, let’s see some of its aspects that remain common across all types of compaction and are important in order to understand the compaction flow.
Migrate mode
Migrate mode is a concept of the page migration framework — used by subsystems like memory hot-unplug and NUMA balancing as well as by compaction — that specifies whether the migrating task can block, and if it can, how aggressively. It controls whether the task can wait only for transient conditions (like lock contention) or whether it can also block for long (like waiting on I/O). For compaction, the migrating task is the memory allocator task in the case of direct compaction, or the kcompactdN task in the case of indirect compaction.
Compaction reuses migrate mode beyond just page migration: because the blocking policy is the same across all stages of compaction, migrate mode also governs other parts of the compaction operation. And since the migrate mode is eventually used during page migration, for compaction it acts as a pre-filter while selecting pages whose migration may create larger contiguous blocks.
There are three modes:
- MIGRATE_ASYNC — In this mode compaction task can’t block. Any page that requires waiting, like pages under writeback, dirty pages that would need writeback to migrate, pages/folios whose lock can’t be grabbed immediately, are skipped while looking for migratable pages. In case of spinlock (zone or lruvec) contention, compaction is aborted after processing the current pageblock.
- MIGRATE_SYNC_LIGHT — In this mode the compaction task can block but only for short and predictable waits. This mode avoids writeback pages just like MIGRATE_ASYNC but handles page lock contention differently. If a folio is locked for I/O it is skipped but if it’s locked for some quick operation like page table update, then the compaction task can wait for it. In case of spinlock (zone or lruvec) contention, compaction is not aborted after processing the current pageblock.
- MIGRATE_SYNC — In this mode the compaction task can block even on I/O. Spinlock contentions are handled in a way similar to MIGRATE_SYNC_LIGHT.
For direct compaction the mode is derived from the compaction priority, which is described in the next section. All other compaction types run at a fixed mode: all indirect compactions (done by kcompactdN) use MIGRATE_SYNC_LIGHT, while manually triggered compaction uses MIGRATE_SYNC. The reason manual compaction allows full blocking is that, usually it is treated as a last option to see if compaction can help to reduce fragmentation and it is expected that since the user is triggering it, they are aware of the costs involved. The subsequent sections refer to MIGRATE_SYNC_LIGHT and MIGRATE_SYNC collectively as sync modes where the distinction between them does not matter, and to MIGRATE_ASYNC as async mode. The practical significance of these modes will become clearer in the later sections when we examine how they influence each stage of compaction.
Compaction priority
Compaction priority is used in direct compaction only and controls how aggressively it pursues its goal. Since direct compaction is triggered from within the page allocator’s retry loop (__alloc_pages_slowpath() → __alloc_pages_direct_compact()), the page allocator knows how many times it has already tried and failed — and therefore how hard the next compaction attempt should try. Direct compaction attempts start with lower-priority and escalate to higher priorities if compaction attempts are not fruitful.
There are three priority levels, from lowest to highest:
- COMPACT_PRIO_ASYNC — the lowest priority, also referred to as INIT_COMPACT_PRIORITY and translates to MIGRATE_ASYNC mode. Since this is a low-priority attempt, it can afford to give up easily, hence MIGRATE_ASYNC mode.
- COMPACT_PRIO_SYNC_LIGHT — also referred to as DEF_COMPACT_PRIORITY, and translates to MIGRATE_SYNC_LIGHT, permitting limited blocking. This is the highest priority used for direct compaction targeting costly orders (orders above PAGE_ALLOC_COSTLY_ORDER, i.e., order 3), because allowing direct compaction to fail for large orders is considered a better option than blocking on I/O for large pages.
- COMPACT_PRIO_SYNC_FULL — the highest priority, also referred to as MIN_COMPACT_PRIORITY and this also translates to MIGRATE_SYNC_LIGHT but it can be used only for non-costly orders. Also at this level, deferral decisions and per-pageblock skip hints from previous passes are ignored, and the entire zone is scanned unconditionally regardless of cached scanner positions.
Even though compaction priorities get translated to migration modes, they are not always used together. Compaction priorities are used by direct compactions only because other compaction types don’t use the idea of escalated compaction attempts. On the other hand, migration modes are used in all kinds of compactions (direct, indirect or manual).
The table below summarizes migration modes and compaction priorities for different types of compaction.
| Compaction type | Priority | Mode |
|---|---|---|
| Direct (Pre-reclaim) | COMPACT_PRIO_ASYNC | MIGRATE_ASYNC |
| Direct (Post-reclaim) | COMPACT_PRIO_SYNC_LIGHT | MIGRATE_SYNC_LIGHT |
| Direct (Post-reclaim, non-costly order) | COMPACT_PRIO_SYNC_FULL | MIGRATE_SYNC_LIGHT |
| Indirect(targeted) | not applicable | MIGRATE_SYNC_LIGHT |
| Indirect(proactive) | not applicable | MIGRATE_SYNC_LIGHT |
| Manual | not applicable | MIGRATE_SYNC |
struct compact_control
The compact_control object defines compaction parameters and tracks compaction progress and results as compaction proceeds through different stages. For v6.18 its definition can be seen here. It’s an exhaustive structure with fields for different purposes like specifying goal and constraints of the compaction pass, tracking page isolation related cursors, tracking progress of compaction pass and various other uses. These fields have been described in detail in the following Deep dive section which can be ignored unless we want to know how these fields are used in different parts of compaction code and how/when their values appear in debug or tracing data.
struct compact_control — Deep dive
For the ease of understanding we can classify compact_control‘s main fields into different categories:
Input parameters
These fields specify the goal and constraints of the compaction pass.
- order — is the target compaction order — the order of the free page compaction is trying to create. For direct compaction it comes from the original allocation request. For indirect compaction where the page allocator wakes kcompactdN, it comes from pgdat->kcompactd_max_order, which the allocator sets according to order (if it’s more than the current value) before waking the daemon. For proactive and manual compaction order is set to -1, as there is no target order.
- gfp_mask — carries the GFP flags of the triggering allocation for direct compaction, and is set to GFP_KERNEL for other types of compaction.
- alloc_flags — influences watermark checking when deciding whether compaction is needed — for direct compaction it is derived from the allocation’s gfp_mask, while for indirect compaction it is influenced by vm.defrag_mode, which controls whether the allocator tries to avoid fragmentation or not.
- highest_zoneidx — restricts compaction to zones at or below a given type.
- direct_compaction — indicates whether this is a direct compaction request.
- proactive_compaction — tells kcompactdN whether the compaction pass was triggered by proactive compaction rather than a failing allocation.
- mode — specifies the migration mode as described earlier.
- whole_zone — controls whether the entire zone is scanned. It is always true for untargeted indirect (proactive) and manual compaction, but for direct compaction it depends on the compaction priority.
- ignore_skip_hint — controls whether per-pageblock skip hints from previous passes are respected. For direct compaction it depends on priority. For targeted indirect compaction it is false; for other indirect compaction and for manual compaction it is true.
- ignore_block_suitable — controls whether blocks otherwise considered unsuitable should still be scanned, unlike ignore_skip_hint that gets used by both scanners, ignore_block_suitable is used by free scanner only.
Scanner positions
These fields track the position of migration and free scanners (described below) within the zone.
- migrate_pfn — tracks the current position of the migration scanner, which starts at the lower end of the zone and moves upward.
- free_pfn — tracks the free page scanner, which starts at the top end of a zone and moves downward.
Progress tracking
These fields track compaction progress.
- freepages and migratepages — are lists holding pages isolated by the free and migration scanners respectively.
- nr_freepages and nr_migratepages — track the running counts of such pages, incremented as pages are isolated and decremented as they are consumed.
- total_free_scanned and total_migrate_scanned accumulate the total pages scanned by each scanner across the entire compaction pass.
Several remaining fields relate to the fast search of buddy freelists performed by both scanners. finish_pageblock forces the migration scanner to fully scan the current pageblock before advancing, when the scanner detects a rescan of the same block (e.g. after a partial migration failure). This prevents recently partially scanned blocks from being revisited during fast freelist searches. search_order is the order at which the free scanner’s next fast search should begin; it is used only in targeted compactions, initialised to cc->order at the start of the pass, and updated to the order of the last successful fast-path isolation. fast_search_fail counts consecutive fast freelist search failures and is incremented each time a fast search fails and resets when it succeeds.
Deferral of compaction request
For targeted compactions (both direct and indirect) the compaction flow uses a deferral mechanism to avoid wasteful repeated attempts on a zone. This deferral mechanism follows three sequential states: a compaction attempt fails, the next attempts may be skipped (up to a maximum of 64 times), and after the skip window is exhausted compaction is tried again — if it succeeds the deferral state is reset.
Deferral state machine — Deep dive
In the case of direct compactions of high priority (!= COMPACT_PRIO_ASYNC) or indirect compactions (only targeted ones), if the compaction attempt fails due to both scanners meeting (signalled by compact_zone() returning COMPACT_COMPLETE or COMPACT_PARTIAL_SKIPPED), the next several attempts on that zone and order may be skipped before trying again. In such cases defer_compaction() gets invoked. If the current failing order is lower than the current value of zone->compact_order_failed, it gets recorded in zone->compact_order_failed as the new lowest failing order.
Also zone->compact_considered is reset to 0 and zone->compact_defer_shift (which controls how many subsequent attempts on this zone will be skipped) is incremented. The zone is skipped (1 << zone->compact_defer_shift) times and zone->compact_defer_shift can have a maximum value of COMPACT_MAX_DEFER_SHIFT (6). The idea here is that for compaction failures we initially skip the zone for a few times but if failures persist skip count is doubled up to a maximum value of 64.
Following the recorded failure, subsequent compaction requests for the same zone are checked by compaction_deferred(), which checks whether this attempt should be skipped. The next (1 << zone->compact_defer_shift) attempts to compact the zone for any order at or above zone->compact_order_failed are skipped.
Once the skip window is exhausted, compaction is retried. After a successful pass, compaction_defer_reset() advances zone->compact_order_failed if applicable. zone->compact_considered and zone->compact_defer_shift are cleared only later, when the page allocator confirms that a page was actually obtained from the freelist after compaction. The two-step reset reflects the fact that a successful compaction pass only guarantees that a free page of the right order appeared in the buddy allocator’s freelist, but a concurrent allocator can still grab it, so the deferral counters are not reset until the allocator side confirms success.
Zone suitability check
For compactions with a target order, it is useful to assess whether a zone genuinely needs compaction, whether compaction is likely to succeed for the targeted order and whether compaction can help with the current allocation request. Zone suitability check, performed via compaction_suit_allocation_order() answers these questions. Compaction code flow uses zone suitability check in various places and proceeds further only if checked zone is reported as suitable for compaction.
Zone suitability is checked at three points: inside compact_zone() before its main loop begins, inside kcompactd_do_work() as it iterates through the node’s zones, and inside kcompactd_node_suitable() when the page allocator requests a wakeup of kcompactdN which is woken only if at least one zone is found suitable.
compaction_suit_allocation_order() performs this check and returns one of three verdicts: COMPACT_SUCCESS, COMPACT_SKIPPED, or COMPACT_CONTINUE. Unless the verdict is COMPACT_CONTINUE, compaction of that zone is not attempted.
COMPACT_SUCCESS is returned when the zone already satisfies zone watermarks at the requested order, so allocation can proceed without needing compaction.
COMPACT_SKIPPED means the zone is not suitable for a compaction attempt and is returned in any of the following cases:
- For costly-order async compactions, without CMA, if there are not enough free pages outside CMA.
- If the zone is too depleted for compaction to have promising destinations (i.e., there are not enough free pages, at the order-0 watermark plus a per-order gap, to act as migration targets).
- If the fragmentation index indicates that memory shortage (not fragmentation) is causing the allocation failure in the first place.
In all other cases, COMPACT_CONTINUE is returned.
Fragmentation index
For costly orders (> PAGE_ALLOC_COSTLY_ORDER), the fragmentation index plays a key role in determining zone suitability for compaction. A high-order allocation can fail either because the system is genuinely short on memory, or because the available memory is scattered into too-small free blocks. Compaction can only help in the latter case and fragmentation index helps in reaching this decision. A fragmentation index of -1000 indicates that allocation can succeed without needing reclaim or compaction; a positive value near 0 indicates that allocation failure is due to shortage of memory and a value near 1000 indicates that allocation failure is due to fragmentation. Since the boundary between these two failure modes is a range rather than a fixed point, the kernel exposes a sysctl parameter named vm.extfrag_threshold to control where that boundary sits. With the default value of 500, any fragmentation index at or below this threshold is treated as a memory shortage and does not signal a need for compaction, when checked by compaction_suit_allocation_order().
Fragmentation index calculation — Deep dive
Fragmentation index is calculated in fragmentation_index() which first walks the buddy freelist to collect three values: total free pages (free_pages), total free blocks of any order (free_blocks_total), and free blocks large enough to satisfy the target order (free_blocks_suitable). If the allocation order is greater than MAX_PAGE_ORDER (i.e., an order the buddy allocator can’t represent) or if free_blocks_total is 0, it means that there are no free pages that can act as migration targets or in other words memory shortage is the main problem here, in such cases fragmentation_index() returns 0. If free_blocks_suitable > 0, the allocation could succeed without needing compaction or reclaim and fragmentation_index() returns -1000 to indicate this.
In all other cases fragmentation index is calculated as follows:
fragindex = 1000 – ((1000 + free_pages * 1000 / requested) / free_blocks_total)
In the above rule, free_pages * 1000 / requested indicates a scaled measure of how many allocations of requested size could theoretically be satisfied if all of the free memory were contiguous and free_blocks_total indicates how many free blocks of any order are available. So if free_pages * 1000 / requested is large w.r.t free_blocks_total, we can assume that blocks on average are large i.e., free memory is spread across few blocks and failure is due to those blocks not being of the right order. In other words allocation failure is due to shortage of memory and it is indicated by a fragmentation index near 0. On the other hand, if free_pages * 1000 / requested is small w.r.t free_blocks_total, we can assume that there are a lot of tiny free blocks i.e., free memory is scattered across tiny blocks and failure is due to there being no large enough blocks. In other words allocation failure is due to fragmentation and it’s indicated by a result near 1000.
Per-zone compaction loop (compact_zone())
As explained earlier, different types of compaction flows eventually end up at compact_zone(). Every compaction run corresponds to a single invocation of compact_zone() and consists of up to three stages.
- Migration scanning (isolate_migratepages()): Scan in-use pages of a zone, from the lower end, and isolate ones that can be migrated to other pages.
- Free scanning (isolate_freepages()): Scan free pages of a zone, from the top end, and isolate ones that will work as targets for pages being migrated.
- Migrate pages (migrate_pages()): move pages selected in step 1 to pages selected in step 2, update mappings accordingly and free up pages that were migrated.
Free scanning happens lazily and is done only when a destination page is needed.
Each invocation of compact_zone() executes the compaction stages in a loop until the target is met or further progress is impossible due to contention or page exhaustion. On every iteration compact_finished() decides whether the loop should keep going, stop with success, or abort.
The following diagram shows the main functions involved in a compaction pass. These functions are described in further detail in subsequent sections, that cover different stages of compaction.
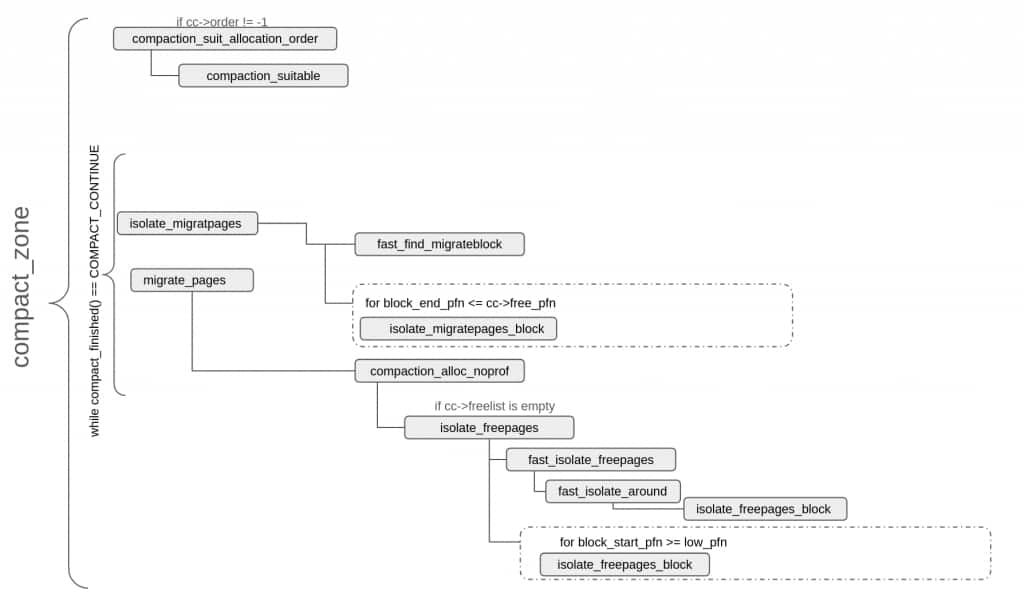
Before the main loop, compact_zone() initialises scan counters and page lists, and derives the migration type from the caller’s gfp_mask. For targeted compactions, compaction_suit_allocation_order() is called to assess whether the pass should proceed. If the deferral cycle for this zone has been fully exhausted, per-pageblock skip hints from previous passes are cleared.
Scanner starting positions are then established. If the caller requested a full zone scan, the migration scanner starts at the zone’s lower boundary and the free scanner at the upper boundary. Otherwise the cached positions — compact_cached_migrate_pfn and compact_cached_free_pfn — are used, allowing successive passes to resume incrementally rather than restart from scratch. The cache is invalidated when the scanners fully meet. Two cached positions are maintained for the migration scanner — one for async mode and one for all sync modes — because async compaction skips pages it cannot immediately migrate, leaving work behind that a sync pass would handle. Proactive and manual compaction always start from zone boundaries since they must cover the entire zone. Finally, the per-CPU folio batch is drained so that those pages are visible to the migration scanner.
The core of compact_zone() is a while loop controlled by compact_finished(), which is evaluated before every iteration. The loop continues as long as compact_finished() reports COMPACT_CONTINUE and no intermediate stage encounters an error.
compact_finished() checks several termination conditions based on the compaction target, zone state, and context. If the free scanner has reached the same or a lower pageblock than the migration scanner, the zone has been fully swept — cached positions are reset and either COMPACT_COMPLETE or COMPACT_PARTIAL_SKIPPED is returned depending on whether the full or only part of the zone was scanned. For proactive compaction, COMPACT_CONTINUE is returned as long as the zone’s fragmentation score remains above the low watermark but if kswapdN (the per-node memory-reclaim daemon) is found running, COMPACT_PARTIAL_SKIPPED is returned to terminate the pass early and ensure that compaction and reclaim don’t struggle against each other. Manual compaction returns COMPACT_CONTINUE until both scanners have met. When vm.defrag_mode is set, the kernel tries harder to avoid fragmentation and hence the success criteria for any indirect compaction gets stricter — only pages in fully free blocks of pageblock_order or above are counted, and COMPACT_CONTINUE is returned until the count of such pages exceeds the zone’s high watermark. For all targeted compactions the primary success condition is the appearance of a free page of the requested order and compatible migration type in the buddy free lists — once detected, compact_finished() returns COMPACT_SUCCESS.
The main loop within compact_zone() interprets the values returned by compact_finished() as follows:
- COMPACT_CONTINUE — no termination condition is met; the loop proceeds to the next iteration.
- COMPACT_SUCCESS — the compaction target has been achieved.
- COMPACT_COMPLETE — the scanners met after sweeping the entire zone without satisfying the target.
- COMPACT_PARTIAL_SKIPPED — the scanners met without satisfying the target but some pageblocks were skipped during the pass, or a proactive compaction attempt was interrupted in favor of background reclaim (kswapdN) running at the same time.
- COMPACT_CONTENDED — the pass should be aborted because lock contention was detected or a fatal signal is pending for the current task.
Within the main loop, isolate_migratepages() attempts to isolate pages for migration and its return value determines how the loop proceeds.
ISOLATE_ABORT indicates lock contention and in such a case, any already-isolated pages are returned to their LRU lists and compact_zone() exits with COMPACT_CONTENDED.
ISOLATE_NONE means no migration candidates were found in this scan window and the main loop should be tried again but before resuming the loop, two things are checked and acted upon: firstly, for async compaction, if the two cached migrate PFNs were in agreement at the start of the pass, the sync cached position is also advanced to avoid rescanning this pageblock. Recall from the earlier description of cached migration scanner positions that the cached sync position can lag behind the cached async position; here that gap can be closed because we have already confirmed there are no migration candidates. Secondly, if the migration scanner has moved past the previous cc->order-aligned block boundary, that would mean that some pages have been freed from that earlier pageblock and these freed pages are flushed back to the buddy freelist so that compact_finished() can have an accurate view of the zone before deciding about the next loop iteration.
ISOLATE_SUCCESS means migratable pages were isolated. compact_zone() proceeds to call migrate_pages() with compaction_alloc and compaction_free as callbacks. compaction_alloc drives Stage 2 — free page isolation — lazily, since destination frames are only needed once migration candidates are available. With both sets of pages in hand, migrate_pages() performs the actual migration.
If migrate_pages() succeeds, that means some pages were migrated. For direct compaction the loop breaks if a page of the desired order was captured; otherwise compact_finished() determines whether to continue, after flushing freed pages into the buddy freelist using the same way as described earlier.
migrate_pages() can also fail — either with a negative errno indicating a fatal error, or a positive value indicating how many pages could not be moved. In both cases unmigrated pages are returned to their LRU lists. -ENOMEM from compaction_alloc(), when the scanners have not yet met, indicates that free pages have been exhausted even before the zone was fully swept and it causes the loop to break with COMPACT_CONTENDED. A partial failure mid-pageblock in MIGRATE_ASYNC or MIGRATE_SYNC_LIGHT mode causes compact_zone() to force a complete scan of the remainder of that block before marking it for skipping.
When the main loop terminates for any reason, any remaining isolated free pages are released back to the buddy freelist.
After looking at overall flow of compact_zone(), next sections describe how each of the compaction stages work.
Migration scanning
Migration scanner starts at or near the lower end of a zone (cc->migrate_pfn) and advances upward towards higher PFNs. Its job is to find migratable pages and put them in the migration list (cc->migratepages). This job is performed at two levels. At first, isolate_migratepages() tries fast search optimisations wherever possible, or does a linear scan, to select the pageblock to scan and then isolate_migratepages_block() selects proper pages from that block. Fast path optimisations lessen the cost of linear scanning and hence are tried first to locate a promising pageblock.
Fast search
For large zones, linear scanning, pageblock by pageblock, to find migration candidates can be slow. isolate_migratepages() therefore calls fast_find_migrateblock() upfront to optionally jump the migration cursor or cc->migrate_pfn to a more promising starting position. Fast search directly looks into buddy freelists to quickly locate a pageblock with free pages. Since fast search is meant to be quick — with linear scanning always available as a fallback — it operates within two constraints: a scan budget controlling how many freelist entries to check, and a target search window defining how far ahead to look. This approach is a heuristic in the sense that the presence of free pages in a pageblock is used as a proxy signal that migrating its movable pages will produce large contiguous free regions, but there is no guarantee that migration will actually succeed from that block. Fast search does not isolate any pages and once it returns linear scanning resumes from updated migration cursor.
Fast search — Deep dive
The scan budget is computed by freelist_scan_limit() using cc->fast_search_fail: each consecutive failure increments fast_search_fail by 1 and halves the budget, so repeated failures progressively restrict how much work the fast path does. The search window upper boundary high_pfn depends on the migration scanner’s position. When starting from zone_start_pfn, high_pfn is set to the pageblock-aligned midpoint of the gap between cc->migrate_pfn and cc->free_pfn (distance >> 1). Once the scanner has moved away from the zone start, the window is tightened to one eighth of that gap (distance >> 3) to avoid jumping too far ahead and leaving migration candidates behind.
fast_find_migrateblock() returns the current cc->migrate_pfn unchanged whenever the fast path is either unsafe or not worthwhile: when skip hints are being ignored (the fast search relies on them to avoid revisits), when cc->finish_pageblock is set (the caller wants the current block finished before advancing), when the cursor is mid-pageblock (treated as a continuation of an in-progress linear scan), when cc->order <= PAGE_ALLOC_COSTLY_ORDER — which also subsumes untargeted compaction (cc->order == -1) — since linear scanning is cheap enough at small target orders, and for direct compaction with a non-MIGRATE_MOVABLE migratetype, where jumping into a MOVABLE pageblock would risk polluting it for an unmovable/reclaimable allocation.
When it does run, it uses a nested loop to locate a promising pageblock. The outer loop iterates orders from cc->order – 1 down to PAGE_ALLOC_COSTLY_ORDER, terminating early if a suitable block is found or the scan budget is exhausted. The inner loop scans the MIGRATE_MOVABLE freelist for each order in the forward direction, stopping on a suitable block or budget exhaustion. For entries within the target window (pfn < high_pfn), the pageblock’s skip hint is checked first — if set the entry is skipped; otherwise move_freelist_tail() moves it to the tail so future scans bypass it. On a successful find, update_fast_start_pfn() records the minimum free PFN seen, pfn is set to the start of the containing pageblock, fast search parameters are updated, and both loops terminate. If the nested loops find a suitable pfn it is returned as the starting point for linear scanning; otherwise cc->migrate_pfn is used.
Linear scanning
Fast search may or may not advance the migration cursor, but after fast search, isolate_migratepages() performs a pageblock-by-pageblock linear scan to identify the first suitable pageblock. The scan window of isolate_migratepages() is limited by boundary of the free scanner (cc->free_pfn) and once a suitable pageblock has been found, isolate_migratepages_block() is called on the pageblock to isolate pages suitable for migration and put those isolated pages into the migration list i.e., cc->migratepages. It should be noted that each invocation of isolate_migratepages() targets at most one suitable pageblock — once found and scanned, the function returns even if no pages could be isolated from it.
Linear scanning — Deep dive
Loop parameters are initialised first: block_start_pfn is set to the start of the pageblock containing the migration scanner’s current position (or the zone start, whichever is higher), block_end_pfn to the end of that pageblock, and fast_find_block is updated to reflect the fast search result to avoid rechecking pageblocks already evaluated there. The scan advances pageblock by pageblock without crossing into the free scanner’s boundary (cc->free_pfn), calling cond_resched() every COMPACT_CLUSTER_MAX pageblocks to avoid monopolising the CPU while scanning large zones.
For each pageblock, a series of checks determine suitability as a migration source. Pageblocks belonging to offline memory or holes are skipped. At the start of a new pageblock, if it was not selected by fast search and skip hints are being obeyed, isolation_suitable() checks the skip hint and skips the block if suggested by skip hint. suitable_migration_source() rejects any pageblock occupied by a compound page spanning pageblock_order or larger, because there is no point migrating a pageblock as a whole. For async direct compaction specifically, the pageblock’s migratetype must be compatible with cc->migratetype (MIGRATE_MOVABLE requests accept MIGRATE_MOVABLE or MIGRATE_CMA blocks), all others require an exact match. Since async direct compactions run with COMPACT_PRIO_ASYNC priority, they are more profligate while selecting suitable migration sources.
Once a suitable pageblock is found, isolate_migratepages_block() is called for per-page isolation. On error, isolate_migratepages() returns ISOLATE_ABORT; otherwise it breaks its loop and returns ISOLATE_SUCCESS or ISOLATE_NONE depending on whether any pages were isolated.
Coming back to isolate_migratepages_block(), it is used in other paths besides memory compaction but this blog describes it only in the context of memory compaction. It begins with a throttle check, since reclaim may be isolating pages from the LRU in parallel with compaction. As long as too_many_isolated() reports that the node has too many isolated pages, the function loops, deciding on each iteration what to do based on context: if pages from a previous isolation round are already pending, it returns -EAGAIN immediately so the caller can drain them; otherwise async compaction also returns -EAGAIN (it cannot afford to wait), while sync compaction sleeps via reclaim_throttle() for a brief period (HZ/50, ~20 ms for HZ=1000) or until pressure eases. After waking, a pending fatal signal yields -EINTR.
isolate_migratepages_block() then walks every page in the pageblock, skipping unsuitable pages cheaply before acquiring the LRU lock. Every COMPACT_CLUSTER_MAX pages the lruvec lock (if held) is dropped, the CPU is yielded, and any fatal signal is checked — a pending signal terminates the loop. On the first iteration of isolate_migratepages_block() — i.e., when no valid page has been encountered yet in this call and the starting PFN is either pageblock-aligned or the zone start — the pageblock’s skip hint is rechecked, and if it is set the entire pageblock is skipped immediately. Once the first valid page has been recorded, this check is not repeated for the remainder of the call, since the caller (isolate_migratepages()) invokes isolate_migratepages_block() once per pageblock anyway.
The following pages are skipped during the walk: HugeTLB pages; free pages in the buddy freelist; compound pages too large to isolate — specifically, for targeted compaction any compound page at or above the target order (migrating it would require a free page at least as large, which would have satisfied the allocation already), and in all cases compound pages at or above pageblock_order; when a non-zero order page is skipped, low_pfn and nr_scanned are advanced accordingly.
For non-LRU pages, if page_has_movable_ops() returns true and the page is not already isolated, the lruvec lock (if held) is dropped and isolate_movable_ops_page() is attempted — on success the page proceeds to isolation; otherwise it is skipped. All other non-LRU pages are rejected.
For LRU pages, additional checks apply: pinned anonymous pages are skipped; under GFP_NOFS only anonymous pages are eligible since file-backed pages may require filesystem locks; unevictable pages are skipped unless vm.compact_unevictable_allowed permits their isolation. In async or sync-light modes, pages under writeback and dirty pages whose mapping lacks a migrate_folio callback are skipped; pages under writeback are skipped because these modes can’t block waiting for I/O to finish; dirty pages whose mapping lacks migrate_folio callback are skipped because these modes can’t use the default fallback_migrate_folio() as that can block on I/O too. For dirty pages with migrate_folio callback, migration just copies the data in memory (no disk I/O) and transfers the PG_dirty flag from source page to destination page inside __folio_migrate_mapping(), leaving the dirty data to be written back at some later time.
Pages passing all checks have the lruvec lock taken (or reused from the previous page if in the same lruvec), are removed from the LRU list, and added to cc->migratepages.
The scan loop may terminate before scanning the full pageblock. If the total isolated pages for this pass has reached COMPACT_CLUSTER_MAX, cc->finish_pageblock is false, and cc->contended is false, the loop breaks early. For async direct compaction the pageblock is further subdivided into cc->order-aligned blocks — if a page within a block is skipped, already-isolated pages from that aligned block are returned and scanning jumps to the next aligned block; if an entire aligned block is successfully isolated, isolate_migratepages_block() returns without scanning the rest of the pageblock.
On loop exit, low_pfn is clamped to end_pfn if a buddy-page advance carried it past that boundary, and the lruvec lock is released if held. If the scan reached end_pfn and either nothing was isolated or cc->finish_pageblock forced a full rescan, the pageblock’s skip bit is set and update_cached_migrate() advances the zone’s cached migrate PFN past this block. Finally, statistics are updated and cc->migrate_pfn is set to low_pfn, recording exactly where this scan ended.
Free scanning
The free scanner starts at or near the upper end of the zone and advances downward, isolating pages, into cc->freepages, to serve as migration destinations. Unlike the migration scanner which runs at the top of compact_zone()‘s main loop, the free scanner runs lazily — it is invoked only when the supply of free destination pages is exhausted. Like the migration scanner, its work is split across two levels: isolate_freepages() selects the pageblock to scan, using fast-path optimisations where possible before falling back to linear scanning, and isolate_freepages_block() performs the per-page isolation within that block. Here too fast-path optimisations are tried first to reduce the cost of linear scanning.
Fast search
isolate_freepages() first attempts a fast search via fast_isolate_freepages(), which looks directly into the buddy freelist to isolate free pages immediately — unlike the migration scanner’s fast path which only advances the scanner position without isolating anything. If fast_isolate_freepages() succeeds, pageblock linear scanning is skipped entirely.
Fast search — Deep dive
fast_isolate_freepages() only operates on targeted compactions with positive orders. Just like in the case of migration scanner, fast search of free scanner also works with a limited budget because linear scanning is there as a fallback.
The fast search runs with a scan budget that bounds how many freelist entries it examines per order. The budget is initialised to max(1, freelist_scan_limit(cc) / 2); on the very first fast search of the zone (when the free scanner is still at its initial position) the budget is overridden to pageblock_nr_pages / 2, allowing a deeper initial search before any per-zone knowledge has been built up. freelist_scan_limit() itself returns (COMPACT_CLUSTER_MAX >> cc->fast_search_fail) + 1, so each consecutive failure — which increments fast_search_fail by 1 — halves the budget seen by subsequent fast-search calls.
The function also restricts isolation to a specific area of the zone using two thresholds derived from the gap between cc->free_pfn and cc->migrate_pfn. low_pfn marks the top quarter of the scan window (preferred); min_pfn marks the top half (acceptable fallback).
Freelist traversal uses a nested loop: the outer loop iterates through orders, the inner loop scans the MIGRATE_MOVABLE freelist for each order. A page found in the top quarter (pfn >= low_pfn) is an immediate success — the fast search state machine is updated and the inner loop breaks. A page found in the top half but not the top quarter (pfn >= min_pfn && pfn > high_pfn, where high_pfn tracks the best fallback PFN seen so far at this order) is recorded as a per-order fallback candidate and the scan budget is halved, since a worst-case fallback now exists. The inner loop breaks when the scan budget is exhausted.
If the inner loop found something in the top quarter, that page is isolated. Otherwise the highest recorded fallback candidate is isolated. If neither exists the outer loop moves to the next order. __isolate_free_page() performs the isolation. The outer loop exits early if cc->nr_freepages >= cc->nr_migratepages.
The outer loop is controlled by next_search_order() rather than a simple decrement, giving a round-robin sweep across orders: it decrements the current order and wraps to cc->order – 1 when it goes below zero. When the sweep wraps all the way back to cc->search_order, every order has been visited once and the loop terminates (next_search_order() returns -1); on its way out it decrements cc->search_order so that the next fast-search call starts one order lower than this one did. Separately, on a successful isolation, cc->search_order is set to the order at which the isolation succeeded — that is what makes follow-up fast searches resume at the productive order; the exhaustion-path decrement is the fallback used when no productive order was found at all.
If all orders are exhausted without isolating anything, cc->fast_search_fail is incremented, reducing the budget for subsequent attempts.
If the first fast search of the zone isolated nothing, cc->free_pfn is updated to optimise subsequent scans. If any free page above min_pfn was observed during the scan, cc->free_pfn is anchored to the pageblock-aligned start of the highest such candidate and fast_isolate_around() attempts to isolate nearby pages within that pageblock. If nothing above min_pfn was seen and this is direct compaction, the pageblock at min_pfn is selected and cc->free_pfn is updated accordingly — the selected page need not itself be free, since fast_isolate_around() will search within the pageblock.
fast_isolate_around() performs a quick linear scan of the entire pageblock identified by the fast search. It exits early if enough free pages are already isolated or if this is async direct compaction. Otherwise it clamps the scan range to the pageblock boundaries within zone limits and calls isolate_freepages_block() to isolate whatever free pages exist. If the scan exhausts the entire pageblock, the pageblock is marked with a skip hint to prevent future scans from revisiting it.
Linear scanning
If fast search fails, isolate_freepages() falls back to linear scanning. Unlike the migration scanner’s fast search, the free scanner’s fast search can actually isolate pages, so linear search is needed only when the fast search fails. isolate_freepages() walks pageblock by pageblock, looking for suitable pageblocks. Its scan window is limited by boundary of the migration scanner, i.e., cc->migrate_pfn. Once a suitable pageblock has been found isolate_freepages_block() isolates free pages from it and puts isolated pages in the freelist i.e., cc->freepages. Again unlike migration scanner, isolate_freepages() does not stop after locating one suitable pageblock and keeps walking subsequent pageblocks until enough free pages have been isolated or isolation of free pages failed partway through a pageblock or of course the scan window has been exhausted.
Linear scanning — Deep dive
Loop parameters are initialised first: isolate_start_pfn is set to cc->free_pfn (where the last scan left off, or the zone top for a first scan), block_start_pfn and block_end_pfn are aligned to the surrounding pageblock boundary (capped at the zone end), and low_pfn is set to the end of the pageblock currently occupied by the migration scanner — this is the hard lower boundary since the two scanners must not cross. stride controls how many pages isolate_freepages_block() skips between candidates within a pageblock: COMPACT_CLUSTER_MAX for async compaction, 1 for sync.
The loop walks pageblock by pageblock from high to low PFN, decrementing block_start_pfn by pageblock_nr_pages each iteration and stopping when it falls below low_pfn. cond_resched() is called every COMPACT_CLUSTER_MAX pageblocks to avoid monopolising the CPU.
For each pageblock, three checks determine suitability:
- pageblock_pfn_to_page() verifies the pageblock contains at least one valid online page — if not, skip_offline_sections_reverse() jumps the scan pointer past the entire offline region in one step.
- suitable_migration_target() checks that the pageblock does not already contain a large-order free block that compaction would have to fragment, and if cc->ignore_block_suitable is false, also restricts to MIGRATE_MOVABLE or MIGRATE_CMA pageblocks.
- isolation_suitable() checks the skip hint if cc->ignore_skip_hint is false.
Pageblocks passing all checks are passed to isolate_freepages_block(). After it returns, the skip hint is set on the pageblock (unless cc->no_set_skip_hint is set) if the full block was scanned, preventing future passes from revisiting it until both scanners have met and cached data is reset. If enough pages are now isolated (cc->nr_freepages >= cc->nr_migratepages) or if isolation failed within the block, the loop terminates. Otherwise stride is adjusted — reset to 1 if any pages were isolated in this pageblock (so the next pageblock is scanned densely, since a productive area was just found), or doubled (capped at COMPACT_CLUSTER_MAX) if nothing was isolated (so sparse areas are skipped over more coarsely on each successive empty pageblock).
isolate_freepages() continues across multiple blocks until one of the three termination conditions is met. On exit, cc->free_pfn is updated to record where the scan left off.
isolate_freepages_block() iterates through the pageblock advancing by stride. Every COMPACT_CLUSTER_MAX pages the zone lock is dropped, the CPU is yielded, and any fatal signal is checked — a pending signal terminates the loop. Compound pages and non-free pages are skipped. For pages that pass these checks, the zone lock is acquired lazily — only at the point a candidate is found rather than upfront — and the page is rechecked for being free since it may have been allocated between the initial check and lock acquisition. If no longer free it is skipped without dropping the lock.
With the lock held and the page confirmed free, __isolate_free_page() performs the actual isolation. It first checks that removing this page will not push the zone below WMARK_MIN — this prevents compaction from draining the zone so aggressively that subsequent allocations fail and trigger reclaim. If the watermark check passes, the page is removed from the buddy freelist. For large isolated blocks (order >= pageblock_order – 1), any spanned pageblocks with a mergeable migration type are converted to MIGRATE_MOVABLE. __isolate_free_page() returns the number of isolated pages (1 << order) on success, or 0 on failure.
An isolation failure of 0 breaks the loop immediately. On success the page is added to cc->freepages at its order and counts are updated; if cc->nr_freepages >= cc->nr_migratepages the loop exits. After the loop the zone lock is released and counts and scan positions are updated. isolate_freepages_block() returns the number of isolated pages, which may be 0.
The handling of isolation failure differs significantly between the two scanners. A failure in isolate_freepages_block() simply breaks the linear scan loop in isolate_freepages() with no further remediation. A failure in isolate_migratepages_block() propagates as ISOLATE_ABORT all the way to compact_zone()‘s main loop, which terminates the entire compaction pass after returning isolated migratable pages to their LRU lists and releasing isolated free pages. This asymmetry makes sense: free pages can be quietly returned to the buddy freelist at cleanup time, but isolated migratable pages are live in-use pages that must be returned promptly, and without migration candidates there is no point continuing the pass.
Page migration
Once migratable source pages have been gathered in cc->migratepages and free destination pages in cc->freepages, the actual migration is performed by migrate_pages(). Migration consists of three things: copying the contents of each source page into a paired destination page, rewriting every page-table entry that points at the source so that it now points at the destination, and finally returning the now- empty source page to the buddy allocator so it can coalesce with its neighbours into a larger contiguous block — which is the whole point of compaction.
migrate_pages() organises this work into three phases that repeat until cc->migratepages has been fully drained or an unrecoverable error is encountered:
- Batching — split cc->migratepages into batches of bounded size so each batch can be processed without holding too many locks at once or accumulating an unbounded TLB-flush backlog.
- Unmapping and pairing — for each batch, walk the reverse mapping of every source folio and replace its real PTEs with migration entries (so any concurrent page fault on the source waits for migration to finish), and pair each unmapped source with a destination folio obtained via the compaction_alloc() callback (which lazily drives the free scanner when destinations run out).
- Content copy and remap — for each unmapped (source, destination) pair, copy the source’s contents into the destination and then walk the reverse mapping again to replace every migration entry with a real PTE pointing at the destination. Once that is done, the source folio carries no live references and is freed back to the buddy allocator.
A successful migration is invisible to user space — the virtual address of the page is unchanged, only its backing physical frame has moved. Migration is also the slowest stage of compaction, so much of the implementation effort goes into making it batchable and into bailing out cheaply when a folio cannot be migrated (e.g. it is pinned, under writeback in async mode, or its mapping refuses to cooperate).
The three subsections below describe each phase. Each opens with a short conceptual summary followed by a Deep dive that covers the involved functions in more detail; the Deep dives can be skipped by readers who only need the conceptual picture, but should be read in full by readers who plan to follow compaction tracepoints or kernel source.
It must be noted that migrate_pages() is shared with paths other than compaction (memory hot-unplug, NUMA balancing, alloc_contig_range, etc.); but the blog describes only the compaction-side behaviour.
Batching
Migration is performed in batches of folios rather than one folio at a time. The main reason is the cost of TLB shootdowns: every unmapped source folio requires a remote TLB flush on every CPU that may have cached its page-table entry, and batching lets the kernel coalesce all those flushes into a single inter-processor interrupt at the end of the batch. A secondary benefit is that holding fewer locks across batch boundaries reduces contention on the LRU and rmap data structures that migration needs to walk.
migrate_pages() creates batches from source folios (cc->migratepages) and then hands it to either migrate_pages_batch() (in async mode) or migrate_pages_sync() (in sync modes). Once a batch has been processed migrate_pages() starts with a fresh batch, if any are left.
Batching — Deep dive
migrate_pages() assembles each batch by walking the from list and accumulating folios until the total page count reaches NR_MAX_BATCHED_MIGRATION (HPAGE_PMD_NR if THP is enabled, or 512 if THP is not enabled; on x86_64, HPAGE_PMD_NR itself is 512 but on other architectures it can be different).
Once a batch has been assembled, it is passed to migrate_pages_batch() or migrate_pages_sync() depending on whether the compaction is happening in async or sync mode. migrate_pages_sync() is a wrapper around migrate_pages_batch(). It first processes the batch in async mode with NR_MAX_MIGRATE_ASYNC_RETRY (3) passes, then falls back to processing each remaining folio individually in true sync mode with up to NR_MAX_MIGRATE_SYNC_RETRY (7) passes per folio. In both cases for actual processing of the batch migrate_pages_batch() is used. The rationale for this two-tier approach in sync mode is that many folios can be migrated without blocking even in a sync context, so the cheap async attempt is tried first to avoid unnecessary serialisation. After each batch, any folios that were split earlier, during batch processing, are collected in split_folios and given one final async retry pass with a single attempt.
After processing each batch, the from list is checked to see if there are more pages to migrate and if there are migrate_pages() starts with a fresh batch.
A fatal error (negative errno) from any batch causes an immediate exit, with split_folios folios moved to ret_folios. On exit, all folios in ret_folios are spliced back into the from list so that the compact_zone() main loop can put them back to their respective lists via putback_movable_pages().
Unmapping and pairing
This phase prepares every source folio in the current batch for the upcoming content copy. For each source folio it (a) decides whether the folio is migratable in the current mode — skipping folios that are pinned, dirty (in async or sync-light), under writeback (in async or sync-light), or otherwise uncooperative; (b) takes the folio lock so nothing else can mutate the folio while we move it; (c) walks the reverse mapping and replaces every real PTE pointing at the folio with a migration entry — a special non-present PTE that traps any concurrent page fault and parks the faulting task until migration completes — and (d) obtains a destination folio via the compaction_alloc() callback, which lazily invokes the free scanner when destinations run out.
Each successfully unmapped source/destination pair is placed on two parallel lists, unmap_folios and dst_folios, that the move phase will iterate in lock-step. After the whole batch has been processed this way, a single batched try_to_unmap_flush() issues one inter-processor TLB shootdown for every PTE that was turned into a migration entry — the optimisation that justifies batching in the first place. Folios that could not be unmapped are either retried in the next pass (transient failures like lock contention or writeback) or moved to the failure list (permanent failures like unsupported mappings).
Unmapping and pairing — Deep dive
migrate_pages_batch() processes one batch of migration candidates at a time. It first unmaps all source folios and pairs them with destination folios, and then moves the content from source to destination. Both of these steps happen in nested loops where the outer loop is controlled by the number of retries and the inner loop processes a list of folios.
At first the nested loop doing unmapping proceeds as follows. For each retry the list of folios for the current batch is traversed and each folio is put through a number of tests and if it fails any of these tests, it is skipped and the next folio in the batch is processed. If the folio is on the deferred split list, is larger than 2 pages and is partially mapped (folio_test_partially_mapped()), try_split_folio() is called to split it now because a partially mapped large folio cannot be migrated cleanly. If THP migration is not supported and the folio is a THP, try_split_folio() is attempted; if splitting fails the folio is moved to ret_folios as a permanent failure. If the source folio’s reference count has dropped to one and it has no movable ops, it means the folio has already been freed and there is no need to migrate it.
For a folio that passes all of the above checks, migrate_folio_unmap() (described further below) is called.
The return codes from migrate_folio_unmap() drive the nested loop: zero means the unmap succeeded and the migration source and target pair are awaiting the move phase; -EAGAIN means a transient condition (lock contention, writeback) requires a retry in the next pass; -ENOMEM means no destination frame was available, which causes the batch to skip to the move phase immediately if there are already unmapped folios waiting (to avoid wasting the work already done), or to abort entirely if there are none; any other error code is a permanent failure and the folio is moved to ret_folios.
After the pass loop exhausts either its retry count or the folio list, try_to_unmap_flush() performs a single batched TLB flush covering all folios whose migration entries were just installed. Batching this flush is a significant optimization since inter-processor TLB shootdowns are expensive.
Coming back to migrate_folio_unmap() (the main function that performs unmapping of migration sources), it first calls get_new_folio() (which for compaction is compaction_alloc()) to obtain a destination frame. If none is available -ENOMEM is returned, otherwise it moves ahead.
Next source and destination folios are locked, in async mode a failed folio_trylock() immediately returns -EAGAIN; in direct compaction, running with PF_MEMALLOC set, blocking on the lock is also refused to avoid deadlocks with readahead; in sync-light mode the lock is acquired only if the folio is already up-to-date, since waiting on I/O completion is too costly for that mode; in full sync mode folio_lock() blocks unconditionally. Once the source is locked, writeback is handled first (if needed). Then for anonymous folios, folio_get_anon_vma() takes a reference on the anon_vma to prevent it from being freed while the folio’s map count drops to zero during unmapping.
The destination folio is then locked via folio_trylock(). For non-LRU movable folios with page_has_movable_ops(), unmapping is not needed at this point — state is recorded and zero is returned immediately, leaving the actual content move to be handled via migrate_movable_ops_page() in the move phase. For mapped folios, try_to_migrate() is called to walk the rmap and replace every real PTE pointing at the source folio with a migration entry. These migration entries trap any concurrent page fault on that address and make the faulting task wait (via migration_entry_wait()), until migration completes, ensuring no process accesses stale data during the copy. Once try_to_migrate() returns, if the folio is no longer mapped, the unmap has succeeded and zero is returned. As mentioned earlier when describing the return value of migrate_folio_unmap(), this places the folio on unmap_folios and its paired destination on dst_folios.
Content copy and remap
This phase (migrate_folios_move()) iterates the locked source and destination folio lists, and for each pair, copies the source folio’s contents into the destination folio and then walks the reverse mapping to replace every migration entry with a real PTE that points at the destination. Tasks that faulted on a migration entry during the unmap window remain blocked in migration_entry_wait(); once the real PTE is installed they are woken up and retry the fault from scratch, this time finding the new PTE and resuming execution as if nothing had happened.
Once the move succeeds the source folio is dropped from the migration list, unlocked, and its last reference is released so the buddy allocator can reclaim the freed frame — turning what used to be a “live” in-use page into raw free memory that compaction can later coalesce. If the move fails mid-flight, the unmap is undone for that pair so no migration entries are left dangling and no destination frame is leaked.
Content copy and remap — Deep dive
Once migrate_pages_batch() has unmapped migration sources and paired them with targets, it invokes migrate_folios_move() to move the content and update PTEs.
migrate_folios_move() iterates the paired unmap_folios and dst_folios lists, calling migrate_folio_move() for each pair.
In migrate_folio_move(), for folios with movable ops, migrate_movable_ops_page() handles the content transfer directly. For all other folios, move_to_new_folio() performs the actual copy and selects the copy mechanism based on the folio’s mapping:
- Anonymous folios that are not in swap cache use migrate_folio() (the generic copy mechanism).
- Anonymous folios in swap cache use the swap-cache migrate_folio callback alongside file-backed folios.
- File-backed folios use mapping->a_ops->migrate_folio if provided (filesystems supply this to handle any private metadata alongside the page content) or fall back to fallback_migrate_folio(), which handles the generic file cache case including waiting for any private buffers.
After a successful move_to_new_folio(), the destination folio is added to the LRU via folio_add_lru(). remove_migration_ptes() then does the rmap walk and replaces every migration entry with a real PTE pointing at the destination folio, allowing faulted tasks that were waiting (in migration_entry_wait()) to wake up. Upon wakeup these tasks will retry the fault from scratch and see the new PTEs installed.
The source folio is then removed from the migration list, it is unlocked, and migrate_folio_done() drops the last reference, allowing the source frame to be freed back to the buddy allocator.
If move_to_new_folio() returns -EAGAIN, the destination folio’s state is re-recorded and both folios remain on their respective lists for another move-phase retry pass. Any other failure triggers migrate_folio_undo_src() and migrate_folio_undo_dst(). migrate_folio_undo_src() re-installs real PTEs pointing back at the source via remove_migration_ptes(), drops the anon_vma reference, and unlocks the source. migrate_folio_undo_dst() unlocks the destination and calls put_new_folio() (compaction_free() in the compaction context) to return it to the free page pool.
Back in migrate_pages_batch(), if the batch exits with folios still on unmap_folios (because -ENOMEM cut the unmap phase short before all folios were processed), migrate_folios_undo() cleans up all remaining pairs by calling migrate_folio_undo_src() and migrate_folio_undo_dst() on each, ensuring no migration entries are left dangling and no destination frames are leaked.
Conclusion
This blog has described the memory compaction mechanism of the Linux kernel, tracing the full path from the triggers that initiate compaction down to the per-page isolation and migration machinery that does the actual work.
A few design themes recur throughout and are worth highlighting as takeaways. Compaction avoids doing more work than necessary at every level — the free scanner runs lazily, cached scanner positions allow successive passes to resume where they left off, fast-path buddy freelist searches skip large sections of the zone in one jump, and skip hints prevent revisiting unproductive pageblocks. Direct compaction escalates aggressiveness gradually across retries, trading latency for thoroughness only when cheaper options have been exhausted, and the deferral mechanism backs off exponentially when a zone repeatedly fails to respond.
The migrate type system and per-pageblock type assignments are the foundation on which all of compaction’s effectiveness rests. By keeping movable and non-movable pages in distinct pageblocks, the kernel ensures that migrating pages out of a movable pageblock typically produces a contiguous free block, rather than scattering free pages across mixed pageblocks where they could not be coalesced. Without this organisation, the migration scanner would find nothing to work with regardless of how sophisticated its heuristics are.
The next blog in this series builds on this foundation and describes the tracepoints and other data exposed by the compaction subsystem and how these tracepoints and other data can be used to diagnose fragmentation and compaction-related issues.