This is a follow-up to the Journal on-disk Data Structures blog. In the previous blog, I covered the on-disk layout of the journal log, the layout of a transaction, and the associated data structures.
In this blog, Let’s discuss journaling algorithms using the ext4 filesystem mounted in data=ordered mode (metadata-only journaling) as an example. By the end of this blog, we will know: What happens when something is modified in the filesystem, how the journal knows about the modifications, and how they are logged. We will also cover how the journal helps recover the filesystem in the event of a crash.
The Core Journal Operations
The journal performs four types of operations that enable it to carry out its responsibilities:
- Committing
- Checkpointing
- Revoking
- Recovery
In an ext4 filesystem mounted with data=ordered mode, only the metadata are journaled. Therefore, all metadata changes made to the filesystem are first written to the journal log. Only after the successful write to the log, are they written to their final locations on the disk. Writing a transaction to the journal log is called committing. Writing those committed transactions to their final on-disk locations is called checkpointing.
A transaction can include one or more modifications, but it is treated as if it is an atomic modification. A transaction is considered committed only if all the changes it includes are written to journal, otherwise it is not considered as committed. On disk, a transaction starts with a descriptor block (or a series of descriptor blocks, if the number of data blocks in the transaction is large), followed by the modified data blocks and ends with a commit block.
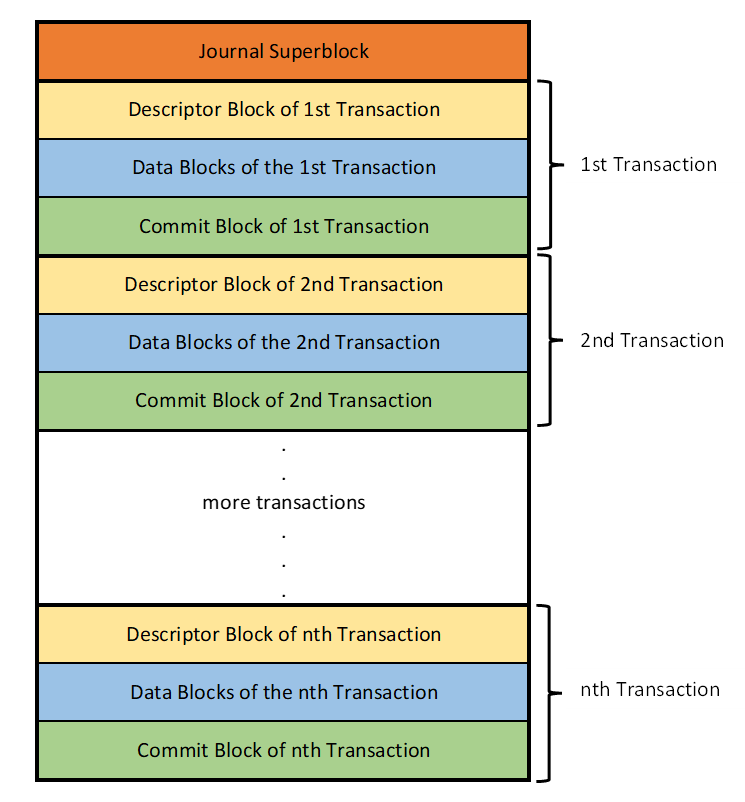
The presence of the commit block at the end indicates that the transaction has been successfully written to the log and is therefore eligible for checkpointing.
The log space used by a committed transaction cannot be reused until the transaction is checkpointed.
Recovery is the process of replaying transactions that were committed but not checkpointed. The recovery restores the filesystem to its last known consistent state in the event of a crash.
Revocation is the process by which the journal is told that certain blocks should not be replayed during recovery. This happens when some changes are no longer required to replay. For example, if a file is created and deleted some time later, the transaction that created the file becomes obsolete. In such cases, a revoke record is created to let the journal know that the blocks associated with that transaction are not to be replayed during recovery. In another words, the revoked blocks are no longer used as medadata by the FS.
The journal control structure.
journal_t is an in-memory data structure that represents the journal and is created when the filesystem is mounted. It maintains the journal metadata that is required for journaling operations.
The following is the journal_t structure with some of the important fields:
struct journal_s
{
...
transaction_t *j_running_transaction;
transaction_t *j_committing_transaction;
transaction_t *j_checkpoint_transactions;
...
unsigned long j_tail;
...
tid_t j_commit_request;
...
int j_max_transaction_buffers;
...
unsigned long j_commit_interval;
...
};
typedef struct journal_s journal_t;j_running_transactionpoints to the transaction that is currently accepting updates.j_committing_transactionpoints to the transaction that is currently being committed.j_checkpoint_transactionspoints to the list of transactions that are ready to be checkpointed.j_tailpoints to the oldest block in use in the journal.j_commit_requestis used to request a commit. It is set to the TID of the transaction that needs to be committed.j_max_transaction_buffersis the maximum number of metadata buffers allowed in a single transaction.j_commit_intervalis the maximum time a transaction can be open before it needs to be committed.
Transaction
transaction_t represents the global transaction that is being built (journal_t->j_running_transaction) and the global transaction that is being committed (journal_t->j_committing_transaction). At any given time, either journal_t->j_running_transaction will be NULL, meaning the journal currently does not have any running transaction, or it will point to a transaction that is accepting updates to be part of it. The same applies to journal_t->j_committing_transaction, either it will be NULL, meaning no transaction is being committed, or it will point to a transaction that is being committed.
Let’s take a look at some of the important fields of transaction_t:
struct transaction_s
{
...
struct journal_head *t_buffers;
...
atomic_t t_outstanding_credits;
...
unsigned long t_expires;
...
};
typedef struct transaction_s transaction_t;t_buffersis a doubly linked circular list that holds the metadata buffers for all the modifications accounted for by a transaction.t_outstanding_creditsgives the number of journal credits (credits refer to journal blocks) the transaction can account for. It accepts new modifications to be part of it as long as it has enough credits to accommodate them.t_expiresgives the deadline of the transaction, after which the transaction becomes due for committing.
Handler
handle_t represents updates performed by a process. It’s main purpose is to account for the journal credits that a process requires to complete its update. The process estimates beforehand the number of journal buffers (i.e credits) required. A handle is attached to the currently running transaction only if the transaction has enough outstanding credits to accommodate the new handle.
struct jbd2_journal_handle
{
union {
transaction_t *h_transaction;
/* Which journal handle belongs to - used iff h_reserved set */
journal_t *h_journal;
};
...
int h_total_credits;
...
};
typedef struct jbd2_journal_handle handle_t;h_transactionpoints to the transaction that the handle is attached to.h_total_creditsgives the total number of journal credits required by the handle.
Journaling Workflow
Let’s walk through the sequence of events from the journal’s point of view that takes place after the filesystem is mounted, and a simple modification (such as creating a directory) is made.
Loading the Journal
When the filesystem is mounted, a journal_t structure is allocated, the on-disk journal superblock is read, and the various fields in journal_t are initialized. In ext4, the journal is stored in inode 8, the exact location of the journal log can be determined from the journal inode’s extent map, and the journal superblock resides in the first block of the journal log. (For more info refer: Journal On-disk Layout) Finally, jbd2_journal_start_thread() is invoked to start kjournald2 journal thread.
Metadata Modification
Let us take the example of creating a directory. This operation involves several metadata changes, such as allocating an inode and updating inode and block bitmaps, inode tables, etc. Before making any changes, the mkdir process roughly estimates the maximum number of journal credits that it may require (i.e., the number of blocks that need to be updated) for it to perform these operations. It then asks the journal to create a handle_t to account for the calculated journal credits by calling jbd2__journal_start(). jbd2__journal_start() returns the handle_t.
handle_t->h_total_credits represents the total journal credits required by the process. Once the handle_t is allocated, the process checks whether the currently running transaction has enough outstanding credits to accommodate the handle. If yes (i.e., journal_t->j_running_transaction->t_outstanding_credits > handle_t->h_total_credits), the handle is attached to the transaction.
If the running transaction’s outstanding credits are not sufficient to accommodate the handle_t, the process waits until the current transaction moves to the commit phase. Then, a new transaction is then created, journal_t->j_running_transaction is updated to point to this new transaction, and the handle_t is attached to it.
Once the handle_t is attached to a transaction, all changes made by the mkdir process become part of journal_t->j_running_transaction. All corresponding buffers are then added to the transaction’s t_buffers list.
Committing
Committing is performed by the journal thread (kjournald2). It usually sleeps and is woken up when the journal_t->j_commit_timer expires. The thread commits the running transaction if the current jiffies cross transaction_t->t_expires (deadline of the transaction, after which the transaction becomes due for committing), or if a transaction commit is explicitly requested (i.e., journal_t->j_commit_request is set with the TID of the transaction being requested to commit). A transaction is committed by a call to jbd2_journal_commit_transaction(). Any handle credits which are not used are returned back to the transaction’s outstanding credits.
jbd2_journal_commit_transaction() after committing the transaction to log, adds the transaction to the list of transactions awaiting checkpointing (journal_t->j_checkpoint_transactions).
Checkpointing
All transactions waiting to be checkpointed are stored in the journal_t->j_checkpoint_transactions list. In the handle allocation path, i.e., in the start_this_handle() function, if the available log space is less than journal_t->j_max_transaction_buffers (the maximum number of buffers allowed in a single transaction), then jbd2_log_do_checkpoint() is called to checkpoint transactions from the journal_t->j_checkpoint_transactions list.
Checkpointing frees up space, which the journal then reclaims for future transactions. As many transactions as necessary are checkpointed to make disk space available for at least more than j_max_transaction_buffers.
Recovery/Replaying from Crash
jbd2_journal_recover() is the primary function responsible for recovering the journal log contents. It is invoked during mount. It checks whether the previous mount ended in a crash by examining journal_t->j_tail. If journal_t->j_tail is zero, (j_tail represents the current log head, it will be 0 if and only if the journal was cleanly unmounted), the filesystem was cleanly unmounted. Otherwise, it indicates that the previous mount ended in a crash, so recovery is started.
int jbd2_journal_recover(journal_t *journal)
{
int err, err2;
struct recovery_info info;
...
if (!journal->j_tail) {
journal_superblock_t *sb = journal->j_superblock;
jbd2_debug(1, "No recovery required, last transaction %d, head block %u\n",
be32_to_cpu(sb->s_sequence), be32_to_cpu(sb->s_head));
journal->j_transaction_sequence = be32_to_cpu(sb->s_sequence) + 1;
journal->j_head = be32_to_cpu(sb->s_head);
return 0;
}
...
err = do_one_pass(journal, &info, PASS_SCAN);
if (!err)
err = do_one_pass(journal, &info, PASS_REVOKE);
if (!err)
err = do_one_pass(journal, &info, PASS_REPLAY);
...
return err;
}Recovery is performed in three passes:
First pass (SCAN)
The goal of the first pass is to find the end of the log, i.e., the last transaction that was successfully written to disk. journal_t->j_tail points to the first block of the log. Since the journal log is circular, j_tail is not always the block immediately following the journal superblock, it can be any block within the log.
To identify the last valid transaction, do_one_pass() iterates over each transaction and verifies the checksums of the descriptor blocks and commit blocks. If the checksum is valid, it proceeds to the next transaction. If an invalid checksum is encountered, the scan stops, and the last valid transaction ID along with its commit block number is reported back to jbd2_journal_recover().
Second pass (REVOKE)
At this point, the end of the log is known. Starting from j_tail and continuing up to the end of the journal log identified in the first pass, the journal scans all revocation records and updates the revoke table (a hash table that maps revoked block numbers to transaction IDs).
Third pass (REPLAY)
This is where the actual replay happens. Each transaction is processed in order up to the end of the log, and for every block, the revoke table is checked:
- If a block is revoked, it is skipped.
- Otherwise, it is replayed.
Replaying a block involves writing it to its final location on disk. After replay, the filesystem will be back in a consistent state, as all incomplete updates are filtered out by the journal.
Conclusion
In this blog, we have covered the journaling algorithms using the ext4 filesystem as an example. We covered the core journal operations: committing, checkpointing, revoking, and recovery. And learnt how these operations enable the journal to ensure data integrity and perform filesystem recovery in the event of a crash.