Introduction
Group scheduling is an important feature of the CFS (Completely Fair Scheduler). It is extensively used in a myriad of use cases on different types of systems. Large enterprise systems use it for containers, user sessions etc. Embedded systems like android use it to segregate tasks of varying importance (e.g. foreground vs background) from each other.
This blog describes CFS group scheduling. It is based on v5.4.267 kernel but it can be used with other kernel versions as well.
CFS group scheduling
Firstly, why do we need group scheduling in the CFS? CFS was developed to implement fairness between individual processes. For example if on a system, at any point of time if there are 25 runnable tasks, of equal priority, CFS would ensure that each of these get 4% of available CPU capacity. But it can happen that 20 of these tasks belong to user Frodo while the remaining 5 belong to another user Samwise. In this case Frodo Frodo ends up with 80% of CPU, compared to Samwise’s 20%. Group scheduling allows us to divide CPU capacity equally or in some other proportion. It can also be used to divide tasks of different importance into different groups (for example in Android) so that too many instances of low importance/priority tasks do not have an adverse impact on scheduling on tasks of higher importance. So group scheduling enables us to implement fairness across users, across processes or a variation of each.
CFS group scheduling was introduced in Linux kernel version 2.6.24 and needs 2 kernel config options, CONFIG_CGROUP_SCHED and CONFIG_FAIR_GROUP_SCHED to get enabled. Users can use the interface provided by the CPU cgroup controller (usually mounted at /sys/fs/cgroup/cpu) to configure and manage task hierarchies, scheduled using group scheduling.
If group scheduling is enabled then there will be a task group, named root_task_group, at the root level. If a task is not part of any specific group of tasks then it belongs to root_task_group. All other task groups are descendants of root_task_group.
Once task groups have been created their CPU utilization limits can be specified using cpu.shares for cgroup v1 or using cpu.weight for cgroup v2. Please see reference 3 for cgroup v1 tunables and reference 4 to cgroup v2 tunables. We will see these parameters in more detail when we see how CFS scheduling works for a group of tasks.
So far we have seen why group scheduling is needed and how it is configured. Next we will delve into the main part of this blog and that is to see how CFS implements group scheduling. I will start with a brief description of task level scheduling in CFS. Once we have an understanding of how CFS works and how different data structures are involved in scheduling of individual tasks, we can utilize this understanding to understand group scheduling, described in later sections.
CFS scheduling for individual tasks (A very brief description):
The Linux kernel uses different scheduling algorithms to schedule tasks of different types (or scheduling policies). CFS scheduling is used for tasks of SCHED_NORMAL (SCHED_OTHER), SCHED_BATCH and SCHED_IDLE policies.
Before looking further into the workings of CFS, let’s first see the main data structures used.
sched_entity: CFS uses scheduler entity or a sched_entity object to keep track of each schedule-able entity. A schedule-able entity can be an individual task or a group of tasks. sched_entity::load indicates the weight (described next), sched_entity::vruntime indicates the virtual runtime of this entity and is used to place it at a proper position in the CPU’s run queue. sched_entity::run_node links the sched_entity with a RB tree sched_entity::sum_exec_runtime indicates the total time this sched_entity spends on CPU and whenever a sched_entity is taken off the CPU its sum_exec_runtime is saved in prev_sum_exec_runtime. The difference between sum_exec_runtime and prev_sum_exec_runtime tells how long a sched_entity has been on a CPU, since its last arrival on that CPU.
load_weight: The weight (load_weight) of a sched_entity determines its CPU time share. For CFS tasks it depends on their priority or nice values (-20 + 19) and these nice values are mapped to weights using the sched_prio_to_weight table. For a group of CFS tasks it is calculated using cpu.shares or cpu.weight mentioned earlier.
task_struct: Kernel maintains all the needed information about a task in a task_struct object. This information includes scheduling related information as well. CFS scheduling related information is contained in task_struct::se which is of struct sched_entity type.
rq: runqueue (rq) contains information about all runnable tasks on a CPU, so it is a per-cpu object. The rq object further contains a scheduling class specific runqueue object. Information about all runnable tasks of a particular scheduling class are kept in a runqueue specific to that class. For CFS, rq::cfs contains this information.
CFS runqueue: Since we are covering CFS, we need to understand the CFS specific runqueue object as well. A CFS runqueue (cfs_rq) object represents a CFS specific runqueue. It is implemented as a time (vruntime) ordered red black (RB) tree. cfs_rq::nr_running indicates the number of runnable CFS tasks on the CPU and cfs_rq::load is the load at runqueue. cfs_rq::min_vruntime is the minimum virtual runtime among virtual runtimes of all the sched entities in the CFS runqueue. It is a monotonically increasing value and sometimes can be bigger than vruntime of the leftmost entity in the CFS RB tree. With cfs_rq::min_vruntime CFS can ensure that when a sleeping task wakes up, its vruntime can be adjusted fairly before placing it back in the CFS RB tree. This ensures that a woken up task does not get unfair treatment because of its vruntime being a lot less less compared to other entities of RB tree. cfs_rq::tasks_timeline is the root of the time ordered RB tree where all sched_entity objects of currently runnable tasks or task groups are kept.
For the remainder of this blog, unless otherwise specified, a runqueue or runq would refer to a CFS run queue.
Having seen the main objects involved in CFS scheduling, let’s see how CFS works for individual tasks. CFS tries to mimic an ideal multitasking CPU. In an ideal multitasking CPU, within each infinitely small unit of time, each running task gets some CPU and all running tasks run in parallel at all points of time. The CPU compute power allotted to each running task may be different (as per their importance or priority) but nonetheless each of them gets some CPU and within any measurable period of time all of these tasks would have run for the same amount of time. Such a parallelism is not always achievable in the real world. For example if there are M runnable tasks on a system with N CPUs (and M > N), then at any point of time only N of these M tasks can be running in parallel.
CFS makes use of a task’s virtual runtime (task_struct.se.vruntime) and its weight (task_struct.se.load.weight) to approximate an ideal multitasking CPU and makes sure to run each runnable task within a specified unit of time known as scheduling period. For CFS, the scheduling period is like the unit time of an ideal multitasking CPU and within this period each runnable task should get some time to run on CPU. A runnable task’s vruntime is the amount of time that it would have spent on an ideal multitasking CPU. Since in an ideal multitasking CPU all runnable tasks would have spent the same amount of time on CPU, ideally vruntime of all runnable tasks should be the same. CFS tries to achieve this goal and hence whenever it has to pick a task, it picks the task with the minimum vruntime.
Ideally the scheduling period (mentioned earlier and calculated by __sched_period) equals sysctl_sched_latency but it gets increased if the number of runnable tasks is more than sysctl_sched_nr_latency. Once selected, a task should run on CPU at least for sysctl_sched_min_granularity nanosecs before being preempted. If it yields the CPU or goes to sleep before that, then it’s okay, but if it remains runnable it should run for at least sysctl_sched_min_granularity nanosecs and this is why if the number of runnable tasks increase, scheduling period gets increased as well. The sysctl_sched_min_granularity ensures the overhead involved in context switching of tasks does not become too much.
When a task is running on CPU, at each scheduler tick its actual runtime (sum_exec_runtime) and virtual run time (vruntime) are incremented as shown below in update_curr:
u64 now = rq_clock_task(rq_of(cfs_rq)); ................... delta_exec = now - curr->exec_start; ................... curr->exec_start = now; ................... curr->sum_exec_runtime += delta_exec; ................... curr->vruntime += calc_delta_fair(delta_exec, curr);
When a task gets on CPU, its curr->exec_start is updated as per runq’s clock (rq.clock_task). Then at each scheduler tick, update_curr updates curr->exec_start as per runq clock. Moreover update_curr also adds the difference between the old and new values of curr->exec_start, into curr->sum_exec_runtime. This is how a task’s actual runtime gets updated, as long as it remains on CPU. When a task has to leave the CPU, update_curr gets invoked again and calculates the runtime delta since the last scheduler tick and accounts for it in the task’s actual runtime. In the above snippet curr corresponds to a sched_entity belonging to a single task or a group of tasks. Besides updating ia task’s actual runtime, update_curr also invokes calc_delta_fair to weight the actual runtime as per sched_entity’s weight (which reflects a task’s priority or a task group’s cpu.share or cpu.weight) and adds this weighted runtime to sched_entity’s vruntime.
If we can ignore some rounding off and overflow checking code, calc_delta_fair basically returns:
delta_exec * NICE_0_LOAD / sched_entity’s weight
This means that for the same amount of time spent on CPU, a higher priority task will have its vruntime increased by less and a lower priority task will have its vruntime increased by more. The slow increase in vruntime of higher priority tasks ensures that their sched_entity(ies) move slowly from left to right in time ordered RB tree of CFS runq and hence these tasks get more chance to run on CPU. Also since CFS tasks of default priority (i.e nice value 0) have a load.weight of NICE_0_LOAD, for such tasks actual and virtual runtimes change at the same rate.
Further at each scheduler tick the current sched_entity’s time quota within the current scheduler period is calculated using sched_slice and this quota is:
scheduler_period * sched_entity’s weight / total load on the CFS runq
So it depends on sched_entity’s weight and total load on the CFS runq and it can be seen from the above equation that higher priority tasks will get a bigger portion of the current scheduler period. If the current task has run for more than its allocated quota within the current scheduler period, it is marked for preemption by setting the TIF_NEED_RESCHED flag. At the next opportune moment the scheduler takes CPU from this task and gives it to the task corresponding to the left most sched_entity in time ordered RB tree of CFS runq.
So far we saw how CFS manages the currently running task on a CPU. But what does it do for a woken up, forked, blocked or terminated task.
CFS tries to remain fair to sleeping tasks as well. A sleeping task does not get its vruntime updated. So when it wakes up CFS adjusts its vruntime before placing the sched_entity in the RB tree of CFS runq. The adjustment in the vruntime of a woken up task is done in a couple of steps. At first a new vruntime for this task is calculated as per following equation:
if scheduler supports GENTLE_FAIR_SLEEPERS feature: vruntime = cfs_rq.min_vruntime - sysctl_sched_latency/2 else: vruntime = cfs_rq.min_vruntime - sysctl_sched_latency
Then sched_entity’s vruntime is set to the maximum of this newly calculated vruntime and sched_entity’s current vruntime. There is a minor possibility that for tasks sleeping for a very long duration the above comparison may give the wrong result (due to overflows), so for such tasks the above calculated vruntime becomes sched_entity’s current vruntime. After adjusting vruntime sched_entity is put into the selected CPU’s CFS runq. Further based on the comparison between vruntime of the woken up task and that of the selected CPU’s current task, selected CPU’s current task can get marked for preemption. For newly created tasks the behavior depends on sysctl_sched_child_runs_first. At first vruntime of a freshly created task is calculated. If the vruntime of the parent is less, then the parent runs first. In such case where sysctl_sched_child_runs_first is set, the child runs first and in such cases if vruntime of the parent is less, it is swapped with vruntime of the child so that the child gets to run first.
When a task blocks or terminates its virtual and actual runtimes are updated and its sched_entity is removed from the time ordered RB tree.
CFS scheduling of group of tasks (task_group(s)):
Having seen CFS scheduling at task level, let’s see how it works at the level of group(s) of tasks. Besides objects that have been introduced earlier, group scheduling introduces another object named task_group. A task represents a group of tasks.
At any point of time a task group can have multiple runnable tasks and on a multi core system these tasks can be on different CPUs. For making group scheduling decisions the scheduler can’t rely on a task’s sched_entity and it needs a sched_entity that represents the whole task group on a CPU. Similarly, the scheduler also needs a CFS runq at the task_group level itself, so that tasks belonging to the task group can be scheduled within the time quota of that task group.
task_group has an array of sched_entity(ies) such that task_group::se[i] is the sched_entity corresponding to this tasks group on the CFS runq of CPU i. A task_group object also has an array of CFS runqs such that task_group::cfs_rq[i] represents the CFS runq owned by this task group on CPU i. All runnable tasks on CPU i and belonging to this task group will have their sched_entity(ies) residing in task_group::cfs_rq[i].
The CFS runq owned by a task group is also pointed to by the my_q member of the corresponding sched_entity or in other words both task_group::cfs_rq[i] and task_group::se[i]::my_q point to the same CFS runq. Besides these a task_group::shares reflects the CPU share specified for this task_group using interfaces such as cpu.shares or cpu.weight from user space and task_group::load_avg is the average load of this task group.
The relationship between top level CFS runq, a task_group and its per-cpu sched_entity and its per-cpu cfs_rq can be best explained using some examples.
First let’s consider that we have a system of one CPU and this system is hosting the following hierarchy of cgroup tasks:

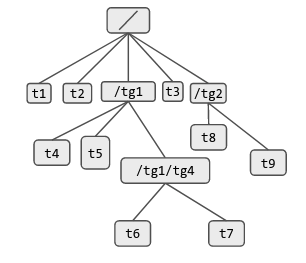
The system may have other cgroups or other tasks as well, but we are considering one cgroup and tasks under it for simplicity.
Figure below shows the CFS runqs, different sched_entity(ies) on these and relationship between these sched_entity(ies) and the corresponding tasks or task groups.

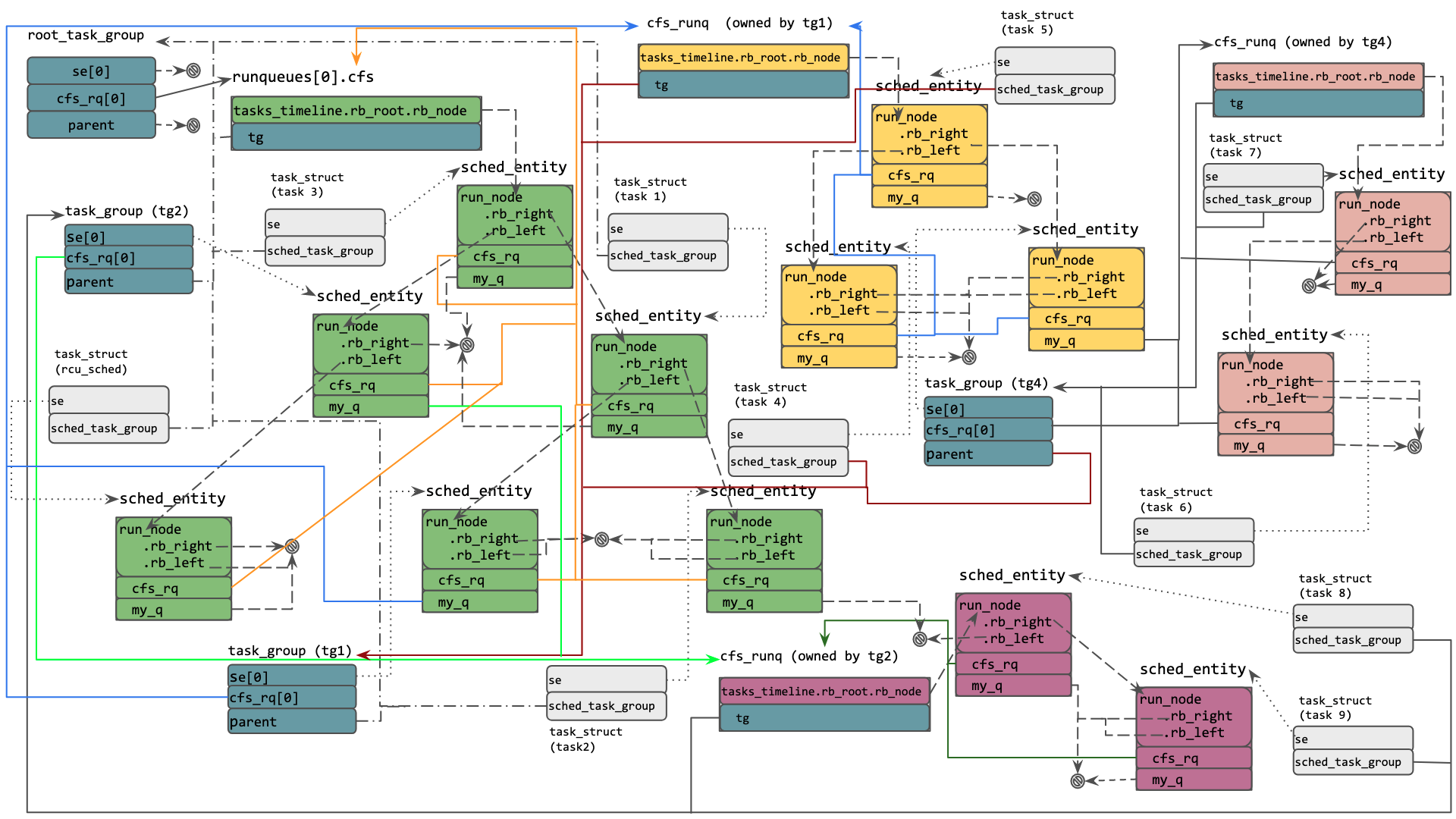
As can be seen there is a top level task_group named root_task_group. As this is a uniprocessor system both the se and cfs_rq arrays of this task_group have just one element. Since the root_task_group will not be scheduled as a whole, it does not reside on any CFS runq and that’s why se[0] is NULL. The CFS runq owned by the root_task_group refers to the top level CFS runq for this CPU and green colored sched_entity(ies) are entities lying on this CFS runq. Some of these entities correspond to individual tasks (t1, t2 , t3 and rcu_sched) while others correspond to task_groups (tg1 and tg2).
Since all of these are lying on CFS runq of CPU 0, they have their cfs_rq pointing to CFS runq of CPU 0. For sched_entities belonging to task_group, task_group::se[0].my_q is the same as task_group::cfs_rq[0]. Yellow colored sched_entity(ies) correspond to tasks and task groups under task group tg1 and hence are lying on the CFS runq owned by tg1.
Further we can see magenta coloured sched_entity(ies) (for t8 and t9) on the runq owned by tg2 and light berry coloured sched_entity(ies) (for t6 and t7) on the runq owned by tg4. Each of these sched_entity(ies) correspond to a task or task_group as per the cgroup task hierarchy shown earlier. The sched_entity(ies) have their cfs_rq pointing to the runq on which they are residing and have their my_q (for task groups) pointing to the runq owned by the corresponding task_group.
It should be noted that even though a task_group has sched_entity(ies) allocated for each CPU, it is not necessary that all of these sched_entity(ies) will be on CFS runqs at all times. The presence or absence of task_group.se[i] on CFS runq of CPU i will depend on whether or not at that point in time the task group has a runnable task on CPU i. Similarly a task_group.cfs_rq[i] may or may not have any runnable tasks.
In order to clarify this further I have also included another example figure for following task groups on an SMP (2 CPU system)

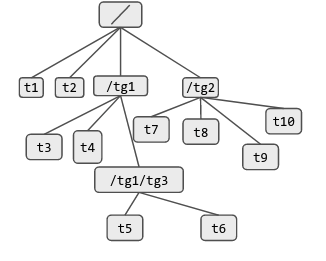
In this case, the runq at CPU 0 has sched_entity(ies) corresponding to t1 and tg2. There is no runnable entity of tg1 on this CPU at this point in time. Similarly runq at CPU 1 has entities corresponding to tg1, t2 and sh and it does not have any runnable entity of tg2 at this point in time. Further we can see different colored sched entities on the CFS runq of task_groups to which they belong. If a task_group does not have a runnable entity on CPU i the RB tree of task_group.cfs_rq[i] is empty and task_group.se[i].on_rq is 0 (indicating that this sched_entity is not on any CFS runq).

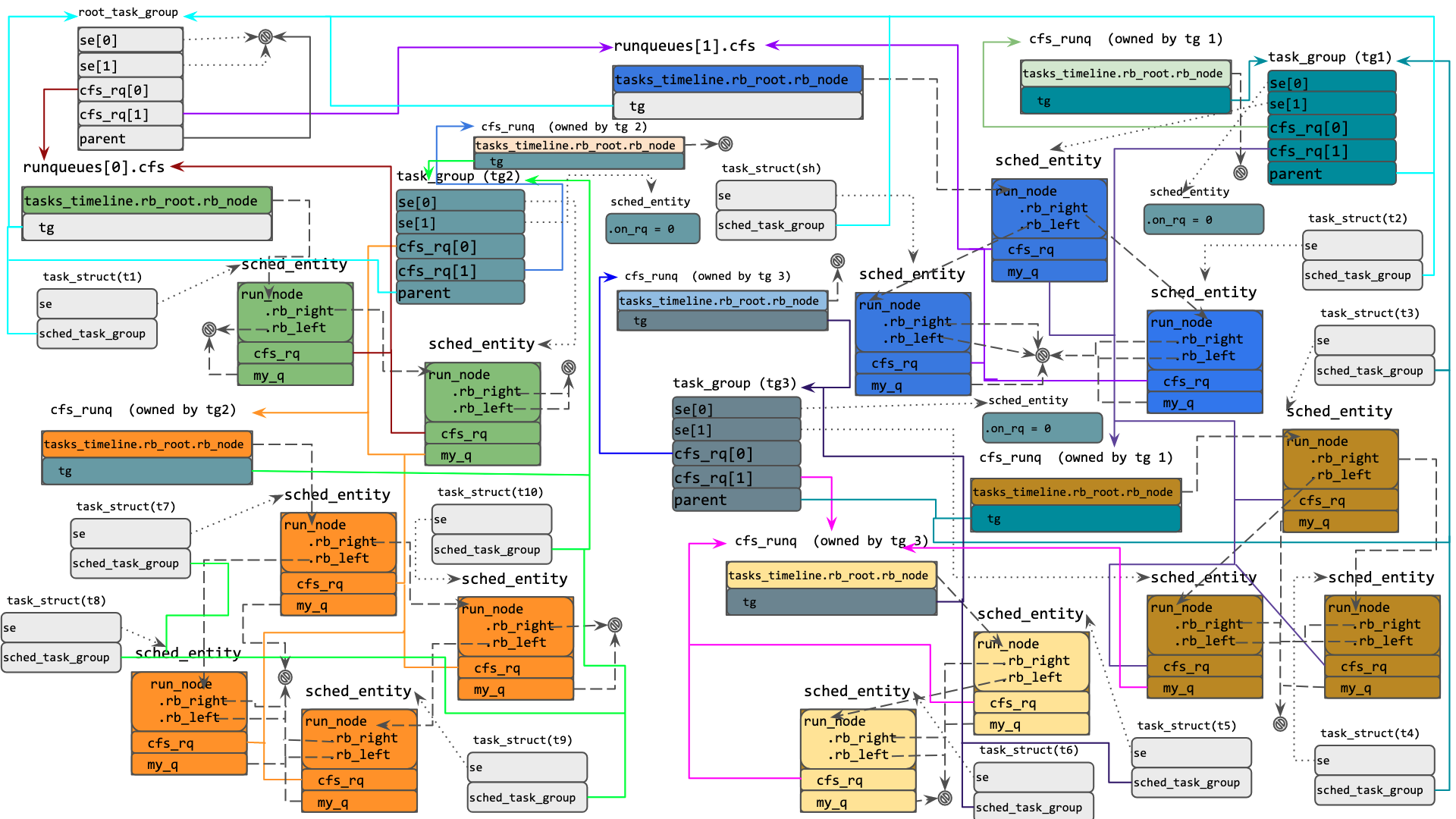
So far we have seen how sched_entity(ies) of a task_group reside on a runq. This runq can be the CFS runq at top level or a CFS runq owned by the task_group. The next thing to see is how these shed_entity(ies) are scheduled.
While looking at CFS scheduling of individual tasks, we saw that actual and virtual runtimes of a task is updated and maintained within its sched_entity and these runtimes are used to make decisions like when a running task needs to be taken off the CPU or which task to pick next to run on CPU. CFS scheduling at task group level also makes use of sched_entity(ies) but it gets a bit more intricate for obvious reasons. For example a task group is given its CPU share, or relative amount of CPU time, as a whole and at any point of time it can have more than one runnable task running on, or in runq of, different CPUs. CFS scheduler needs to ensure that combined CPU shares of a task group’s task do not go beyond the CPU share given to the whole group. Further, tasks of a task group are not always spread uniformly across all available CPUs. For example a task group with 4 tasks on a 4 CPU system can have its 4 runnable tasks on 4 CPUs at one point in time and on 1 or 2 CPUs at other points in time. So the group scheduling mechanism needs to make sure that the task group’s CPU share is divided in the correct proportion between the CPUs. For example the CPU having more runnable tasks of this group should get a larger portion of the task group’s CPU share.
As described earlier, in the group scheduling introduction, a task group’s CPU share is specified using cpu.shares (in cgroup v1) or cpu.weight (in cgroup v2).
Just like priority or the nice value of a CFS task determines its CPU share, cpu.shares or cpu.weight determines a task group’s CPU share. A group’s CPU share is then further divided amongst tasks or groups of tasks within that group. By default cpu.shares is 1024 and cpu.weight is 100. As far as the kernel is concerned both of these values are internally scaled into the same value (NICE_0_LOAD), which is then stored into task_group::shares at the time of task group creation. So by default a CFS task group gets the same amount of CPU time as a CFS task of default priority (nice value 0) at that level of task hierarchy.
For example if we have 3 CFS tasks of nice value 0, and 2 CFS task groups with cpu.shares of 1024 (with any number of tasks) under the root cgroup, then each of the 3 CFS tasks will get 20% of available CPU capacity and each of the 2 CFS task groups will get 20% of available CPU time.
Once a task group has been created one can use cpu.share or cpu.weight interfaces to modify relative CPU time allotted for a task group.
Some examples given below clarify the significance of cpu.shares (or cpu.weight) further. In all of these examples the shown runnable tasks are CPU intensive so we don’t need to bother about them sleeping and hence getting less or no CPU.
In the first example (given below) there are a total 5 runnable tasks with pids 225 to 229. Out of these, pid 228 is a task under test_group_1 and pid 229 is a task under test_group_2. All other tasks are under the root cgroup and have default priority (nice value 0) and both test_group_1 and test_group_2 have default cpu.shares (1024).
We can see below that each of the 5 tasks is getting roughly 20% of CPU:


In the next example shown below, cpu.shares of test_group_1 has been halved and we can see its impact on CPU time of test_group_1:


And lastly in the following example we can see that although both test_group_1 and test_group_2 have default cpu.shares (1024), tasks in test_group_1 are getting roughly half as much CPU as tasks in test_group_2. This is because CPU time given to task_group_1 as a whole is being shared by the 2 tasks under it:


So far we have seen how relative CPU time of a task group is specified and how it takes effect. The stuff that the kernel does underneath to make it all work is the crux of CFS group scheduling.
Firstly the kernel needs to find a task group’s appropriate share on each CPU because the CPU share (task_group::shares) specified using sysfs or similar interface is for the whole group. At any point in time, there can be a different amount of load contribution from a task group’s task(s) on different CPUs. Even some CPUs may have no load at all from this task group’s tasks. So the kernel just can’t divide the whole task group’s share equally between all CPUs. Also it needs to make sure that the task group, as a whole, does not get more than the share specified for it.
When a task group is created all of its per-cpu sched_entity(ies) are given a weight of NICE_0_LOAD. This is fine because right at this point of time we are just creating the task group and it has not got any runnable task on any CPUs yet.
When tasks of a task group start running on one or more CPUs, the weight of its per-cpu sched_entity(ies) (i.e task_group.se[i]) are updated in proportion to its load on that CPU.
The weight of a per-cpu sched_entity can be approximated using the following equation:
task_group.se[i].load.weight = task_group.weight * task_group.cfs_rq[i].avg.load_avg / task_group.load_avg
The CFS scheduler uses this approximation to avoid excessive overhead involved in doing more precise calculations. This weight calculation happens via update_cfs_group which invokes calc_group_shares to determine a CPU’s portion of task_group::shares.
calc_group_shares takes the CFS runq i.e task_group::cfs_rq[i], corresponding to this CPU (CPU i) and based on the load of that CFS runq, determines the share of this CPU from task_group::shares. This share further determines the load weight of this task_group’s sched_entity (task_group.se[i]). This is how each CPU gets a portion (which can be 0 as well) of task_group::shares, proportional to the task group’s running load on that CPU.
Now when/how does update_cfs_group get invoked? update_cfs_group is invoked from entity_tick which itself is invoked for a CPU’s current sched_entity (sched_entity corresponding to CPU’s current task) and its ancestors on each scheduler tick. So a task_group’s running load on each CPU is being accounted for on each scheduler tick. update_cfs_group is also invoked from enqueue_task_fair, dequeue_task_fair, enqueue_entity and dequeue_entity. This ensures that the load contribution of a task_group::cfs_rq[i] and load weight of task_group::se[i] is also updated when a task changes its cgroup or moves from one CPU to another CPU due to load balancing decisions.
The change in cpu.shares or cpu.weight from user space invokes kernel backend sched_group_set_shares which updates task_group::shares and invokes update_cfs_group to adjust according to changed task_group::shares.
So far we have seen how the share of a CPU is decided in proportion to the task group’s load on that CPU but how is a task group’s load kept up to date. A task group’s load is stored in task_group::load_avg and ideally it should be:
task_group.load_avg = sum of (task_group.cfs_rq[i].avg.load_avg)
A task group’s average load is updated in update_tg_load_avg which is invoked with one of its per-cpu CFS runq’s. First the difference between this runq’s current load and its last recorded contribution in task_group’s load is recorded. If this difference is significant i.e more than 1/64th of last recorded contribution then the difference is added to task_group::load_avg and the current load of this CFS runq is recorded as task_group’s last load contribution.
Since small differences are ignored the task group’s load (or average load) is not always the same as the sum of loads at task_group.cfs_rq[i] but it is very close and the difference does not have any adverse side effects. Also if load contribution of a task_group.cfs_rq[i] gets reduced, say because of CPU hot plugging or task migration to different a CPU, the above mentioned delta between current load and last load contribution will become negative and in such a case adding the difference to task_group::load_avg will amount to taking away this CFS runq’s load contribution because its contribution has become 0 or has reduced.
So now we have understood how a task group’s load and weight of its per-cpu sched_entity is calculated. Once this is clear the CFS group scheduling mechanism can be understood easily.
A task group’s sched_entity will reside on a CPU’s main CFS runq or in a runq owned by another task group and its time quota, within each scheduler period, will be decided based on its weight and load at its host CFS runq.
When a task belonging to this task group is running on a CPU, on each scheduler tick task’s virtual and physical run times will be updated and recorded in its sched_entity. This update happens hierarchically in a bottom to top manner and at each level the weight of that level’s sched_entity will be used.
So for a task the load weight specified by its priority and for a task_group the load weight determined by calc_cfs_share will be used. At any level of this hierarchical update if a sched_entity is found to have consumed its quota within the current scheduler period, the current task on CPU will be marked for preemption.
For example in Fig.3 above, if t5 is the current task on CPU and if any of t5, tg1/tg3 or tg1 has consumed their quota within the current scheduler period then t5 will be marked for preemption.
Similarly when the scheduler has to pick a task to run on CPU, it picks the leftmost sched_entity from the main CFS runq’s RB tree. If this sched_entity belongs to a task_group, the scheduler will use the same logic to pick the left most entity from the RB tree of task_group.cfs_rq[i] and this process will continue unless we end up with a sched_entity belonging to a task.
This completes the CFS group scheduling mechanism. We saw how total CPU share of a task group is specified, how CFS makes use of this share and a task group’s running load on CPU i to calculate weight of task_group.se[i], and how CFS makes use of this weight to decide when, and for how long, to run this task group’s task(s) on CPU i.
Conclusion:
This blog described CFS scheduling for individual tasks and groups of tasks. Hopefully the infomation presented here, will help readers in getting a better understanding CFS group scheduling.