Introduction
Ksplice allows our customers to stay up to date without downtime, by live patching code fixes at runtime for the Linux kernel, Xen, Openssl and Glibc. Live patching the kernel whilst it’s running is akin to fixing a plane engine while it is flying.
For live patching to work effectively, Ksplice has a number of safety checks that are run before it applies the live update, one of them is what we call “stack check”. This is essentially a verification that none of the to-be-patched functions are in use (no tasks are either in the middle of executing that function or have them somewhere in their call chain). The check itself is pretty simple, it iterates over all running tasks on the system, and checks all the addresses on their stack and compares them to a list of to be-patched addresses.
The acute reader is likely already thinking about blocking functions in the kernel, say a read() syscall on a network connection, and how that would prevent applying Ksplice updates if we were to patch that function, potentially never allowing Ksplice to do its patching. Well, this article will take a deep dive into how Ksplice (ab)uses the freezer interface already built into the kernel in order to force tasks to get out of the function we want to patch. First, let’s take a step back and talk about suspend/hibernate and how that relates to the freezer, and then to Ksplice.
Suspend and hibernation
In order to reduce power consumption of a laptop whilst running on battery power, the operating system will usually automatically put the system into a low power consumption mode after a certain amount of idle time or when the user closes the lid of their laptop. Multiple levels of power saving exist, each having their pros and cons.
Suspend mode is the fastest one where the laptop is still powered but all peripherals are put in a low power mode. It usually takes only few seconds to exit suspend mode and to resume normal activity, however the laptop is still consuming power even if that’s a lot less than a normally running system.
Hibernation mode is the one where less power is consumed as the laptop is completely shutdown. The drawback of this non existing power consumption mode is the time required to get back to normal activity. Indeed, exiting hibernation is exactly like a normal boot after a complete shutdown of the computer, from the UEFI firmware to the kernel. As opposed to a normal reboot, the state of the computer is restored so the user does not have to restart any applications.
To enter and exit these low power modes, the operating system has to be extremely cautious to not impact the user experience and make sure all peripherals and programs are working as expected.
In this blog post, we are going to describe what is happening in the Linux kernel during such scenarios and we will detail more precisely what is happening to the running processes. Especially how processes (also referred to as tasks) are put in the so-called refrigerator in the Linux kernel. We will also discuss what optimizations have been done to make suspend and hibernation more efficient and finally, we will talk about how Ksplice uses the freezer for live patching.
Differences between suspend and hibernation
From an operating system point of view, the suspend and hibernation of a computer in the Linux kernel requires similar actions to be taken. This is basically notifying all device drivers that suspend/hibernation is taking place, thus making sure all processes are in a ‘safe’ state where it could not impact the suspend/hibernation process.
Having the laptop shutdown in hibernation mode leads to one major difference with regards to the handling of volatile memory. As mentioned above, during suspend, the power of the laptop remains and it only enters a very low power consumption mode. Due to this, Random-Access-Memory (RAM) is still powered and the data it contains remains so the kernel does not have to save its content on non volatile memory. Whereas, during hibernation, every part of the computer is shutdown, RAM included, so the kernel has to save the content of RAM to non volatile memory, usually on a disk drive.
Having to put all peripherals and CPU in a low power state is another major difference as it’s required only for the suspend mode. Indeed, the Linux kernel has to notify all device drivers about the suspend state and make sure all of them configure their peripherals in low power mode and also stop any on-going activity. The same difference applies when exiting suspend state where the kernel also must notify all device drivers.
Now that we know the main differences between suspend and hibernation, we can focus on the internals of hibernation whilst assuming suspend is similar for the part we are interested in.
Hibernation mode overview
A good entry point to understand how hibernation works is to look at the hibernation code in kernel/power/hibernate.c. Especially the hibernate() function, which is called when a user adds disk to the file /sys/power/state. This is actually what happens when systemd is asked to enter hibernation. This function will check if hibernation is possible, acquire required locks, freeze tasks, create a snapshot of RAM and save it on disk before eventually entering hibernation mode.
To examine the complete hibernate() function refer to the following link:
https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/kernel/power/hibernate.c?h=v5.15#n710
At this point, we have a global overview of hibernation mode, we can focus on the freezing of tasks, where freeze_processes() is called.
Why tasks need to be frozen?
One may ask why do we need to put the tasks in the refrigerator before entering hibernation. According to the kernel documentation and especially: https://www.kernel.org/doc/html/latest/power/freezing-of-tasks.html, there are multiple reasons for this.
- Prevent the filesystem from being damaged by having tasks modifying the file system while the computer is entering hibernation.
- Make sure no tasks are doing memory allocation after the hibernation image has been created, otherwise tasks would end up with corrupted memory that may not be restored on resume.
- Prevent tasks from interfering with the hibernation process by any means.
What is the freezer?
The freezer is a mechanism by which tasks are put in an infinite loop in a TASK_UNINTERRUPTIBLE state. This infinite loop is more commonly called the refrigerator. Once tasks are in this state, we are sure they will not get scheduled and will not interfere with the hibernation process.
Here is a brief reminder of what a process state is.
In the Linux kernel, all process information is stored in a list and is represented by a struct task_struct data structure. This data structure from include/linux/sched.h contains all information required by the kernel to handle a task properly. Among many things, it contains the state of the task. of which there are three main states:
- TASK_RUNNING: task is runnable and is running or waiting to run
- TASK_INTERRUPTIBLE: task is sleeping and waiting on a condition. It can go to TASK_RUNNING state when the condition is met or when it receives a signal
- TASK_UNINTERRUPTIBLE: Same as TASK_INTERRUPTIBLE except it can’t be interrupted by a signal
We will now see how the kernel manages to put a task into the refrigerator.
How does the kernel put a task in the freezer?
Overview
Before diving into the code, let’s describe simply what the freezer code is doing. It sets a global variable indicating that the system is being frozen, and then sends a fake signal to all processes to ensure they are all awake. Once woken up, each task will end up calling try_to_freeze() to enter the __refrigerator() function. In this function, the task will be put in a loop and the state set to TASK_UNINTERRUPTIBLE and assumed to be frozen.
Detailed explanation
To make it easier to understand the whole freezer mechanism, we will take a common process as an example: ssh. Most of the time, ssh is waiting on the select() syscall for new data. Here is a typical stack of a ssh process waiting in kernel space:
[<0>] do_select+0x6bb/0x7d0 [<0>] core_sys_select+0x19b/0x3b0 [<0>] kern_select+0xdd/0x170 [<0>] __x64_sys_select+0x1d/0x20 [<0>] do_syscall_64+0x38/0xc0 [<0>] entry_SYSCALL_64_after_hwframe+0x44/0xae
We will refer to this ssh process later on after presenting kernel internals related to the freezer.
Preparation before freezing tasks
As we discussed earlier, the interesting function from the hibernation code is freeze_processes(). Since the implementation may slightly change across kernels, we will use kernel v5.15 as a reference:
int freeze_processes(void)
{
int error;
error = __usermodehelper_disable(UMH_FREEZING);
if (error)
return error;
/* Make sure this task doesn't get frozen */
current->flags |= PF_SUSPEND_TASK;
if (!pm_freezing)
atomic_inc(&system_freezing_cnt);
pm_wakeup_clear(true);
pr_info("Freezing user space processes ... ");
pm_freezing = true;
error = try_to_freeze_tasks(true);
if (!error) {
__usermodehelper_set_disable_depth(UMH_DISABLED);
pr_cont("done.");
}
pr_cont("\n");
BUG_ON(in_atomic());
/*
* Now that the whole userspace is frozen we need to disable
* the OOM killer to disallow any further interference with
* killable tasks. There is no guarantee oom victims will
* ever reach a point they go away we have to wait with a timeout.
*/
if (!error && !oom_killer_disable(msecs_to_jiffies(freeze_timeout_msecs)))
error = -EBUSY;
if (error)
thaw_processes();
return error;
}
The first interesting part is current->flags |= PF_SUSPEND_TASK where the current task gets PF_SUSPEND_TASK flag added to its flags member to avoid having it entering the refrigerator. The current task is the one taking care of putting all tasks into the freezer and entering hibernation so it’s not possible to freeze it. Later on, it will be shown where the PF_SUSPEND_TASK flag is checked.
Remember that each task has a flags field in its associated data structure struct task_struct and this is where PF_SUSPEND_TASK is set.
Once the current task is prevented from entering the freezer, the system_freezing_cnt global variable is atomically incremented if there is no freezing action already in progress, and pm_freezing is set to say it’s in progress.
Actual freezing of tasks
The try_to_freeze_tasks() call is where tasks will actually be frozen after the above preparation steps. The function can be examined via the following link:
https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/kernel/power/process.c?h=v5.15#n31
This basically contains an infinite loop, where for each running and freezable task, freeze_task() will be called. The loop will stop when all required tasks are frozen.
Let’s have a look at freeze_task():
bool freeze_task(struct task_struct *p)
{
unsigned long flags;
if (freezer_should_skip(p))
return false;
spin_lock_irqsave(&freezer_lock, flags);
if (!freezing(p) || frozen(p)) {
spin_unlock_irqrestore(&freezer_lock, flags);
return false;
}
if (!(p->flags & PF_KTHREAD))
fake_signal_wake_up(p);
else
wake_up_state(p, TASK_INTERRUPTIBLE);
spin_unlock_irqrestore(&freezer_lock, flags);
return true;
}
freeze_task() will first make sure that a task can be frozen by checking return values of freezer_should_skip(), freezing() and frozen() respectively.
freezer_should_skip() will be discussed in detail later.
Regarding freezing() and frozen(), it’s interesting to check what flags or global variables are checked as some were mentioned previously.
freezing() and other functions it calls are shown below:
/* Called by freezing() below. */
bool freezing_slow_path(struct task_struct *p)
{
if (p->flags & (PF_NOFREEZE | PF_SUSPEND_TASK))
return false;
if (test_tsk_thread_flag(p, TIF_MEMDIE))
return false;
if (pm_nosig_freezing || cgroup_freezing(p))
return true;
if (pm_freezing && !(p->flags & PF_KTHREAD))
return true;
return false;
}
static inline bool freezing(struct task_struct *p)
{
if (likely(!atomic_read(&system_freezing_cnt)))
return false;
return freezing_slow_path(p);
}
static inline bool frozen(struct task_struct *p)
{
return p->flags & PF_FROZEN;
}
freezing() first ensures system_freezing_cnt has been incremented meaning tasks are allowed to enter the freezer. It then calls freezing_slow_path() which makes sure the task doesn’t have the PF_SUSPEND_TASK flag as it means this is the thread calling freeze_processes() and that should not be frozen as seen earlier.
freezing_slow_path() is also checking that PF_NOFREEZE is not set. It could be set in the case of a task being dead or if it’s a kernel thread. Eventually, it checks the pm_freezing global variable is set and that the task is not a kernel thread among other checks that will not be detailed here to keep it simple.
Back to freeze_task(), after the above checks have passed, the task will actually start to be frozen. If a task is allowed to be frozen, fake_signal_wake_up() will be called. (wake_up_state() is only called for a kernel thread which is a particular case and will be discussed later.)
signal_wake_up() is called from signal_wake_up_state() and sets task thread info flags to TIF_SIGPENDING to notify a signal is pending and also sets all TASK_INTERRUPTIBLE tasks to TASK_RUNNING state so that the scheduler will schedule it.
For already TASK_RUNNING tasks, it calls kick_process() to make sure a task already running on another CPU enters kernel mode by sending an Inter-Processor-Interrupt (IPI) to the other CPU. This way the signal will be handled and the task will be able to enter the refrigerator.
How a task enters the freezer after being woken
Now that a signal is pending for all freezable tasks and that the scheduler will schedule it, these tasks will end up in the refrigerator. From here, multiple events could happen depending on the state of the task. We will start with the most common state from which a task could go into the freezer: TASK_INTERRUPTIBLE.
Before going further, let’s refresh our mind about how a syscall works with an example.
When our ssh userspace process runs and needs to interact with the Linux kernel to read some file descriptors, it will use the select syscall. To trigger a syscall, the process will simply put the syscall number and its arguments in processor registers and execute a specific instruction (SYSCALL on x86_64) which causes the processor to transition to kernel space. The CPU is actually configured so that, when a syscall occurs, it goes to a specific entry point in the kernel. (entry_SYSCALL_64 on x86_64 for example.) From this entry point, the kernel will save the return address from the userspace program among other things, switch to the kernel page table and find the function to call corresponding to the syscall.
This is done in the below function on x86_64.
__visible noinstr void do_syscall_64(struct pt_regs *regs, int nr)
{
add_random_kstack_offset();
nr = syscall_enter_from_user_mode(regs, nr);
instrumentation_begin();
if (!do_syscall_x64(regs, nr) && !do_syscall_x32(regs, nr) && nr != -1) {
/* Invalid system call, but still a system call. */
regs->ax = __x64_sys_ni_syscall(regs);
}
instrumentation_end();
syscall_exit_to_user_mode(regs);
}
syscall_enter_from_user_mode() takes care of getting the syscall number which will let the kernel map it to the corresponding function thanks to the syscall table. The adequate function is then called in do_syscall_x64(). Once done, it calls syscall_exit_to_user_mode() where all required steps are done before returning back to userspace and resuming execution of the process. Among other things, pending signals are handled in syscall_exit_to_user_mode().
Now that we have a global view on how a syscall works, let’s see how our ssh command enters the freezer. As already mentioned, before the freezer woke up ssh task, it’s in the select() syscall, more precisely in the do_select() function, waiting in a while loop in TASK_INTERRUPTIBLE state.
In order to understand what happens internally in the kernel when ssh is being frozen, we can use ftrace and trigger freezing of processes using a power management debug feature.(Note that we could also have used the Freezer cgroup to freeze only one process here)
We first configure the power management framework to stop the hibernation action after all tasks entered the freezer by using the sysfs interface and avoid actually powering down the computer:
$ echo freezer > /sys/power/pm_test
Once done, we can configure ftrace to trace functions for the process ID corresponding to our ssh client:
$ echo function > /sys/kernel/debug/tracing/current_tracer $ echo <ssh_client_pid> > /sys/kernel/debug/tracing/set_ftrace_pid $ echo 1 > /sys/kernel/debug/tracing/tracing_on
And we can now trigger the hibernation process with the following commands:
$ echo platform > /sys/power/disk $ echo disk > /sys/power/state
All tasks will freeze during 5 seconds. After these 5 seconds, it will resume and we can retrieve the ftrace output:
$ cat /sys/kernel/debug/tracing/trace > /tmp/trace $ echo 0 > /sys/kernel/debug/tracing/tracing_on
Since we didn’t enable any filter of functions in the ftrace configuration, the trace is a bit verbose so I have extracted only interesting parts here:
ssh-26494 [003] ..... 43688.833471: tty_poll <-do_select ssh-26494 [003] ..... 43688.833474: __cond_resched <-do_select ssh-26494 [003] ..... 43688.833474: poll_freewait <-do_select ssh-26494 [003] ..... 43688.833476: poll_select_finish <-kern_select ssh-26494 [003] ..... 43688.833476: syscall_exit_to_user_mode_prepare <-syscall_exit_to_user_mode ssh-26494 [003] d.... 43688.833476: exit_to_user_mode_prepare <-syscall_exit_to_user_mode ssh-26494 [003] ..... 43688.833476: arch_do_signal_or_restart <-exit_to_user_mode_prepare ssh-26494 [003] ..... 43688.833477: get_signal <-arch_do_signal_or_restart ssh-26494 [003] ..... 43688.833477: uprobe_deny_signal <-get_signal ssh-26494 [003] ..... 43688.833477: __cond_resched <-get_signal ssh-26494 [003] ..... 43688.833477: rcu_all_qs <-__cond_resched ssh-26494 [003] ..... 43688.833477: freezing_slow_path <-get_signal ssh-26494 [003] ..... 43688.833477: cgroup_freezing <-freezing_slow_path ssh-26494 [003] ..... 43688.833477: rcu_read_unlock_strict <-cgroup_freezing ssh-26494 [003] ..... 43688.833477: __refrigerator <-get_signal ssh-26494 [003] ..... 43688.833479: schedule <-__refrigerator>
As we can see, the do_select() function returns, causing the kernel to try to switch to user mode as when any syscall returns using syscall_exit_to_user_mode(). From here, it ends up in exit_to_user_mode_prepare() where it detects a signal is pending thanks to the thread_info flag TIF_SIGPENDING and then calls arch_do_signal_or_restart().
Here, get_signal() is called and that’s where the kernel calls try_to_freeze():
static inline bool try_to_freeze_unsafe(void)
{
might_sleep();
if (likely(!freezing(current)))
return false;
return __refrigerator(false);
}
static inline bool try_to_freeze(void)
{
if (!(current->flags & PF_NOFREEZE))
debug_check_no_locks_held();
return try_to_freeze_unsafe();
}
try_to_freeze() is actually checking if all conditions to enter the freezer for this task are met. If it does, it calls __refrigerator() as we can see in the trace. Here is the code for this function:
/* Refrigerator is place where frozen processes are stored :-). */
bool __refrigerator(bool check_kthr_stop)
{
/* Hmm, should we be allowed to suspend when there are realtime
processes around? */
bool was_frozen = false;
unsigned int save = get_current_state();
pr_debug("%s entered refrigerator\n", current->comm);
for (;;) {
set_current_state(TASK_UNINTERRUPTIBLE);
spin_lock_irq(&freezer_lock);
current->flags |= PF_FROZEN;
if (!freezing(current) ||
(check_kthr_stop && kthread_should_stop()))
current->flags &= ~PF_FROZEN;
spin_unlock_irq(&freezer_lock);
if (!(current->flags & PF_FROZEN))
break;
was_frozen = true;
schedule();
}
pr_debug("%s left refrigerator\n", current->comm);
/*
* Restore saved task state before returning. The mb'd version
* needs to be used; otherwise, it might silently break
* synchronization which depends on ordered task state change.
*/
set_current_state(save);
return was_frozen;
}
We can see the current state of the task will be saved (TASK_RUNNING in our case) and an infinite for loop will be entered. In this loop, the task is set to TASK_UNINTERRUPTIBLE state and it’s struct task_struct flags is set to PF_FROZEN indicating it’s in the refrigerator. It will stay in this loop until the below check resolves to false and PF_FROZEN flag is cleared:
if (!freezing(current) ||
(check_kthr_stop && kthread_should_stop()))
current->flags &= ~PF_FROZEN;
schedule() function will be called to tell the scheduler to schedule other tasks as this one is in TASK_UNINTERRUPTIBLE state and doesn’t need to be scheduled any more. That’s done, our ssh process is now in the freezer!
Here is brief overview of what could happen for other states of a task:
- If the task is in TASK_RUNNING state, the kernel will call kick_process() as mentioned earlier to interrupt the process and make sure it enters kernel mode to handle the fake signal and enter the freezer
- If the task is in TASK_UNINTERRUPTIBLE state, it will not be set to TASK_RUNNING state as it can’t be awoken by a signal. It will actually make the freezing of tasks fail unless this task called freezable_schedule() for example. We will discuss this case later on in Optimizations
Great, now we have our ssh process in a refrigerator, it’s cold there, how do we exit ?
How a task exits from the freezer?
Remember that our ssh process called schedule() and is in TASK_UNINTERRUPTIBLE state so it’s not going to be scheduled unless its state is changed to TASK_RUNNING. In the hibernation code, we have a function called software_resume() in kernel/power/hibernate.c. This function is called when exiting from hibernation once the kernel is almost done booting and all the devices have been initialized. It will basically check if a hibernation image is available and restore it if found.
It will then resume tasks that were frozen by calling thaw_processes(). This function will call __thaw_task() for each process:
void __thaw_task(struct task_struct *p)
{
unsigned long flags;
spin_lock_irqsave(&freezer_lock, flags);
if (frozen(p))
wake_up_process(p);
spin_unlock_irqrestore(&freezer_lock, flags);
}
If a task is frozen, wake_up_process() will be called. This effectively moves the task to TASK_RUNNING state, ensuring the scheduler processes the task.
Back to our ssh process, we actually have an ftrace of the resume given we stopped the tracing after all tasks were resumed. Here is a simplified version of it:
ssh-26494 [003] ..... 43703.973832: _raw_spin_lock_irq <-__refrigerator ssh-26494 [003] d.... 43703.973884: dequeue_signal <-get_signal ssh-26494 [003] d.... 43703.973884: recalc_sigpending <-dequeue_signal ssh-26494 [003] d.... 43703.973884: fpregs_assert_state_consistent <-exit_to_user_mode_prepare ssh-26494 [003] d.... 43703.973885: switch_fpu_return <-exit_to_user_mode_prepare
We can see it exits the __refrigerator loop before eventually returning to exit_to_user_mode_prepare() where it actually restores ssh context and switches back to it. Our task is now awake and will most likely call select() syscall again.
Optimizations
As described before, to enter the freezer, we iterate all tasks, send a fake signal, wake up the task and wait for it to enter the refrigerator after it unwinds its stack up to syscall_exit_to_user_mode(). With thousands of tasks running, all those steps could be cumbersome and time consuming, this is why some optimizations have been implemented since the first iteration of the freezer code.
Tasks that are not holding resources and are in TASK_UNINTERRUPTIBLE state could be considered frozen if they use some of the optimizations that were done in the following commit range from the Linux kernel git repository: 1b1d2fb4444231f25ddabc598aa2b5a9c0833fba..dd5ec0f4e72bed3d0e589e21fdf46eedafc106b7
If a task is waiting on an event in TASK_UNINTERRUPTIBLE state, freezable_schedule() could be called instead of schedule(). This will let the task enter the freezer directly if the task is scheduled or simply leave the task in it’s current state assuming it’s frozen enough.
Functions listed below will be called in this case:
static inline void freezer_do_not_count(void)
{
current->flags |= PF_FREEZER_SKIP;
}
static inline void freezer_count(void)
{
current->flags &= ~PF_FREEZER_SKIP;
/*
* If freezing is in progress, the following paired with smp_mb()
* in freezer_should_skip() ensures that either we see %true
* freezing() or freezer_should_skip() sees !PF_FREEZER_SKIP.
*/
smp_mb();
try_to_freeze();
}
static inline void freezable_schedule(void)
{
freezer_do_not_count();
schedule();
freezer_count();
}
freezable_schedule() will call freezer_do_not_count() to set PF_FREEZER_SKIP so that the freezer code doesn’t send a signal to the task nor wake it up. If the task for some reason gets scheduled, it will call freezer_count() where it clears PF_FREEZER_SKIP and will try to enter the freezer. Note that if the task is not scheduled, it will be considered as already frozen even if it’s not in the refrigerator.
Kernel threads
By default, all kernel threads have the PF_NOFREEZE flag set, meaning that the freezer code will never try to wake it up to put it into the freezer. Also remember in the freezing_slow_path() checks, we were checking if PF_KTHREAD was set in the list of task_struct flags. If it is set, the task doesn’t get frozen.
So how does a kernel thread enter the freezer? Let’s have a look at freezing_slow_path() again to understand how:
/* Called by freezing() below. */
bool freezing_slow_path(struct task_struct *p)
{
if (p->flags & (PF_NOFREEZE | PF_SUSPEND_TASK))
return false;
if (test_tsk_thread_flag(p, TIF_MEMDIE))
return false;
if (pm_nosig_freezing || cgroup_freezing(p))
return true;
if (pm_freezing && !(p->flags & PF_KTHREAD))
return true;
return false;
}
As we can see the only way for a kernel thread to cause freezing_slow_path() to return true is to have pm_nosig_freezing or cgroup_freezing(p) also returning true. The cgroup_freezing() function is part of the Freezer controller that provides a way to freeze and unfreeze all tasks in a cgroup. As it’s a bit out of scope, we will ignore it here.
Looking for pm_nosig_freezing in the kernel, we encounter the freeze_kernel_threads() function:
int freeze_kernel_threads(void)
{
int error;
pr_info("Freezing remaining freezable tasks ... ");
pm_nosig_freezing = true;
error = try_to_freeze_tasks(false);
if (!error)
pr_cont("done.");
pr_cont("\n");
BUG_ON(in_atomic());
if (error)
thaw_kernel_threads();
return error;
}
Here pm_nosig_freezing is set to true, and then try_to_freeze_tasks() is called allowing kernel threads which don’t have the PF_NOFREEZE flag set to be frozen. That’s how a kernel thread could enter the freezer.
However when a kernel thread is created, the PF_NOFREEZE flag is set, meaning that, by default, a kernel thread cannot enter the freezer. It is assumed that all default non freezable kernel threads are non threatening, and therefore by not freezing they will not hurt the system.
For kernel threads which need to enter the refrigerator due to constraints related to hibernation, the PF_NOFREEZE flag is cleared by calling set_freezable() from the thread. Here is an example of a freezable thread:
static int a_kernel_thread(void *arg)
{
set_freezable();
while(!kthread_should_stop()) {
try_to_freeze();
/* Do some stuff */
set_current_state(TASK_UNINTERRUPTIBLE);
schedule();
}
return 0;
}
For threads identified in freeze_kernel_threads() the kernel will end up calling freeze_task(), which we discussed above where we mentioned that wake_up_state() was only called for kernel threads:
if (!(p->flags & PF_KTHREAD))
fake_signal_wake_up(p);
else
wake_up_state(p, TASK_INTERRUPTIBLE);
And that’s exactly what will happen here, wake_up_state() will simply change the state of the task to TASK_RUNNING so that it gets scheduled. No signals are sent to kernel threads as it’s not needed. When being scheduled, the thread will call try_to_freeze() and enter the freezer.
How Ksplice (ab)use the freezer
Now that we have seen how the freezer works, let’s see how Ksplice uses it to ease livepatching. First of all, let’s get a very brief overview of how livepatching works for general cases.
Let’s assume the current version of a function in the kernel leads to a security issue and must be patched to make sure this vulnerability cannot be exploited by an attacker. Ksplice will first compile the original code of this function, apply the patch fixing the security issue and compile the new code for this function.
From here, an update will be generated by diffing both generated objects. An update is actually a set of kernel modules containing the Ksplice core code, a representation of the running code and the new code.
When applying the update on a running kernel, all Ksplice modules from the update will be loaded and all symbols will be discovered either by the kernel module loader or by the Ksplice core code. First operation to take place is the run-pre matching which consists of comparing the ‘old’ code and the code running in the kernel. This helps making sure the running code matches what we expect.
Once done, Ksplice will add a trampoline at the beginning of the target function to make sure it jumps to the new code (the new version of the function) next time it’s called.
To ensure this process of livepatching is safe, multiple checks are taking place. One of them is the stack check of each process as we must ensure the target function is not on the stack of any processes. Otherwise, once livepatching is done, when the task will unwind its stack, it could end up executing deleted or invalid code and this could lead to unpredictable behavior. When a task has the target function on its stack, Ksplice utilizes the kernel freezer to put the stack in the refrigerator so that its call stack is unwound up to the refrigerator function.
To understand better what happens, let’s get back to our ssh process and its call stack:
[<0>] do_select+0x6bb/0x7d0 [<0>] core_sys_select+0x19b/0x3b0 [<0>] kern_select+0xdd/0x170 [<0>] __x64_sys_select+0x1d/0x20 [<0>] do_syscall_64+0x38/0xc0 [<0>] entry_SYSCALL_64_after_hwframe+0x44/0xae
Now let’s say, do_select() has a vulnerability and needs to be patched using Ksplice. Ksplice will look for the do_select() address on the stack of each task and will find it in our ssh process. From here, Ksplice will use the freezer to put the ssh process in the refrigerator.
Attentive readers will notice that it’s currently not possible to put a single task into the freezer given all the checks actually made by the kernel before entering the freezer. That’s why Ksplice applies a first update to the kernel, which modifies the freezer code to support freezing a single task from the Ksplice code module. Essentially Ksplice applies a Ksplice update on the refrigerator to be able to apply further Ksplice updates.
After entering the freezer, the call stack of our ssh process would look like:
[<0>] __refrigerator+0x44/0x120 [<0>] get_signal+0x8dc/0x910 [<0>] arch_do_signal_or_restart+0xed/0x790 [<0>] exit_to_user_mode_prepare+0x11f/0x210 [<0>] syscall_exit_to_user_mode+0x18/0x40 [<0>] do_syscall_64+0x48/0xc0 [<0>] entry_SYSCALL_64_after_hwframe+0x44/0xae
As we can see, do_select() does not appear on the stack, and theoretically the Ksplice update can be applied. However in reality, Ksplice is checking all bytes on the stack of the process, meaning we could end up with do_select() still on the stack even if does not appear on the call stack.
Ksplice is checking all bytes on the stack as opposed to the call stack only to ensure a pointer to the target function is not present on the stack. This could lead to an indirect call to the old function resulting in unpredictable behavior.
To explain how we can have garbage on the stack, we will use the stack from the ssh process:
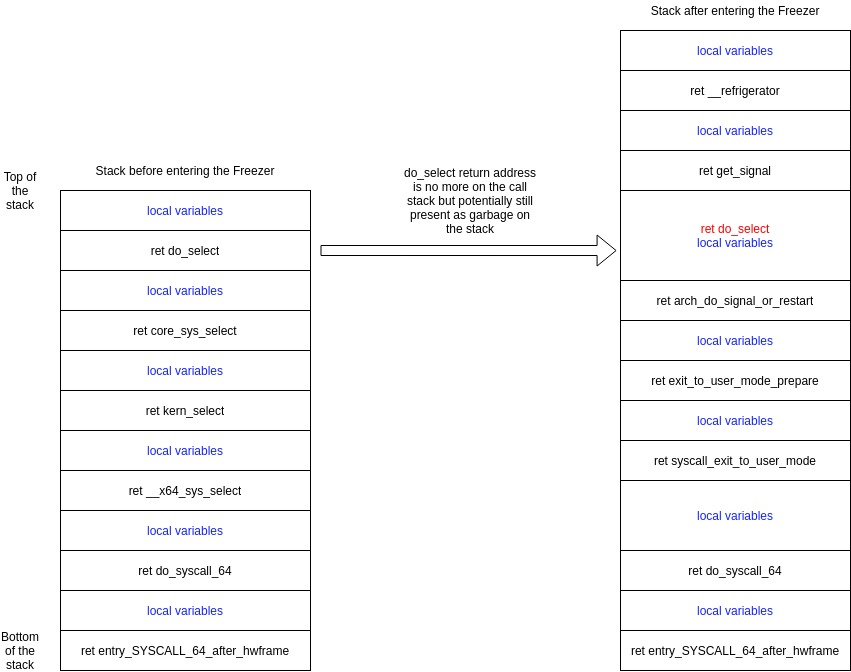
Before entering the freezer, an address from do_select() is present on the call stack, this is the return address to where the CPU must jump after the function returns. After entering the freezer, this address is not on the call stack but can still be present on the stack if it didn’t get erased by the new elements of the stack.
This could happen if no local variables etc were placed at the stack address where the return address of ‘do_select()’ was.
To avoid false positives and ignore garbage on the stack, Ksplice is adding a hook in the signal handling code where all the bytes above the current stack pointer are cleared before entering the refrigerator. This way, any garbage on the stack is zeroed.
Conclusion
The Ksplice team often has to deal with kernel internals to either help livepatching or simply handle features from the kernel interfering with the livepatching process.
If this kind of work sounds interesting to you, consider applying for a job with the Ksplice team! Feel free to drop us a line at ksplice-support_ww@oracle.com.