*** Post atualizado em 17 de dezembro de 2025 ***
Disclaimer
Este post serve como um complemento aos procedimentos oficiais de atualização do OCVS (links abaixo), para ajudar no planejamento, execução e troubleshooting.
Antes de qualquer intervenção em seu ambiente OCVS:
- Sempre faça backups de todos os componentes, conforme descrito no Guia Oracle para atualização (link abaixo);
- Abra uma SR proativa com pelo menos 15 dias de antecedência (consulte seu CXM para obter os procedimentos);
- Coloque na SR o máximo de detalhes possível, tais como: data/hora da janela; versão atual do ambiente; versão para a qual atualizarão; contatos dos responsáveis pela atualização (telefone e e-mail); quais componentes serão atualizados por janela (em caso de upgrade faseado); etc…
- Como em toda atualização de ambientes VMware, checar a Matriz de Compatibilidade, para garantir que as novas versões sejam todas compatíveis entre si, e também com outros produtos conectados (ex.: vROps, SRM, soluções de backup como Veeam e Commvault, etc…).
Em caso de problemas e/ou dificuldades, acione o suporte mencionando a SR Proativa. Isso agiliza a atuação do time.
Material Oficial
Guia Oracle para atualização – Upgrade an Oracle Cloud VMware Solution Software-Defined Data Center from 7.x to 8.x
Vídeo demonstrando, na prática, o processo completo de atualização (ative as legendas) – Oracle Cloud VMware Solution | Upgrade V7 to V8
Modelo de Plano de atualização
1. Atualização do HCX – Tempo total estimado: 2 horas (depende da quantidade de appliances NE/IX/WO/etc…).
1.1. Atualizar o HCX Manager na Cloud;
1.2. Atualizar o HCX Connector em On-Premises;
1.3. Atualizar os Appliances de IX, WO, NE e dos demais serviços que estiverem ativos.
• O Interconnect é responsável pelas migrações de VMs. Se houverem migrações em andamento, elas serão canceladas.
• As Network Extensions são o data plane das redes estendidas entre on-premises e Cloud. Durante o upgrade, este tráfego tem interrupção (algumas perdas de pacotes. Semelhante a um vMotion).
Documentação de update do HCX (selecionar a versão correspondente): https://techdocs.broadcom.com/us/en/vmware-cis/hcx/vmware-hcx/4-8.html
2. Atualização do NSX OCVS – Tempo total estimado: 8 horas.
2.1. [Pré-requisito] – Validar se as senhas de root, admin e audit não estão expiradas ou requerem reset;
2.2. Baixar o arquivo .mub que será fornecido no portal OCI, quando a atualização do SDDC for iniciada;
2.3. No NSX, selecionar System -> Updates, fazer o upload do arquivo .mub;
2.4. Atualizar o NSX Edge Cluster – Há indisponibilidade no chaveamento entre os Edges Ativo/Passivo (algumas perdas de pacotes. Semelhante a um vMotion);
2.5. Atualizar o NSX nos hosts ESXi (~30 minutos por host); os hosts não são reiniciados após atualização dos módulos do NSX neles;
2.6. Atualizar o Management Plane (esse passo demora bastante ~2 horas).
Obs.: Em geral, durante as atualizações, reservamos um dia para atualizar o NSX e o dia seguinte para atualizar todo o resto.
3. Atualização do vCenter – Tempo estimado: 1 hora.
3.1. [Pré-requisito] – Um IP livre da rede vSphere, para ser o IP temporário do novo appliance do vCenter versão 8;
3.2. [Pré-requisito] – Colocar o DRS em modo Manual e anotar o host ESXi em que o vCenter está, para se for necessário acessá-lo para tomar alguma ação na VM. Não desabilitar o DRS, para não perder as resource pools! Apenas colocar em Manual e voltar depois;
3.3. [Pré-requisito] – Verificar se os Core Dumps dos hosts ESXi estão sendo enviados para o vCenter. Caso positivo, alterar o parâmetro do serviço netdumper. Verificar a seção Troubleshooting, no final deste guia;
3.4. Baixar o arquivo .iso que será disponibilizado no portal OCI e montar num Jump Server, fazer o upgrade pelo assistente.
4. Provisionar novos hosts ESXi – (~30 min no portal + ~15 min no vCenter)
4.1. Para cada host do SDDC, provisionar um novo host pelo portal (usando o assistente de atualização);
4.2. No vCenter, adicionar o host no Datacenter, dentro do vCenter, usando o hostname fornecido (Datacenter -> Add Host). Não adicionar direto no cluster!;
4.3. Adicionar o host no vDS, fazendo a correspondência entre os Port Groups;
4.4. Mover o novo host para dentro do cluster. No assistente, selecionar a opção para gerenciar o host via Lifecycle Manager – NÃO selecionar “Manage this host with a single image”!!!
4.5. Se usar vSAN, adicionar os discos do host no Disk Group de vSAN;
4.6. Tirar o host de Maintenance Mode, mover uma VM para dentro dele, testar;
4.7. Repetir para os demais hosts.
5. Remover os hosts antigos – (Depende da volumetria de dados no Host)
5.1. Para remover os hosts antigos, colocá-los em Modo de Manutenção (se forem DenseIO com vSAN, selecionar a opção Full Data Migration);
5.2. Remover o host do cluster, acompanhar a desinstalação do NSX pela interface web do NSX;
5.3. Disconnect;
5.4. Remove from Inventory;
5.5. Terminate do host no portal OCI (como a atualização está a decorrer, entrar no host e haverá uma opção especial de Terminate – caixa de texto amarela, na parte superior);
5.6. Validar que o Billing do host antigo foi transferido para o novo.
Obs.: durante a atualização, não há “Grace Period” no período em que o host antigo e o novo permanecem ativos simultaneamente no SDDC, como acontece em caso de Host Replacement por a falha de hardware.
6. Atualizar o formato dos discos de vSAN – Tempo estimado: 10 minutos
6.1. Após concluídas as atualizações do vCenter e hosts, se usar vSAN, podemos atualizar os discos de vSAN para a última versão;
6.2. Cluster -> Configure -> vSAN -> Disk Management -> Upgrade.
Somente metadados são atualizados, não há evacuação/migração de dados.
⚠️ Pontos de Atenção ⚠️
1. Prepare-se com antecedência, certificando-se de que o NSX e o vCenter estejam saudáveis. É possível rodar o pre-check no NSX usando o arquivo .pub disponibilizado no portal OCI, antes de atualizar. Assim, pontos que impeçam de seguir com a atualização do NSX podem ser corrigidos com tempo antes da atualização. Entre na VAMI do vCenter (porta 5480) e verifique se não há erros ou warnings. Certifique-se de que não hajam partições cheias no VCSA. Certifique-se de que os usuários admin, root e audit (NSX), bem como root e admin (vCenter) não estejam com as senhas expiradas e/ou bloqueados. Recomenda-se fazer tudo isso antes do dia do upgrade, evitando ter que parar para fazer troubleshootings durante a janela de atualização.
2. Certifique-se de que os certificados e senhas não estejam expirados, especialmente no NSX. Isto é apontado pelo pre-check com o arquivo .pub, conforme mencionado no item 1. Caso tenha problemas nos certificados do NSX, use o scrit CARR, disponível na seção Troubleshooting mais abaixo, para corrigí-los automaticamente.
3. O vCenter requer um endereço IP temporário na rede vSphere (port group no switch distribuído), para implantar um novo VCSA. Procure e anote este IP antes da atualização, bem como máscara, gateway e servidores DNS da rede vSphere. Estas informações podem ser obtidas acessando o appliance do vCenter na porta 5480, aba Networking. O IP temporário pode ser qualquer um da rede vSphere que estiver livre. Teste antes (ping), para garantir que não usará o IP do NSX, HCX, ou outro que já estiver em uso.
4. O sistema onde for feito deploy do novo VCSA (geralmente uma máquina Windows) requer conectividade com os hosts no SDDC e com o VCSA antigo. Lembre-se: no assistente de deployment do novo VCSA, serão feitas conexões ao VCSA antigo e ao host ESXi onde será realizado o deployment do novo appliance. Portanto, ele deve conseguir chegar em ambos.
5. O sistema onde for feito deploy do VCSA e o novo VCSA devem ter resolução de DNS para o VCSA existente, bem como para os hosts ESXi no SDDC.
6. Caso hajam FSS e/ou datastores de terceiros conectados aos hosts do SDDC, eles também devem ser conectados aos novos hosts.
7. Manter backups de todos os componentes VMware e workloads.
8. Para atualização do NSX, caso esteja na versão 3.1.x, é necessário atualizar para 3.2.x antes de seguir para a versão 4.x.
9. Caso não consiga migrar as VMs do NSX (Edges/Managers) dos hosts antigos para os novos: Nos hosts novos, haverão Standard Switches nomeados vSwitch0, sem nenhuma NIC associada. Nestes Standard Switches, haverão Standard Port Groups chamados VM Network. Edite estes port groups. Em Security, marque a caixa de seleção “Override”, deixando MAC Address Changes e Forged Transmits em Accept. Conforme mostrado no vídeo do processo de upgrade disponibilizado no começo deste post (https://videohub.oracle.com/media/Oracle%20Cloud%20VMware%20Solution%20%7C%20Upgrade%20V7%20to%20V8%20(Captioned)/1_23q0uhbr), aos 56:03.
10. Após adicionar os hosts novos no cluster, é recomendável setar o DRS para Manual (não desative o DRS, para não perder suas resource pools), tirar os hosts de Modo de Manutenção, migrar uma ou duas VMs de workload manualmente para eles; validar conectividade e funcionalidade delas; e depois seguir fazendo vMotion do restante das VMs – manualmente ou por DRS, em modo Fully Automated.
11. Para SDDCs com vSAN: Se você não adicionar corretamente os novos hosts ao vSAN e não remover corretamente os hosts antigos, haverão perdas de dados irrecuperáveis. Ao adicionar os novos hosts ao cluster, tenha atenção nos passos de Claim Disks e para adicioná-los nos Fault Domains. Para remover os hosts antigos, coloque-os em Modo de Manutenção selecionando a opção “Full Data Migration“. Aguarde a tarefa completar. Mova o host para fora do Cluster. Aguarde a desinstalação do NSX concluir. Remova o host do vCenter, selecionando primeiro “Disconnect” e em seguida “Remove from Inventory”. Só então, finalize o host no portal OCI. Caso receba alguma mensagem de erro, ou o processo trave em algum desses passos, JAMAIS force a remoção do host do vCenter.
Troubleshooting
Falha no pre-check do NSX
Garanta que os usuários root, admin e audit não estejam com as senhas expiradas, em todos os appliances, que são 3 NSX Managers e 2 NSX Edges, por padrão.
Procedimento (selecionar a versão de NSX correspondente): https://techdocs.broadcom.com/us/en/vmware-cis/nsx/nsxt-dc/3-2/administration-guide/authentication-and-authorization/managing-local-user-accounts.html
NSX fica com um alerta de “Application Crashed” pós-update
Este é um problema conhecido, onde arquivos de core dump antigos são lidos novamente como se fossem novos.
Procedimento: https://knowledge.broadcom.com/external/article/345792/application-on-nsx-node-has-crashed-alar.html (item 4 – remover os arquivos de core dump).
Erro de Repo_Sync (Update NSX 4.1 para 4.2)
Mensagem de erro: “Unable to connect to File /repository/4.2.1.2.0.24476729/Manager/vmware-mount/libgobject-2.0.so.0 on source 10.192.64.120. Please verify that file exists on source and install-upgrade service is up”
Solução: https://knowledge.broadcom.com/external/article/322436/after-replacing-managers-or-while-runnin.html
Option: Correcting User and Group permission recursively for the /repository directory after coping (scp) it from a know good source manager.
The user and group the whole of the /repository directory should be user: uuc and group: grepodir for the directory and all subdirectories and files.
The permission should be wrx wrx.
This is was not the case when the directory was copied with scp to the newly replaced manager/s.
To ensure the correct user, group, and permission the following command is executed at the cli of each replacement manager.
Copy /repository directory to new manager.
Open an SSH session to the known good host.
#scp -r /repository <remote User>@<IP of Remote Server>:/
Example command:
#scp -r /repository root@A.B.C.D:/
This command copies the /repository directory recursively to the root directory (/) of host A.B.C.D.
Now the user, group, and permission will need to be check and corrected.
This will recursively set the user and group:
#chown -R uuc:grepodir /repository
This will recursively set the required permissions:
#chmod -R 770 /repository
Depois de copiados os arquivos do NSX Manager Orchestrator (VIP) para os demais managers e acertadas as permissões, dar Retry na tela de erro.
Além disso, na interface do NSX, em System -> Appliances -> Selecionar More Details nos três NSX Managers e observar se algum deles está com erro de REPO_SYNC (Imagem abaixo). Se estiver, clicar em RESOLVE – depois que tiver copiado os arquivos e acertado as permissões.
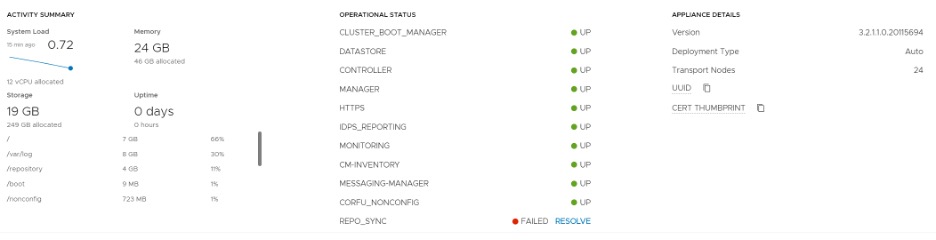
Erros de Certificado
Podem ser apresentados erros de certificados no Pre-check do NSX, impedindo de prosseguir com o upgrade.
Resolução: https://blogs.oracle.com/lad-cloud-experts-pt/renovandocorrigindo-certificados-do-nsxt-com-a-ferramenta-carr
Falha ao atualizar o vCenter, de/para 7.0u2
Há casos reportados de falhas de atualização a partir desta versão, no caso peguei um ambiente que teve uma destas no passado e estava em estado inconsistente (a atualização constava como bem-sucedida, mas a versão reportada do vCenter ainda era a anterior).
Passos a seguir:
1. Aplicar os KBs https://knowledge.broadcom.com/external/article?legacyId=85068 e https://knowledge.broadcom.com/external/article?legacyId=87238;
2. Remover o arquivo de status de atualizações (rm /etc/applmgmt/appliance/software_update_state.conf);
3. Rodar a atualização novamente, com sucesso.
Falha ao iniciar o serviço Netdumper
Caso usem o vCenter para enviar core dumps dos hosts ESXi, antes da atualização, editar o arquivo de configuração do serviço Netdumper do VCSA (vi /etc/sysconfig/netdumper), e adicionar a seguinte linha no começo do arquivo:
NETDUMPER_DIR_THRESHOLD_GB = 8Este passo também pode ser seguido caso o serviço Netdumper apresente problemas para iniciar, durante a atualização.
Para verificar se há alguma configuração de Forwarding, acessar a interface de gerência do vCenter na porta 5480, em Syslog:
Se tiver algo configurado nesta tela, mudar o parâmetro do Netdumper.
Falha ao iniciar os serviços do HCX pós-upgrade
Em alguns casos, após atualizar o HCX Manager/Connector, ele pode ficar indisponível, devido a um bug conhecido onde as permissões de diretórios internos são alteradas, impedindo que os serviços subam.
Sintomas:
- A VM do HCX Manager/Connector atualiza e reinicia, porém os serviços não sobem mesmo após aguardar 30 minutos ou mais;
- GUI do HCX inacessível;
- No sumário da VM (Manager/Connector) no vCenter, pode não exibir o endereço IP, ou exibir o status do VMware Tools como “Not running”;
- Consultando os logs do appliance, mostram a atualização como concluída, porém os serviços não sobem. Somado a isso, as permissões em diretórios específicos estão incorretas. Referência: https://knowledge.broadcom.com/external/article/380971/hcx-manager-postgresdb-service-fails-to.html
Resolução:
Criar um snapshot da VM.
Acessar o HCX Manager/Connector via SSH com usuário admin. Rodar os comandos abaixo:
su - (entrar a senha de root)
chown -R postgres:postgres /common/postgres-db
chown -R postgres:postgres /common/logs/postgres
chown -R kafka:kafka /common/kafka-db
rebootAguardar o reboot da VM e validar a funcionalidade. Após, remover o snapshot criado.
