In this blog post, we’ll show how Intelligent Advisor web-authored decision services can be combined with a large language model to provide reliable advice. The specific practical example shows using the OpenAI SDK, but other language models can also be used.
Background
Since it burst onto the scene in 2022, ChatGPT has redefined our expectations for interacting with computer systems in human language. From travel itineraries to movie plots to answering all sorts of questions about the world, the large language model (LLM) that powers ChatGPT and other similar chatbots appears to have powerful reasoning capabilities.
I say “appears to” because in fact there is no reasoning going on. In fact, large amounts of input data were used to train a next-most-likely word prediction model that is not doing any logical reasoning. It is this lack of actual reasoning that results in these models’ tendency to hallucinate, that is to make things up that are simply not true.
Tools for LLMs
To address this, OpenAI started exploring ways to augment the model with plug-ins that could perform tasks reliably. Frameworks such as langchain also appeared that allow LLMs to use so called tools when they can help an LLM complete a requested task. Plug-ins/tools can theoretically do anything that a computer can do – from adding lists of numbers accurately, to ordering food, or searching the web. They can even run code that has itself been generated by the model.
For example, let’s suppose you ask an LLM the distance across the surface of the Earth between Paris and Timbuktu: the so-called “great circle distance”. A large language model might have been trained with an article written by a human that happened to contain the answer to this exact question – and so it might give you the right answer without any help from tools. But for any two random points on the Earth’s surface, it is unlikely it will be accurate. If, however, the LLM has access to two tools: one to find out the exact position of a city, and a second to run arbitrary code – it can do the following:
- Use the first tool to get the position of the two cities (latitude and longitude)
- Generate code to take two lat/longs, and calculate the great circle distance between them
- Substitute the position of the two cities into that code, and use the second tool to run it
- Return the result given by the code as the answer to the question asked by the user
When accuracy matters
Now, imagine you are responsible for a team of customer service agents answering tax questions from citizens that want to know how to file their tax return correctly. Can a large language model help those agents provide reliable and accurate answers?
With help from tools, yes, it can.
In the rest of this article, we’ll show how to use the OpenAI SDK with an Oracle Intelligent Advisor-powered tool to provide accurate answers to customer service agents on certain tax topics. A similar approach would work with Microsoft’s Azure API, Google’s recently announced Gemini API and with Oracle’s LLM which is currently in Beta.
The basic outline is as follows:
- Define an Oracle Intelligent Advisor web-authored decision service to help answer the first topic in the Interactive Tax Assistant on the IRS website: Do I Need to File a Tax Return.
- Create an OpenAPI specification for that decision service.
- Use the OpenAI chat completions API with the decision service as a tool definition, and some background starting context to create a sample interactive application.
The files for this example are all in the Oracle Intelligent Advisor samples GitHub repository at https://github.com/oracle-samples/ia-tools-samples, in the llm/llm_ds_chat folder.
Define the decision service
Here are some Intelligent Advisor decision service rules for whether a tax return needs to be filed.
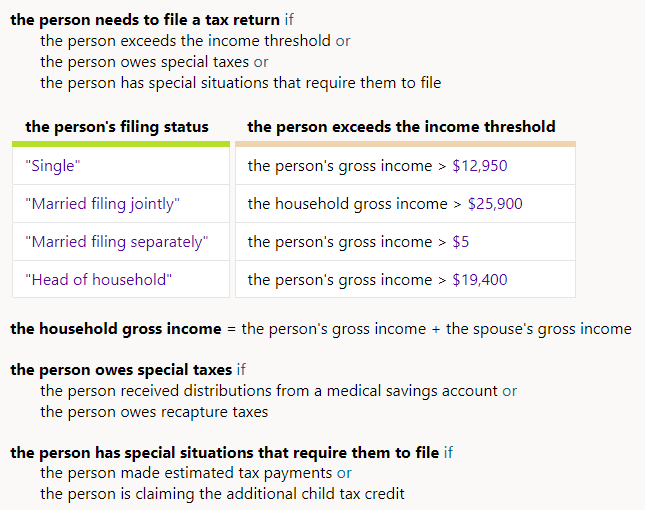
Note that this is only partial logic for whether a tax return needs to be filed. We are keeping this example very simple. More logic can be added to the decision service as needed.
The content for the sample decision service can be imported into your Intelligent Advisor Hub from the doINeedToFile.json file in the decisionservices folder. Go to the Projects page. Choose Actions > Import. Choose the file and choose Import on the preview screen that is shown.
As with any decision service, the Input/Output contract defines what inputs the decision service expects, and what outputs it returns.
This decision service has only a single boolean output, for whether a tax return needs to be filed:
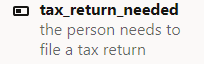
It accepts several inputs, not all of which are always needed to reach a decision (more on that later). For example, here are three of the inputs:

For the inputs and outputs, the bold text is the name for that input or output in the decision service REST API, whereas the gray text is the name of the data field in the rules. For example, the person’s filing status is used as a condition column in the one rule table in the decision service rules.
In this example, the only required input is the person’s filing status. We’ll see why this matters a little later.
If needed, it is easy to add more inputs, and then use those inputs in the rules that need those values.
For now, simply deploy your imported decision service with the same name as the project, into a Hub workspace where you have an apiuser with permission to call it.
Create an OpenAPI specification for the decision service
The next step is to create an OpenAPI specification that describes to the LLM what the decision service can be used for, what inputs it expects and what outputs it can return.
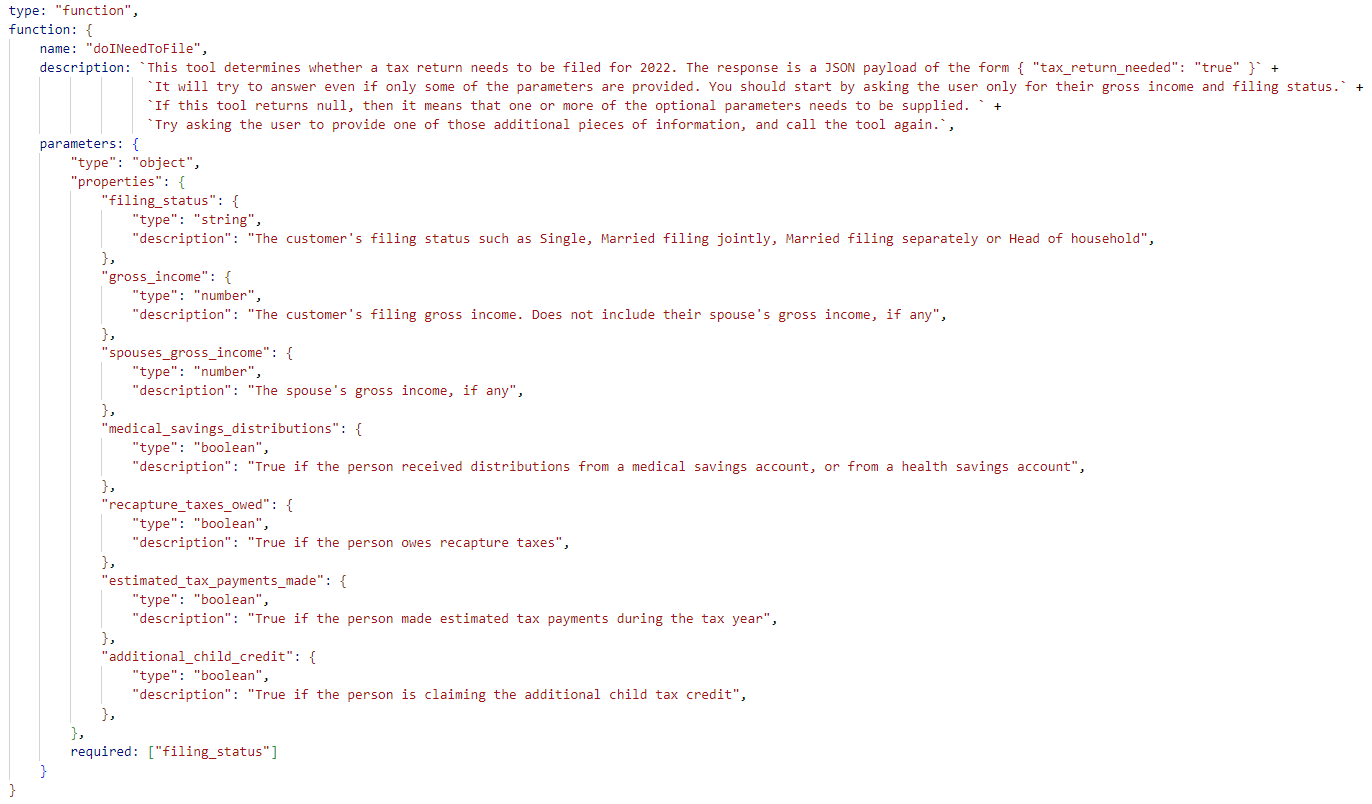
This natural language description of the decision service lets the LLM decide when it should call it. In other words, it is how the tool is defined for the LLM to use.
Some key things to note about this specification:
- The function description includes the shape of the JSON response returned by the decision service. This must match the structure of the data returned by the decision service REST API. This example just returns a single Boolean value, but the structure can include multiple fields and even arrays of objects.
- Each of the properties has a name and type that matches the input contract.
- The property descriptions can include a list of permitted options – such as for filing_status. The LLM will use this description to help it describe for the user what information they need to provide.
You can find the definition of the decision service in the tools.js file in the sample folder.
Putting it together
The rest of the sample wires these pieces up into a simple chatbot user experience.
decision.js calls the Intelligent Advisor decision service.
- It uses an apiuser name and apiuserPassword to get a bearer token for calling the decision service with the name defined in the tool definition
- You will need to modify this file to use an API user that has Assess Service permission for the workspace where you have deployed the doINeedToFile decision service.
- A decision service will return an error that the LLM does not handle well, if all the required fields are not provided, so be prudent about which fields you mark as required. With the limited initial prompt and tool description tuning done for this article, it is possible for the tool to be invoked with not all required parameters supplied.
llm.js provides a simple framework that calls the OpenAI completions endpoint to provide the chat experience.
- You will need to modify this file to use your own OpenAI apiKey
- You may also need to modify the model name, if it has changed since this sample was created
- As is usual with LLM powered chatbots, the history of the conversation builds over time, and that full history is passed to the LLM completion endpoint every time it is called
- The first time, the messages only contain a single system message that includes background for the LLM on how to call the tools for maximum effect

- We are encouraging the LLM to not ask for all the parameters defined on a decision service (since each one can have a lot of optional inputs) but instead to only ask for the parameters marked as required.
- The decision service can’t tell the LLM what additional information it needs to make a final decision. That’s a topic for a future blog post. So, for now some iteration with the agent is needed to discover what that information is. Usefully, as more information is supplied (often whatever is easiest to get from the customer), a final recommendation can be reached often without all the LLM-requested information being supplied.
- On every call, the definition of tools (defined in tools.js) is used as context for the LLM
index.html wraps up these components to provide a tool-powered chatbot experience.
- A single text input at the bottom of the screen is where our imaginary customer service agent can type their queries
- In response to text from the user, the LLM can indicate that one or more tools need to be called, which is actioned by the handleUserMessage while loop
- Yellow bubbles indicate the requests and responses from each tool, whereas gray indicates responses from the LLM, and blue are text entered by the user
Trying it out
A simple way to try out the sample on your local machine is:
- Install node.js
- In Intelligent Advisor Hub, navigate to the Permissions page
- Choose Actions > Access Settings
- In ASSESSMENT APIS ACCESS CONTROL section add http://localhost:8080
- From a command prompt, in the folder containing the llm/llm_ds_chat sample files:
- npx http-server
- In your favorite browser, navigate to http://localhost:8080
You will see what might at first look like a blank page, but there is a text box at the bottom of the page.
Type something in it like:
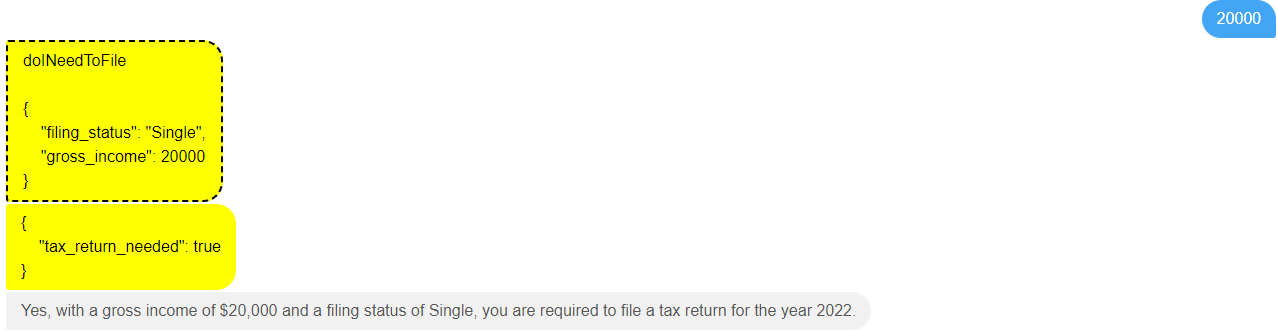
I have a customer filing as Head of Household with gross income of 60000, do they need to file a tax return?
and watch what happens next. The LLM works out that it has a tool that can help it with this, will work out the values of the two parameters to pass to it, and then return an answer back to the user:
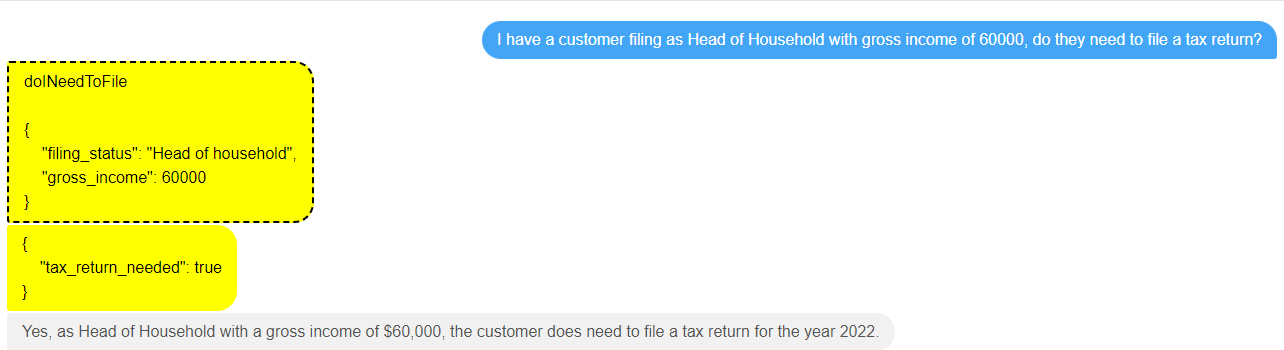
So, a very simple case was answered quickly using the decision service.
With the power of the LLM helping interpret the user’s input we have a lot of flexibility here. See what happens if the user changes some information:
In this case, the tool returns null, and the LLM works out that it needs to supply some of the other optional parameters defined by the tool before it should call it again.
So, it asks for some (but not all!) of the other inputs that the decision service can accept.
Perhaps at this point the agent learns from the customer that none these situations apply:

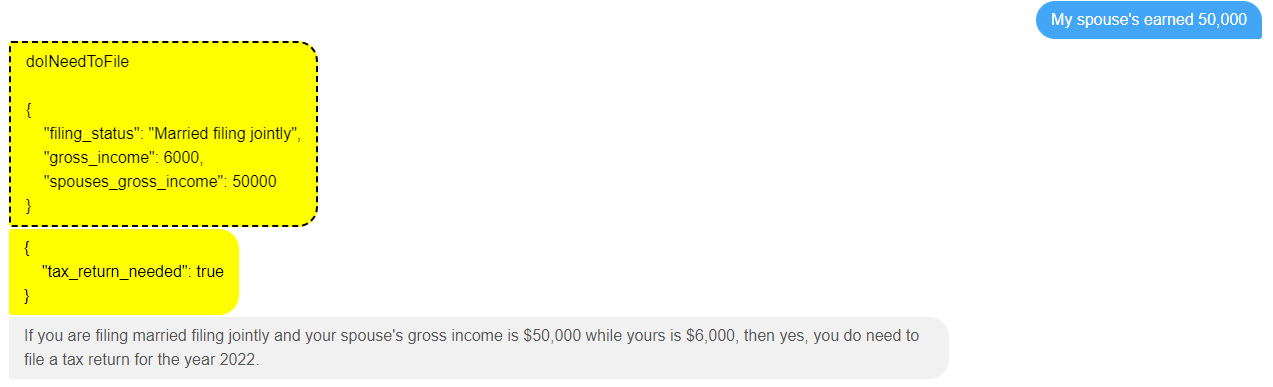
At which point the decision service tool is invoked again, and it turns out this was enough to get a final determination about whether a tax return needs to be filed.
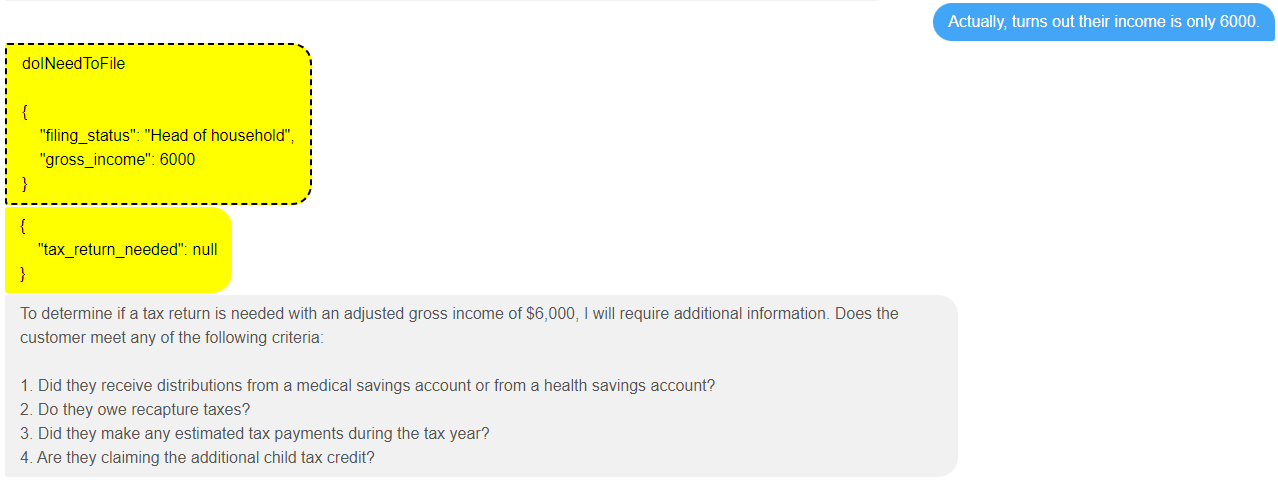
Let’s suppose we change this one more time, and now say the person is married filing jointly.
What’s interesting here is that it doesn’t use all the previous information we gave it, but it does use the gross income, and now it has realized it probably needs the spouse’s income. This is one of the great things about using an LLM that has been trained on material that describes how the world works in practice. When you are filing as head of household, you aren’t going to need your spouse’s income, so it works out not to ask for that (optional) input – at least in this particular run through.
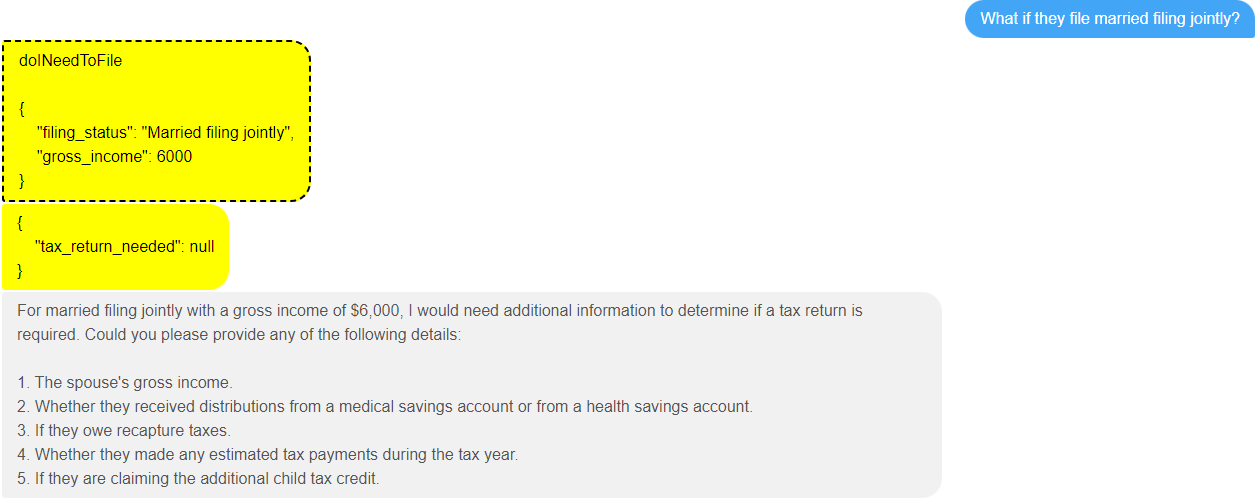
Now if only the spouse’s income is provided (complete with grammatical mistake!):
The LLM again invokes the tool, and gives the correct answer.
One more thing
If you looked closely at tools.js, you may have noticed it defines a second tool called taxpayerInformation . This tool is also implemented as a decision service, but this is just a convenient way to simulate some other REST API you may have in your organization that is able to get information about customers. The goal here is that the LLM can retrieve that information for the agent, so that they don’t have to ask all the details you already know about them.
For example, with the help of this tool, the agent might ask a question like “Does customer 4444 have to file a tax return this year?”
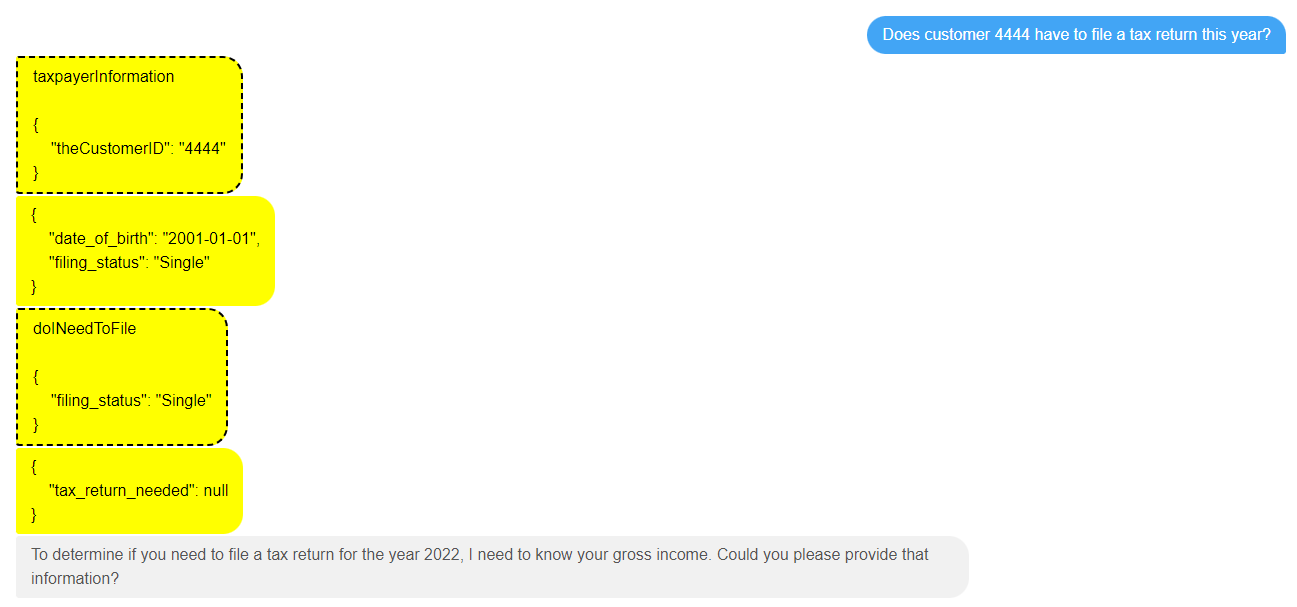
As you can see, the first thing the LLM does is call the taxpayerInformation tool, to get the filing status (which it knows is required by the doINeedToFile decision service) for customer 4444.
It then calls the doINeedToFile decision service, realises it doesn’t have all the information it needs to get an actual true/false answer, and asks the first question about gross income.
A nice thing about this interaction pattern is that the LLM responds back with the filing status it has assumed carries over the last year, so that this can easily be verified with the customer, in case it has changed.
You can import taxpayerInformation.json to create this decision service project. Don’t forget to deploy it, too!
Wrapping up
As mentioned, the approach shown here is not specific to OpenAI. Since many people already have an OpenAI API key for, we picked it for this demonstration. Oracle’s Cohere-powered OCI LLM model is currently in Beta, and is already powering AI features in Oracle’s Fusion applications suite.
So, what have we seen here?
- It is easy to use Intelligent Advisor decision services to create a consistent accurate advice tool that can be used by an LLM when it is needed.
- Using an LLM API, you can provide clarity about exactly when the tool is being called by the LLM, and when it is choosing to make decisions on its own. This is shown using the yellow bubbles in this sample UI but can be done however you wish.
- Multiple tools can be used in combination by an LLM – providing a flexible way of combining existing data APIs together with advice services
The example scenario focused on in-house agents using the LLM to work with systems (decision services and data retrieval APIs) that are deployed internally within the organization. I am seeing many organizations be cautious about deploying LLMs directly customer facing until they have more experience with them, so call center agents are often the first consumers of these tools. With some additional thought and safeguards, this approach can also work directly with customers.
This is an area that we continue to explore and innovate in:
- When applying AI to enterprise decision making, explainability is key. This is something Intelligent Advisor is very good at, and a future blog post will show how the explanations behind the decision service’s reasoning can also be shared with and by the LLM.
- The natural language descriptions of the decision services could be maintained and even generated within Intelligent Advisor Hub, to simplify the process of creating the tool descriptions. Look for future announcements on this topic.
- In some cases, you may want to specifically chain tools together outside the LLM. Oracle Digital Assistant, Oracle Process Cloud and other tools can help create composite tools that can be combined with LLMs. For example, ODA can broker the user’s chat experience with the LLM. Or as shown in this blog post, a custom chat client can be brokered directly via an LLM with composite tools.
What do you think? Is this approach something you are exploring? Do you want to see other examples of combining trustworthy decision making and advice with large language models?
