The Challenge: Uncontrollable LLMs
If you’ve been following the recent growth of Large Language Models (LLMs)—the wildly popular AI models capable of processing and generating natural language text—you might know that deploying them for real-world applications can be a challenging endeavor. Imagine a chatbot powered by such an LLM: helpful until it starts providing incorrect information, reciting nonsense, and requiring consistent human intervention.
How can solution specialists looking to apply LLMs in production facilitate safe and high-quality LLM output? How do you prevent unintentional regressions in behavior when you update or upgrade your model?
Introducing LLM Toolchain
One answer to these questions lies in a new architecture called LLM Toolchain. LLM Toolchain is a way to assess LLMs before deployment, minimizing unexpected hiccups and improving generative quality. It works across various stages of LLM development—including pretraining, fine-tuning, adaptation, prompt tuning, and prompt engineering—for both classification and generation tasks, while also tackling a critical challenge for LLM developers: covariate shift and concept drift, or the idea that both the data distribution and expected output can change over time.
Quality Assurance and Safety
We’ve seen content filtering in action, but it’s only a reactive measure that doesn’t create foolproof safeguards, especially against behavioral regressions when upgrading the model and concept/data drift (Business Insider, ZDNET, The Verge, The Guardian, Yahoo Finance).
LLM Toolchain goes further by providing pre-deployment evaluations, proactively identifying and preventing regressions. If a new model performs worse on certain inputs, you’ll be informed. Toolchain lowers the risk of LLM deployments by providing a minimum quality assurance on business-critical and adversarial prompts. Beyond that, Toolchain provides detailed reports on various metrics (non-functional evaluation, accuracy, safety, quality, etc.), allowing you to choose the best model for your specific requirements.
Evaluating LLM Performance
LLM Toolchain assesses a model’s performance by evaluating its output against a user-provided test suite. Akin to a standard machine learning evaluation dataset, this suite comprises input-output pairs for both classification and regression tasks. Generative tasks, however, focus on inputs, with optional output constraints instead of explicit values.
Models often hallucinate1 when fine-tuning for a specific style/form, especially with supervised methods. The goal of fine-tuning should not be to replicate training data, but rather to simply produce high-quality output. We strive for the model to have flexibility in its generation (a general idea in reinforcement learning), without simply training it to memorize specific text completions.
Toolchain’s evaluation is rooted in this philosophy. Unlike traditional techniques, it doesn’t assume a single correct output. Rather, it’s based on a distribution of outputs; any output that satisfies the constraints is deemed valid.
Using its own evaluation language model, Toolchain evaluates quality, safety, sentiment, and several other factors against given natural language or mathematical constraints.
The LLM application developer can create custom test suites or use predefined ones for chatbots, code generation, text editing, and more. Toolchain augments Test Suites to enhance model robustness and minimize unexpected effects on inputs similar to known inputs (the business-critical inputs).
Improving LLM Performance with AutoML
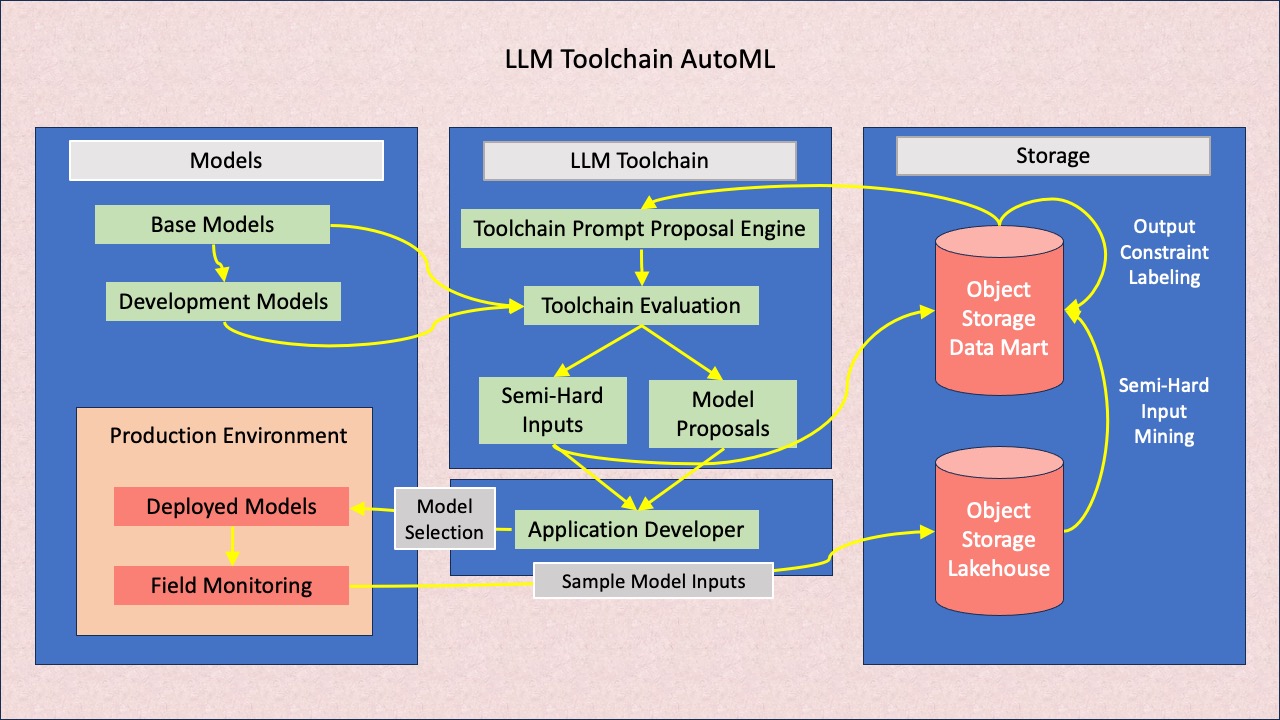
LLM Toolchain goes beyond evaluation; it’s also about improvement!
LLM Toolchain AutoML leverages the power of LLM Toolchain to automatically propose model enhancements (automated machine learning), such as changing the base LLM, or using a generated engineered prompt template. Model weights can be tuned using Reinforcement Learning from Artificial Intelligence Feedback (RLAIF) techniques, with the Toolchain evaluation itself as a reward function. And remarkably, LLM Toolchain’s internal LLM can improve itself using Toolchain AutoML, continually improving over time by bootstrapping its own learning process.
Conclusion
LLM Toolchain empowers businesses to confidently integrate language models into their production applications while maintaining control and minimizing unintended risks.
The architecture enables LLM application developers to evaluate their models prior to deployment, limit behavior regressions, assure a baseline of output quality, and automatically improve their models. With the ability to describe expected behavior in natural language, organizations can align models with their specific requirements and ethical guidelines, without the need for highly skilled machine learning engineers or human reviewers in the loop.
The LLM Toolchain architecture is a step towards a more robust, responsible, and effective use of language models and continual breakthroughs in the rapidly evolving field of Generative Artificial Intelligence.
Want to learn more about LLM Toolchain and LLMs? Read the longform version of this blog or contact Avi Mehra.
