Key Takeaways
- Semantic caching is policy-controlled answer reuse, not just vector search. A nearest-neighbor match is only a candidate until tenant, security, model, prompt-template, data-domain, threshold, freshness, and reuse policy approve it.
- Keep semantic-cache answers separate from retrieval-augmented generation (RAG) documents. RAG retrieves source material for a new answer; semantic caching retrieves a prior generated answer only when reuse is safe.
- Oracle AI Database 26ai is a strong fit when the cache lookup needs both vector ranking and SQL predicates. Native
VECTOR,VECTOR_DISTANCE(), vector indexes, relational columns, transactions, metadata, provenance, and invalidation state can live in one SQL-backed record. - Oracle True Cache belongs on the eligible read-only lookup path. In this series, we use it for lookup-heavy semantic-cache SQL traffic where routing and freshness rules fit; it does not compute embeddings, judge semantic equivalence, or approve cached answers.
Your Spring AI application has probably seen traffic like this:
Prompt A: "How do I reset my password?"
Prompt B: "I forgot my login password. How do I reset it?"
Prompt C: "Can you help me recover account access?"
If you cache only by exact prompt text, those are three different strings. Unless your application normalizes them into the same scoped key, you get three misses, three large language model (LLM) calls, and three chances to spend latency and tokens on essentially the same answer.
That is the problem semantic caching is meant to solve.
Semantic response caching reuses a previously generated answer when a new prompt is semantically similar and the application policy says reuse is safe. Instead of asking, “Have I seen this exact string before?”, the application asks a more useful question: “Have I already answered a sufficiently similar question, and is that answer still safe to reuse for this request?”
The second half of that question is what keeps the architecture honest. A semantic cache is not a “vector search equals cache hit” button. Vector search proposes candidates. The application and database policy decide whether reuse is allowed.
That is where Oracle AI Database 26ai becomes interesting for Spring AI developers. Semantic-cache entries are not just disposable cache keys. In many applications, they are governed records: scoped by tenant, security, chat model, embedding model, prompt template, data domain, freshness rules, provenance, invalidation state, feedback, and operational metrics. With Oracle AI Database 26ai, the prompt embedding and policy metadata can live in the same transactional database record and be queried together.
Oracle True Cache fits one layer below that decision. When semantic-cache lookups become read-heavy, True Cache can support eligible read-only lookup traffic without changing what a semantic-cache hit means.
This is the first article in the series, so we will stay at the architecture level. We will define the moving parts, draw the boundaries, and set the decision rules that the implementation and benchmark preserve.
Different cache layers solve different LLM application problems
Caching discussions around LLM applications get confusing because several mechanisms reduce repeated work, but they operate at different layers. The simplest way to keep them straight is to ask what each layer stores and who decides whether reuse is safe.
An exact response cache stores an answer under a deterministic key. That key usually includes normalized prompt text plus scope such as tenant, chat model, prompt template, application, and data domain. Exact caching is simple and often the safest place to start. If the same scoped request arrives again, return the same answer. If the wording changes, the exact key usually changes too.
A semantic response cache stores a prior prompt embedding plus the generated answer and policy metadata. When a new request arrives, the application embeds the new prompt and searches for nearby prior prompts. A close match can avoid another LLM call, but only after policy approves reuse.
A retrieval-augmented generation (RAG) store is different. RAG retrieves source material: documentation chunks, policy text, product manuals, support articles, tickets, or other records used to construct a new answer. RAG retrieval does not mean “return this old model answer.” It means “bring relevant source content into the generation step.”
A database result cache or HTTP cache usually caches deterministic outputs for exact queries or resources. It does not understand paraphrases. It is useful, but it is not semantic matching.
An LLM provider prompt cache is also adjacent, not equivalent. Provider prompt caching, where available, can reduce provider-side processing for repeated prompt prefixes or context blocks. The application still sends the request, and the provider still generates the response. Semantic response caching is an application-controlled decision to skip generation and reuse a prior answer.
Oracle True Cache is another layer. True Cache is an in-memory, read-only cache in front of Oracle AI Database. In this architecture, it helps with eligible database reads during semantic-cache candidate lookup. It is not the semantic cache itself, and it does not decide whether two prompts mean the same thing.
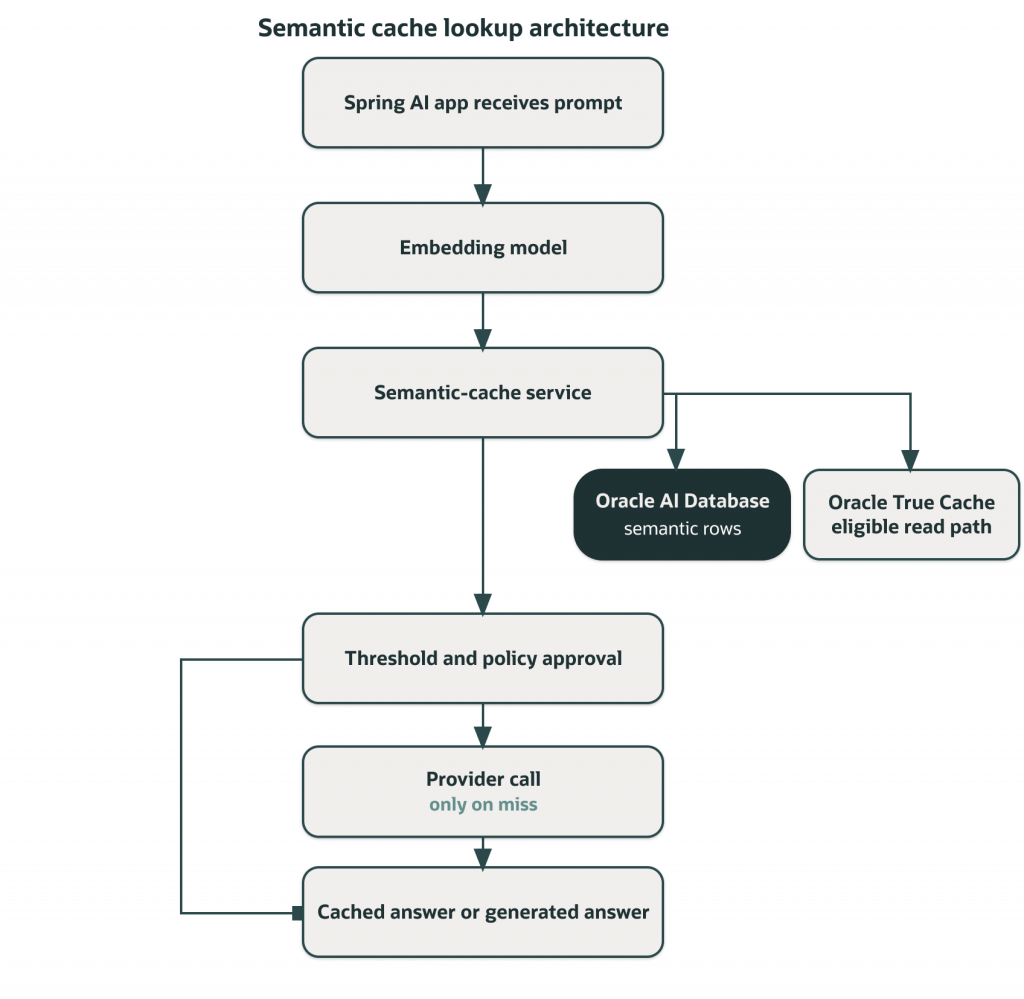
Oracle AI Database 26ai is the semantic-cache system of record. Vector similarity proposes candidates, SQL predicates narrow the eligible set, Oracle True Cache supports eligible read-only lookup traffic, and the app calls the LLM only when no candidate is approved for reuse.
The distinction looks small in a diagram. In production code, it is the difference between safe reuse and a false-positive machine.
A semantic-cache candidate is not a hit
Let’s replay the password example.
exact-cache lookup:
A -> MISS -> call LLM -> store answer
B -> MISS -> call LLM again
C -> MISS -> call LLM again
Now compare that with a semantic-cache path:
semantic-cache lookup:
A -> MISS -> call LLM -> store prompt embedding + answer + policy metadata
B -> CANDIDATE -> passes policy -> reuse answer
C -> CANDIDATE -> may pass or fail depending on threshold and policy
Notice the word candidate.
Prompt B is probably a safe paraphrase of Prompt A in a simple account-help FAQ application. Prompt C is broader. “Recover account access” could mean reset a password, unlock an account, recover a username, pass multi-factor authentication, or talk to support. Whether Prompt C can reuse the same answer depends on your domain and policy.
That is the mental model to keep: vector similarity proposes candidates; policy approves hits.
A semantic-cache candidate needs to pass checks like these before the application returns the cached answer:
- same tenant or authorized sharing scope
- same security scope
- same application and data domain
- compatible chat model or model family, depending on your reuse policy
- same embedding model and embedding dimension
- same prompt template and prompt-template version
- unexpired and not invalidated
- acceptable vector distance or similarity threshold
- acceptable provenance and source-policy version
Some of those checks can live in vector-store metadata filters. In an Oracle-backed design, you can also encode them directly as SQL predicates alongside vector ranking.
Spring AI handles the AI flow; the semantic-cache service owns reuse policy
Spring AI provides the application-level pieces for this architecture, including chat clients, embedding models, vector-store abstractions, SearchRequest, metadata filters, provider integrations, and advisor-style request interception. The Spring AI vector database reference describes the core VectorStore shape, including similarity search with top-k, threshold, and filter expressions. Spring AI also documents an OracleVectorStore integration for Oracle Database AI Vector Search.
For an Oracle implementation, the important design choice is to keep the semantic-cache store dedicated. Even if your application already has a RAG vector store, avoid quietly reusing it for cached answers. Give the cache its own Oracle table, schema, or hard metadata scope.
Depending on the Spring AI version you target, the implementation can take one of two paths:
- use a Spring AI cache component if the selected version exposes one that fits the required policy and storage model
- implement a small Oracle-native semantic-cache service beside Spring AI, using Spring AI for embeddings and chat while Oracle AI Database 26ai handles vector-plus-policy lookup
That second option is not a workaround. It can be the cleaner production shape when the cache decision needs strict relational predicates, transactional hit logging, invalidation, provenance, and reporting. Spring AI remains the Java AI framework. Oracle AI Database 26ai serves as the governed semantic-cache backend.
One practical caveat: do not assume that every Spring AI cache API is backend-agnostic or that every vector-store abstraction is enough for strict tenant, security, model, template, freshness, and invalidation policy. For the Oracle path, pin the Spring AI version and the Oracle AI Database target, then decide whether OracleVectorStore metadata filters are sufficient or whether direct Oracle SQL is the clearer implementation.
For this architecture article, the important boundary is simple: Spring AI handles the application AI flow, and the semantic-cache service owns the answer-reuse decision.
The semantic-cache lookup architecture
The main lookup path has a simple rhythm.
The application receives a prompt and builds a scoped exact-cache key first. If there is no exact hit, it creates an embedding for the prompt. Then it queries a dedicated Oracle semantic-cache table for the nearest policy-eligible candidates. If a candidate passes threshold and reuse policy, the application returns the cached answer. If not, it calls the LLM, stores the new answer and metadata in Oracle AI Database 26ai, and returns the new answer.
The key point is not only that the database stores vectors, although it does. Oracle AI Database 26ai includes a native VECTOR data type, SQL vector distance functions such as VECTOR_DISTANCE(), and vector indexes such as HNSW and IVF through CREATE VECTOR INDEX. Those features matter because they let the cache lookup live in SQL with the same metadata that determines whether reuse is safe.
A semantic-cache row is closer to an operational record than a document chunk. It might include fields such as tenant scope, security scope, application identity, model identity, prompt-template version, data domain, the original question, the question embedding, the generated answer, source-policy version, timestamps, invalidation state, provenance, hit metadata, and feedback signals.
You do not need every field on day one. A first implementation can start narrower: tenant, domain, model identity, template version, embedding model, expiration, invalidation state, the prompt embedding, and the answer. The point is to make the reuse boundary explicit: who may reuse the answer, which model and prompt template produced it, which domain it belongs to, and when it becomes unsafe to serve.
Use Oracle SQL to rank by vector distance and filter by reuse policy
The semantic-cache lookup is not just this:
ORDER BY VECTOR_DISTANCE(...)
A representative lookup query looks like this:
SELECT
cache_id,
answer_text,
VECTOR_DISTANCE(question_embedding, :query_embedding, COSINE) AS distance
FROM semantic_cache
WHERE tenant_id = :tenant_id
AND security_scope = :security_scope
AND application_id = :application_id
AND chat_model_id = :chat_model_id
AND embedding_model_id = :embedding_model_id
AND embedding_dimension = :embedding_dimension
AND prompt_template_id = :prompt_template_id
AND prompt_template_version = :prompt_template_version
AND data_domain = :data_domain
AND source_policy_version = :source_policy_version
AND invalidated_at IS NULL
AND (expires_at IS NULL OR expires_at > SYSTIMESTAMP)
ORDER BY distance
FETCH FIRST 5 ROWS ONLY;
The shape is the important part. The query combines vector ranking with policy predicates. The database does not return “the answer is safe.” It returns the nearest candidates that are eligible under the SQL predicates. The application still applies the threshold and any application-specific reuse rules before serving the cached answer.
That distinction also avoids a common threshold mistake. VECTOR_DISTANCE() returns a distance value; lower is closer for a distance metric such as cosine distance. Spring AI’s SearchRequest exposes a similarity-threshold concept at the abstraction layer, where values closer to 1 represent higher similarity. If your implementation reports both, make the direction explicit. A distance threshold and a similarity threshold are not the same number with a different label.
For small demos, exact vector search can be easier to reason about. For larger cache tables, Oracle vector indexes such as HNSW and IVF become tuning tools. Approximate indexes trade recall and performance characteristics, so they belong in the measurement discussion after the correctness rules are stable.
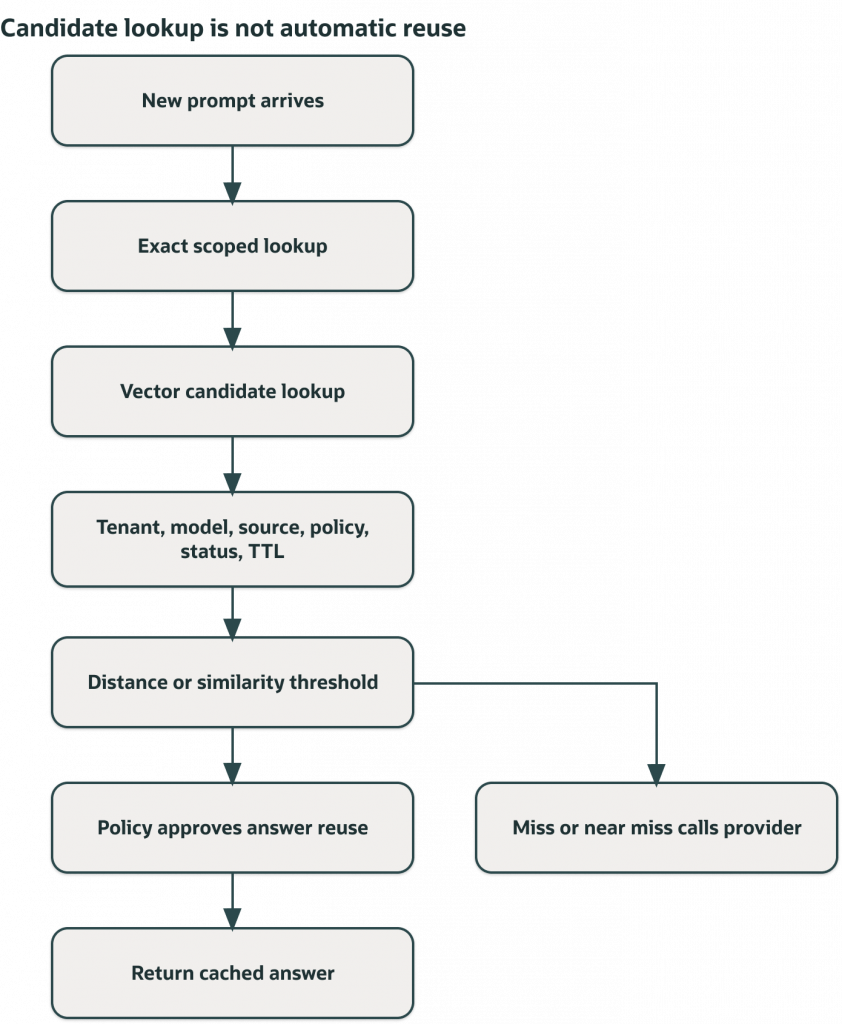
The nearest vector result is a candidate. Tenant, chat model, embedding model, prompt-template version, domain, freshness, invalidation, and threshold rules determine whether the application can reuse the answer.
Keep RAG documents and cached answers in separate vector spaces
RAG and semantic caching both use embeddings, but they store different things for different purposes. A RAG vector store retrieves source material for generation. A semantic-cache store retrieves a prior final answer for possible reuse.
That difference is important enough to show in the data model.
A RAG store contains source material:
RAG store:
- record_type: RAG_DOCUMENT
- content: "Password reset links expire after 15 minutes."
- purpose: source material for generating a new answer
A semantic-cache store contains prior generated answers:
Semantic-cache store:
- record_type: SEMANTIC_CACHE
- question: "How do I reset my password?"
- answer: "Go to Account Settings, choose Security, then Reset Password..."
- purpose: previously generated final answer that may be reused
A source document can help generate a new answer. A cached answer is prior model output. Do not let one silently stand in for the other.
The safest default is separate Oracle tables:
-- Source chunks for RAG retrieval
rag_documents
-- Prior generated answers for semantic-cache reuse
semantic_cache
If you intentionally use a shared table or shared vector-store infrastructure, every query needs a hard predicate such as record_type = 'SEMANTIC_CACHE' or record_type = 'RAG_DOCUMENT', plus tenant and domain scope. Separate storage spaces are easier to inspect, test, audit, and explain than a shared table that relies on every caller passing the right filter every time.
This separation also helps Spring applications as they grow. Today you may have only a semantic cache. Tomorrow you may add RAG, memory, tools, or safety advisors. Explicitly named stores and beans keep those paths from bleeding into each other.
Oracle True Cache offloads eligible lookup reads, not semantic decisions
True Cache is useful after the semantic-cache boundaries are clear.
In this architecture, Oracle AI Database 26ai primary remains the authoritative store for semantic-cache entries, RAG documents, policy metadata, invalidation state, hit logging, feedback, and new cache writes. Oracle True Cache is the read-path component we use for eligible, read-only semantic-cache candidate lookup traffic in the semantic-true-cache mode.
The read/write boundary matters. Semantic-cache writes, invalidation updates, feedback, and hit metadata belong on the primary write path. Candidate lookup can use the configured read path when the query is eligible and the freshness behavior matches the application’s correctness rules.
The intended separation is:
semantic-primary:
lookup path -> Oracle AI Database 26ai primary service
semantic-true-cache:
lookup path -> Oracle True Cache read service
write path -> Oracle AI Database 26ai primary service
The request flow then follows the read/write boundary shown below.
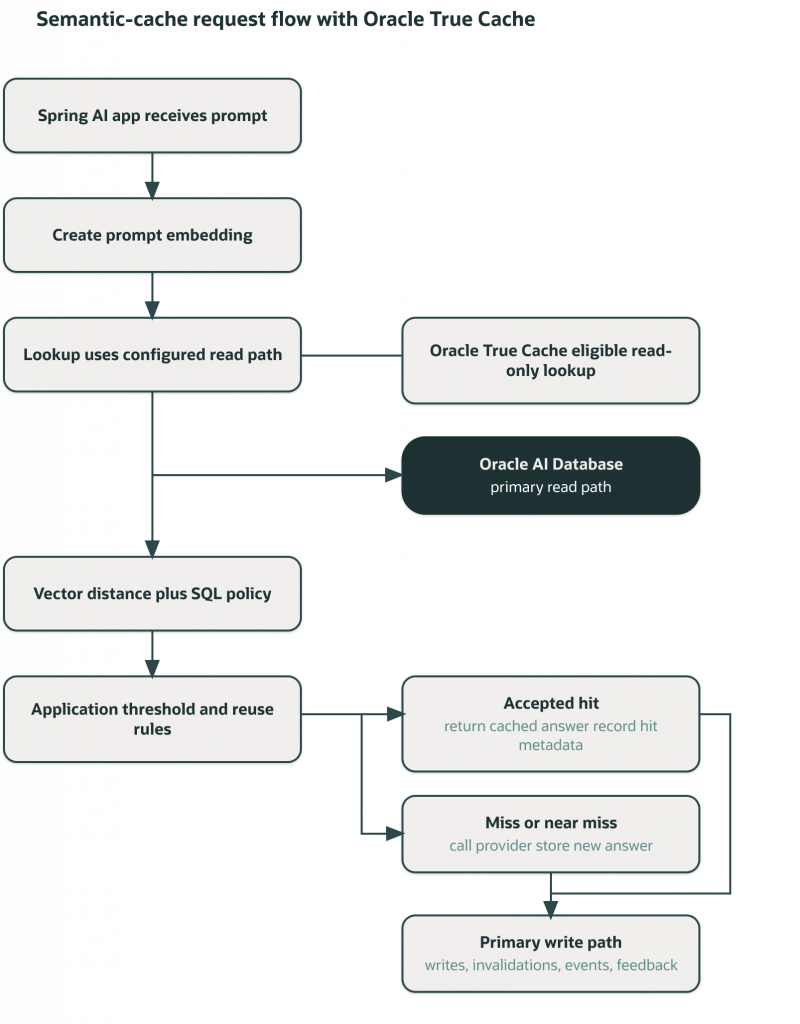
True Cache supports eligible read-only lookup SQL. Semantic approval remains an application responsibility, and all writes, invalidations, events, and feedback stay on the primary database path.
Oracle True Cache does not embed prompts. It does not calculate semantic meaning by itself. It does not decide whether a cached answer is safe. It supports the Oracle AI Database read path.
There is an important freshness caveat. True Cache is automatically maintained from the primary database, and reads return committed, consistent data. Like any cache, though, it may not show the latest primary write at every instant. That matters for semantic caching because invalidation and expiration are correctness rules, not only performance details. For checks that are sensitive to the latest primary write, use the primary service for that check, require a primary-confirmed policy version before reuse, or measure refresh behavior for the workload before routing that path through True Cache.
That read/write separation also makes measurement honest. If every cache hit synchronously updates hit_count, last_hit_at, and detailed metrics in the same request, the workload may stop being read-heavy. The implementation can still record hit metadata, but those writes belong on the primary database path. The benchmark separates read-only lookup latency from full request latency with write-back.
Why Oracle AI Database 26ai is an excellent semantic-cache backend
Oracle AI Database 26ai is a strong fit when cached LLM answers are governed application records, not just short-lived cache values. The database is especially useful when the reuse decision needs vector similarity and relational policy checks in the same lookup.
That combination is the center of this architecture. A cache row can store the question embedding, generated answer, tenant scope, security scope, model identity, prompt-template version, data domain, provenance, expiration, invalidation state, and feedback signals together. A single SQL query can rank candidates by vector distance while filtering by the policy fields that decide whether reuse is even eligible.
Oracle AI Database 26ai is attractive when:
- tenant isolation and security scope are mandatory
- answers depend on chat model, embedding model, prompt template, data domain, or policy version
- invalidation must be auditable
- provenance and source fingerprints matter
- hit/miss behavior needs SQL reporting
- feedback or quality signals are stored with the cache entry
- application data and policy state already live in Oracle AI Database
- DBAs and platform teams want backup, access controls, lifecycle management, and operational views in the same database estate
The design is strongest when the cache decision is semantic and relational at the same time. If repeated traffic is mostly exact repeats, start with an exact scoped cache. If answers are disposable, short-lived, and governed only by simple TTL rules, a lightweight cache service may be enough. If vector retrieval is a standalone platform shared across many independent applications, a dedicated vector database can also be a reasonable fit.
For this series, the interesting case is the governed one: cached answers that must carry tenant, security, model, prompt, domain, freshness, invalidation, and provenance policy with the vector used to find them.
What the series benchmark measures
Articles 1 through 3 use a single-machine Docker Compose environment as a functional test bed. That setup is ideal for validating the schema, policy rules, route selection, exact hits, semantic hits, near misses, invalidation behavior, and the basic Oracle True Cache read-path integration. Article 4 then takes the same application pattern into a more realistic deployment scenario, with the application and Oracle True Cache kept together and the primary database moved to a remote OCI deployment so the read-path comparison reflects a real network hop.
The series demo is designed to test the same architecture described here:
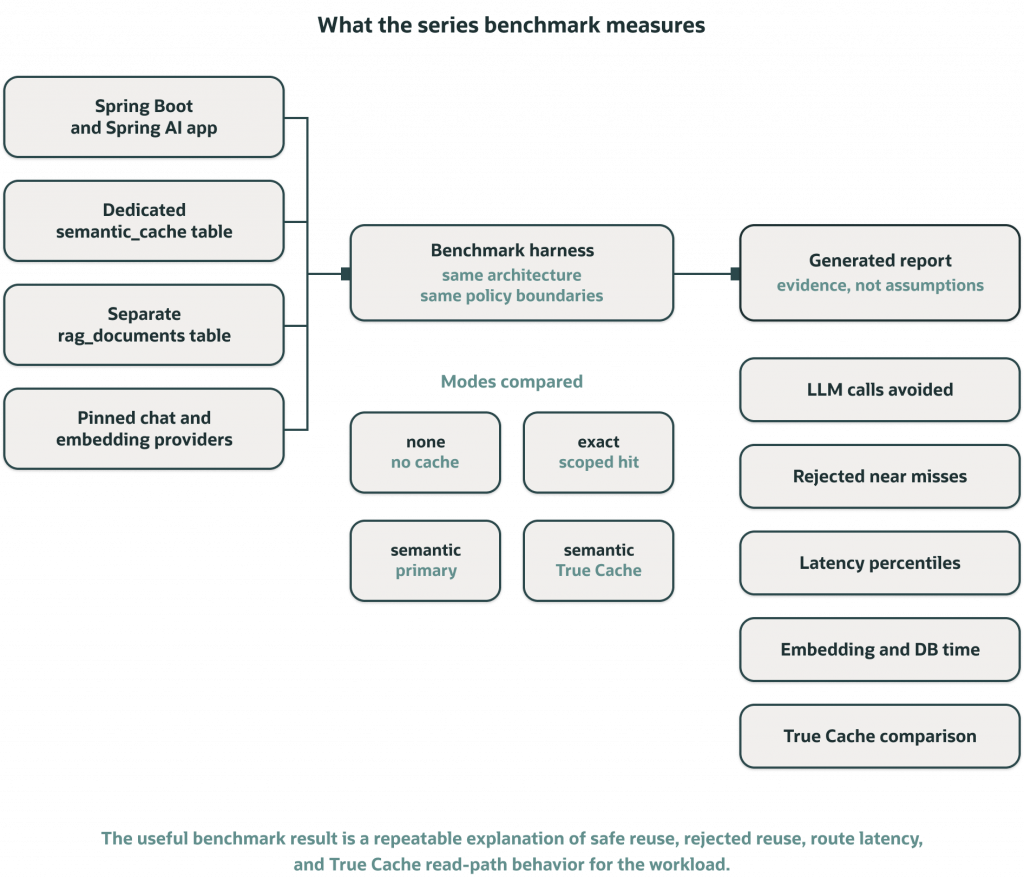
The benchmark keeps the same application, schema boundaries, provider pinning, and policy rules while comparing none, exact, semantic-primary, and semantic-true-cache modes.
Treat semantic-true-cache as the mode that exercises Oracle True Cache for eligible read-only semantic-cache lookup SQL. True Cache can offload eligible read-only database lookups from the primary database and may improve lookup latency or scalability for read-heavy workloads, but that is something to measure for the workload, not assume.
The report tracks total requests, LLM calls avoided, exact hits, semantic candidates, accepted semantic hits, rejected near misses, latency percentiles, database lookup time, embedding time, token usage where available, expiration and invalidation behavior, and the Oracle True Cache read-path comparison.
The goal is not to publish a universal “semantic caching saves X percent” claim. The useful result is a repeatable way to answer narrower questions:
- For this workload, how many repeated LLM calls did the cache safely avoid?
- Which near misses did the policy reject?
- How sensitive were results to threshold and freshness settings?
- How much time did embedding and database lookup add?
- Did the Oracle True Cache read path help, remain neutral, or add overhead for this lookup workload?
Those answers have to come from measurement, not assumptions or a single happy-path demo.
A practical decision rule for Spring AI semantic caching
Use semantic caching when your application repeatedly answers semantically equivalent questions and answer reuse is safe within the same tenant, security scope, chat model or approved model family, embedding model, prompt template, data domain, and freshness window.
Use exact caching first when exact reuse is available. Add semantic caching when paraphrased repetition is common enough to justify embedding and vector lookup. Keep RAG documents and cached answers separate. Treat vector results as candidates. Make freshness and invalidation part of the schema, not an afterthought. Route eligible read-only semantic-cache lookups through Oracle True Cache when the query path and freshness rules fit the workload, and measure the effect rather than assuming it.
Semantic caching is a poor fit when each answer depends on rapidly changing user-specific state, when the prompt is high-risk, or when a near miss could cause material harm. In those cases, a cache miss and a fresh generation are cheaper than a wrong answer.
That is the architecture to build on: Spring AI at the application layer, Oracle AI Database 26ai as the vector-plus-policy semantic-cache backend, and Oracle True Cache as the eligible read-path component for lookup-heavy semantic-cache SQL traffic.
In the next article, we will turn this architecture into an inspectable implementation: a Spring Boot command-line demo, a dedicated Oracle semantic-cache table, exact and semantic lookup paths, scoped rejection cases, fixture vectors, and validation output that shows what the database returned. After that, the measurement article will use the same demo reports to separate correctness checks from benchmark claims.
