Vector Embeddings: How They Work, Where to Store Them, and Best Practices
Key Takeaways
- Vector embeddings convert unstructured data into numeric representations that power semantic search, recommendations, and multimodal analytics beyond keywords.
- Embedding success isn’t just about the model—it also depends on a data platform that can meet requirements for scale, low latency, security, and governance, including vector indexing/ANN search, access controls, encryption, and monitoring.
- Oracle AI Database unifies native vector types and similarity search, enterprise-grade security, and integrated vector, structured, and unstructured data—so teams can build RAG, search, and analytics without piecing together multiple systems.
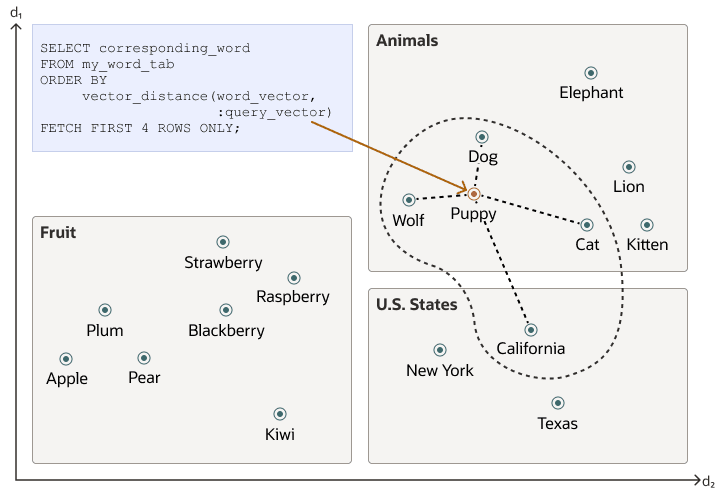
Introduction to Vector Embeddings
Vector embeddings have changed the way we interact with unstructured data such as text, images, audio, and code. By transforming this data into high-dimensional numeric vectors, we can use embeddings to process the semantic meaning and relationships within the data.
We can look at embeddings as task or domain-specific representations of vectors. The geometric relationships among them represent meaningful similarities between concepts in semantic space. The efficient storage and querying of vector embeddings enables capabilities such as semantic search, recommendations, and advanced analytics; and bridges the gap between unstructured and structured information.
What are Vector Embeddings? A Definition and Their Role
Vector embeddings are mathematical representations of objects—such as words, sentences, images, or audio—encoded as dense, high-dimensional vectors. Each vector encapsulates features that capture semantic meaning, context, or structure of the data. For example, similar words or images will have embeddings positioned closely in the vector space, enabling similarity-based operations. This allows for similar “things” to be grouped together under a distance metric.
The adoption of vector embeddings underpins many cutting-edge technologies:
- Retrieval-augmented generation (RAG): Enhances large language models by retrieving relevant context using embedding similarity.
- Semantic search: Finds documents with similar context, not just matching keywords.
- Recommendations: Suggests products or content by comparing user or item embeddings.
- Deduplication and anomaly detection: Identifies near-duplicates or outliers based on embedding distances.
- Multimodal analytics: Links information across text, image, audio, and other domains.
This ability to bridge structured and unstructured data makes embeddings indispensable across modern data architectures.
How to Create Embeddings? Some Tools That Can Help
A variety of tools can encode text, images, and code as vector embeddings, enabling similarity search, retrieval workflows (including RAG), and other ML tasks:
- OpenAI – provides hosted embedding APIs backed by task-optimized models, accessible with REST interfaces.
- Hugging Face – offers a large catalog of pre-trained multimodal embedding models and libraries (such as the Transformers library), plus community benchmarks.
- Oracle AI Database – provides a native vector memory store in Oracle Database, enabling storage, indexing (e.g., IVF/flat/HNSW), and retrieval of vector embeddings alongside relational data with SQL and PL/SQL integration; supports hybrid search (vector + metadata filters), enterprise-grade security, and governance for RAG and semantic search workloads
- TensorFlow – enables building and serving custom embedding models using Keras, enabling easy integration into training pipelines.
- PyTorch – provides flexible primitives to fine-tune or implement embedding models, and deploy them via TorchScript.
Benefits of Working With Vector Embeddings
The following are just a few of the benefits vector embeddings have brought to today’s AI tech stack:
- Vector embeddings are currently the best way to transform complex data into numerical units that reflect meaning, similarity and enable clustering and retrieval beyond keyword matching.
- The limitations of keyword methods were particularly visible in areas such as synonym handling, typos, and paraphrasing, and are now absent in modern-day LLMs relying on vector embeddings.
- Embeddings support multilingual and cross-modal experiences by aligning meaning across languages and modalities.
Other approaches, such as sparse lexical retrieval and symbolic/ontology-based methods, can be effective, but dense vector embeddings are often a better fit when you need semantic similarity matching (for example, paraphrases and synonyms) rather than exact keyword overlap.
Challenges in Working With Vector Embeddings
The following are some of the potential challenges you may face in working with vector embeddings, and potential ways to mitigate them:
Storage Volume and High Dimensionality
Storage challenges include:
- Large embedding volumes: Billions of vectors require scalable storage and efficient indexing.
- High dimensionality: Embeddings of 128, 512, or 1024+ dimensions need specialized data structures and optimized storage formats.
Performance and Latency Bottlenecks
Performance factors include:
- Indexing and search speed: ANN techniques improve latency, but very large datasets demand optimized infrastructure.
- Batch insertion and streaming: Efficiently handling ongoing ingestion of new embeddings.
Distributed System Complexities and Operational Overhead
At scale, sharding, replication, and consistency management become complex. Automated scaling, monitoring, and failover are desirable for production systems.
Cost Factors
Vector embeddings may affect operational cost:
- Compute and storage requirements: High-dimensional data and fast search consume substantial resources.
- Operational overhead: Consider cost of infrastructure, team expertise, and maintenance.
Encryption at Rest and in Transit
Securing embeddings is crucial as they can encode sensitive information:
- Encryption at rest: Protects stored vectors using strong industry-standard algorithms.
- Encryption in transit: Ensures vectors remain confidential when transmitted between systems or users.
Oracle AI Database enforces encryption by default and integrates with enterprise key management solutions.
Access Control and Authentication
Control who can access, modify, or query embeddings:
- Granular permissions: Define user roles and table-level permissions.
- Integration with SSO and identity providers: Streamlines enterprise authentication.
- Audit trails: Track access and changes for compliance.
Data Sanitization and Monitoring
Reduce risk by implementing:
- Sanitization: Remove or obfuscate sensitive or personal information in embeddings before storage.
- Monitoring and anomaly detection: Detect unusual access patterns or potential misuse.
Advanced Cryptographic Techniques
For highly sensitive embeddings:
- Homomorphic encryption or secure multi-party computation: Enables computation and search on encrypted embeddings, minimizing exposure.
Common Vector Embedding Use Cases
Embeddings open up a wide array of practical use cases:
- Enterprise search and information retrieval: Improved accuracy and relevance in document and knowledge base searches.
- Personalization and recommendation engines: Enhanced user experiences by surfacing relevant content or products.
- Fraud and anomaly detection: Early identification of unusual patterns using embedding distances.
- Data deduplication and clustering: Streamlined datasets and improved analytics through intelligent grouping.
- Multimodal retrieval and analytics: Unified analysis over diverse data types, fostering deeper insights.
Storing Vector Embeddings and the Oracle Advantage
The following are a few key points related to the storage of vector embeddings, and how Oracle AI Database’s native vector store capabilities can streamline and strengthen your stack with its native vector store capabilities.
Specialized Vector Databases
Dedicated vector databases are built for storing, indexing, and searching embeddings efficiently. These databases excel at large-scale similarity search with features such as:
- High-dimensional indexing: Specialized data structures to support billion-scale embeddings.
- Approximate search capabilities: Fast, scalable similarity queries using Approximate Nearest Neighbor (ANN) techniques.
- RESTful APIs and SDKs: Developer-friendly interfaces for ingestion and search.
Popular examples include Pinecone, Weaviate, Milvus, and Vespa. Specialized databases are ideal for workloads with large volumes of embeddings and demanding similarity search requirements.
SQL/NoSQL Databases with Vector Support
Traditional databases are evolving to meet AI’s demands by adding native vector data types and search capabilities:
- SQL databases: PostgreSQL (with pgvector), Oracle AI Database, and others support vector columns and similarity search via extensions or built-in features.
- NoSQL databases: MongoDB and Redis now offer basic vector search features, often using plugins or modules.
This integration enables seamless blending of embeddings with structured business data, supporting hybrid query scenarios.
Oracle AI Database Approach
From Oracle’s viewpoint, AI databases must natively support vector data types, efficient similarity queries, and enterprise security for integrating embeddings across applications. Oracle AI Database is designed to address these needs at scale.
The Oracle AI Database offers a unified approach allowing developers to:
- Store embeddings alongside structured and unstructured data.
- Run similarity queries directly using SQL and specialized vector search operators.
- Integrate with Oracle’s rich security, high availability, and scalability features.
- Combine vector search, filtering, ranking, and analytical queries in a single stack.
Example Procedures – Using Vector Embeddings in Oracle AI Database
The following examples are intentionally minimal and illustrative. They highlight how Oracle AI Database supports native vector storage and SQL-based similarity search.
CREATE TABLE documents (
id NUMBER,
content CLOB,
embedding VECTOR
); This example shows a minimal table definition using Oracle AI Database’s native VECTOR data type. In practice, embeddings are stored alongside structured or unstructured application data in the same database.
SELECT id, content
FROM documents
ORDER BY VECTOR_DISTANCE(embedding, :query_vector, COSINE)
FETCH FIRST 5 ROWS ONLY; This example illustrates SQL-based similarity search in Oracle AI Database. The :query_vector placeholder represents the embedding generated from user input by an embedding model (inside or outside the database) and is used to rank the nearest matches.
Hybrid query pattern (semantic + relational filtering)
SELECT id, content
FROM documents
WHERE content IS NOT NULL
ORDER BY VECTOR_DISTANCE(embedding, :query_vector, COSINE)
FETCH FIRST 5 ROWS ONLY; This hybrid pattern combines standard SQL filtering with semantic ranking in a single query. It is useful when semantic search must also respect metadata constraints, access controls, or business rules. This streamlines workflows and facilitates embedding-driven applications without moving data across siloed systems.
Using Oracle Autonomous AI Database in conjunction with langchain-oracledb, for example, we can simply generate embeddings, store, and interact with vectors directly from within the database – requiring no additional investment in another separate vector database.
Querying and Searching for Stored Vector Embeddings
The following are a few of the things you should keep in mind if your work involves querying and searching for stored vector embeddings:
Approximate Nearest Neighbor (ANN) Algorithms and Data Structures
Searching for similar embeddings at scale requires efficient algorithms:
- ANN Techniques: Rather than exact search, algorithms like HNSW (Hierarchical Navigable Small World), IVF (Inverted File Index), and PQ (Product Quantization) yield fast, near-accurate results.
- Data Structures: Use trees (KD-Tree, Ball Tree), graphs (HNSW), or hash-based indices (LSH) to organize and retrieve vectors efficiently.
ANN can deliver millisecond-latency searches over millions or billions of embeddings, making it essential for operational AI applications.
High-level retrieval workflow (generalized)
At a high level, semantic retrieval follows a simple and reusable pattern that applies across vector databases, frameworks, and application stacks:
1. Convert user input into a query embedding
2. Compare it against stored embeddings
3. Rank results by similarity
4. Apply filters and business rules as needed
This high-level workflow is framework- and language-agnostic. While the underlying implementation differs across platforms and tools, the conceptual flow remains the same for the most vector search and RAG-style applications.
Popular Libraries
Several tools make it easier to store, and search embeddings:
- Vector search libraries: FAISS (Facebook AI Similarity Search), Annoy (Spotify), NMSLIB, ScaNN.
These libraries power both stand-alone vector stores and integrations within general-purpose databases.
How to Choose the Right Similarity Metrics
Selecting the right similarity metric is critical for effective search:
- Cosine similarity: Measures the angle between vectors; ideal for text and semantic similarity.
- Euclidean distance: Useful for geometric or spatial data.
- Dot product: Common in deep learning models; efficient for high-dimensional comparisons.
Your choice depends on the nature of your data and the specifics of your application.
Oracle AI Database Capabilities
Oracle’s AI Database combines native vector capabilities, enterprise security, and proven scalability, making it a robust choice for organizations seeking a unified solution for traditional data and AI-enabled workloads.
- Native vector data types and indexing: Supports efficient storage and retrieval of high-dimensional vectors.
- Integrated similarity search: Enables querying and filtering based on vector proximity.
- Enterprise-grade security: Encryption at rest, robust access controls, and activity monitoring.
- Hybrid queries: Seamless combination of structured, unstructured, and vector data in complex analytical tasks.
- High scalability: Handles massive volumes of embeddings without performance degradation.
Best Practices for Working With Vector Embeddings
The following are a few of the best practices for using vector embeddings to power semantic search, personalized recommendations, multimodal analytics (including anomaly detection), and domain-specific insights across enterprise applications.
Semantic Search and Information Retrieval
Semantic search with embeddings offers better context and intent recognition than keyword search. Querying an embedding retrieves documents or objects with similar meanings—crucial for legal, healthcare, customer support, and research applications.
Recommendation Systems and Personalization
Compare user and item embeddings to power personalized recommendations. This increases engagement, retention, and value in e-commerce, media, and B2B applications.
Multimodal Search and Anomaly Detection
Combine embeddings across text, image, and audio for multimodal analytics or use distance-based thresholds to flag anomalies and outliers in fraud prevention or system monitoring.
Domain-Specific Analytics
Specialized embeddings can be trained for particular industries—finance, healthcare, retail—and stored/retrieved for advanced analytics, predictions, or compliance monitoring.
How to Select Appropriate Tools and Architectures
- Match your use case to the data platform (dedicated vector database vs. extended relational/NoSQL).
- If you want both, Oracle AI Database is a good option.
- Factor in scale, integration needs, security requirements, and budget.
- Leverage proven libraries and frameworks to speed up development.
Security and Scalability Considerations
- Encrypt embeddings, control access, and monitor usage.
- Choose solutions that scale with data growth and user demand.
- Balance security, performance, and cost based on enterprise requirements.
Architectural Patterns
- Hybrid architecture: Combine vector storage/search with structured data in a unified database like Oracle AI Database.
- Microservices: Separate ingestion, search, and analytics as independently scaling components if needed.
- Cloud-native solutions: Consider managed vector databases for elasticity and reduced operational burden.
Tooling Reminders
- Use specialized libraries (FAISS, Annoy, HNSWLib) for local development, prototyping, or custom solutions.
- For production or enterprise use, rely on databases with native vector support and robust security, such as Oracle AI Database. .
Frequently Asked Questions (FAQ)
What are vector embeddings and why do they matter?
Vector embeddings are dense, high-dimensional numeric representations of objects like text, images, audio, or code. They place semantically similar items near each other in a continuous space, enabling tasks like semantic search, recommendations, RAG, deduplication, and anomaly detection. Compared with keyword or symbolic methods, embeddings better capture meaning, handle synonyms/paraphrases, and are robust across languages and modalities.
What are the main challenges in storing and querying embeddings at scale?
- Volume and dimensionality: Billions of vectors, often 128–1024+ dimensions
- Performance: Fast indexing and low-latency search, efficient batch/stream ingestion
- Distributed ops: Sharding, replication, consistency, monitoring, and failover
- Cost: Compute, storage, and operational overhead
- Security: Encryption at rest/in transit, access control, auditing, data sanitization, and advanced cryptographic techniques for sensitive data
Where should I store embeddings: a dedicated vector database or a database with vector support?
Two common patterns:
- Specialized vector databases (e.g., Pinecone, Weaviate, Milvus, Vespa) for high-scale, low-latency similarity search with ANN, SDKs, and REST APIs.
- SQL/NoSQL databases with vector support (e.g., Oracle AI Database, PostgreSQL with pgvector, MongoDB, Redis) for blending vectors with structured data and enabling hybrid queries.
Your choice should consider scale, integration with existing data, security, cost, and operational complexity.
What does Oracle AI Database provide for embeddings?
Oracle AI Database offers native vector types and indexing, integrated similarity search in SQL, enterprise-grade security (encryption, granular access control, auditing), and high scalability. It supports hybrid analytical queries across structured, unstructured, and vector data. With Oracle Autonomous AI Database and libraries like langchain-oracledb, teams can generate, store, and query embeddings within one platform—avoiding data silos and extra operational overhead. Encrypt data, enforce access controls, and monitor usage to meet enterprise requirements.
Conclusion
Storing and querying vector embeddings is a critical enabler for next-generation AI and data applications. By leveraging the right databases, libraries, and best practices, organizations and engineers can unlock new value from unstructured content, while maintaining performance, scalability, and security.