A lot of developers concentrate on making sure their code functions correctly in ideal conditions, but what happens when there is an outage? If an application instance crashes, or we are performing maintenance, how does that affect the end user? It can be more than just an annoyance, it can cost money and really damage their trust. Industry studies estimate that even a few minutes of downtime can cost thousands of dollars and permanently impact your brand.
Introduction
Most developers optimize for the happy path. However, failures are inevitable in production, and a single crash or maintenance window can ripple outward, costing money, frustrating users, and eroding trust. High Availability (HA) isn’t just about servers and databases anymore; it’s about the way we design, build, and architect applications from day one.
The Oracle Maximum Availability Architecture (MAA) team has spent over 20 years helping enterprises achieve uptime at the platform level. But HA doesn’t stop at the infrastructure layer. With this project, we asked: What if developers applied the same discipline inside the application itself?
Instead of treating resilience as an afterthought, what if we designed it in from day one?
Key Takeaway: High availability is not just about being “up” — it’s about being reliably fast and responsive, even when things go wrong.
This is the first post in our HA App Development Best Practices series. Throughout this series, we will share technical principles, real-world hurdles, and best practices we discovered while creating and testing a representative application. We will not stick to theory — we’ll show how architectural choices and code patterns measurably improve availability..
Let’s jump in.
Why HA Matters for Your App: The Project Premise
Traditionally, HA was an ops problem. Today, users expect responsiveness despite failures, so developers must make HA part of application design, not just deployment.
We started this project to demonstrate that availability should be integrated from the ground up, rather than just added as an afterthought. So we developed a real application, simulated real failures, tracked everything, , and continually experimented to find out what actually helps.
Availability isn’t just about being “up.” An application might return a 200 OK, but if it takes too long to respond, users still perceive it as a failure. Real availability means the app is up, it’s working as expected, and it’s responding fast enough to keep people moving.
While some downtime is inevitable, our goal was to maximize uptime and measure practical resilience beyond just “online/offline” status. By focusing on users’ real experiences — speed, correctness, and reliability — we could improve the app’s true availability.
Project Development Uncovered
To explore HA from a developer’s perspective, we built a simple RESTful service with two endpoints:
- GET /user/{uid}: retrieve user info
- PUT /user: insert or update user info
The app is deliberately minimal. Our goal was not complex business logic, it was to test how architecture and code choices impact availability, performance, and recovery. By keeping it simple, we aimed to make the results broadly applicable.
We defined success and failure in strict, user-facing terms:
- HTTP 200 for valid responses
- HTTP 404 when data isn’t found
- No HTTP 5xx errors allowed — any 5xx was treated as downtime
- Responses always under 50 ms — any outlier counted as a service interruption
Measuring HA in Real Time
We established strict SLAs to create real-world conditions. Success was defined as HTTP 200 responses that return a name, with HTTP 404 used for unknown IDs. Failures included any HTTP 5xx status.
For performance, we drove a load of 1,000 requests per second with 10 percent as PUT requests. We enforced a maximum latency of 50 ms per request, whether the request ultimately succeeded or failed, and we did not allow outliers.
To test efficiency under pressure, we limited the application to a maximum of 8 database connections while still delivering 1,000 requests per second.
Our availability definition was strict: any 5xx response or any request with latency greater than 50 ms counted as a service outage. The goal was to achieve maximum availability during outages.
This intentionally tough SLA let us see which frameworks truly handled stress, and pushed the system to deliver not just uptime, but fast, reliable, and predictable service.
By changing how we define availability, we moved the conversation away from just asking if it is online to asking if it is responsive and reliable, especially under stress.
Stress Testing for the Real World
Once we had the app up and running, we put it to the test under heavy load, triggering both planned and unplanned outages.
- Database connection dropouts
- Server crashes
- Network issues
We weren’t just testing for smooth sailing; we aimed to replicate everything that could go wrong, since that’s the reality in production.
We wanted to know not just if the system could survive, but how fast it detected, responded, and recovered:
- Response time: how quickly it handled both successful and failed requests when things got busy
- Resilience: how it behaved during those failure scenarios
- Recovery speed: how fast the system bounced back after going down
Same App, Eight Frameworks
To make the results meaningful, we ported the same app across eight modern stacks, and held every framework to the same strict SLA:
- Performance: 1,000 requests per second with a strict 50 ms service level agreement
- Efficiency: limit to 8 database connections to really test connection pooling and avoid resource overloads
- Availability: any 5xx errors or slow responses mean hard downtime, no exceptions
These constraints exposed weak spots, trade-offs, and optimizations across frameworks, providing apples-to-apples comparisons for languages, frameworks, and driver maturity.
- Java Servlet
- Spring Boot with UCP and HikariCP
- Node.js (JavaScript)
- Node.js (TypeScript)
- .NET C#
- Python
- Rust
- Go
Spoiler: not every stack handled failure gracefully. We’ll dive into those differences in upcoming posts.
Built and Tested on Oracle Cloud
We ran all of this on Oracle Cloud Infrastructure (OCI) with:
- Oracle AI Database 26ai
- Autonomous AI Database + APEX for storing and visualizing results
That setup gave us a real-world environment, not just lab experiments, while letting us analyze results quickly with dashboards and charts.
Although we chose Oracle Cloud for testing, the HA concepts, principles, and lessons are broadly applicable across cloud providers and deployment environments.
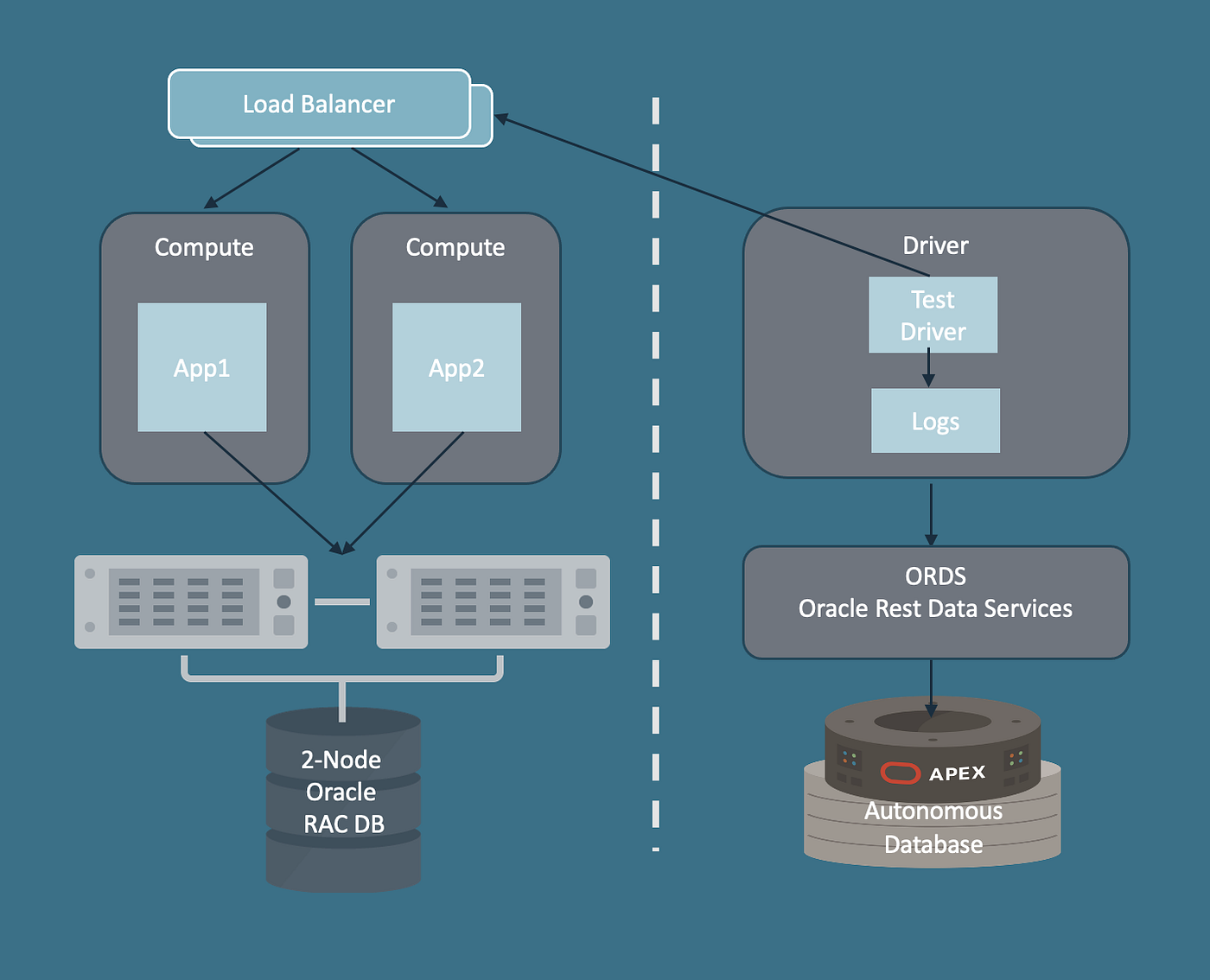
In upcoming blog posts, we’ll dive into the architecture of this test harness, explore how each component contributed to HA, and share real-world test results and lessons learned.
What’s Next?
This is just the foundation. Over the next posts, we’ll peel back the layers of resilience step by step from application architecture and load balancers to connection pools and real failover tests:
- Designing the application architecture for high availability
- How load balancers detect and respond to outages
- Connection pooling strategies across frameworks
- Real failover scenarios, both planned and unplanned
- Actual test results, logs, and graphs
We’ll also share practical tips and sample code patterns to help you design for HA from the start — regardless of your chosen tech stack.
Our aim is to make HA practical for developers. Because in the end, high availability isn’t something you sprinkle on after coding — it’s something you design into every layer from the very first line.
While our test criteria are intentionally strict, they highlight how much headroom different platforms provide before user experience suffers. The trade-off between cost, complexity, and real HA is one every engineering team must weigh.
Stay tuned!

