In part-1 of this series, I covered how we went about comparing features of Apache Hudi and Deltalake. To recap, my team came away with the feeling that both libraries are pretty similar with a slight edge for Hudi because of the possibility of handling version reconciliation by parsing the data files directly and its slightly better administration capabilities.
We felt both deserved to move forward for more in-depth performance testing as there was no clear winner. However, given “time travel” was supported in Hudi’s copy-on-write table type we decided to run our tests against that.
As alluded to previously our storage technology is Object Store and our Spark runs on Kubernetes in the cloud aka OKE. So this is not a typical on-prem Hadoop setup. We had no streaming use-case currently (jinx!!) and so we were interested in using these in our Spark batch jobs.
Here are the criteria we came up with based on the following assumption
- 100 MB is the average file size in JSON format during an incremental run
- 1 GB is the average file size in JSON format during an initial load
- Note that we could receive 100’s of such files together in any given batch but to keep the test simple we opted to compare the performance of processing one file as things should scale naturally with Spark
- Two to four minute processing time per file is the best guess processing requirement to keep the latency for delivering an insight to around 1hr from when data is available
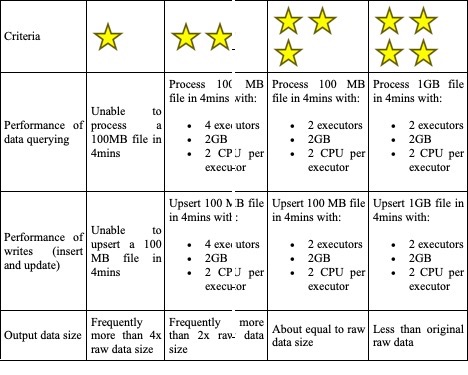
Performance numbers
Without further adieu, here is the surprise (at least we were surprised by these numbers) you have been waiting to see
Data Size
To set up our tests we started off two entities, users and transactions, for which we could arbitrarily generate input data.
Note that Deltalake uses snappy compression whereas Hudi uses GZip.
The output size measurement shown here is after an initial run and an update run using the same input file to create a second version of the data
Users Table

Transactions Table
![]()
Write Performance
Writes really set up the data for the read. Using “merge into”/”upsert” with both libraries we could essentially run the same code for creating the table with the first run and also for updating it with a second run.
We did not partition the data to not only keep the setup simple but it’s also something we want to avoid for real as there are no set access patterns the users will adhere to when querying in the data lake.
Resources: Driver memory: 4GB, Number of executors: 4, Memory/Executor: 4GB, CPU/Executor: 2
Hudi Parallelism: set to 4; No custom config for Deltalake

Read Performance
To measure the performance of read we came up with a set of “representative” queries that had filters, joins and aggregations between the two entities. We then measured the total time for this entire Spark job to finish.
Resources: Driver memory: 4GB, Number of executors: 4, Memory/Executor: 4GB, CPU/Executor: 2
Hudi Parallelism: set to 4; No custom config for Deltalake

Summary
As you can see, the performance is pretty comparable for smaller files but Hudi definitely used more resources than Deltalake as is evident by the sharp decline in performance for the largest file. I am not presenting the runs we did 2 executors and 2GB memory/executor to keep this readable but the decline happened sooner. We were so surprised by the difference (after all, Hudi is used at Uber) that we even ran similar tests with Hudi’s merge-on-read table-type that is supposedly faster to write to but did not see a marked difference.
It’s quite possible that Hudi’s configuration needs additional tuning but without a Hudi expert in our payroll we couldn’t figure out what it was. However, we suspect that most of Hudi’s performance woes are because it uses older spark APIs (hence Hudi supports Spark 2.1 whereas Deltalake only works with Spark 2.4.3 and above) and on top of that has to read more data than Deltalake.
Two other write operations we did not look into with Hudi were INSERT and BULK_INSERT because they will lead to duplicates that our system cannot tolerate or the pipeline has to account for additional logic to split the work into update vs insert. Also, Hudi seems to have true streaming writes whereas Deltalake offers micro-batches that could be important for some use cases and might offer better or comparable performance in that environment.
Anyway it’s time to see the final grades
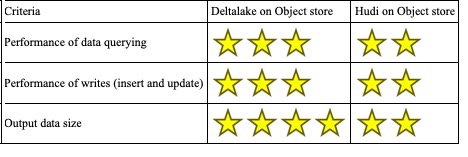
We ultimately ended up choosing Deltalake as our incremental data processing framework to power our batch process as it suited our use case better than Hudi. Things could have turned out differently if we were looking at a streaming use case where throughput is not quite as important as latency. Every situation is different and ultimately an evaluation comes down to what you are willing to give up or suffer through to solve a higher priority problem.
