ACID compliance on Data Lake in a Hadoop-like system has gained a lot of traction and Databricks Delta Lake and Uber’s Hudi have been the major contributors and competitors. Both solve a major problem by providing different flavors of abstraction on “parquet” file format. In this blog, I will outline how my team went about making a choice.
A few words on evaluation.
A good technology solves your most pressing problem and creates a whole host of others so at the end of an evaluation you can adopt the new technology with your eyes wide open. Or so we think because no amount of POC can fully replicate a moderately complex production environment or anticipate all the ways it can change often within the time frame it takes to push the newly minted tech stack to production. In a previous project, we decided to rewrite our entire ETL pipeline with a traditional ETL tool after evaluating it against Apache Spark and then a health system decided to buy half the hospitals in the country and we realized our half re-written ETL cannot keep up with the processing demands.
So in the interest of “moving fast” to production where we can get the best data possible to analyze and evaluate the technology we try to time box the evaluation based on the likelihood and severity of changing course in the future (organizational impact). In this case, we spent about a month evaluating Deltalake and Hudi, short-circuiting the process as soon as sufficient data was available pointing us in the right direction while building support for both technologies within the Spark cluster (not a cop-out, I promise we have a clear winner at the end).
Our decision-making process
As in any software developer’s household, ideas and processes flow seamlessly between personal and professional life (standup with kids after my coffee – check, retrospective before bedtime – check). A structure for evaluating ideas is one of those – I am not even sure where it began, but all I remember from the experience of coaching my daughter’s FLL team last year was scrambling to figure out how I can cut through the politics amongst 5th graders (can’t wait to see what happens when they are old enough to run for office) and motivate them to work towards a common goal. I figured if they can give each other honest feedback without really paying attention to who is saying the words I could get them on the path of continuous improvement and self-correction
Here is a picture of the team’s evaluation of project ideas their teammates came up with (numbers are scores from all the kids on the team)

Back at work, since we are adults, we use star notation instead of scores and tied the criteria for evaluation to how important it is for the product to succeed
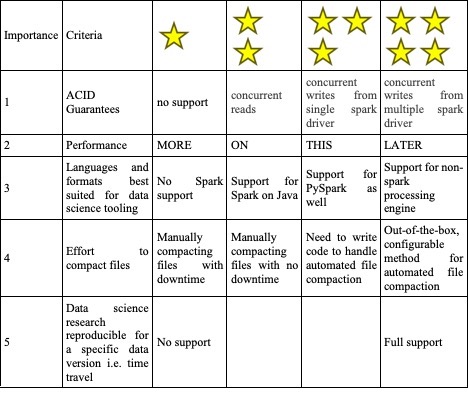
The table above is all the criteria we used for the “theoretical” evaluation of the two technologies and what would be given a 1 star vs a 4 star. This is an opportunity for engineers to work with stakeholders/product managers and determine the parameters for feasibility analysis as well as potential trade-offs and is ideally done before knowing anything about the capabilities of the technologies under evaluation so it truly reflects the need of the product/business. Otherwise, it tends to get skewed.
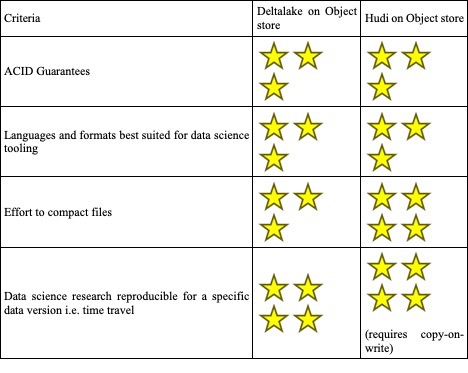
ACID guarantees for both Hudi and Deltalake are predicated on the atomicity and durability guarantees of the storage system. Our Spark cluster is backed by OCI Object Storage that does not guarantee “consistent listing” i.e. Once a file has been written in a directory, all future listings for that directory must return that file (don’t panic, Amazon S3 doesn’t guarantee this either). Hence concurrent writes from multiple Spark drivers can lead to data loss and both libraries score 3 stars.
Both Deltalake and Hudi need Apache Spark to interpret the data for you – that is they use the Spark processing engine to read the metadata (timeline in the case of Hudi and deltalog in the case of Deltalake) associated with data to provide features such as time travel and to figure out the latest version of the data. Currently, neither libraries support Dask that is gaining popularity within Oracle’s data science community and hence both get 3 stars. Hudi is slightly easier to work with as all the metadata is stored in the parquet data files whereas Deltalake’s deltalog is a separate JSON file that requires an understanding of the deltalake protocol.
Apache Hudi supports two types of table – Copy-on-write and Merge-on-read. Only the former supports time travel. So we evaluated that more thoroughly in our performance test.
Lastly, the main differentiator for Hudi is its admin console (although I can’t find documentation about it after its 0.5.0 version https://hudi.apache.org/docs/0.5.0-admin_guide.html) and its ability to “configure” compaction (combine small files and delete older version of data) without the need to write an independent job as is the case with open source version of Deltalake (the paid version support auto-optimize).
In summary, the two libraries are pretty close when it comes to feature parity. With that out of the way, we will get down to the second most important criteria, performance, in the next blog.
