
Jeremy Morgan, Senior Training Architect
Key Takeaways
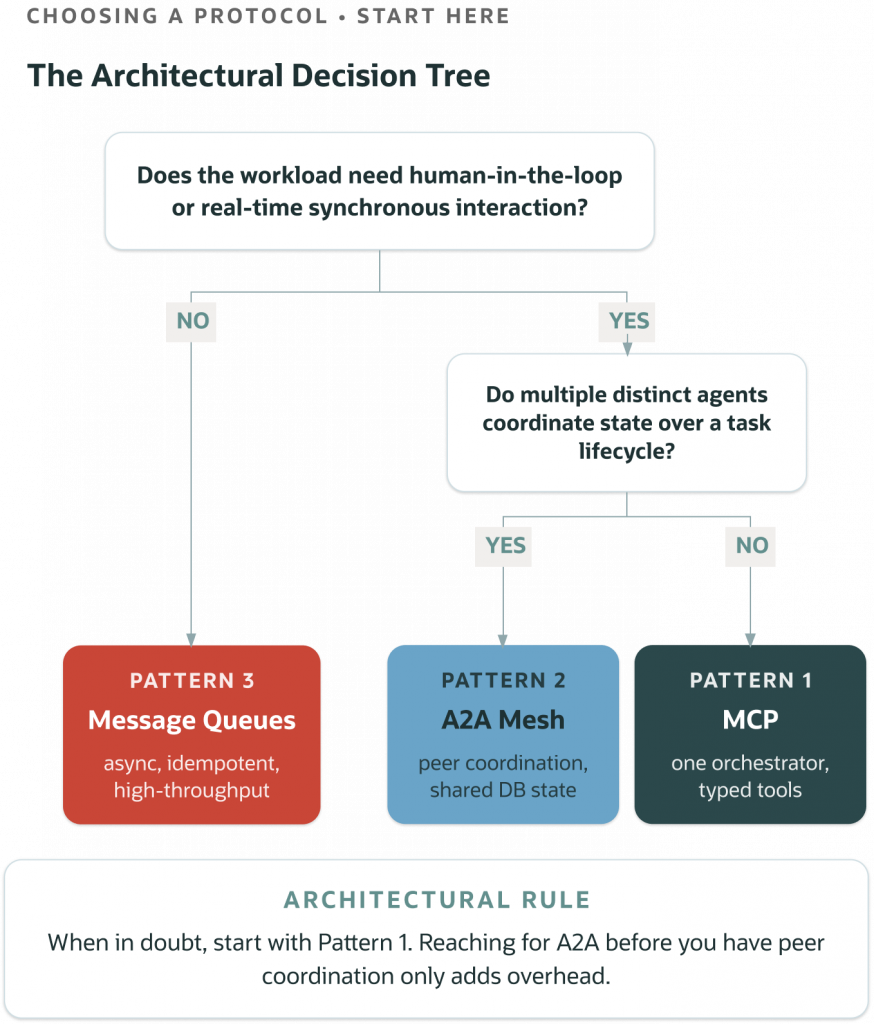
- Agent communication has three problems, not just one. Tool access, peer coordination, and system integration each need a different solution. Most production failures occur when one protocol tries to cover all three.
- MCP and A2A are complements, not rivals. The Model Context Protocol (Anthropic, 2024) defines how models find and use tools. The Agent-to-Agent (Google, 2025) explains how agents cooperate. Generally, agents use A2A for coordination and MCP for tool access.
- Simple infrastructure still works well for many tasks. Message queues provide at-least-once delivery, dead-letter queues, and automatic back-pressure. Adding these features to MCP or A2A requires coding idempotency, retry coordination, and ordering manually. When the LLM acts as a worker, use a queue.
- Three reference patterns cover most production needs. MCP-Centric Tool Access (one orchestrator, multiple tools), A2A Mesh with Oracle Memory (peer agents coordinating via task envelopes), and Queue-Backed Backoffice Agents (RabbitMQ workers writing to Oracle, without agent protocol). Each includes runnable Python in the companion repo.
- The protocol layer can change; the memory layer should stay stable. The Oracle AI Database remains consistent across all three patterns (vector-indexed, transactional, audit-friendly). This consistency allows the protocol above to evolve while keeping the system of record intact.
The protocol you picked is doing three jobs at once

Imagine your team created a multi-step research agent. It has three specialist sub-agents: a retriever, a synthesizer, and a reviewer. They connect over plain REST. It worked well in staging. But in production, p99 latency hit 14 seconds at the third hop. Retries piled up. A failed downstream call left the orchestrator with a half-written database row. The rollback logic, designed for a different failure mode, made things worse.
Then they implemented RabbitMQ. Latency stabilized, and throughput increased. Now, retry issues were someone else’s concern, which was the goal. But two weeks later, the security team filed a ticket. They asked which agent had touched which row during a specific time, and nobody could answer. Request-scoped tracing had disappeared into the queue.
The LLM-facing tool interface had splintered into six unique queue-message schemas, one for each specialist. None were introspectable by the model. The synthesizer agent started calling tools it didn’t know about and failed silently if they didn’t respond.
The team hadn’t chosen a bad protocol. They had picked the same protocol for three different jobs, twice in a row.
Agent communication isn’t just one problem. It involves tool access, peer coordination, and system integration. Each area needs its own solution.
Tool access occurs when a model needs to use a capability it lacks, like a SQL query or memory write. The Model Context Protocol (MCP) addresses this need. It’s often the first task for production agent systems.
Peer coordination happens when one agent assigns work to another. This isn’t just a function call; it’s a task with its own state and lifecycle. The second agent may work independently on this task. The Agent-to-Agent protocol (A2A) supports this, solving problems that the tool-call model can’t handle well.
System integration involves agents interacting with your broader infrastructure—databases, queues, services, scheduled jobs, and audit pipelines. For two decades, REST, message queues, and event buses have managed this. Often, the simplest solution is the best.
This article offers a framework to help you choose the right protocol for your needs. It includes three reference patterns for building with these protocols, each with runnable Python examples using Oracle AI Database. One constant remains true as the protocol layer evolves: the governed memory core.
The Agent Communication Matrix
Key insight: Protocols aren’t ranked on a single axis. They differ on five concrete attributes (interaction shape, streaming, reliability semantics, governance surface, and primary job), and the right choice is the one whose attribute profile matches the job.
| Protocol | Primary job | Interaction shape | Streaming | Reliability semantics | Governance surface |
|---|---|---|---|---|---|
| MCP | Expose tools and resources to a model | Typed request/response: model calls a discoverable tool, server returns structured output | Native: supports streaming responses and progress notifications | At-most-once over HTTP/JSON-RPC; retries are the client’s job | Strong: tools self-describe via JSON Schema; capabilities are discoverable at connection time |
| A2A | Coordinate work between peer agents | Task-oriented: one agent submits a task, another reports state changes (submitted, working, completed, failed) | Native: status and artifact updates stream as the task progresses | At-most-once with task-level retry; tasks are addressable and resumable | Medium: agent cards declare capabilities, but task semantics are author-defined |
| REST | Service-to-service integration | Synchronous request/response: caller blocks until server returns | None native; long-poll or upgrade to SSE/WebSocket if needed | Best-effort; retry and idempotency are the application’s problem | Weak by default: OpenAPI helps, but it’s convention, not contract |
| Message queue | Hand work to a worker asynchronously | Fire-and-forget: producer drops a message, worker consumes when ready | None: queues deliver discrete messages, not streams | At-least-once with ack/nack; dead-letter queues catch poison messages | Medium: per-queue ACLs and DLQs give operational control, but no schema layer |
| Event bus | Broadcast facts to many consumers | Publish-subscribe: one producer, N consumers, decoupled in time | Stream-native: consumers replay from offsets | At-least-once, often with ordering guarantees per partition; replayable history | Medium: topic-level governance, schemas via registry (Avro, Protobuf), but consumer behavior is author-defined |
Caption: The Agent Communication Matrix. Use these five attributes to decide which protocol fits which job. WebSockets, SSE, and gRPC streaming appear in this discussion as transports, not as peers; they carry messages for several of the protocols above.
Three cells in this matrix do most of the real work, and they’re worth examining.
MCP and A2A look similar on the wire but interact differently. Both use HTTP, JSON-RPC, and streaming. MCP treats interaction as atomic: the model makes a call, and the server returns a structured response. A2A treats interaction as stateful: an agent submits a task, which follows a lifecycle (submitted, working, completed, failed) that both sides monitor.
This has clear implications for engineers. If your “agent” acts like a stateless function, MCP is ideal, and A2A adds overhead. If your “agent” has a lifecycle (it can pause, resume, check status, or cancel), A2A provides functionality that MCP lacks. This highlights the real differences between Pattern 1 and Pattern 2.
The reliability column is the most important trade-off in the matrix. Teams often misjudge it.

At-most-once delivery, common in HTTP protocols like MCP and REST, means that a failed request might have been completed or not. This leaves the client uncertain.
At-least-once delivery, typical for queues and event buses, ensures a message is processed at least once. However, it might be processed more than once if a worker crashes. Here, idempotency becomes the app’s responsibility.
Neither approach is better than the other. The key question is where you want retry logic: in your application code (HTTP) or in your infrastructure (queues).
Pattern 3 suggests that for certain agent tasks, placing retry logic in the infrastructure is better.
MCP’s “strong” governance and REST’s “weak by default” rating tackle the same issue that created the OpenAPI ecosystem, but they do it differently. MCP servers self-describe when a connection happens. For example, a client requests tools/list and receives a complete schema of capabilities. This includes types, descriptions, and parameter constraints.
In contrast, REST provides OpenAPI only if the producing team publishes and maintains it, while the consuming team must trust it. That’s three “if”s the agent runtime can’t resolve at runtime. MCP makes discoverability a requirement, not just a convention. This governance model includes auditable tool inventories, type-checked invocations, and capability negotiation for each session. Many underestimate this before adopting it. This is the edge that Pattern 1 uses.
The matrix doesn’t choose a protocol for you. It shows what you’re trading.
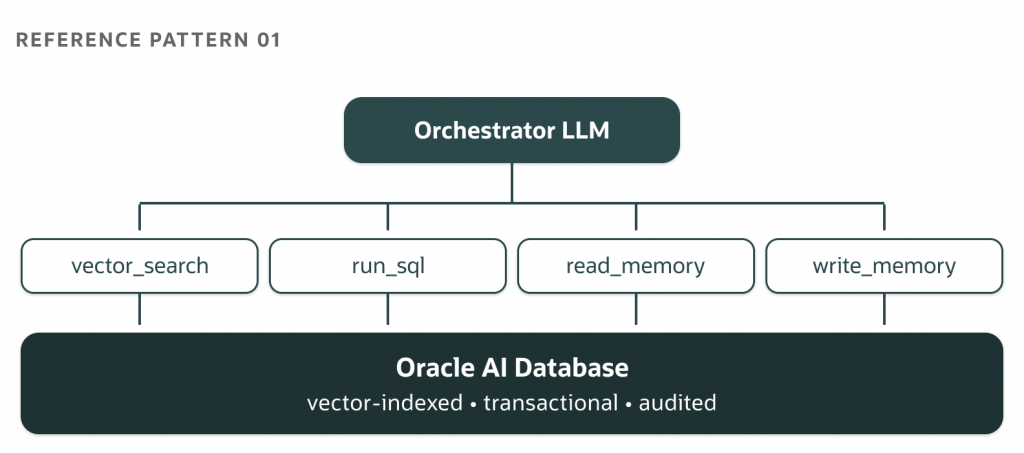
Pattern 1: MCP-Centric Tool Access
Spec: Model Context Protocol specification, Anthropic (2024)
This is the pattern for production agent systems: a single LLM orchestrator, one or more MCP servers, and a typed contract between them. The model doesn’t call your database directly. Instead, it uses a tool that interacts with it, and this difference is important.
MCP excels at the discovery layer. When an MCP client connects to a server, it sends a tools/list request. In return, it receives the full schema of available capabilities: names, parameters, descriptions, and return types. The model sees this inventory before acting. Selecting tools becomes a reasoning step rather than a hardcoded choice. This is a significant change. A model with discoverable tools handles “I don’t know how to do that” better than one with fixed function calls. The lack of a tool provides useful information for the model to reason about.
Oracle AI Database serves well as the MCP server. The capabilities you want to expose to an agent—like vector search over embedded content, parameterized SQL against business tables, and structured memory reads and writes—fit perfectly with MCP’s tool model. A typical Oracle-backed MCP server offers four or five tools: vector_search, run_sql, read_memory, write_memory, and summarize_thread. Each is a small, focused function with a typed schema. The model chooses among them based on the task.
The code below shows the minimal version: an MCP server registering one tool that performs vector search against Oracle AI Database. Note the typed array.array("f", ... ) bind for the vector column; a plain Python list will not work. The full server, with authentication, retries, and the other four tools, is in the companion repo.
import array
from mcp.server import Server
from mcp.types import Tool, TextContent
import oracledb, os
server = Server("oracle-tools")
pool = oracledb.create_pool(user=os.environ["DB_USER"],
password=os.environ["DB_PASS"],
dsn=os.environ["DB_DSN"], min=1, max=4)
@server.list_tools()
async def list_tools() -> list[Tool]:
return [Tool(
name="vector_search",
description="Semantic search over the knowledge base. Returns top-k passages.",
inputSchema={
"type": "object",
"properties": {"query": {"type": "string"}, "k": {"type": "integer", "default": 5}},
"required": ["query"],
},
)]
@server.call_tool()
async def call_tool(name: str, arguments: dict) -> list[TextContent]:
# Embed the query, then run an Oracle AI Vector Search against the indexed corpus.
vec = array.array("f", await embed(arguments["query"]))
with pool.acquire() as conn, conn.cursor() as cur:
cur.execute("""
SELECT chunk_text FROM kb_chunks
ORDER BY VECTOR_DISTANCE(embedding, :q, COSINE)
FETCH FIRST :k ROWS ONLY
""", q=vec, k=arguments.get("k", 5))
return [TextContent(type="text", text=row[0]) for row in cur]
Here are a few key points about what’s happening here. The tool schema acts as a contract. The model views vector_search as a typed capability. It requires a query string and allows an optional integer k. This info helps the model decide when and how to use it.
The Oracle AI Database vector search executes as a single SQL statement on a VECTOR column. It uses a cosine-distance HNSW index. There’s no separate vector store, no sync job, and no eventual-consistency window.
The embed() call is left out here for clarity. In the repo, it connects to a local Ollama model. (This setup allows the demo to run without needing paid API keys).
In tests with the demo corpus (1,000 chunks using 768-dimensional embeddings via Ollama’s nomic-embed-text on a GPU workstation), median tool-call round-trip latency is 15.3ms. This includes 14.1ms for embedding inference and 0.9ms for Oracle vector search. On CPU-only hardware, the embedding step is usually 5 to 20 times slower, but the database side remains constant. Remember this key point: an MCP tool call to an Oracle-backed server is fast like a database, not like an LLM. The latency during an agent turn mainly relies on the model’s own inference, not the tool.
Recommended usage: Use one orchestrator agent with various specialized tools. Teams should standardize access across different agent frameworks or model providers. This setup works best when the typed schema improves model behavior, which is often true. MCP is ideal if you plan to add tools later. The discovery layer allows new capabilities to integrate with the model without changes on the client side.
When not to use this: Avoid having a single agent for just one tool. Don’t add a protocol if a function call is enough. If your “agent” is simply one model with a clear capability, an MCP server adds extra complexity. The discovery layer is helpful when there’s something to find; with only one tool, there’s nothing to discover.
Pattern 2: A2A Mesh with Oracle Memory
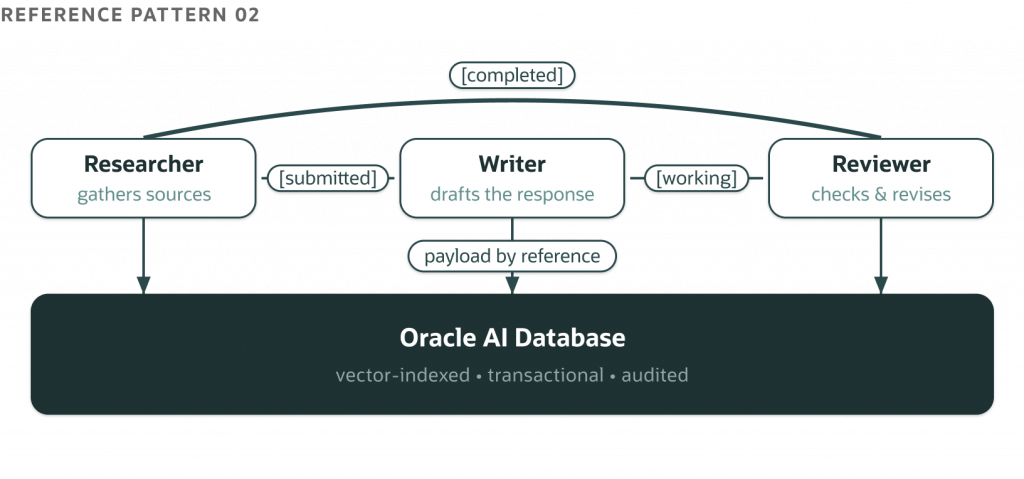
Spec: Agent-to-Agent Protocol specification, Google (2025)
A2A solves a problem MCP doesn’t: what happens when an agent isn’t calling a tool but handing work to another agent. The distinction sounds semantic until you try to express “the Researcher has finished gathering sources; the Writer should now draft a response using them” as a tool call. It doesn’t fit. The Writer isn’t a function the Researcher invokes. It’s a peer with its own model, its own prompt, its own lifecycle. A2A models that relationship as a task with state, addressable identity, and a status machine that both sides observe.
Consider a two-agent research workflow. A Researcher agent gathers context from external sources, checks relevance, and produces findings. A Writer agent then uses those findings to draft a response in the desired tone and format. A simple setup would have the Researcher return findings directly as a response to a tool call. This works for two agents but fails with three. When a third agent, like a Reviewer, needs the same findings, you end up duplicating data in message history instead of having a central record.
The A2A pattern changes this. Findings are stored in the Oracle AI Database as durable, vector-indexed rows. The Researcher writes them and sends a task message to the Writer with a reference to the findings, not the data itself. The Writer reads from the same table. This protocol ensures coordination, while the database holds the state. Multiple agents can access the same information without the protocol layer needing to see the contents.
The code below is one half of the mesh: the Writer agent’s task handler, listening for task.created events from the Researcher and producing a draft. The Researcher side, plus the full A2A envelope with retries and status updates, lives in the companion repo.
import asyncio, oracledb, os
from a2a.server import A2AServer
from a2a.types import Task, TaskStatus, Message
pool = oracledb.create_pool(user=os.environ["DB_USER"],
password=os.environ["DB_PASS"],
dsn=os.environ["DB_DSN"], min=1, max=4)
writer = A2AServer(agent_id="writer-v1")
@writer.on_task("draft_response")
async def handle_draft(task: Task) -> Message:
# The Researcher passed a memory_id, not the findings themselves.
memory_id = task.payload["memory_id"]
with pool.acquire() as conn, conn.cursor() as cur:
cur.execute("SELECT findings, source_refs FROM agent_memory WHERE id = :id",
id=memory_id)
findings, sources = cur.fetchone()
await writer.update_status(task.id, TaskStatus.WORKING)
draft = await llm_draft(findings, sources, tone=task.payload["tone"])
cur.execute("UPDATE agent_memory SET draft = :d WHERE id = :id", d=draft, id=memory_id)
return Message(role="agent", content=draft, refs={"memory_id": memory_id})
A few things in that snippet do the load-bearing work. The Writer never receives the findings in the message. It receives a memory_id and reads the actual content from Oracle. That’s the payload-by-reference pattern, and it’s the core architectural move of this pattern. The update_status call tells the Researcher (and any observer subscribed to the task) that work has begun; A2A’s status machine handles the streaming update without the Writer having to manage its own connection lifecycle. The final Message returns the draft inline because it’s the artifact of the task, but it also includes the memory_id ref, so a third agent picking this up next reads the same memory rather than re-deserializing a payload.
The trade-off is clear in token counts. In the demo, using serialized findings in the message costs 1,394 tokens per Writer turn for 3KB of research. This size is typical for a research agent creating a synthesized summary with source references.
In contrast, the payload-by-reference version only costs 61 tokens, no matter the findings’ size. This means a 22.9 times reduction at 3KB. The difference grows with findings size: at 500 characters, the reduction is 5.6 times; at 8KB, it reaches 58.9 times. The ratio isn’t fixed; it depends on how much data is in the message versus in the database. (Tokens counted using OpenAI’s cl100k_base tokenizer; Anthropic and Google tokenizers yield similar counts for English text.)
The compounding effect is more important than any single hop. A three-agent mesh sharing the same research context across two handoffs costs about 4,000 tokens in the naive version. In the payload-by-reference version, it costs only 183 tokens. At five hops, the difference exceeds 6,500 tokens per request. This is before any agent has done actual reasoning work. The cost of “just put it in the message” increases linearly with mesh depth. Most mesh topologies grow over time, not the other way around.
Oracle AI Database plays a key role here. The agent_memory table serves as a single source of truth. It is vector-indexed for semantic recall and transactional for consistency between reads and writes. Each row includes the agent ID, making it audit-friendly. The protocol layer can be A2A today and something else tomorrow. However, the memory layer stays the same.
Recommended usage: Use multi-agent workflows that need peer coordination, like planner-and-specialist patterns or multi-step research pipelines. This applies when multiple agents require consistent access to the same conversational or task state. A2A is ideal for long-running tasks where a synchronous request/response model would keep connections open unnecessarily.
When not to use this: Avoid A2A for one agent with a set of tools. This is an MCP problem, not an A2A issue. Using A2A with a single orchestrator adds unnecessary task lifecycle management. A good test: if you can name a second agent and explain its independent decisions, A2A works. If the “second agent” is just a different prompt using the same model, it’s a tool call.
Pattern 3: Queue-Backed Backoffice Agents
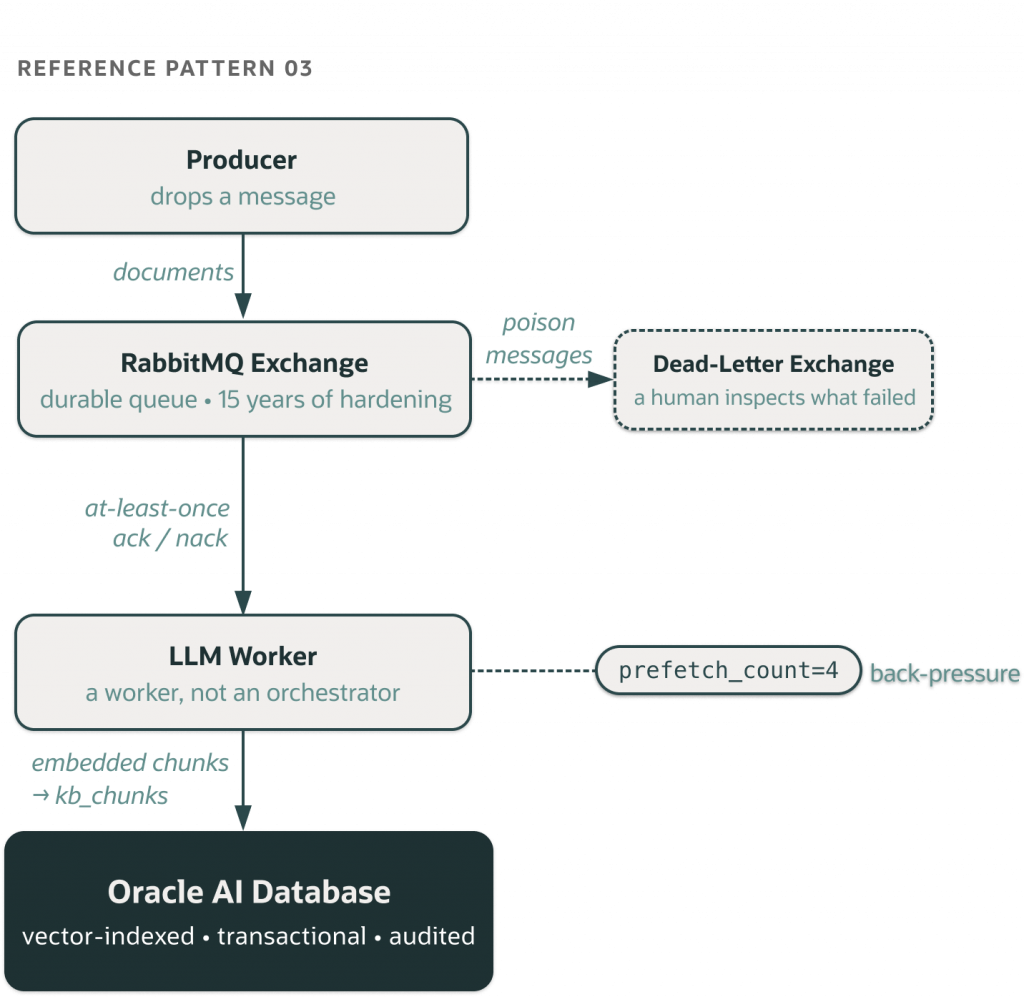
Imagine a document-processing pipeline. PDFs arrive in a queue. A worker agent picks them up, extracts text, embeds chunks, and writes them to the Oracle AI Database with vector indexing. It then shows results through a simple FastAPI endpoint. No MCP. No A2A. This is key. Adding either would increase the surface area without enhancing capability.
This pattern resists the pull of new protocols. The urge to add MCP just because there’s an LLM involved somewhere is strong but should be resisted. A worker using the same embedding model and prompt for each message doesn’t need tool discovery. It needs at-least-once delivery, a dead-letter queue, and back-pressure for when the embedding service slows down. These are queue issues, not agent-protocol issues.
The architectural shape predates the agent era, which is key to its function. Producers send messages to a queue. Workers process them at their own pace. If messages fail, they retry with exponential backoff and go to a dead-letter queue if they keep failing. The LLM acts as a worker in the pipeline, not as its orchestrator. This means the protocol layer above the LLM is as straightforward as the rest of the system, and that’s a benefit.
The code below is the worker’s core loop: consume a message, embed the chunks, write to Oracle AI Database, acknowledge. Producer, dead-letter handling, and the FastAPI edge live in the companion repo.
import array, json, oracledb, pika, os
from embed import embed_chunks # local Ollama call, see repo
pool = oracledb.create_pool(user=os.environ["DB_USER"],
password=os.environ["DB_PASS"],
dsn=os.environ["DB_DSN"], min=1, max=4)
conn = pika.BlockingConnection(pika.URLParameters(os.environ["AMQP_URL"]))
ch = conn.channel()
ch.queue_declare(queue="documents", durable=True,
arguments={"x-dead-letter-exchange": "documents.dlx"})
ch.basic_qos(prefetch_count=4) # back-pressure: at most 4 in-flight per worker
def handle(ch, method, _props, body):
doc = json.loads(body)
chunks = doc["chunks"] # already segmented upstream
vectors = [array.array("f", v) for v in embed_chunks(chunks)]
with pool.acquire() as db, db.cursor() as cur:
cur.executemany("""
INSERT INTO kb_chunks (doc_id, chunk_text, embedding)
VALUES (:doc, :txt, :vec)
""", [(doc["id"], t, v) for t, v in zip(chunks, vectors)])
db.commit()
ch.basic_ack(delivery_tag=method.delivery_tag)
ch.basic_consume(queue="documents", on_message_callback=handle)
ch.start_consuming()
The interesting parts are what isn’t there. There’s no tool schema, no agent identity, and no status state machine. The worker doesn’t need to show its capabilities because nothing is looking for it. The contract is the queue’s message schema, enforced by the producer’s chosen validation. The prefetch_count=4 setting tells the whole back-pressure story. If the embedding service slows down or Oracle’s connection pool fills up, messages stay on the queue instead of piling up in worker memory. The DLX (dead-letter exchange) on the queue means any message that fails repeatedly goes to a place where a human can check it, without the producer or any other agent needing to know.
Reliability semantics play a crucial role here. RabbitMQ provides at-least-once delivery with ack/nack semantics. This means if a worker crashes during processing, the message is sent to another worker. You don’t need application-level retry logic. In contrast, achieving the same reliability with an MCP server involves manually writing idempotency keys, retry coordination, and ordering logic. The queue handles this for you, and “for free.” RabbitMQ has been improving these semantics since 2007. You’re not going to outdo that on a side project.
The Oracle integration mirrors Patterns 1 and 2: it’s durable, vector-indexed, and transactional. The worker writes embedded chunks into the same kb_chunks table that Pattern 1’s MCP vector_search tool reads from. Teams using Oracle Database can merge the queue and memory layer into one component with Oracle Advanced Queuing. The trade-off is one less service to manage, but with slightly less portable demo code. This is the architectural benefit of the three-pattern arc: while the protocol layer changes (MCP, A2A, none), the memory layer remains constant. A document processed by Pattern 3’s queue worker is instantly searchable by Pattern 1’s MCP tool and can be referenced by Pattern 2’s A2A peers. This isn’t a coincidence; it reflects the efficiency gained when each protocol performs its best role, with Oracle AI Database maintaining the shared state for all three patterns.
Recommended usage: Use this for asynchronous, idempotent, and throughput-sensitive tasks. Examples include document processing, batch embedding, ETL pipelines, scheduled report generation, and back-office automation. Here, the LLM acts as a worker, not an orchestrator. This pattern is ideal when you need to manage slow or temporarily down downstream services. Queues can handle those issues without the application noticing.
When not to use this: Avoid it for real-time, conversational, or human-in-the-loop tasks. Don’t place a queue between a user and a chatbot. It’s not suitable when latency is more critical than throughput, especially when users expect quick answers. The conversational loop fits in Patterns 1 or 2, while Pattern 3 works behind them, tackling non-interactive tasks.
The Enterprise Reality
Cost scales with protocol surface area. Adding each protocol to an agent system creates another layer. This layer must be monitored, secured, and fixed if something goes wrong at 3 a.m. The patterns above outline the architecture, while what follows shows how that architecture shifts when faced with real users at scale.
Auditability across async boundaries. When a request crosses from MCP to a queue to A2A, the question regulators and security teams actually ask is which agent touched which row, and when? The answer almost never lives in any single protocol. According to LangChain’s State of Agent Engineering 2026 report, 89% of organizations have implemented some form of agent observability, and among teams already running agents in production that figure rises to 94%, with 71.5% reporting full tracing across individual agent steps and tool calls.
The teams ahead of the curve are not the ones with the most sophisticated protocols; they are the ones who decided early that the system of record sits in the database, not in protocol message history. Oracle AI Database earns its place here as that record. Every memory write, every tool invocation, every agent identity is durable in a single governed store that does not care which protocol delivered the message.
Cost scales with iteration, not just calls. The LangChain report shows that 32% of respondents see quality as their main blocker, while latency follows at 20%. Interestingly, cost concerns have dropped over the year. Teams aren’t just paying for tokens; they’re paying for hops. Each protocol boundary adds latency, retries, and overhead. A multi-agent system crossing four boundaries per request multiplies the engineering effort. The key lesson from Pattern 3 is clear: Avoid adding a coordination protocol when the work is async, idempotent, and doesn’t need a model in the orchestration loop.
Multi-tenancy and Isolation. A report shows that among enterprises with 2,000 or more employees, security is now the second-largest barrier to production, noted by 24.9% of respondents. This is more significant than latency, and it affects protocol choice. MCP servers can be deployed for each tenant or shared with tenant-scoped tools. A2A meshes follow the trust boundaries of their network. Queues can isolate by virtual host or topic. None of these options are wrong, but they differ. A tenancy model that works for one protocol often doesn’t fit all three. The constant factor is the database tenancy model. Row-level security, schema-per-tenant, and Oracle’s audit infrastructure remain relevant, regardless of which protocol is in vogue for the next roadmap.
The protocol layer can change. The governed memory layer should not.
Where This Is Heading
Three things are visibly changing in the agent communication layer right now, and one of them is not yet resolved.
Protocols are converging on capability cards. Both MCP’s tool schemas and A2A’s agent cards share a key idea: discoverable, typed descriptions of capabilities. These can be fetched at connection time instead of being hard-coded in client code. The two specifications came to this idea independently, suggesting it’s a fundamental concept. In the next two years, we can expect to see shared schema conventions across protocols. This may include cross-walks between MCP’s tools/list and A2A’s agent cards, or even a new specification that combines both. Teams using either spec now are not going against this convergence; they are ready for it.
Database-resident memory is becoming the default. In this article’s three patterns, the key constant is the memory layer, not the protocol. We see vector-typed columns, consistent transactions between agent writes and reads, and audit trails that endure even after framework updates. This marks a significant shift from the architecture of 2023 and early 2024. Back then, vector stores operated as separate sidecars, while agent memory was just a Python dictionary. Oracle AI Database showcases this trend. The larger pattern shows that durable agent state should exist in the same governed system that manages your data, not in a separate stack needing constant syncing.
The tool/agent boundary is dissolving, and the taxonomy in this article will eventually need to be rewritten.
An MCP server can wrap an LLM-powered backend, in which case calling it is functionally an agent invocation. An A2A agent can expose itself as an MCP tool, in which case it is being addressed as a capability rather than a peer. Both moves are legitimate, both are happening in production today, and the protocols themselves do not yet have an opinion on which framing is correct.
This is the open question. The matrix in this article tells you what each protocol is good at today, and the three patterns work today. But the line between here is a tool, call it and here is a peer, coordinate with it is genuinely blurring, and I do not think the industry has agreed yet on where it settles. The people I trust most on this question are the ones building both patterns in production and treating the distinction as an engineering choice rather than a protocol mandate. That is the right posture for the next eighteen months. The taxonomy will catch up to the practice, or it will not, and the architectural decisions you make this quarter should be robust to either outcome.
Frequently Asked Questions
Should I pick MCP or A2A for my first agent project? Almost certainly MCP. A2A addresses peer coordination, which many initial projects lack. Start with one model and a set of tools. Introduce A2A when you have a second agent that needs to work with the first on a task that lasts beyond a single request. Using A2A too early creates extra coordination without a clear need.
Do I need both MCP and A2A in the same system? Yes, often. The typical production shape is A2A between agents and MCP from each agent to its tools. This is because the two protocols operate at different layers and handle different tasks. A system requires both when it has real peer coordination and actual tool access. If you don’t have one of these, you don’t need the related protocol yet.
Can I migrate from REST to MCP without rewriting my services? Yes, that’s usually the cleanest adoption path. An MCP server acts as a thin wrapper over existing REST endpoints. It adds a typed tool schema and a discovery layer without altering your service code. The migration cost lies in the wrapper, not in the services. The services continue to serve their non-agent clients as before.
Does Oracle AI Database require Oracle-specific tooling for any of these patterns? No. All three patterns in this article use standard open-source Python libraries (oracledb, the mcp SDK, pika for RabbitMQ, FastAPI). Oracle AI Database participates through a connection string and a vector-typed column, not through a framework lock-in. Teams already running Oracle gain the option of collapsing the queue and the memory layer into a single component using Oracle Advanced Queuing, but it is an option, not a requirement.
What is the cheapest way to try this end-to-end? The companion repository ships a docker-compose.yml that stands up Oracle AI Database Free, RabbitMQ, and Ollama for local model inference. No paid API keys, no cloud accounts, no proprietary SDKs. The entire three-pattern demo runs on a developer laptop with roughly 16GB of RAM, and the Oracle AI Database Free edition supports up: 2 CPUs for foreground processes, 2GB of RAM (SGA and PGA combined), 12GB of user data on disk (irrespective of compression factor)
When is “just use a queue” the right answer? When the work is asynchronous, idempotent, and sensitive to throughput, the LLM acts as a worker, not an orchestrator. This applies to most backoffice tasks, like automation, batch embedding, document processing, and scheduled reporting. The key test is if a human needs the result in real time. If not, a queue is usually the best choice. MCP or REST should only be used at the edges, where the system interacts with a human or a synchronous external service.
