Key Takeaways
In this article, GraphRAG with Oracle AI Database 26ai refers to an architecture pattern. It combines Oracle AI Vector Search with graph-based relationship context from SQL property graphs; it is not used here as a standalone product name.
Knowledge graphs help when enterprise answers depend on relationships. Customers, contracts, products, policies, assets, documents, suppliers, employees, and events often matter because of how they connect, not just because of the words used to describe them.
Oracle AI Database 26ai can provide a database-centered foundation for GraphRAG-style architectures. Teams can combine vector search, SQL property graphs, relational data, JSON data, and SQL-oriented filtering in the same Oracle database environment.
A practical starting point is a minimum viable knowledge graph. Pick one domain, one AI use case, a few high-value entities and relationships, and expand only when new relationships improve retrieval quality.
A support engineer asks what sounds like a simple question:
Which replacement policy applies to this customer’s installed asset?
A basic retrieval-augmented generation, or RAG, system may find a policy document that mentions replacement parts. That helps, but it may not be enough. The answer may also depend on the customer’s contract, the asset’s product family, an active entitlement, a regional exception, and whether the policy is still in force.
That is where GraphRAG becomes useful. In this article, GraphRAG with Oracle AI Database 26ai means an enterprise AI architecture pattern that combines vector search with graph-based relationship context. Oracle AI Vector Search helps applications retrieve semantically similar content. SQL property graphs can model and query connected entities and relationship paths. If source identifiers and lineage properties are modeled, the application can also return provenance with the retrieved context. The application brings those retrieval signals together and sends a more structured evidence package to an LLM, AI assistant, search workflow, recommendation service, or agent.
Retrieval-augmented generation combines retrieval with generation so a model can use external evidence during response generation. GraphRAG-style systems commonly extend that idea by adding graph-derived context, such as entities, relationships, paths, graph neighborhoods, and source references, when those elements are modeled and retrievable. For conceptual background, see the original paper on retrieval-augmented generation and this survey of Graph Retrieval-Augmented Generation.
This article is for AI architects, application developers, data engineers, and platform teams who already understand the basics of RAG, vector embeddings, relational data, and access control. The examples are conceptual rather than executable setup instructions. They use Oracle AI Database 26ai capabilities such as Oracle AI Vector Search, SQL property graphs, relational data, JSON data, and SQL.
What GraphRAG Means in an Oracle AI Database Architecture
GraphRAG adds relationship-aware retrieval to a RAG workflow. Instead of retrieving only text chunks that are semantically similar to a question, a GraphRAG workflow can also retrieve the entities, relationships, paths, and source references that explain how information is connected.
Basic RAG usually starts with embeddings. An application embeds a user question, searches for similar document chunks or records, assembles the retrieved passages into a prompt, and sends that prompt to a large language model. That pattern works well when the answer is contained in a few semantically similar passages.
GraphRAG adds another retrieval signal: connected business context.
A knowledge graph represents entities and relationships in a domain so applications can query how people, products, policies, documents, assets, events, and processes are connected. In an enterprise AI system, those entities might be customers, contracts, assets, products, policies, service tickets, suppliers, documents, employees, projects, or events. The relationships between them are not decoration. They often determine whether a retrieved document actually applies.
In Oracle AI Database 26ai, SQL property graphs provide the graph side of this pattern. A SQL property graph can expose selected database objects as vertices and edges with properties, allowing teams to query relationships through SQL-oriented graph features. You can define SQL property graphs with CREATE PROPERTY GRAPH, and GRAPH_TABLE can be used in SQL to match graph patterns against a property graph.
Oracle AI Vector Search provides the semantic retrieval side. Vector search retrieves semantically similar content by comparing embeddings that represent the meaning of text, documents, images, or other data. In a GraphRAG system, those embeddings may represent document passages, case summaries, product descriptions, policy excerpts, tickets, or entity summaries. This article assumes embeddings already exist or are generated by an application or platform pipeline; it does not cover embedding-generation setup. For more on the core workflow, see the Oracle AI Vector Search overview.
The boundary is important. Oracle AI Database 26ai provides data and retrieval capabilities. The application or platform design decides how embedding generation, entity resolution, result fusion, prompt assembly, model calls, access-scoped context assembly, evaluation, and user experience are implemented. Some steps may use database features, while others belong in application or platform services.
Why Enterprise AI Systems Need Knowledge Graphs
Enterprise AI systems need knowledge graphs when the correct answer depends on relationships, not just relevant wording. A passage can look relevant and still be wrong for a specific customer, contract, product, region, asset, or effective date.
A policy paragraph may match a user’s question, but the AI system still needs to know whether the policy applies to the specific customer, asset, product, region, contract, entitlement, and date. A risk report may mention a supplier, but the business impact depends on which components, products, contracts, shipments, and customers are connected to that supplier.
For the support example, the retrieval problem might look like this:
Question:
Which replacement policy applies to this customer’s installed asset?
Vector search may retrieve:
- A policy document about replacement parts
- A support bulletin about the asset family
- A warranty exception note
Graph context can add:
- Customer -> Contract
- Contract -> Entitlement
- Customer -> Installed asset
- Installed asset -> Product
- Product -> Replacement part
- Product -> Applicable policy
- Policy -> Regional exception
Combined GraphRAG context:
The policy is relevant because this customer has an active contract,
the installed asset belongs to the product family covered by the policy,
and the entitlement is valid for the customer’s region.A vector-only step may find the policy. A graph step can help show why that policy may apply by retrieving the customer, asset, product, contract, entitlement, and exception relationships used by the application. The graph path supports retrieval and explanation; it does not by itself make the business or legal decision.
The same shape appears in many enterprise domains. A supplier risk workflow may need to follow supplier-to-component-to-product-to-order-to-customer relationships. A compliance workflow may need document-to-product-to-policy paths. A workforce planning workflow may need employee-to-skill-to-project-to-certification relationships.
The text still matters. But the relationships determine whether the text is useful, current, authorized, and applicable.
How Knowledge Graphs Improve RAG
Knowledge graphs can improve RAG in use cases where entity identity, relationship paths, graph neighborhoods, provenance, or business semantics change which evidence should be retrieved. Vector search can find content that is semantically similar to the question. Graph traversal can show which entities that content is connected to, and the application can use those paths to explain why the content may be relevant.
One practical Oracle-based GraphRAG workflow can follow this shape:
User question
-> Embed the question
-> Run vector search for related documents, chunks, or entity summaries
-> Resolve top results to graph vertices
-> Traverse the SQL property graph for connected entities and relationships
-> Apply authorization-aware SQL predicates, database controls, and application-level access checks for freshness, status, scope, and business rules
-> Assemble passages, graph paths, structured facts, and provenance
-> Send the evidence bundle to the LLM or AI agent
-> Return an answer with source referencesThis is a retrieval pattern, not executable setup code. Other systems may resolve entities first, traverse a graph first, or run graph and vector retrieval in parallel.
The first signal is semantic similarity. Oracle AI Vector Search can retrieve passages, records, or entity summaries that are close to the user’s question in embedding space. The workflow typically includes generating embeddings, storing them, and searching vectors for similarity. For more implementation context, see the Oracle AI Vector Search workflow.
The second signal is graph context. A SQL property graph can model the enterprise entities and relationships that matter to the use case. Graph queries can retrieve a customer’s contracts, a product’s applicable policies, an asset’s component dependencies, or a supplier’s affected products. Because GRAPH_TABLE returns graph-pattern matches in tabular form, teams can combine graph results with SQL queries, joins, and filters.
The third signal is structured filtering. Relational and JSON data often decide whether retrieved context is current, authorized, applicable, or in scope. A policy may be valid only in certain regions. A contract may be inactive. A document may be restricted. A product may be retired. In a GraphRAG application, JSON columns or documents can store flexible metadata such as document attributes, source-system references, workflow state, or access-related attributes, if the application design uses them that way. Oracle AI Database 26ai supports JSON data management alongside relational data; for details, see the Oracle JSON Developer’s Guide.
The output is an evidence bundle: retrieved passages, graph paths, structured facts, source identifiers, and provenance. The LLM still generates the final language, but it receives more useful context than a loose set of similar chunks.
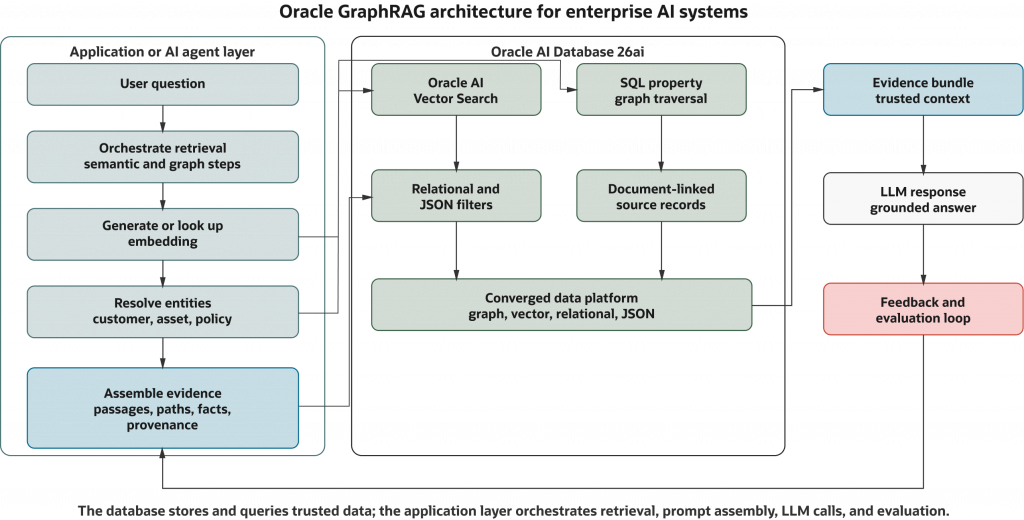
Figure 1. In a GraphRAG architecture with Oracle AI Database 26ai, applications can combine semantic retrieval with graph-based relationship context so enterprise AI systems can use both similar content and connected business data.
Oracle AI Database 26ai as the Data Foundation for GraphRAG
Oracle AI Database 26ai can support GraphRAG-style systems by bringing graph, vector, relational, JSON, and SQL-oriented workflows together in a database-centered architecture. That matters because a production GraphRAG system usually needs more than a vector index and a model call.
Vector data represents embeddings for documents, chunks, product descriptions, service cases, policy excerpts, or graph node summaries. Oracle AI Vector Search provides the vector storage, indexing, and similarity search capabilities used for semantic retrieval.
Graph data represents connected enterprise entities. SQL property graphs model vertices, edges, and properties over selected database objects. They are useful when the AI application needs relationship paths such as customer-to-contract-to-entitlement or asset-to-component-to-supplier.
Relational data represents operational facts: customers, products, contracts, service tickets, orders, assets, suppliers, financial records, employee records, and transaction history. SQL remains important because enterprise AI retrieval often needs joins, filters, dates, statuses, and business rules.
JSON data represents application payloads, flexible metadata, document attributes, event details, or semi-structured records. In GraphRAG applications, JSON can be useful for document metadata, source-system references, workflow state, and access-related attributes when those attributes are part of the application design.
Security and governance need to be designed across the full retrieval path. Treat vector results, graph traversal, and prompt assembly as part of the authorization boundary. A user should not receive restricted context simply because it is semantically similar or graph-connected to something the user can access. The Oracle AI Database Security Guide documents database security capabilities that can be used as part of protected data access designs. Those controls do not remove the need for application-level authorization logic: the retrieval service still has to pass the right user context, filter vector and graph results appropriately, and prevent unauthorized context from entering prompts or responses.
For data already managed in Oracle Database environments, teams can build GraphRAG workflows closer to operational records. Some architectures will still need document ingestion, embedding generation, entity extraction, derived graph structures, or synchronization from external sources. The practical goal is not to eliminate every data movement. The goal is to avoid unnecessary separation between AI retrieval and the enterprise data that gives retrieval its business meaning.
Where GraphRAG Helps in Enterprise AI
GraphRAG helps most when relationship context changes retrieval quality. If an application only needs to find a few relevant documents, vector or hybrid search may be enough. GraphRAG becomes more valuable when the answer depends on how customers, products, contracts, assets, policies, people, events, or documents are connected.
Semantic Search and Question Answering
For semantic search and question answering, GraphRAG helps when the system needs both relevant documents and business context. A support engineer might ask which policy applies to a replacement part for a customer’s installed asset. Vector search can retrieve policy passages, support notes, product manuals, or prior cases. Graph traversal can connect the customer to the asset, the asset to the product, the product to replacement parts, the customer to a contract, the contract to an entitlement, and the product to the applicable policy.
The application can then apply SQL predicates, database security controls, and application-level authorization logic so retrieved vector, graph, relational, and JSON context is scoped to the user and use case. Region, effective date, status, contract scope, and access rights all matter.
Knowledge Discovery
For knowledge discovery, GraphRAG helps teams find relationships across entities and documents. An operations team might ask which assets with recent failures are connected to suppliers under review. A SQL property graph can represent assets, components, suppliers, incidents, risk records, maintenance events, and products. Vector search can add relevant maintenance notes, supplier reports, or incident descriptions. Together, graph and vector retrieval can surface connected evidence that may be hard to find through document search alone.
Recommendations
For recommendations, GraphRAG is useful when similarity and business relationships both matter. A recommendation service might use vector search to find similar resolved cases, then use graph traversal to retrieve related products, experts, policies, documents, and outcomes. SQL predicates and application rules can apply availability, status, access scope, or other business constraints. Graph context is not necessary for every recommendation, but it helps when recommendations should reflect how the enterprise is actually connected.
Decision Support
For decision support, GraphRAG helps assemble connected evidence. A risk analyst might ask which open contracts could be affected by a supplier disruption. A compliance analyst might ask which policies apply to products in a region. A product leader might ask which customers are exposed to a component issue.
These questions require relationships among suppliers, components, products, contracts, customers, regions, policies, shipments, and events. For high-risk decisions, keep the system evidence-driven: source attribution, review workflows, access control, and evaluation should be part of the design.
AI Agents With Enterprise Context
AI agents can use GraphRAG as a retrieval tool or knowledge service when they need connected enterprise context before taking action. An agent may need to resolve an entity, retrieve a customer profile, find related assets, inspect policy context, or identify which documents support a recommendation. The practical design is simple: give the agent a retrieval service that returns evidence, provenance, and structured facts. Then let the application decide what actions are allowed and how results are evaluated.
GraphRAG is a candidate pattern for use cases such as semantic search, question answering, knowledge discovery, recommendations, decision support, compliance analysis, supplier risk, product support, customer service, and AI agents when relationships materially affect the retrieved evidence.
How to Start With a Minimum Viable Knowledge Graph
A minimum viable knowledge graph starts with one domain, one application goal, and a small set of high-value relationships. The starting point is not an enterprise-wide ontology program. The starting point is a retrieval problem worth solving.
For product support, the first graph might be small:
Minimum viable knowledge graph for product support
Domain:
- Product support
AI use case:
- Help support engineers find the policy that applies to a customer asset
Core entities:
- Customer
- Contract
- Entitlement
- Asset
- Product
- Policy
- Support document
High-value relationships:
- Customer has Contract
- Contract grants Entitlement
- Customer owns Asset
- Asset is instance of Product
- Product is governed by Policy
- Support document mentions Product
- Policy has Exception
First retrieval pattern:
- Use vector search to find relevant policies and support documents
- Use graph traversal to connect the customer, asset, product, contract, entitlement, and policy
- Apply structured filters for contract status, policy effective date, region, and access rights
- Assemble the retrieved passages and graph paths as context for the AI applicationThis first version is intentionally narrow. It has one domain, one AI-assisted workflow, a few entity types, a small set of relationships, and vector-searchable documents linked to graph entities. That is enough to test whether graph context improves retrieval for known support questions.
A practical adoption path is to choose a domain such as product support, policy compliance, asset maintenance, supplier risk, or customer service. Identify the entities that determine the answer. Identify the relationships that change retrieval outcomes. Map trusted structured data into graph vertices and edges. Link documents, policies, tickets, manuals, and notes to relevant entities. Store embeddings for semantic retrieval. Combine vector results with graph traversal. Review retrieval failures and expand the graph only when new relationships improve the use case.
This keeps the project grounded. A knowledge graph should grow because it makes retrieval, explanation, recommendation, or decision support better, not because a theoretical model says every relationship must be captured on day one.
Turn the Knowledge Graph Into a Reusable Service
A knowledge graph becomes more valuable when application teams expose it through reusable retrieval services, rather than trapping the logic inside one chatbot or retrieval script. Once the graph exists, multiple applications can reuse the same entity lookup, relationship traversal, provenance lookup, and context assembly patterns.
A search application may use entity lookup and graph-enriched retrieval. A recommendation service may use relationship traversal. A decision-support workflow may request paths, facts, and source references. An AI agent may call a knowledge service before summarizing a customer, recommending an action, or invoking a business tool.
A conceptual service contract might look like this:
Conceptual knowledge service: get_policy_context
Inputs:
- customer_id
- asset_id
- question
- user_context
Retrieval steps:
- Find semantically relevant policy and support passages
- Resolve the customer and asset to graph vertices
- Traverse related contracts, entitlements, products, policies, and exceptions
- Apply authorization-aware predicates, database controls, and application-level access checks
- Apply status, region, effective-date, and result-size filters
- Return only context the user is allowed to see
- Return passages, graph paths, source IDs, and provenance
Returns:
- Relevant text passages
- Relationship paths
- Applicable structured facts
- Source references
- Context ready for an AI assistant, search app, or support workflowThis is a conceptual service contract, not a built-in Oracle API. The point is architectural: GraphRAG should become a reusable retrieval capability. Application teams can implement it through SQL, application services, REST APIs, framework integrations, or internal platform services depending on their standards.
The key design habit is to return evidence. The service should return retrieved passages, graph paths, structured facts, source identifiers, and provenance. The calling application or agent then decides how to use that evidence, how to cite it, and what actions are allowed.
When Oracle AI Database 26ai Is a Strong Fit for GraphRAG
Oracle AI Database 26ai is a strong fit for teams that already manage important operational data in Oracle Database environments and need to combine vector search, SQL property graph traversal, relational records, JSON metadata, and SQL filters in one database-centered architecture.
Convergence matters because GraphRAG is not just “a vector store plus an LLM.” The retrieval layer needs embeddings for semantic search, graph relationships for connected context, relational records for operational facts, JSON for flexible application data and metadata, and SQL for filtering, joining, and applying business logic.
In organizations where customers, orders, contracts, assets, products, service records, or transactions already live in Oracle Database environments, GraphRAG workflows can be built closer to those operational records. For those datasets, a database-centered design can simplify the path from retrieval to business context because the semantic, graph, and structured signals can be assembled near the data that gives them meaning.
SQL accessibility also matters. SQL property graphs are especially relevant for SQL-oriented teams because graph patterns can be queried through SQL database workflows. A team can model connected entities as graph vertices and edges while still using SQL-oriented access patterns for retrieval and integration.
Operational fit matters because production AI systems inherit data-platform concerns. Access control, transaction boundaries, backup and recovery planning, availability, lifecycle management, and auditing still need explicit design when an LLM is introduced. Some of those concerns are handled in the database layer; others belong in the application, platform, or model-integration layer.
This is also why GraphRAG should be scoped carefully. If a use case only needs simple document Q&A, graph context may not be necessary. GraphRAG with Oracle AI Database 26ai is most valuable when the answer depends on connected business context and when the retrieval system must work with enterprise data that already has operational meaning.
Frequently Asked Questions
What is GraphRAG with Oracle AI Database 26ai?
GraphRAG with Oracle AI Database 26ai is an enterprise AI architecture pattern that combines vector search with graph-based relationship context. Oracle AI Vector Search helps retrieve semantically similar content, while SQL property graphs help applications model and query connected entities and relationship paths.
It is not a standalone product in this article. It is a pattern that uses Oracle AI Database 26ai capabilities to assemble better retrieval context for AI applications.
How is GraphRAG different from basic RAG?
Basic RAG commonly retrieves text chunks based on semantic similarity. GraphRAG also retrieves entities, relationships, paths, graph neighborhoods, and source references when those elements are modeled and retrievable.
The practical difference is applicability. A basic RAG workflow may find a policy document. A GraphRAG workflow can also retrieve the customer, contract, entitlement, product, and exception path that helps determine whether the policy applies.
What is a knowledge graph in enterprise AI?
A knowledge graph represents enterprise entities and their relationships so applications can query how information is connected. In enterprise AI, those entities might include customers, products, contracts, policies, assets, suppliers, documents, events, employees, and service records.
The value of the graph is not just storing entities. The value is making relationships available to retrieval workflows, search applications, recommendation services, decision-support tools, and AI agents.
What is a SQL property graph?
A SQL property graph models data as vertices and edges with properties. In Oracle AI Database 26ai, SQL property graphs can define graph structures over database objects and support SQL-oriented graph querying.
You can define SQL property graphs with CREATE PROPERTY GRAPH. GRAPH_TABLE can be used in SQL to match graph patterns against a property graph.
For reference, see CREATE PROPERTY GRAPH and the GRAPH_TABLE operator.
Does GraphRAG require moving enterprise data out of Oracle Database?
Not necessarily for data already managed in Oracle Database environments. Teams can build graph and vector retrieval workflows closer to that data.
Some architectures still require document ingestion, embedding generation, entity extraction, derived graph structures, or synchronization from external sources. The right design depends on where the source data lives, how often it changes, what access controls apply, and how the AI application will use the retrieved context.
What enterprise AI use cases fit GraphRAG?
GraphRAG fits use cases where answers depend on relationships among entities. Common examples include semantic search, question answering, knowledge discovery, recommendations, decision support, compliance analysis, supplier risk, product support, customer service, and AI agents that need enterprise context before taking action.
Graph context is most useful when it changes the retrieval result, explains why evidence applies, or helps enforce scope through structured facts such as status, region, effective date, contract, entitlement, or authorization.
How should teams start building a knowledge graph for AI?
Start with one domain and one use case. Define a small set of entities and relationships. Build a minimum viable knowledge graph. Add vector-searchable content. Combine semantic retrieval with graph traversal. Expand based on measured retrieval gaps.
A good first project might involve product support, policy compliance, asset maintenance, supplier risk, or customer service. The first graph should be small enough to validate and useful enough to matter.
Conclusion: From AI Demos to AI Systems
Enterprise AI is moving from isolated demos toward reusable systems that need relationship-aware context. Basic RAG can retrieve relevant passages, but many enterprise questions depend on how business entities are connected. GraphRAG adds that relationship layer.
GraphRAG with Oracle AI Database 26ai combines Oracle AI Vector Search, SQL property graphs, relational data, JSON data, and SQL-oriented workflows. Vector search finds semantically similar content. Graph traversal retrieves connected entities and paths. Structured predicates, database controls, and application-level checks help apply business rules, freshness, region, status, and authorization scope. The application assembles the evidence bundle and sends it to an LLM, AI assistant, search workflow, recommendation service, or agent.
The practical path is to start small. Choose one domain. Model the entities and relationships that affect retrieval. Link documents and records to those entities. Add vector search. Evaluate whether graph context improves the answers. Then expand the knowledge graph and expose it as reusable knowledge services.
That is the shift from AI demo to AI system: retrieval that is not only semantically similar, but also connected, scoped, explainable, and grounded in the business data that determines the answer.
