Data Warehousing in the real world
When we think about creating a new data mart we typically imagine creating a single environment into which we load our data set then run our queries. For many individuals and departmental teams this is all that is needed: a single instance of an autonomous data warehouse to meet all the required needs. In fact, if you look at the vast majority of our collateral you will see data flowing into a single data warehouse environment and then being connected to reporting tools such as Desktop Data Visualization and/or Oracle Analytics Cloud.
However, if we step up a level from working with a data mart or a departmental mart, to a more sophisticated, broader data warehouse that covers a multitude of subject areas then it’s likely that a single environment might not be sufficient.
When multiple data sets and multiple teams are involved in preparing and loading data into a data warehouse, querying data sets and building reports and dashboards then making any changes to the data warehouse can become a little tricky! Why? Because a lot of people and workflows can be affected by even a small change. Using a single data warehouse environment if one team asks for a new data source to be incorporated into the data warehouse then that data set will be immediately available and visible to everyone. Reports could be created right away against that data and then distributed across the organization. Now some will see this as a shining example of “agile” development.
But….
What if the first time we try to load a new data set there is a problem which to fix requires changes to the existing tables?
What if the first time we load the new data set some records get rejected because of errors in the data – maybe a number column has a row with characters as “N/A” – which essentially means we have missing rows in our data set, i.e. incomplete data?
What if a team wants to run some what-if type analysis that requires changes to the way data is structured and organized in the data warehouse but they don’t want anyone else to have access to those changes?
What if we want to allow a new team of business users to access the data warehouse so we can train them about how to use the new data sets and how to access the new reports?
Why you need cloning
Essentially what the majority of data warehouse teams need is a series of different environments that are separate from the main operational, or production, environment. Where additions, changes, updates can be done in isolation without impacting the “main” data warehouse. For example most data warehouse and enterprise data warehouse environments consist of the following environments: (in addition to operational/production instances):
Development instance(s) – where the technical team can build test new data sources, new reports etc
Test instance(s) – where the technical and business teams can check, validate new data sources, new reports etc
Training instance(s) – where the business teams can try out new data sources, new reports in isolation without impact the operational system etc
Sandbox instance(s) – where data scientists and data discovery teams can work in isolation on new “interesting” data sets
Until now, creating these non-operational/production environments has been challenging and time consuming process for the technical teams, especially the data warehouse DBAs! What everyone has been waiting for is a way to just “right-click” and deploy an exact copy of an existing data warehouse instance (obviously you can do this programmatically too using the Cloud command line APIs but that’s not the focus of this post) . Well the wait is over….
The new cloning feature of autonomous data warehouse comes to the rescue….in a few mouse clicks it is possible to make exact copies of your data warehouse, either including or excluding the actual data depending on your precise needs. Let’s see how this works…
How does cloning work?
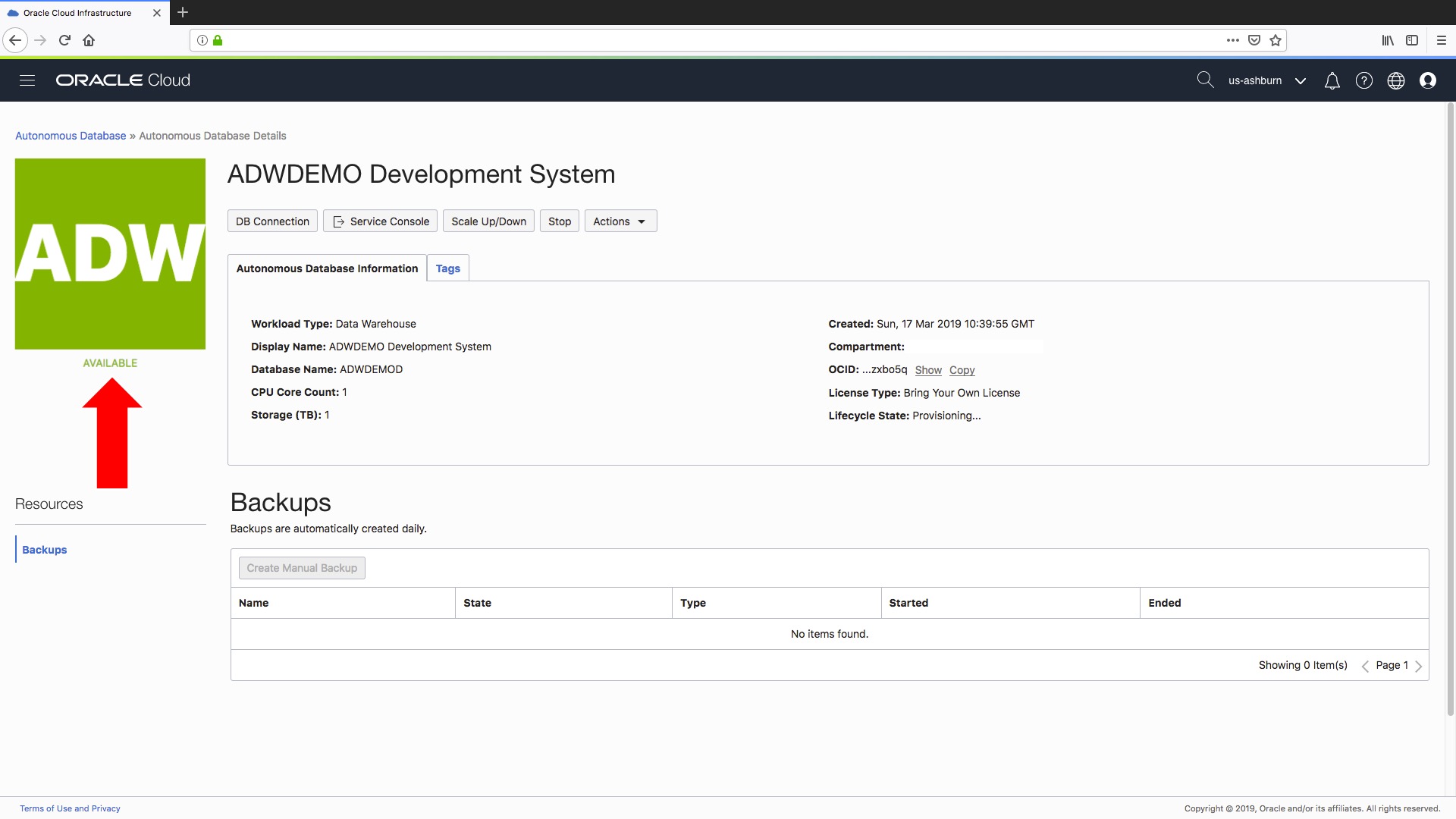
First step is to log in to your cloud console and go to your Autonomous Database overview screen, like the Autonomous Data Warehouse page as shown here:
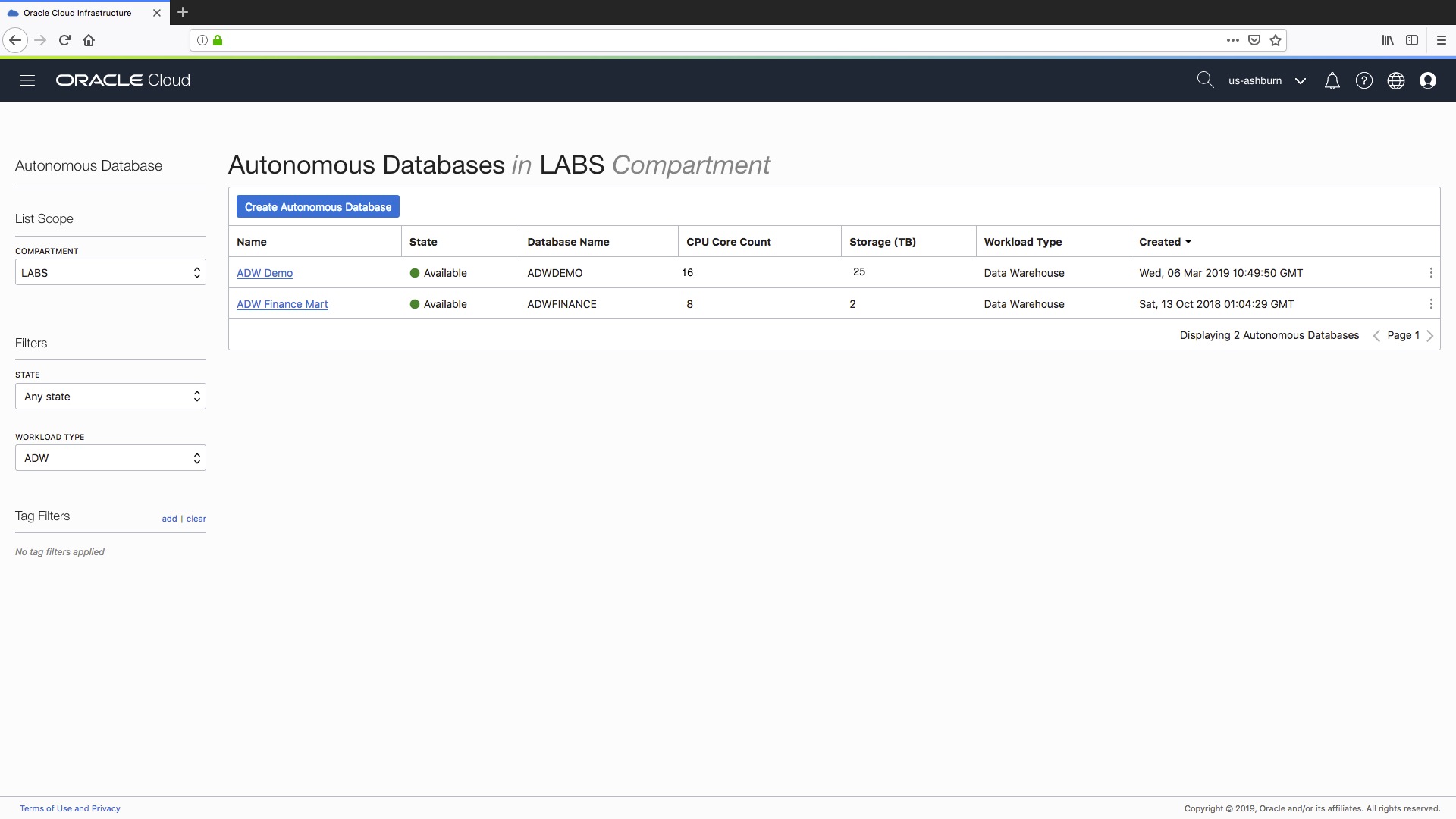
As you can see we have an existing Autonomous Data Warehouse called “ADW Demo”. Let’s assume that I want to create a new development instance of this data warehouse so my technical team can build and test some new ETL jobs for me. To do this I will use the new cloning feature to make a copy of my existing “ADW Demo” data warehouse. Here we go…
If you click on the little three vertical dots on the right hand side. In the pop-up menu there is a new menu option “Create Clone”, as shown here:
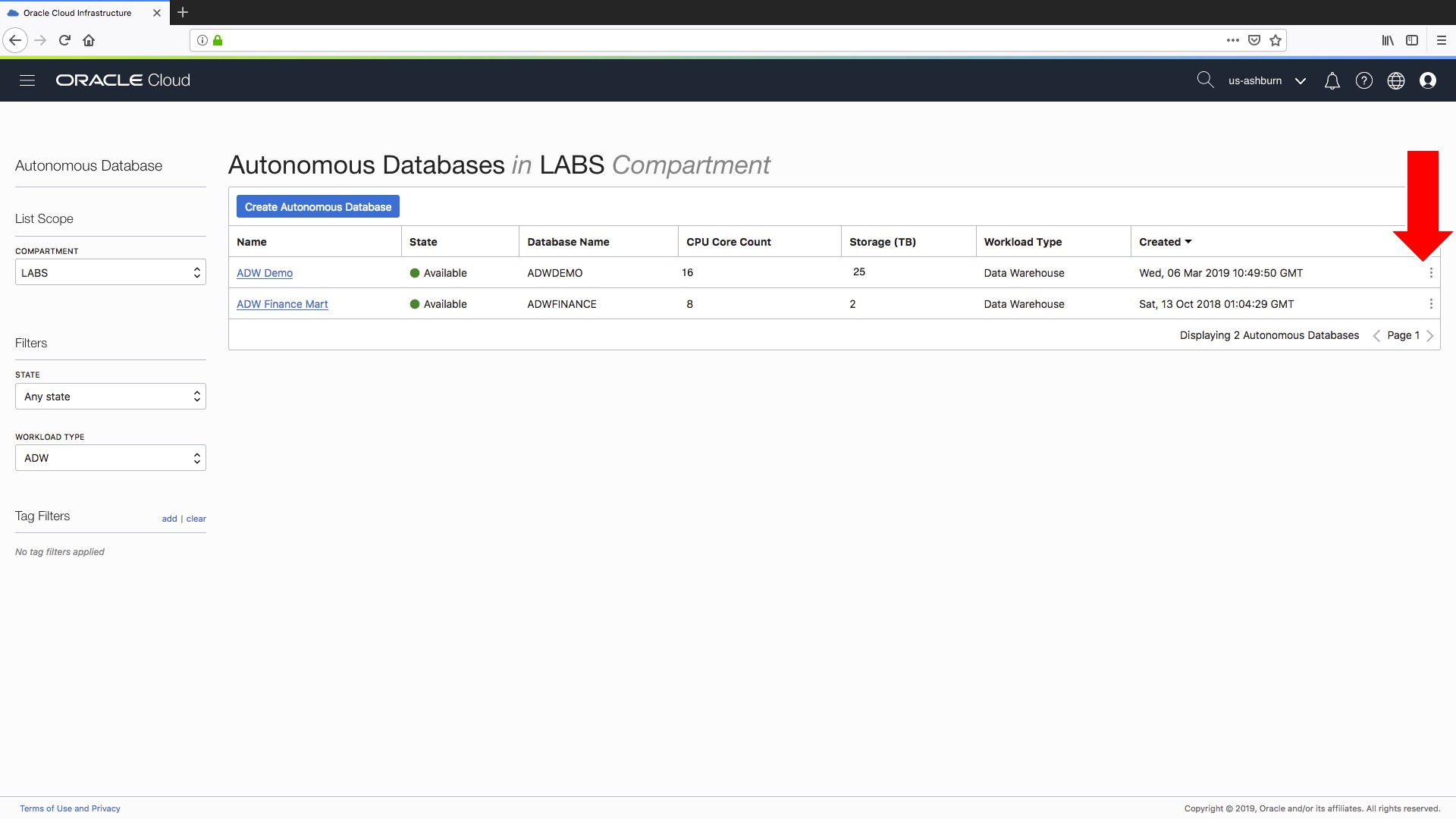
which gives you access to the “Create Clone” feature on the pop-up menu…
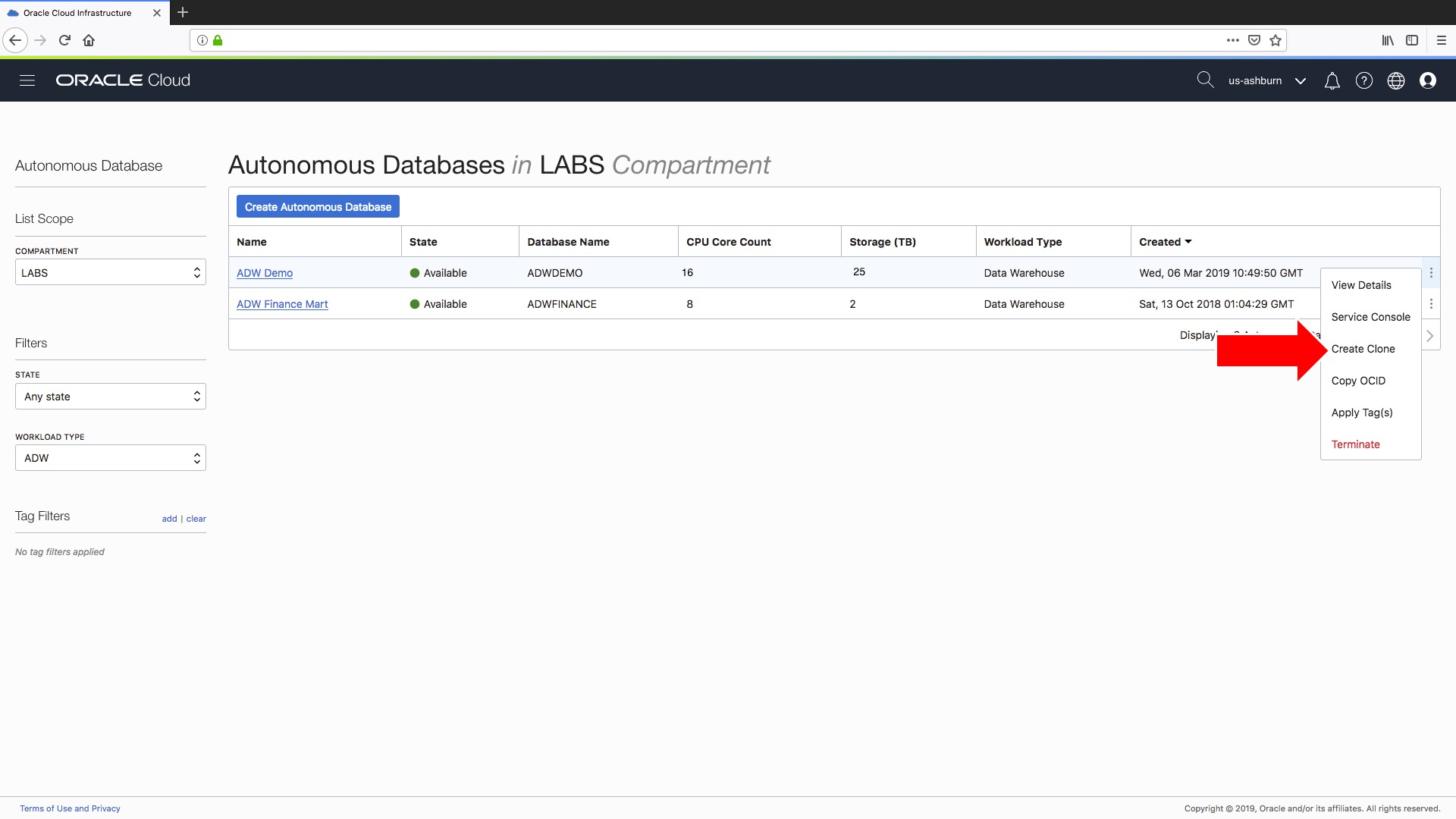
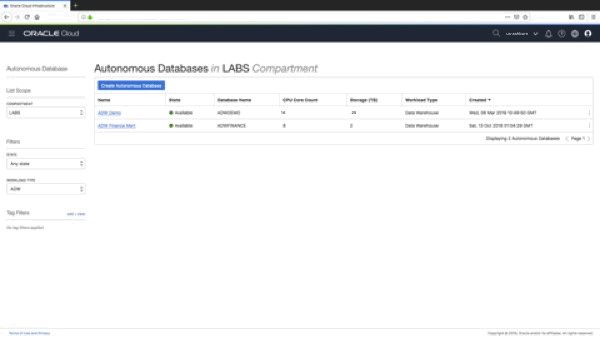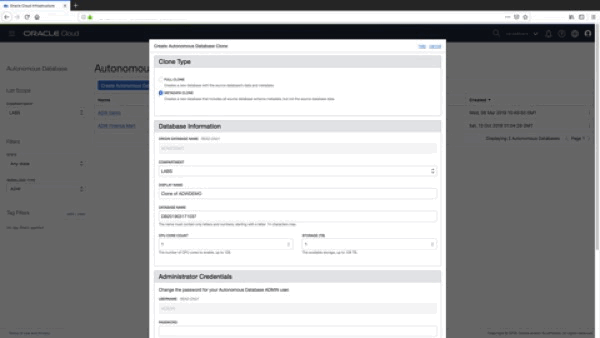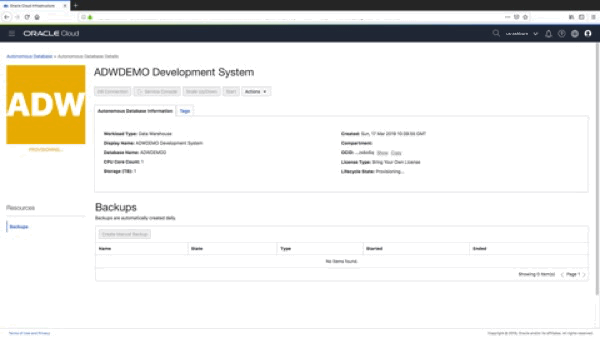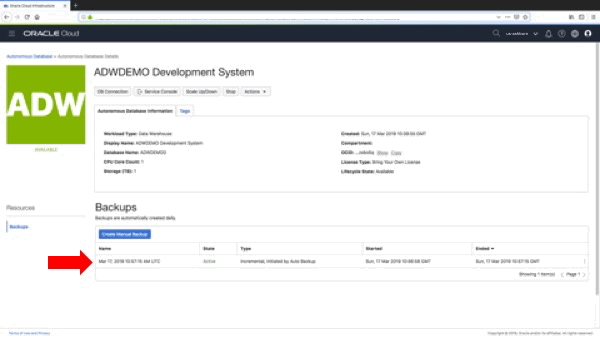
Step 1) Now up pops our familiar “Create Autonomous Database” form except this time it says ““Create Autonomous Database Clone” and the first decision we have to make is to determine the type of clone that we want to create! Fortunately, there are two simple options:
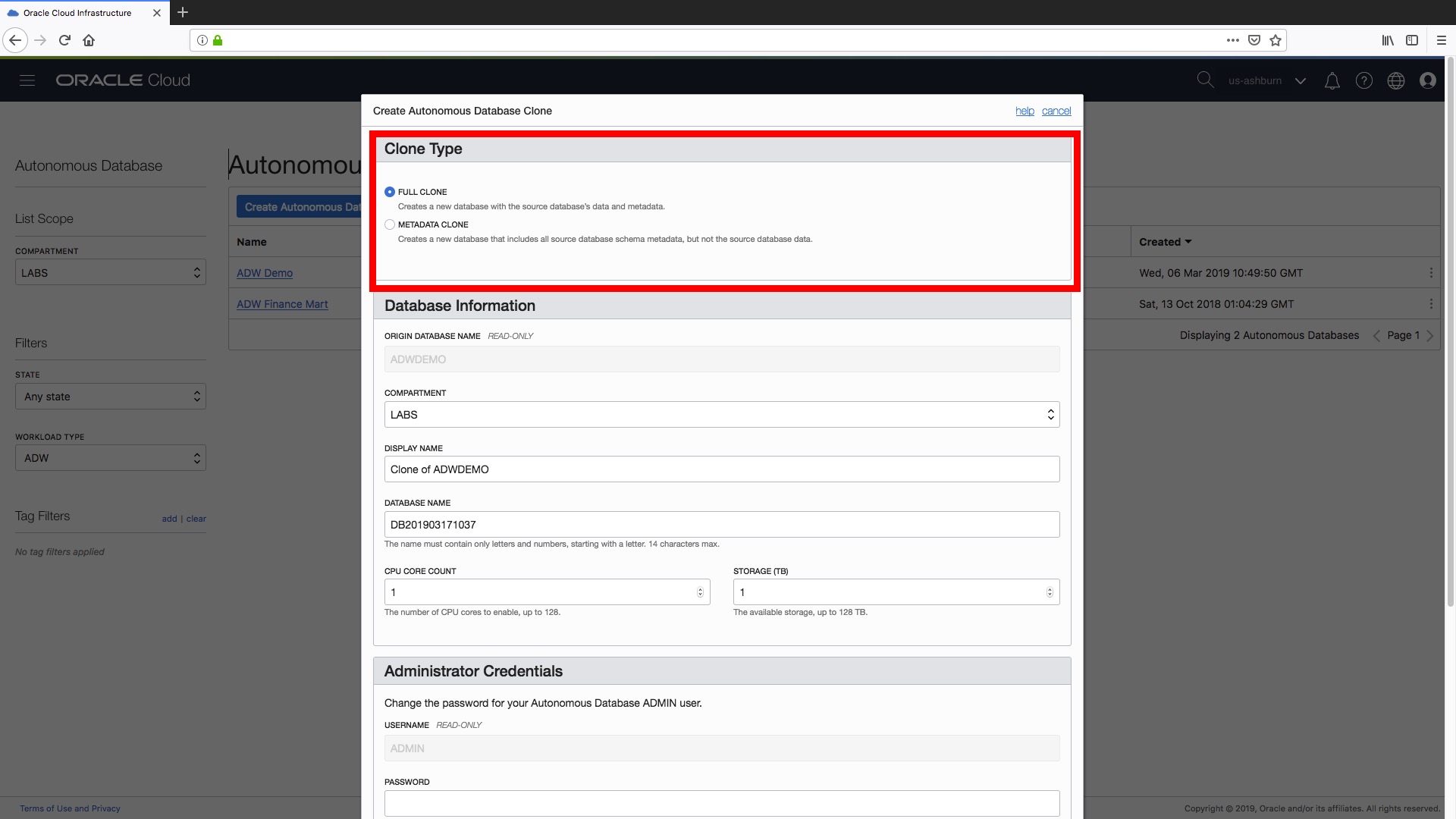
Full Clone – this creates a new data warehouse instance complete with all our data and metadata (i.e. the definition of all the data warehouse objects such as tables, views etc).
Metadata Clone – this creates a new data warehouse that contains only our source data warehouse’s metadata without the data (i.e. the new warehouse will only contain the definitions of our existing database objects such as tables, views etc).
In my experience I expect you will want to create “Full Clones” for QA-type and training-type environments since these will function best if they contain a realistic, i.e. as close to production as possible, data set. For development-type or testing-type instances a metadata-only clone is likely to be sufficient. Irrespective of the type of cloning, the following rules currently apply:
- If your existing data warehouse instance contains any Oracle Machine Learning workspaces, projects, and notebooks, those are not cloned to the new database. There is more information about how to export existing OML workbooks and notebooks here.
- Only one clone operation can be done at any current point in time. If there is an ongoing clone operation on a source database, you cannot initiate a new clone operation on the database being cloned until the ongoing operation completes.
- You can only clone an Autonomous Data Warehouse instance to the same tenancy and the same region as the source database
Step 2) We can change the compartment if we need to and there is more information about compartments and how to use them here. For example, you could have compartments setup for development, testing, QA, sandboxes as a way of organising, grouping your data warehouse instances. In this example let’s put this new “clone” in the same compartment as our “ADW Demo” instance:
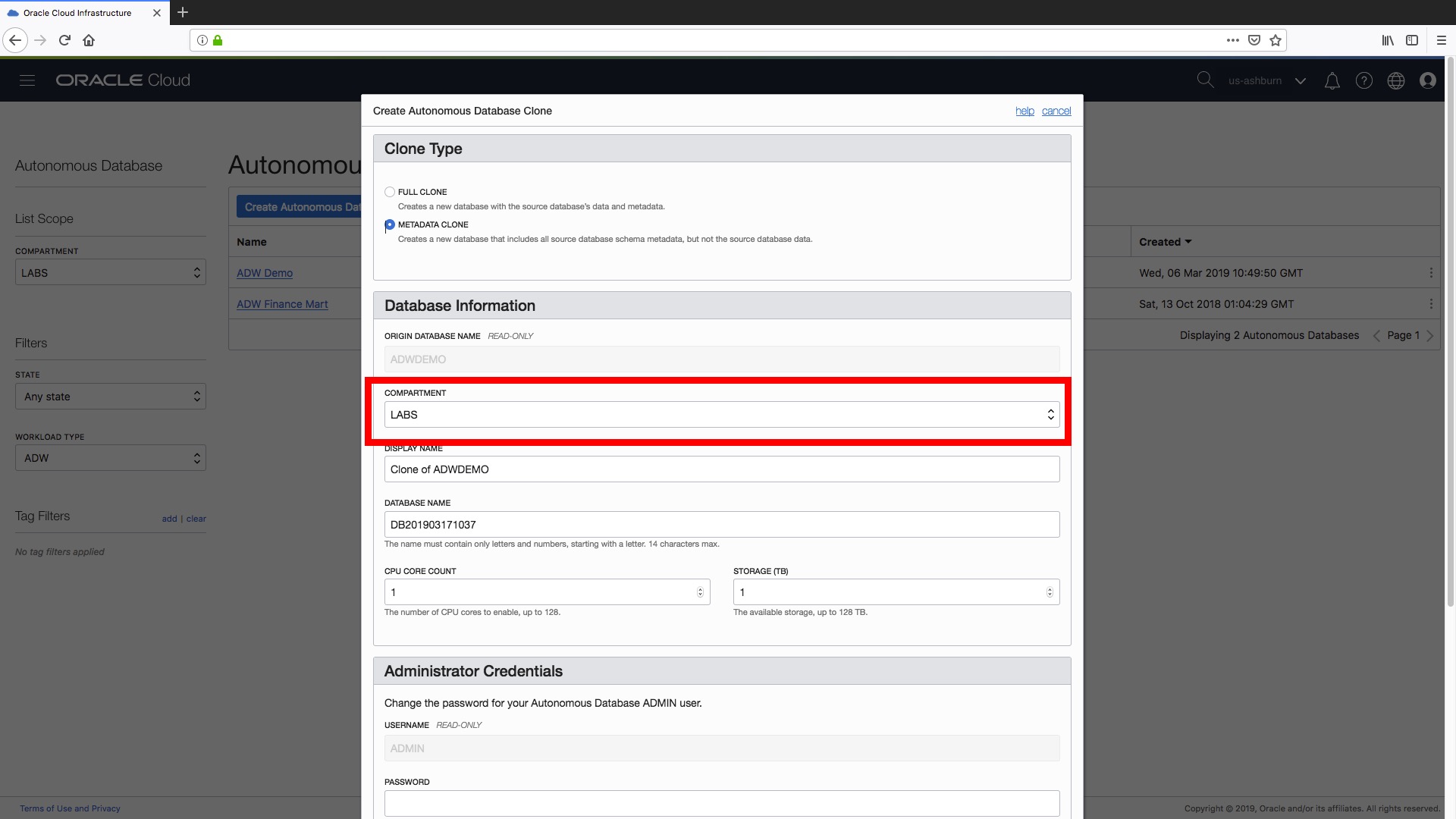
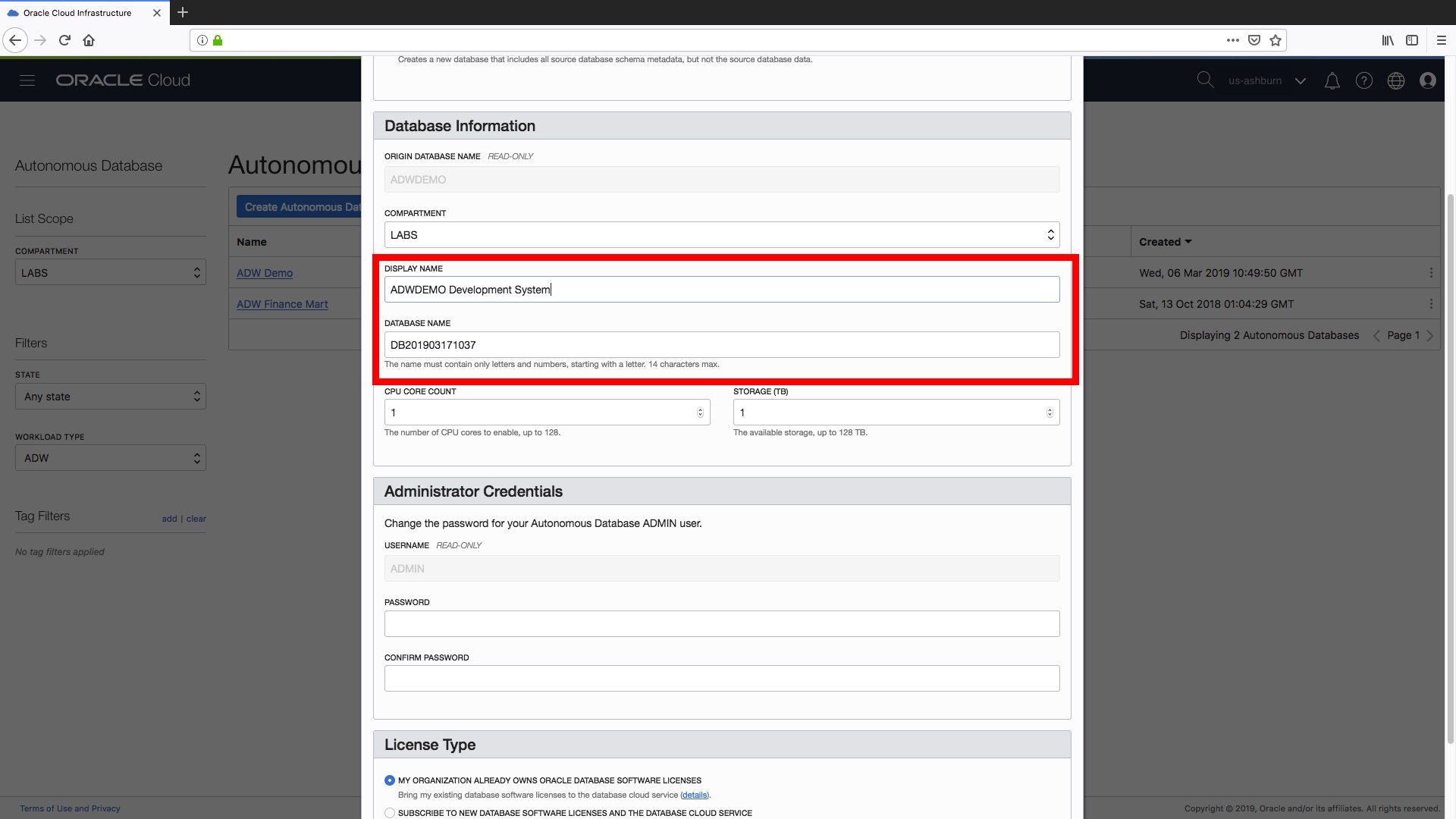
Step 3) Now we can set the Display Name and Database Name for our new data warehouse instance, as shown below. As of today, a clone does not keep any relationship to its source instance so it might be a good idea to have some sort of naming convention to identify development vs. testing vs. QA etc etc instances just to make your life easier in the long run!
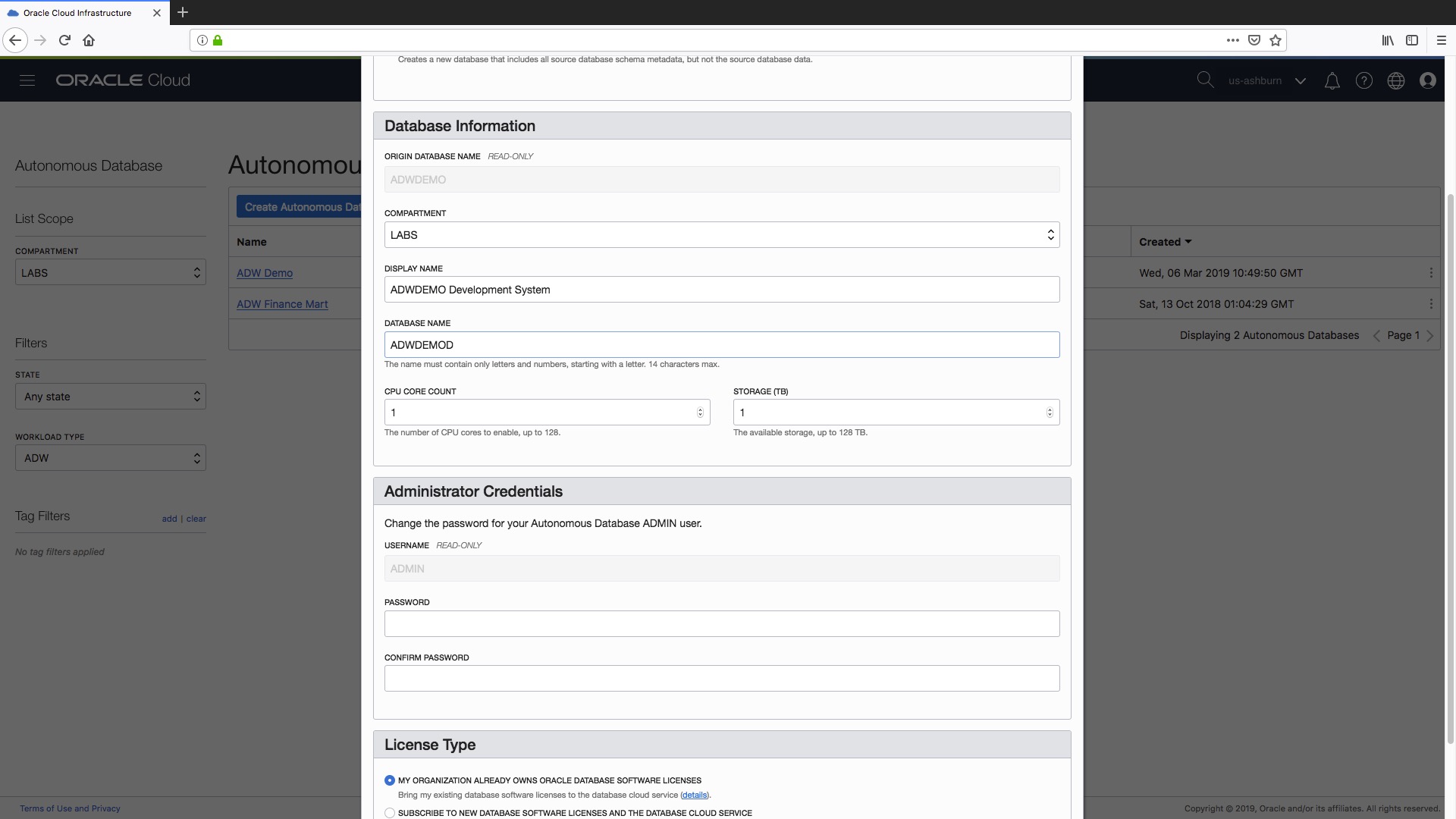
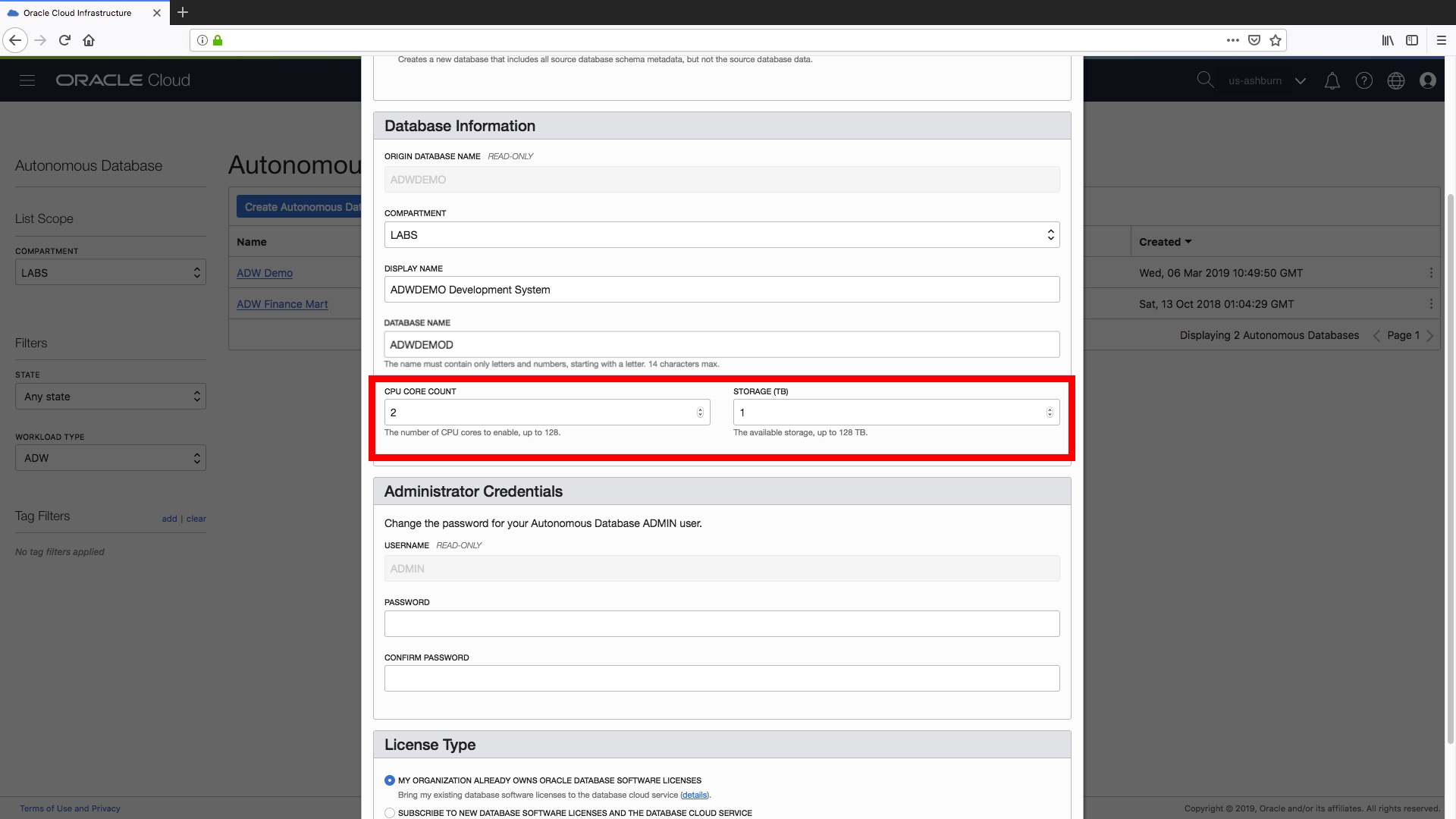
Step 4) Next step is to set our CPU and storage resources for our new “clone“, i.e. the number of cores and the amount of storage. Note that if you specify a “Full Clone” in Step 1 then obviously the minimum storage that you can specify here is the actual used space (rounded to the next TB) by your “source” data warehouse. The great thing here is that you can set the resources you need specifically for your clone. In this case our source data warehouse, “ADW Demo”, was configured with 8 OCPUs but as we are creating a “development” instance we can allocate fewer resources (i.e. just 1 OCPU).
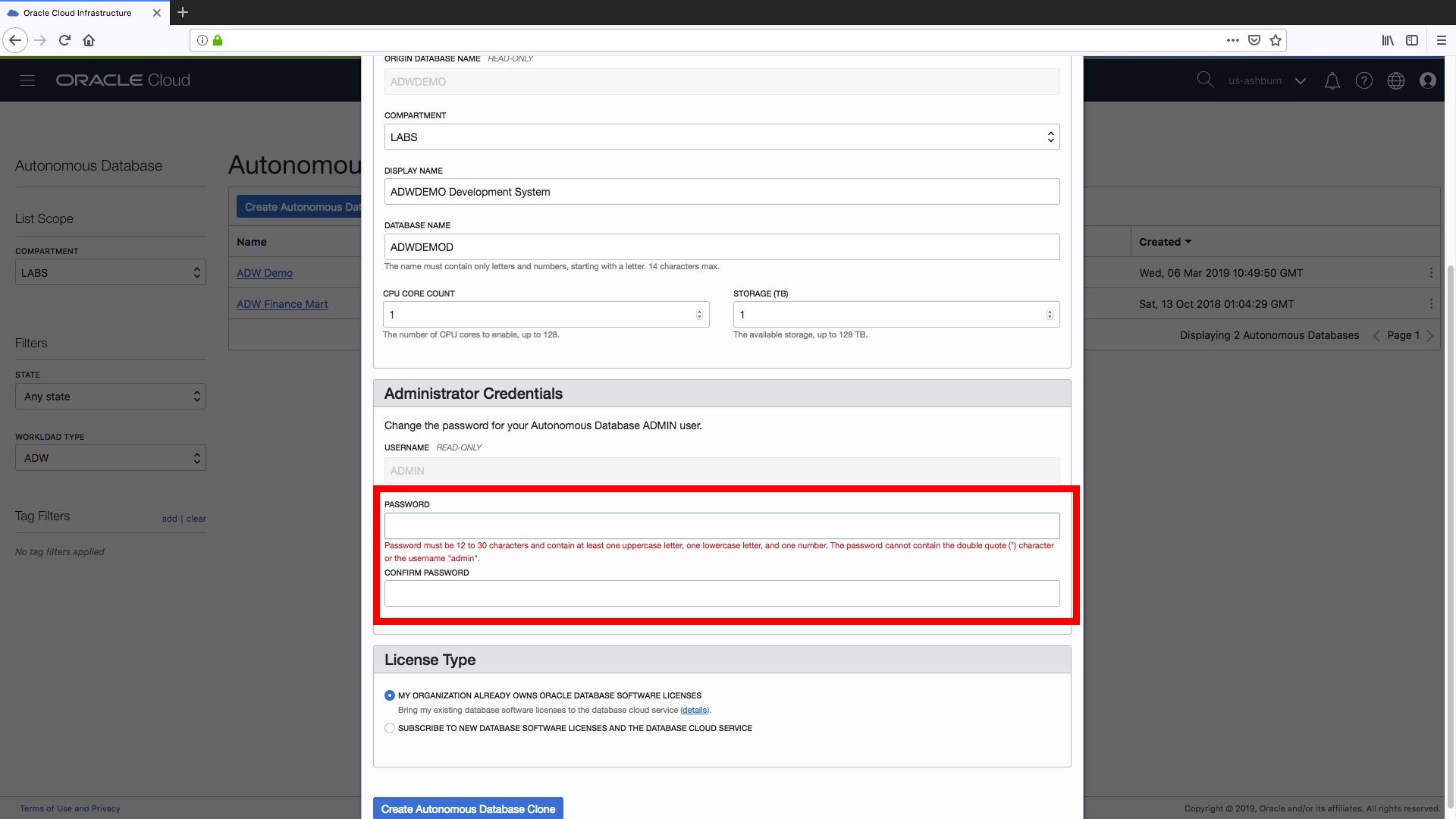
Step 5) You are required to set a new administrator password for your cloned data warehouse. All the usual password requirements apply here to ensure our new instance remains safe and secure:
- The database checks for the following requirements when you create or modify passwords:
- The password must be between 12 and 30 characters long and must include at least one uppercase letter, one lowercase letter, and one numeric character.
- Note, the password limit is shown as 60 characters in some help tooltip popups. Limit passwords to a maximum of 30 characters.
- The password cannot contain the username.
- The password cannot be one of the last four passwords used for the same username.
- The password cannot contain the double quote (“) character.
- The password must not be the same password that is set less than 24 hours ago.
here are the screenshots to show this process.…
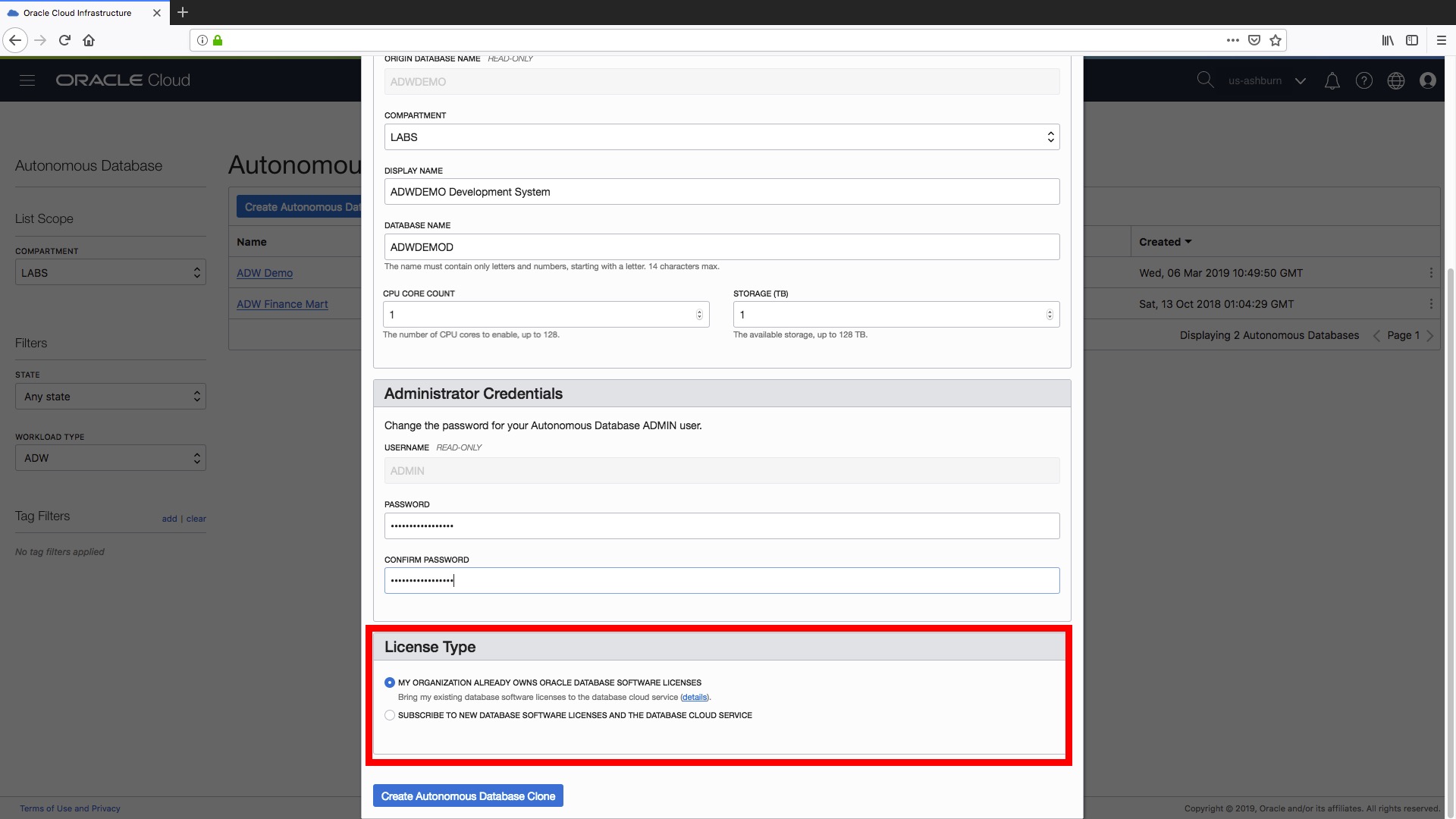
Step 6) The final step is to set the type of license we want to use for with our new data warehouse. The options are the same as for when you create a completely new data warehouse:
- Bring your existing database software licenses (see here for more details).
- Subscribe to new database software licenses and the database cloud service.
That’s it, we are all done! All we have to do is click the big blue “Create Autonomous Database Clone” at the bottom of the form to start the provisioning process.
….and in a couple of minutes our new data warehouse will be ready for use.
Let’s look at the whole process from start to finish….
Happy cloning
But we are not quite finished if you are part of a technical team reading this blog post because…
Now let’s go a little deeper…
If you are a technical user or a data warehouse DBA or a Cloud DBA then there a couple of additional areas that you will want to consider after creating your newly cloned data warehouse:
- What about all the optimizer statistics from my original data warehouse instance?
- What the resource rules within my newly cloned instance?
What about the Optimizer Statistics for your cloned data warehouse?
Essentially it doesn’t matter which type of clone you decide to create (Full Clone or a Metadata Clone) the optimizer statistics are copied from the source data warehouse to your newly cloned data warehouse. For for a Full Clone, where all the data from your source data warehouse is copied to your newly cloned instance you are ready to roll straight away! With a Metadata Clone, the first data load into a table will force the optimizer to update the statistics based on the new data load.
What about our resource management rules?
During the cloning process for your new data warehouse instance (Full Clone and Metadata Clone), any resource management rules in the source data warehouse that have been changed by the cloud DBA/administrator will be carried over to our newly cloned data warehouse. For more information on setting resource management rules, see Manage Runaway SQL Statements on Autonomous Data Warehouse.
Now you are totally ready to start cloning!
So, what happens next?
Now that your newly cloned data warehouse instance is available you are ready to start connecting your data warehouse and business intelligence tools. If you are new to connecting different tools to autonomous data warehouse then take a look at our guide to Connecting to Autonomous Data Warehouse.
