Oracle
SQL Developer and Data Modeler (version 4.0.3) now support Hive andOracle
Big Data SQL. The tools allow you to connect to Hive, use the
SQL Worksheet to query, create and alter Hive tables, and automatically generate Big Data SQL-enabled Oracle external tables that dynamically
access data sources defined in the Hive metastore.
Let’s take a look at what it takes to get started and then preview this
new capability.
Setting up Connections to Hive
The first thing you need to do is set up a JDBC connection to Hive.
Follow these steps to set up the connection:
Download and Unzip JDBC Drivers
Cloudera provides high performance JDBC drivers that are required for
connectivity:
- Download the Hive Drivers from the Cloudera
Downloads page to a local directory - Unzip the archive
unzip hive_jdbc_2.5.15.1040.zip- Three zip files are contained within the archive. Unzip the JDBC4
archive to a target directory that is accessible to SQL Developer (e.g. /home/oracle/jdbc below):
unzip Cloudera_HiveJDBC4_2.5.15.1040.zip -d /home/oracle/jdbc/
Note: you will get an error when attempting to open a Hive connection in SQL Developer if you use a different JDBC version. Ensure you use JDBC4 and not JDBC41.
Now that the JDBC drivers have been extracted, update SQL Developer to
use the new drivers.
Update SQL Developer to use the Cloudera Hive JDBC Drivers
Update the preferences in SQL Developer to leverage the new drivers:
- Start SQL Developer
- Go to Tools -> Preferences
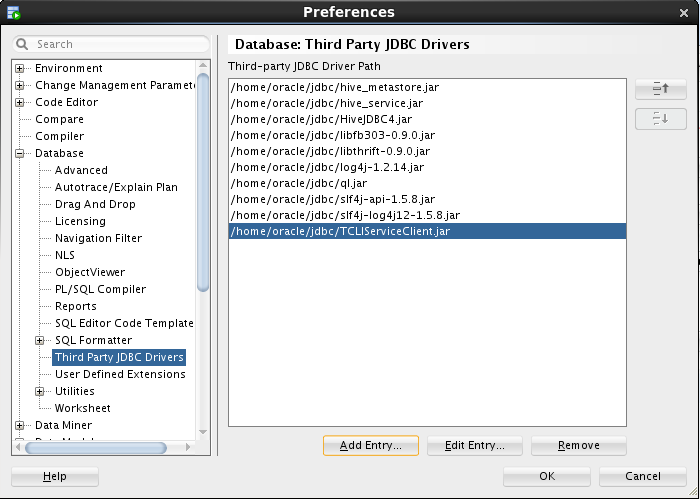
- Navigate to Database -> Third Party JDBC Drivers
- Add all of the jar files contained in the zip to the Third-party JDBC
Driver Path. It should look like the picture below:
- Restart SQL Developer
Create a Connection
Now that SQL Developer is configured to access Hive, let’s create a
connection to Hiveserver2. Click the New Connection button in the
SQL Developer toolbar. You’ll need to have an ID, password and the port where Hiveserver2 is running:
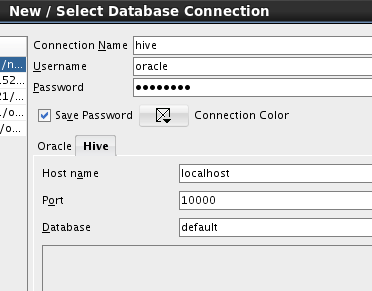
The example above is creating a connection called
hive which connects to
Hiveserver2 on
localhost running on port 10000. The Database field is
optional; here we are specifying the
default database.
Using the Hive Connection
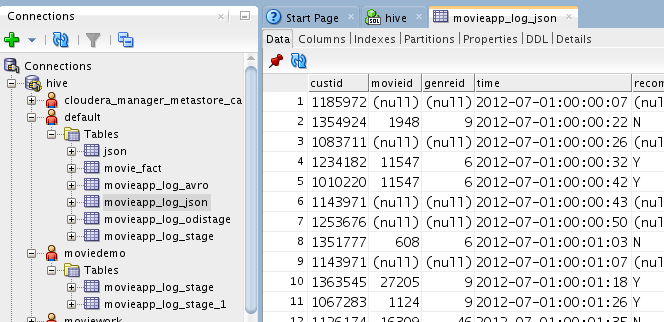
The Hive connection is now treated like any other connection in SQL
Developer. The tables are organized into Hive databases; you can review the tables’ data, properties, partitions, indexes, details and DDL:
And, you can use the SQL Worksheet to run custom queries, perform DDL
operations – whatever is supported in Hive:
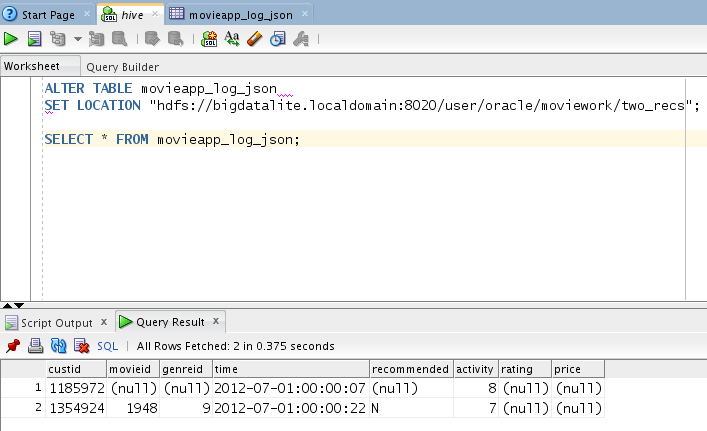
Here, we’ve altered the definition of a hive table and then queried that
table in the worksheet.
Create Big Data SQL-enabled Tables Using Oracle Data Modeler
Oracle Data Modeler automates the definition of Big Data SQL-enabled
external tables. Let’s create a few tables using the metadata from the Hive Metastore. Invoke the import wizard by selecting the File->Import->Data Modeler->Data Dictionary menu item. You
will see the same connections found in the SQL Developer connection navigator:
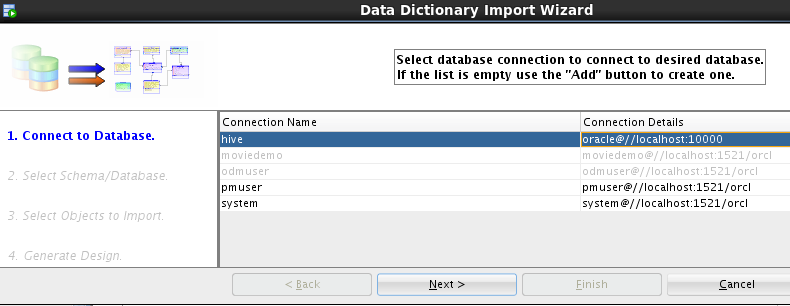
After selecting the hive connection and a database, select the tables to import:
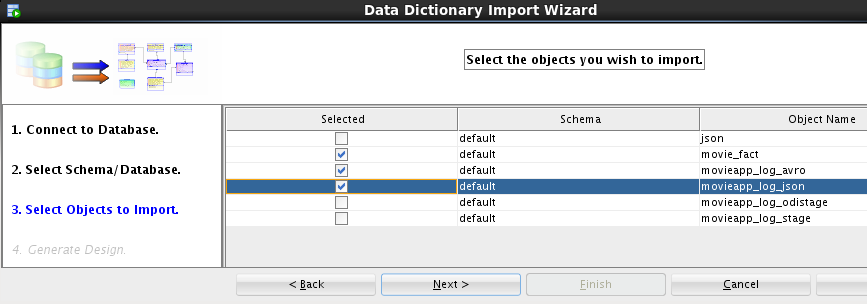
There could be any number of tables here – in our case we will select
three tables to import. After completing the import, the logical table definitions appear in our palette:
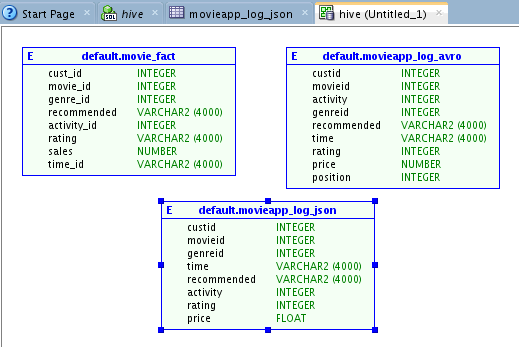
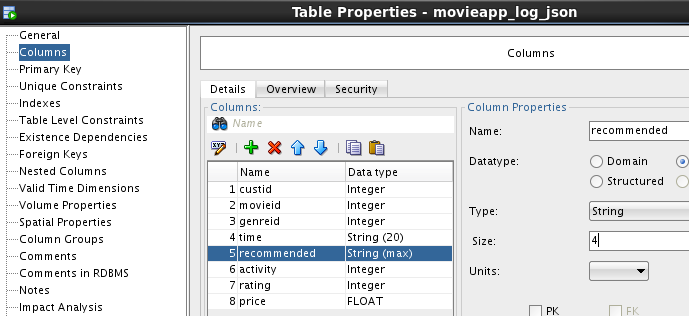
You can update the logical table definitions – and in our case we will
want to do so. For example, the recommended column in
Hive is defined as a string (i.e. there is no precision) – which the Data Modeler casts as a varchar2(4000). We have domain knowledge and understand
that this field is really much smaller – so we’ll update it to the
appropriate size:
Now that we’re comfortable with the table definitions, let’s generate the
DDL and create the tables in Oracle Database 12c. Use the Data Modeler DDL Preview to generate the DDL for those tables
– and then apply the definitions in the Oracle Database SQL Worksheet:
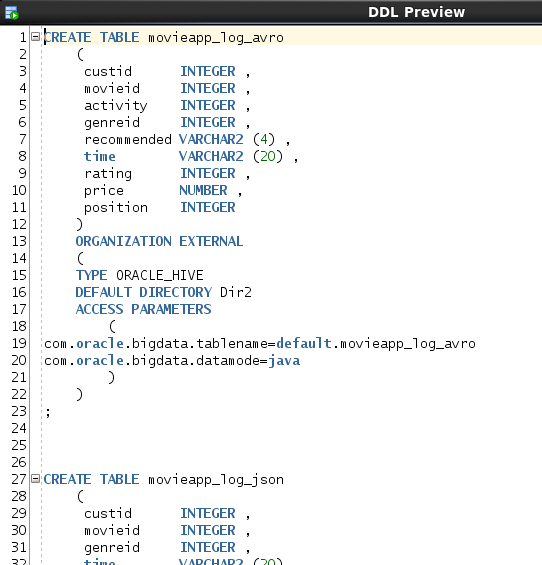
Edit the Table Definitions
The SQL Developer table editor has been updated so that it now
understands all of the properties
that control Big Data SQL external table processing. For example, edit table movieapp_log_json:

You can update the source cluster for the data, how invalid records should
be processed, how to map hive table columns to the corresponding Oracle table columns (if they don’t match), and much more.
Query All Your Data
You now have full Oracle SQL access to data across the platform. In
our example, we can combine data from Hadoop with data in our Oracle Database. The data in Hadoop can be in any format – Avro, json,
XML, csv – if there is a SerDe that can parse the data – then Big Data SQL can access it! Below, we’re combining click data from the JSON-based
movie application log with data in our Oracle Database tables to determine how the company’s customers rate blockbuster movies:
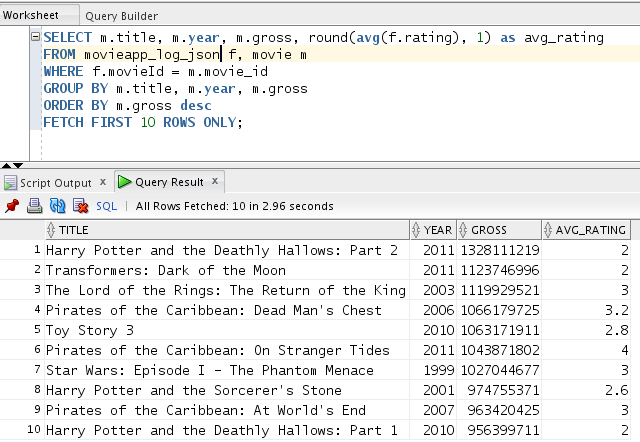
Looks like they don’t think too highly of them! Of course – the ratings data is fictitious 😉
