Attribute clustering is a feature that’s new to Oracle Database 12.1.0.2 (Enterprise Edition). It was designed to work with other features, such as compression, storage indexes, and especially with a new feature called zone maps, but since attribute clustering has some useful benefits of its own I’ll cover them here and make zone maps the subject of a
later post.
So what is attribute clustering? It is simply a table property – just like compression – but it defines how rows should be ordered and clustered together in close physical proximity, based on one or more column values. For example, in a sales transaction table you could choose to cluster together rows that share common customer ID values. Why would you consider doing this? Perhaps your system frequently queries sales data relating to particular customers, and perhaps there is a requirement for extremely fast and consistent response times (a call center CRM application would be a good example). Your physical database design will probably incorporate an index on the customer ID column already, but you can gain further benefit if sales table rows are physically near to one another when they share common customer IDs. The diagram below represents an index being scanned to find a particular customer, followed by some reads that fetch the corresponding sales table rows:
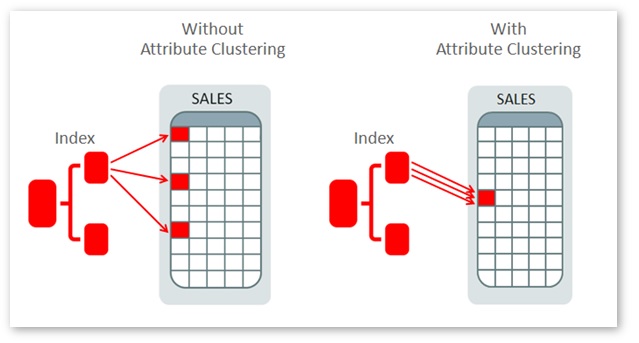
With attribute clustering, the matching sales table rows are near to one another, so it is likely that fewer database blocks will need to be read from storage (or database cache) than if the rows are scattered throughout the sales table. The reason for this is that database blocks will usually contain multiple rows, so it is beneficial if each block we read happens to contains multiple matching rows. Technically, attribute clustering improves index clustering factors, an important metric with regards to the efficiency of scanning indexes and fetching the corresponding table rows.
Many DBAs have used a similar trick in the past by ordering rows as they are loaded into the database (using an explicit SQL “ORDER BY” clause). Attribute clustering has the advantage of being transparent and a property of the table itself; clustering behavior is inherited from the table definition and is implemented automatically. Just like compression, attribute clustering is a directive that transparently kicks in for certain operations, namely direct path insertion or data movement. This is especially useful because row clustering will occur during table and partition movement as well as during data load.
It’s pretty common for database systems to order rows on data load or data movement to improve table compression ratios. Attribute clustering can be used instead to achieve a similar result.
The name, “attribute clustering” might remind you of another database feature called Oracle Table Clusters, but be careful not to confuse the two. Oracle Table Clusters store rows from one or multiple tables in close proximity inside a specialized storage structure. Attribute clustering simply orders rows within a table (or its partitions and subpartitions); related rows will be physically close to one another, but they will not be held inside any new type of storage structure that’s specific to attribute clustering.
Although attribute clustering is especially useful in conjunction with zone maps, it can be used as a transparent, declarative way to cluster or order table rows in order to improve:
- Index range scan performance.
- Table compression ratios (including for Oracle Database In-Memory).
- Smart scan filtering on Exadata and the In-Memory column store through more efficient storage indexes.
Here’s an example of using attribute clustering to speed up a query. We’ll compare before and after; so start by creating a table that is not attribute clustered:
CREATE TABLE sales_ac (sale_id NUMBER(10), customer_id NUMBER(10)); INSERT INTO sales_ac SELECT ROWNUM, MOD(ROWNUM,1000) FROM dual CONNECT BY LEVEL <= 100000; EXEC dbms_stats.gather_table_stats(ownname=>NULL, tabname=>'SALES_AC'); CREATE INDEX sales_ac_cix ON sales_ac (customer_id); SET AUTOTRACE ON STATISTIC
Our table is not very large, so I’ve included a hint in the test query to encourage the optimizer to use the index:
SELECT /*+ INDEX(sales_ac sales_ac_cix) */ COUNT(DISTINCT sale_id) FROM sales_ac WHERE customer_id = 50;
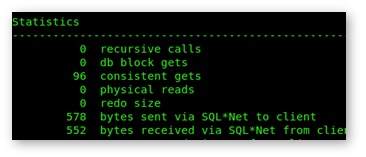
Run the query a few times, and see what the reported value for “consistent gets” settles at. I get 96, but since the value depends on some storage defaults, don’t be surprised if your value is different:
Attribute clustering is a property of the table, so when it is added, existing rows are not re-ordered. The following command is very fast because it just makes a change to the data dictionary:
ALTER TABLE sales_ac ADD CLUSTERING BY LINEAR ORDER (customer_id) WITHOUT MATERIALIZED ZONEMAP;
Now we can physically cluster the existing table data by moving the table:
ALTER TABLE sales_ac MOVE;
Moving tables and partitions is much cleaner and simpler than the manual “ORDER BY” method, where we would have to create a new table, add indexes, drop the old table and then rename. The simpler MOVE approach is particularly relevant in real-world scenarios, where it would be more usual to move tables a partition or sub-partition at a time, potentially using on-line operations.
Rebuild the index:
ALTER INDEX sales_ac_cix REBUILD;
Use the same test query:
SELECT /*+ INDEX(sales_ac sales_ac_cix) */ COUNT(DISTINCT sale_id) FROM sales_ac WHERE customer_id = 50;
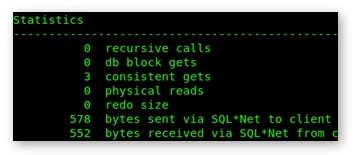
Again, run it a number of times to settle the reported value for “consistent gets”. In my case, I now read 3 database blocks instead of 96: a considerable improvement!
Full details on zone maps and attribute clustering can be found in the Oracle documentation, particularly the Oracle 12c Data Warehousing Guide.
The zone maps blog post includes some more on attribute clustering, plus links to a bunch of scripts for you to try out.
