Most of you will be familiar with partition pruning, where the Oracle Database will avoid the need to scan table and index partitions based on query predicates. This optimization is transparent to your application, but for it to work, the database has to find a way of mapping a query filter predicate to the partitioning key column (or columns). Partition pruning can only occur if the query has predicates that match the predetermined shape of a partitioned object. For example, a query on a SALES table partitioned by ORDER_DATE will need to include ORDER_DATE in a join or WHERE clause for it to be optimized by partition pruning.
What if you could do better than this? What if you could prune partitions using a variety of column predicates and dimension hierarchies, irrespective of their appearance in the partitioning key? How about pruning at a much finer level of granularity than a partition? Perhaps we want to optimize queries that filter SALES by SHIP_DATE, STATE and COUNTY, as well as ORDER_DATE. The new Oracle 12.1.0.2 zone map feature is designed to achieve this, and just like partitioning, zone maps are transparent to your queries; you don’t have to change your applications to make use of them.
Zone maps are available in Oracle Database 12c for Oracle Engineered Systems. Conceptually, they divide a table up into contiguous regions of blocks called zones (the default zone size being 1024 blocks). For each zone, the Oracle database records the minimum and maximum values for specified columns using a new database object called a zone map. Queries that filter on zone map columns have the potential to be optimized; it’s possible to prune zones that contain ranges of column values outside the match specified in the query predicate.
Consider a query that filters a sales table by (North American) state; in this case “CA”. A zone map on the STATE column will record the minimum and maximum values for this column for each zone in the table. This makes it possible to skip the zones that we can be certain won’t contain rows for “CA”.
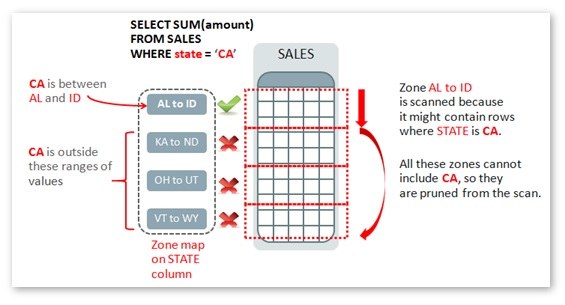
You are probably aware that Exadata storage cells and the Oracle database In-Memory Column Store uses similar storage index techniques, so what benefits do zone maps add? Besides the fact that you can control zone maps explicitly, the most significant difference between zone maps and storage indexes is that zone maps can be used to prune zones using column predicates from multiple (joined) tables. Consider a more realistic scenario, in which the SALES table doesn’t have a STATE column, but instead has a LOCATION_ID referencing a dimension table called LOCATIONS. This is our query for summing the sales figures in California:
SELECT SUM(amount) FROM sales s, locations l WHERE s.location_id = l.location_id AND l.state = 'CA';
It would be great if we could avoid scanning zones in SALES that don’t contain rows associated with “CA”. Before we look at how we can do this, we’ll make the scenario even more realistic by assuming that LOCATIONS is a dimensional hierarchy of State and County, like this:
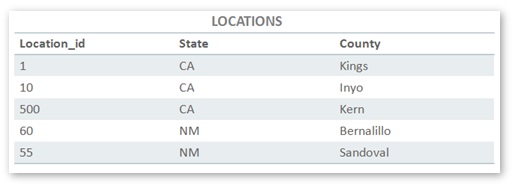
Each State is made up of multiple Counties, so “CA” will be associated with multiple LOCATION_ID values. If we want the “CA” rows in SALES, we’ll need to match the ones marked below in bold/red:
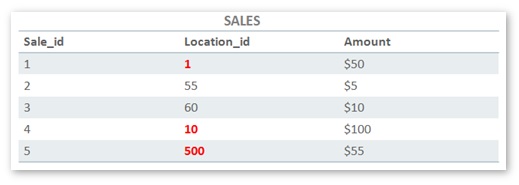
If we want to optimize a scan for “CA” rows, we will have to address a few issues:
- The SALES table does not have a STATE column, so no storage index structure on SALESs data will allow us to directly prune disk regions based on “CA”.
- Table rows associated with “CA” are likely to be physically scattered throughout the SALES table, so it’s unlikely that these rows will be confined to a relatively small number of zones or disk regions. We might not be able to make efficient use of an Exadata storage index on SALES.LOCATION_ID, if any (note that I am consciously ignoring the push down of BLOOM FILTERs to Exadata here, which still suffers from the physical scattering).
- A SALES storage index based on min/max Location ID is likely to be less efficient than using zones based on min/max State values, simply because each State is made up of multiple Location IDs. This inefficiency is more pronounced if Location IDs for “CA” are not numerically close to one another – it will reduce the chances that the Location IDs we’re searching for will be found within the same min/max Location ID regions.
Of course, zone maps are designed to address these issues – with a little bit of help from another Oracle Database 12c feature called attribute clustering. I introduced attribute clustering in an earlier post, but don’t worry if you haven’t read that yet; I’ll cover the basics here anyway. You’ve probably deduced that we can reduce the number of zones that contain “CA” rows if we cluster or sort the rows in SALES, keeping these rows close to one another, like this:
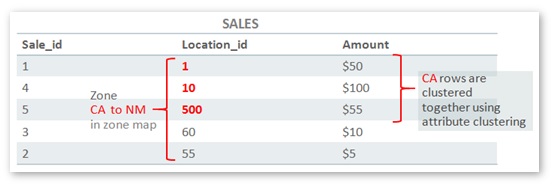
Attribute clustering is the feature that’s used to cluster the rows together. Zone maps are used to record the min/max values for specified columns for each zone (and this can include column values derived from joins; LOCATIONS.STATE and LOCATIONS.COUNTY in our case).
The following DDL will create a zone map on our SALES fact table using the dimension table columns LOCATIONS.STATE and LOCATIONS.COUNTY. It will also enable attribute clustering, using the same columns to cluster the table’s rows:
ALTER TABLE sales ADD CLUSTERING sales JOIN locations ON (sales_ac.location_id = locations.location_id) BY LINEAR ORDER (locations.state, locations.county) WITH MATERIALIZED ZONEMAP;
The LINEAR ORDER clause specifies a linear clustering algorithm, which is ideal for this example. Another algorithm is available; it is specified with “INTERLEAVED” and is optimized for more complex combinations of query predicates and dimension tables. Note that the definition of attribute clustering by itself does not change any data stored on disk; instead, it provides a directive for direct path operations; INSERT APPEND and MOVE that will physically perform the clustering operation for us. If there are pre-existing rows in SALES, we can MOVE the table (or its partitions) to re-order them.
Joins between SALES and the dimension table are now candidates for optimization when the query includes predicates on the dimension hierarchy “state” and “state, county”. For example:
SELECT SUM(amount) FROM sales JOIN locations ON (sales.location_id = locations.location_id) WHERE locations.state = 'NM'; SELECT SUM(amount) FROM sales JOIN locations ON (sales.location_id = locations.location_id) WHERE locations.state = 'CA' AND locations.county = 'Kern';
By clustering the rows and recording appropriate min/max column values for our zones, we have addressed all of the issues I identified above. What’s more, we can still get benefit from Exadata storage indexes because zone maps and storage indexes complement one another, and they work together transparently.
Zone maps are explicitly created and controlled by the database administrator on a table-by-table basis. They are an inherent part of the physical database design and can be thought of as a coarse anti-index structure (unlike an index, a zone map tells you what zones not to access). Zone maps are very compact, and in some cases it is possible to use them where you would otherwise use an index. This is most relevant in data warehousing environments where scanning is often more appropriate than indexed row retrieval, and where indexes can use a considerable amount of storage space. Zone maps must be refreshed to be synchronized with the underlying table data, so you will need to give some consideration to how you want them to be kept up-to-date if you decide to use them as an alternative to indexes.
In summary, take a look at zone maps if you want to:
- Optimize scanning queries, particular when joining with one or more tables.
- Reduce your dependency on indexes, particularly in data warehousing environments.
- Improve performance in your data warehouse; particularly for star or snowflake schemas.
Here’s an example of using zone maps to optimize a table scan. To compare before and after, start by creating a table that has no zone map or attribute clustering:
CREATE TABLE sales_zm (sale_id NUMBER(10), customer_id NUMBER(10));
Insert 8 million rows with the following PL/SQL code. Why that many? With our example, we’ll read one or two zones rather than the entire table, so I’m aiming to make the difference pretty obvious when you look at the block read statistics:
DECLARE i NUMBER(10); BEGIN FOR i IN 1..80 LOOP INSERT INTO sales_zm SELECT ROWNUM, MOD(ROWNUM,1000) FROM dual CONNECT BY LEVEL <= 100000; COMMIT; END LOOP; END; EXEC dbms_stats.gather_table_stats(ownname=>NULL, tabname=>'SALES_ZM'); SET AUTOTRACE ON STATISTIC
Run the following query a few times to see what value “consistent gets” settles at:
SELECT COUNT(DISTINCT sale_id) FROM sales_zm WHERE customer_id = 50;
On my machine, I read 7,545 blocks from the buffer cache, but since the value depends on some storage defaults don’t be surprised if your value is different:
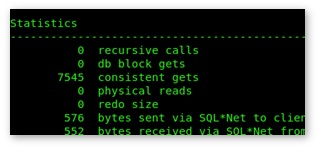
The following DDL will create a zone map, but since attribute clustering is a property of the table (like compression), any existing rows will not be re-ordered:
ALTER TABLE sales_zm ADD CLUSTERING BY LINEAR ORDER (customer_id) WITH MATERIALIZED ZONEMAP;
The zone map will not be efficient until we cluster the rows together, so we’ll MOVE the table to achieve this. This will refresh the zone map too:
ALTER TABLE sales_zm MOVE;
Run the same query a few times to see what value “consistent gets” settles at:
SELECT COUNT(DISTINCT sale_id) FROM sales_zm WHERE customer_id = 50;
On my database, I read around 1,051 database blocks instead of 7,545: a considerable improvement:
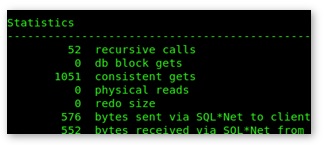
You’ll find more examples covering zone maps and attribute clustering in the Oracle Learning Library and inside the Oracle Github repository. Full details on zone maps and attribute clustering can be found in the Oracle documentation library; particularly the Oracle 12c Database Data Warehousing Guide.
There’s an earlier post on attribute clustering if you haven’t read it already.
If there’s anything to need to ask, or if you can’t find what you need regarding zone maps or attribute clustering, please let me know by leaving a comment below. Thanks!
