In my post about common distribution methods in Parallel Execution I talked about a few problematic execution plans that can be generated when the optimizer statistics are stale or non-existent. Oracle Database 12c brings some adaptive execution features that can fix some of those issues at runtime by looking at the actual data rather than statistics. In this post we will look at one of these features which is about adapting the distribution method on the fly during statement execution.
Adaptive Distribution Methods
One of the problems I mentioned in the earlier post was hash distribution with low cardinality. In that case there were only a few rows in the table but the optimizer statistics indicated many rows because they were stale. Because of this stale information we were picking hash distribution and as a result only some of the consumer PX servers were receiving rows. This made the statement slower because not all PX servers were doing work.
This is one of the problems we are trying to fix by using adaptive distribution methods in 12c. To show what an adaptive distribution method is and how it works I will use the same example from the older post and try to see how it works in 12c.
You can go back and look at the post I linked, but as a reminder here are the tables we used.
create table c as
with t as (select rownum r from dual connect by level<=10000)
select rownum-1 id,rpad('X',100) pad
from t,t
where rownum<=10;
create table s as
with t as (select rownum r from dual connect by level<=10000)
select mod(rownum,10) id,rpad('X',100) pad
from t,t
where rownum<=10000000;
exec dbms_stats.set_table_stats(user,'C',numrows=>100000);
exec dbms_stats.gather_table_stats(user,'S');Just like in the 11g example I modified the optimizer statistics for table C to make them stale.
Here is the same SQL statement I used before, this time without optimizer_features_enable set.
select /*+ parallel(8) leading(c) use_hash(s) */ count(*)
from c,s
where c.id=s.id; Here is the SQL Monitor report for this query in 12.1.
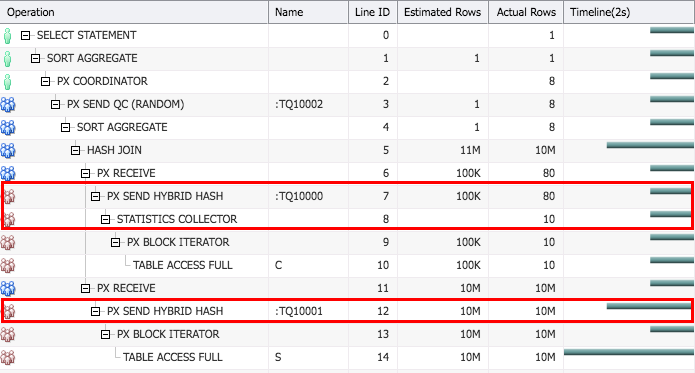
Rather than picking broadcast distribution for table C based on optimizer statistics like in 11g, here we see that the plan shows another distribution method, PX SEND HYBRID HASH in lines 7 and 12. We also see a new plan step called STATISTICS COLLECTOR. These are used to adapt the distribution method at runtime based on the number of rows coming from table C.
The query coordinator (QC) at runtime looks at the number of rows coming from table C, if the total number of rows is less than or equal to DOP*2 it decides to use broadcast distribution as the cost of broadcasting small number of rows will not be high. If the number of rows from table C is greater than DOP*2 the QC decides to use hash distribution for table C. The distribution method for table S is determined based on this decision. If table C is distributed by hash, so will table S. If table C is distributed by broadcast, table S will be distributed by round-robin.
The QC looks at the number of rows from table C at runtime using the statistics collector. Each PX server scanning table C count their rows using the statistics collector until they reach a threshold, once they reach the threshold they stop counting and the statistics collector is bypassed. They return their individual counts to the QC and the QC makes the distribution decision for both tables.
In this example table C is distributed by broadcast and table S is distributed by round-robin as the number of rows from table C is 10 and the DOP is 8. You can find this out by looking at the number of rows from table C (line ID 10), which is 10, and the number of rows distributed at line ID 7, which is 80. 10 rows were scanned and 80 rows were distributed, this is because DOP was 8 and all 10 rows were broadcasted to 8 PX servers. For an easier way to find out the actual distribution method used at runtime, please see an earlier post that shows how to do it in SQL Monitor.
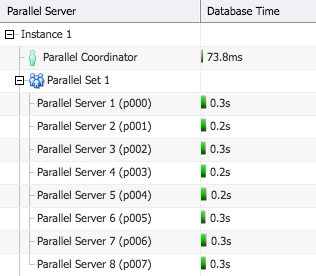
If we look at the Parallel tab we now see that all consumer PX servers perform similar amount of work as opposed to some of them staying idle in 11g.
Another problem I mentioned before was using hash distribution when the data is skewed. We will look at how Oracle Database 12c solves this problem in a later post.
