Parallel execution uses the producer/consumer model when executing a SQL statement. The execution plan is divided up into DFOs, each DFO is executed by a PX server set. Data is sent from one PX server set (producer) to another PX server set (consumer) using different types of distribution methods.
In this post we will look at the most common distribution methods used in joins in Oracle Database 11gR2. The distribution method is chosen by the optimizer and depends on the DOP, the cardinality of the tables, the number of partitions, etc…
Hash distribution
Let’s look at a simple 2-table join that joins table C (10K rows) and table S (1M rows).
create table c as
select rownum-1 id,rpad('X',100) pad
from dual
connect by level<=10000;
create table s as
select mod(rownum,10000) id,rpad('X',100) pad
from c,c
where rownum<=1000000;
exec dbms_stats.gather_table_stats(user,'C');
exec dbms_stats.gather_table_stats(user,'S');
explain plan for select /*+ parallel(2) */ count(*) from c,s where c.id=s.id;
select * from table(dbms_xplan.display);
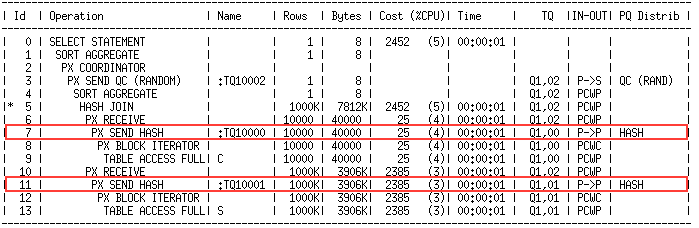
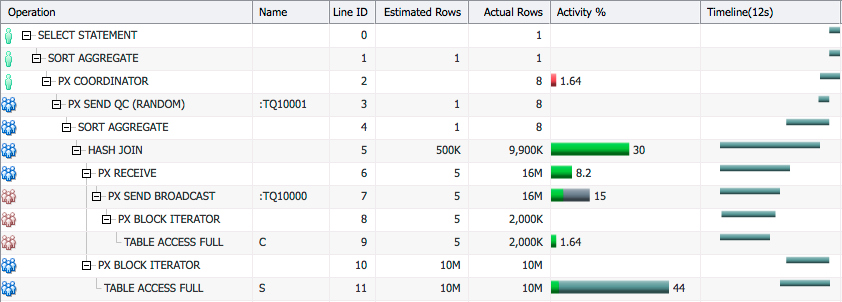
In both sides of the join we see hash distribution being used (Line Ids 7 and 11).
In hash distribution each PX server in the producer PX server set applies a hash function on the join key columns and sends the row to a single PX server in the consumer PX server set.
In the plan above PX servers PX1 and PX2 scan table C, they apply a hash function on the join column for each row and send that row to either PX3 or PX4 depending on the output of the hash function. After this PX3 and PX4 each have some of the rows from table C.
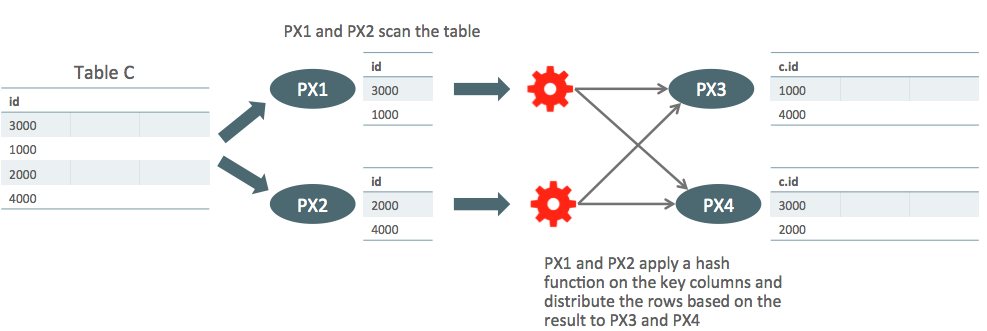
Now PX1 and PX2 scan table S and they again apply the hash function to the join column and send the rows to PX3 and PX4. This way, PX3 and PX4 receive rows having the same join column value from both tables. They now can do the join of these rows.
Hash distribution is used to equally distribute the rows to each consumer PX server so that each consumer has equal amount of work to do. This is based on the assumption that the join column values are not skewed. It is usually used when the number of rows to be distributed is high.
Broadcast distribution
Now let’s look at the same statement when table C has only a few rows.
create table c as
select rownum-1 id,rpad('X',100) pad
from dual
connect by level<=10;
create table s as
with t as (select rownum r from dual connect by level<=10000)
select mod(rownum,10000) id,rpad('X',100) pad
from t,t
where rownum<=1000000;
exec dbms_stats.gather_table_stats(user,'C');
exec dbms_stats.gather_table_stats(user,'S');
explain plan for
select /*+ parallel(2) */ count(*)
from c,s
where c.id=s.id;
select * from table(dbms_xplan.display);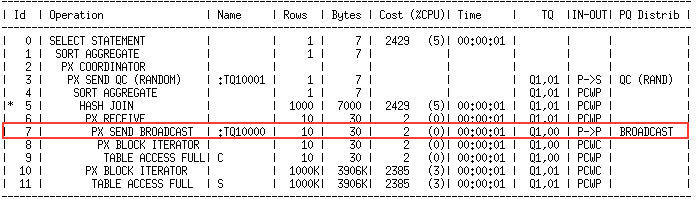
Now, the left side of the join, table C, is distributed using broadcast distribution (Line Id 7) and the right side of the join, table S, is not distributed.
In broadcast distribution each PX server in the producer PX server set sends all rows to every consumer PX server.
In the plan above PX servers PX1 and PX2 scan table C, send all rows they have to both PX3 and PX4.
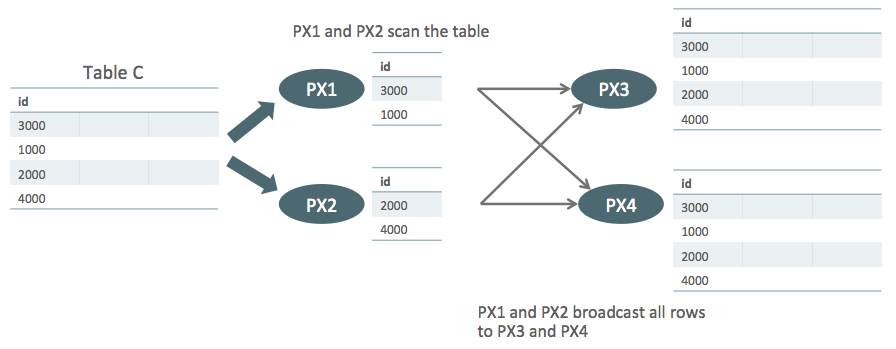
Since both PX3 and PX4 now have all rows from table C they can each scan a part of table S and do the join. This is what happens in Line Ids 10 and 11 in the plan above. Table S is divided into block granules and each PX server reads its own granules and the join is done by the same PX servers in Line Id 5.
Broadcast distribution is used when the number of rows is relatively low so that the cost of broadcasting the rows to all PX servers is not high.
Common problems
It is critical for the optimizer to choose the correct distribution method for the best possible performance. If it picks the suboptimal distribution method, the distribution of rows can take significant amount of time or the work distribution between consumer PX servers may not be balanced which causes some PX servers to stay idle. Let’s look at the most common examples where the optimizer can pick the suboptimal distribution method.
Broadcast distribution with high cardinality
The optimizer relies on table statistics to find out the cardinality of each side of a join. If the optimizer thinks that the cardinality of a table is low, it can pick broadcast distribution even if the actual cardinality turns out to be high. In this case, a lot of rows will be broadcasted to all consumer PX servers. The time spent for distribution can be significant impacting the performance badly. This is even more detrimental if the DOP is high and there are a lot of RAC nodes involved.
Here is an example where the optimizer statistics on table C are gathered when there are 5 rows in the table. After stats gathering, 2M rows are loaded into the table which makes the stats stale. This example is from a 12.1.0.2 database, note that I am setting optimizer_features_enable to 11.2.0.4 to show the behavior in 11gR2.
create table c as
select rownum-1 id,rpad('X',100) pad
from dual
connect by level<=5;
create table s as
with t as (select rownum r from dual connect by level<=10000)
select mod(rownum,100) id,rpad('X',100) pad
from t,t
where rownum<=10000000;
exec dbms_stats.gather_table_stats(user,'C');
exec dbms_stats.gather_table_stats(user,'S');
insert /*+ append */ into c
select rownum+5,rpad('X',100)
from s
where rownum<=2000000;
commit;
select /*+ optimizer_features_enable('11.2.0.4') parallel(8) leading(c) use_hash(s) */ count(*)
from c,s
where c.id=s.id; Here is the SQL Monitor report for the query. Note that I executed the example queries in this post multiple times so that we do not get the overhead of first execution in SQL Monitor reports.
We see that the estimated cardinality for table C was 5 (Line ID 9, Estimated Rows) but at runtime there were 2M rows (Line ID 9, Actual Rows). The optimizer picked broadcast distribution because of the low cardinality estimation, therefore 2M rows were broadcasted to all consumer PX servers (Line ID 7, Actual Rows = DOP*2M = 16M).
Here is the SQL Monitor report for the same statement after stats were gathered correctly for table C.
exec dbms_stats.gather_table_stats(user,'C',no_invalidate=>false);
select /*+ optimizer_features_enable('11.2.0.4') parallel(8) leading(c) use_hash(s) */ count(*)
from c,s
where c.id=s.id; 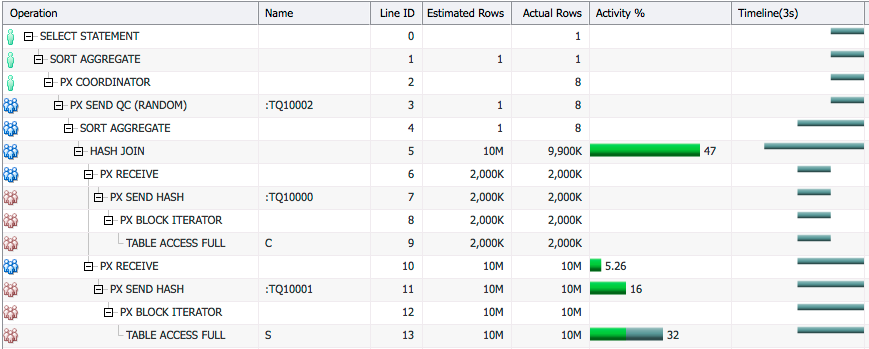
Now, we see that the estimated number of rows matches the actual number of rows (Line ID 9), and the distribution method is hash instead of broadcast (Line ID 7). Since table C is now distributed using hash, the right side of the join, table S, is also distributed by hash so that the matching rows go to the same consumer PX server. This second distribution (Line IDs 10 and 11) added some time to the query duration but the total elapsed time for the query was still lower than the plan with broadcast distribution, 3 seconds compared to 12 seconds.
Hash distribution with low cardinality
As opposed to the previous example you may have cases where optimizer stats indicate a high cardinality for a table, but the actual cardinality is low. In this case the optimizer will tend to pick hash distribution to avoid the cost of broadcasting a lot of rows. This means each consumer PX server will have some rows from the producers, but not all rows. If some of the consumer PX servers do not get any rows they will stay idle and will not contribute to the execution. This will lead to suboptimal performance for your query.
Here is an example that shows such a case, again on a 12.1.0.2 database with optimizer_features_enable set to 11.2.0.4. Table C actually has 10 rows but I modified the stats so that the optimizer thinks that the table has 100K rows.
create table c as
with t as (select rownum r from dual connect by level<=10000)
select rownum-1 id,rpad('X',100) pad
from t,t
where rownum<=10;
create table s as
with t as (select rownum r from dual connect by level<=10000)
select mod(rownum,10) id,rpad('X',100) pad
from t,t
where rownum<=10000000;
exec dbms_stats.set_table_stats(user,'C',numrows=>100000);
exec dbms_stats.gather_table_stats(user,'S');
select /*+ optimizer_features_enable('11.2.0.4') parallel(8) leading(c) use_hash(s) */ count(*)
from c,s
where c.id=s.id; Here is the SQL Monitor report for this query.
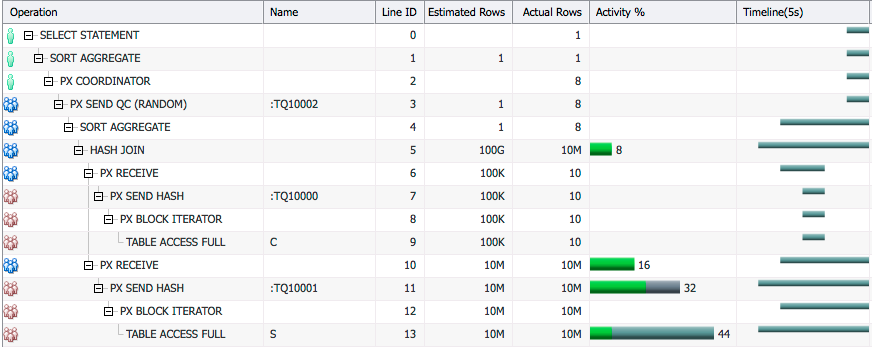
We see that the optimizer estimated 100K rows for table C whereas at runtime there were 10 rows (Line ID 9). Because of this it picked hash distribution for table C which in turn requires hash distribution for table S too.
If we look at the Parallel tab in the SQL Monitor report we see that some PX servers doing the join are more active than the others. This is because they got more rows from hash distribution of table C and table S and had to do more work.
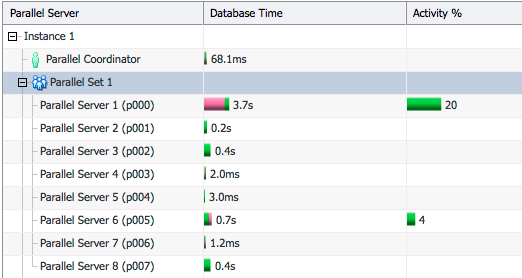
Here is the SQL Monitor report for the same statement after stats were gathered correctly for table C.
exec dbms_stats.gather_table_stats(user,'C',no_invalidate=>false);
select /*+ optimizer_features_enable('11.2.0.4') parallel(8) leading(c) use_hash(s) */ count(*)
from c,s
where c.id=s.id;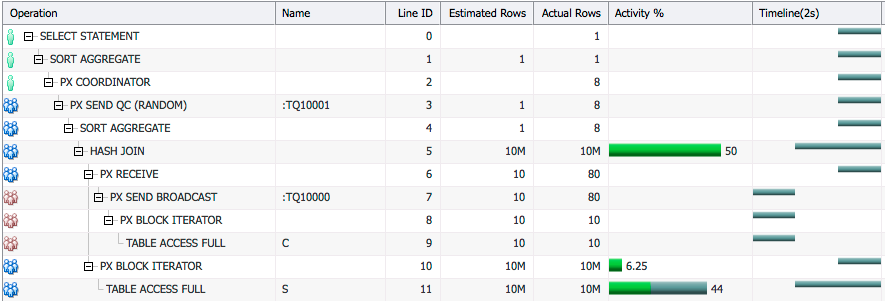
Now the estimated number of rows matches the actual number of rows (Line ID 9) and since there are only a few rows in the table the optimizer picked broadcast distribution for table C and no distribution for table S. As a result of this the elapsed time dropped to 2 seconds from 5 seconds.
If we look at the Parallel tab, we now see that all PX servers doing the join are equally utilized.
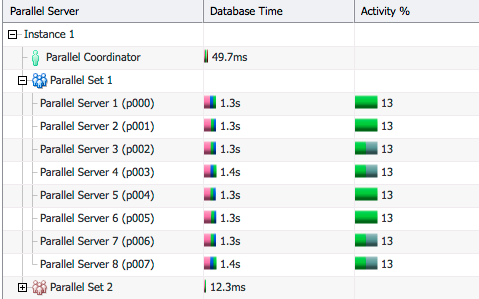
Hash distribution with skewed values
Even if the optimizer statistics are up-to-date there may be issues with data distribution when the join columns have skewed values. Let’s look at an example showing what happens in that case.
create table c as
with t as (select rownum r from dual connect by level<=10000)
select rownum-1 id,rpad('X',100) pad
from t,t
where rownum<=1000000;
create table s as
with t as (select rownum r from dual connect by level<=10000)
select mod(rownum,2) id,rpad('X',100) pad
from t,t
where rownum<=100000
union all
select 100 id,rpad('X',100) pad
from t,t
where rownum<=10000000
;
exec dbms_stats.set_table_stats(user,'C');
exec dbms_stats.gather_table_stats(user,'S',method_opt=>'for columns id size 254');Here is the data distribution for column ID in table S.
ID COUNT(*)
---------- ----------
1 50000
100 10000000
0 50000Column ID has 3 values with one value (100) having many more rows compared to the other values. This is why I also created a histogram on that column when gathering stats for the table.
Here is the SQL Monitor report for this statement.
select /*+ optimizer_features_enable('11.2.0.4') parallel(8) leading(c) use_hash(s) */ count(*)
from c,s
where c.id=s.id; 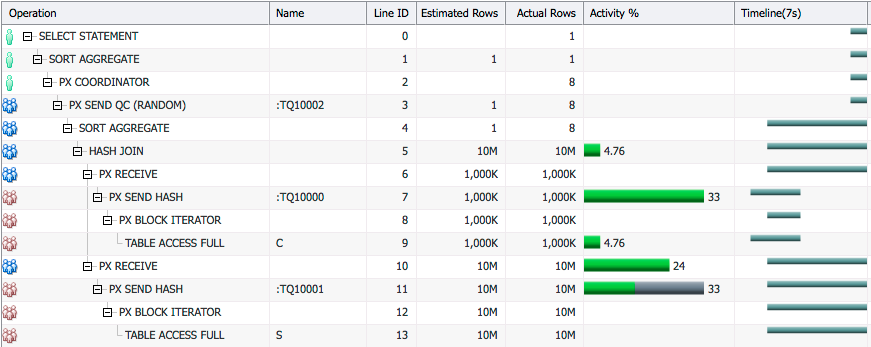
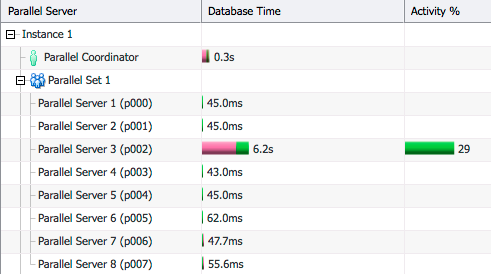
We see that hash distribution of both tables is impacting the elapsed time significantly (Line IDs 7, 10, 11). If we look at the Parallel tab we see that one PX server (P002) is doing nearly all the work. This is because 10M rows in table S have the join column value 100 and all these rows are sent to the same PX server as a result of hash distribution.
Adaptive Distribution Methods
Keeping optimizer statistics up-to-date is essential for good performance. To help with the cases where the stats are stale or non-existent, Oracle Database 12c introduces many optimizer and parallel execution features to adapt the execution plan at runtime for better performance. Adaptive distribution methods introduced in 12c help with data distribution problems caused by stale optimizer stats or skewed values in join columns.
In a later post we will look at how these features handle the data distribution problems we talked about in this post.
