Do you want to be on the wrong end of a data breach? Do you want to suffer the consequences of accidental exposure of sensitive data and potential misuse of that data? Autonomous Database offers several documented, security measures inherent to the service, such as data encryption, key management, data redaction, data subsetting, data masking, and data encryption to protect your sensitive data. But what about data that may have compliance or governance requirements that could prohibit moving a column’s sensitive data to the cloud?
Data tokenization is an ideal solution for this use case. Data tokenization helps preserve sensitive columnar data in an external, secure service provider vault. The sensitive data is obfuscated using tokenization and then inserted into your Autonomous Database along with your non-sensitive data. This can be important when complying with data governance requirements. Data tokenization in Autonomous Database offers the added security benefits:
- Simplicity: non-sensitive and tokenized data loads into your Autonomous Database,
- Performance: pre-tokenization of bulk data loads into the database speeds processing,
- Flexibility: tokenize ad hoc DML inserts,
- Authorized access to the original data: contextual data access through in-memory Application Context authentication,
- Seamless integration: external storage of sensitive data in service provider vaults,
- Consistency: preservation of original data shape,
- Security: data governance features
One of the key benefits of data tokenization is that it allows you to analyze your data without revealing sensitive information. For example, you can aggregate data by that sensitive column and get results that are consistent and meaningful.
Data tokenization allows you to obfuscate the actual data with token data, e.g. data that is obfuscated but retains the data ‘shape’ as stored in the database. For example, you will likely want to protect Social Security numbers (SSN), a unique 9-digit identifier assigned to individuals, which have a data shape like 222-22-2222. Your tokenization service provider may offer an SSN-like token which replaces the sensitive data with a token reference preserving the data shape with a human readable string of characters. This is unlike data encryption which replaces the value with an algorithm generated unreadable cipher. Tokens map back to the actual, sensitive data which is protected in an external third-party managed vault. To retrieve the real data, you must provide the corresponding authentication information for the vault. Oracle Autonomous Database allows you to configure and store that authentication information in the privileged users Application Context. A token is irreversible unless you authenticate to access the vault.
In this blog, we will show you how to implement data tokenization and detokenization functions in Oracle Autonomous Database for an external tokenization service, such as Very Good Security (VGS), and how to protect your sensitive data for bulk loads, ad hoc insert via DML, and SQL queries.
Overview of Tokenization Integration in Oracle Autonomous Database
The specific implementation may vary depending on which tokenization service-provider you choose. In the examples in this blog, we use Very Good Security (VGS), which provides API services for data tokenization.
Valid authentication information is required in order to call VGS’s API (please check VGS’s documentation on how to get their authentication data). We then store the VGS’s secret information in the privileged user’s application context and retrieve it when we call VGS’s API. In figure 1 below describes the high-level data flow for the data tokenization during insert, bulk loads, or ad hoc SQL DML. The insert operation invokes a tokenization function which calls the tokenization service API, VGS in this case, to store the original sensitive data and returns the tokenized version of the data. Tokenized data is inserted in the target table. Authentication is handled in-memory using defined application context for the user.
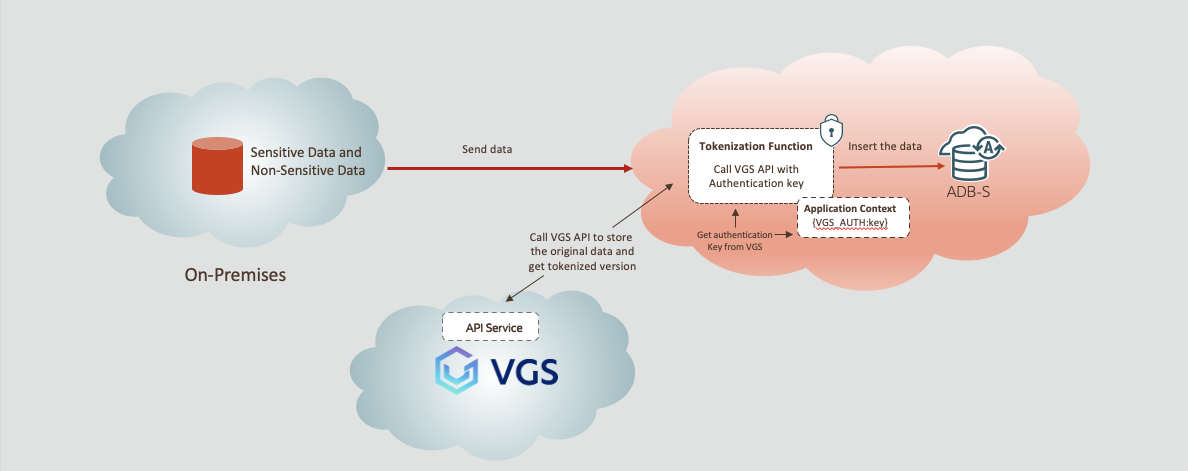 Figure 1. Data tokenization data flow in Oracle Autonomous Database using VGS
Figure 1. Data tokenization data flow in Oracle Autonomous Database using VGS
Reading sensitive data as a privileged, authorized user requires data detokenization. The privileged user executes the read requests, the user’s application context has the authentication key defined, and it is validated. The detokenization function is invoked which calls the tokenization providers API with the authentication key. The original, detokenized data is returned, and this privileged user can read both sensitive and non-sensitive data in the same query. Figure 2 below is a high-level description of this operation.
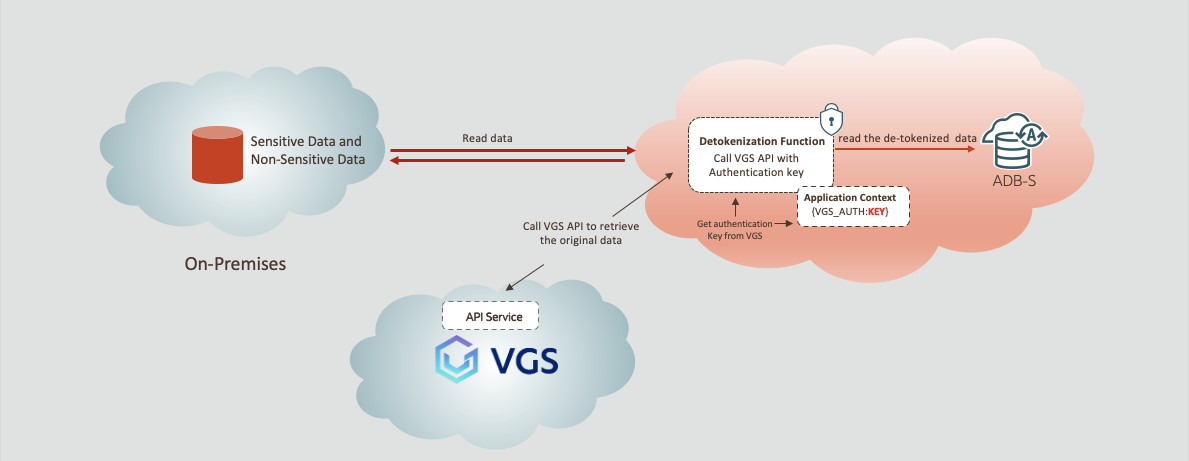
Figure 2. Data detokenization data flow in Oracle Autonomous Database as an authorized user using VGS
In contrast to authorized user detokenization, an unauthorized user does not have the authorization stored in the application context. As consequence, the detokenization function checks if the user has the authorization key. If not, there is no API call to the tokenization service provider and the unauthorized user only sees tokenized data as depicted in figure 3 below.
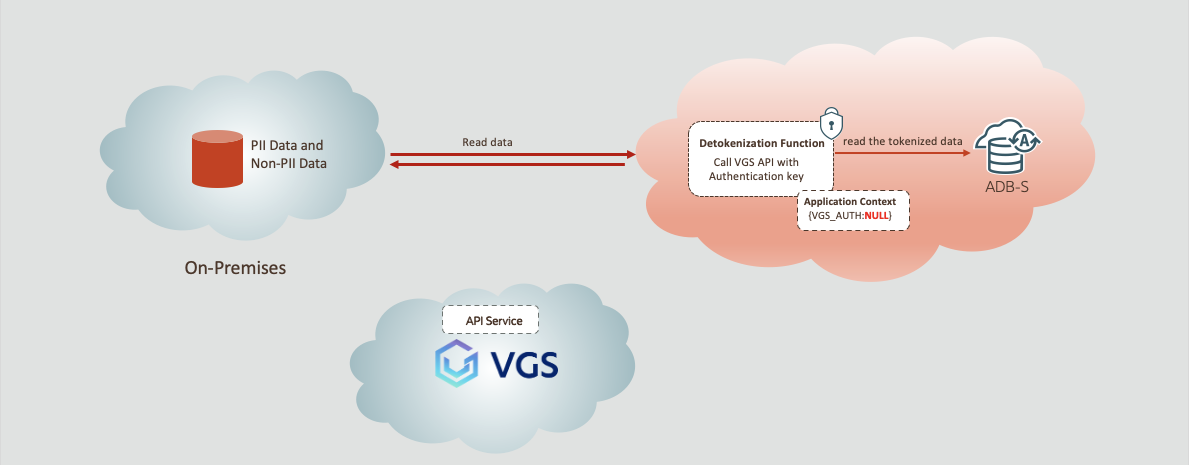
Figure 3. Data detokenization data flow in Oracle Autonomous Database as an unauthorized user using VGS
Store Authentication Info in Application Context
As we discussed above, we suggest you employ Database Application Context, which is a set of name-value pairs that the Oracle Database stores in memory, to store authentication data. The benefits of using Application Context for token service authentication include:
- Keys stored in Application Context remain exclusively accessible to the database user, ensuring that Oracle and other entities cannot access the data.
- Admin users can easily manage who can encrypt or decrypt the data by verify if they have the authentication available.
Below are detailed steps to store the key into the application context.
- Create an Application Context and specify the PL/SQL package that can set or reset the context variables with the USING clause.
Create the Application Context for authentication:
-- Create an application context with namespace 'USER_CTX', and specify the package CREATE OR REPLACE CONTEXT USER_CTX USING pkg_user_application_context;
- Create the PL/SQL package with the procedure that calls DBMS_SESSION.SET_CONTEXT to add a value pair for the secret key under the USER_CTX context created earlier.
Create the set_context_values procedure:
-- Create user application context package
CREATE OR REPLACE PACKAGE pkg_user_application_context
IS
PROCEDURE set_context_values(secret IN VARCHAR2);
END pkg_user_application_context;
/
CREATE OR REPLACE PACKAGE BODY pkg_user_application_context
IS
PROCEDURE set_context_values(secret IN VARCHAR2)
IS
BEGIN
-- Use below line for VGS API which adds {VGS_AUTH : secret} pair into 'USER_CTX':
DBMS_SESSION.SET_CONTEXT('USER_CTX', 'VGS_AUTH', secret);
END set_context_values;
END pkg_user_application_context;
/
-- Call the set_context_values procedure we defined in step 2 and pass the secret key you want to store
BEGIN
pkg_user_application_context.set_context_values(< vgs_key>);
END;
/
You can run the following code block to print the key and verify if the secret key is stored successfully.
-- Verify secret key is in SYS_CONTEXT
set serveroutput on;
BEGIN
DBMS_OUTPUT.PUT_LINE(SYS_CONTEXT('USER_CTX','VGS_AUTH'));
END;
/
Steps for Data Tokenization in ADB
Tokenization and detokenization are executed by function calls to the external tokenization service. In our example we invoke VGS’s API to do the tokenization for sensitive data. Details for the VGS API used in our example include:
- API:
https://api.sandbox.verygoodvault.com/aliases (sandbox),
https://api.live.verygoodvault.com/aliases (live).
- Method: POST
- Authorizations: BasicAuth
- Request body Sample:
— value: the data we want to tokenize.
— classifier: relevant category for the data.
— format: the data format.
Details in: https://www.verygoodsecurity.com/docs/vault/concepts/tokens/.
— storage: either VOLATILE or PERSISTENT. Persistent storage allows you to store your data with VGS on a permanent basis, such as credit card numbers, account numbers, and Personally Identifiable Information. To be PCI compliant, Sensitive Authentication Data cannot be stored in persistent storage, even if it is encrypted. Sensitive Authentication Data must be stored in volatile storage, and it must be deleted after the authorization for which it was collected is completed. More detail: https://www.verygoodsecurity.com/docs/getting-started/storage/.
Request Body for VGS Tokenization API
{
“data”: [
{
“value”: 122105155,
“classifiers”: [
“bank-account”
],
“format”: “UUID”,
“storage”: “PERSISTENT”
}
]
}
- Response sample (201):
— alias: the token for the data.
Response Body From VGS Tokenization API
{
“data”: [
{
“value”: 122105155,
“classifiers”: [
“bank-account”
],
“aliases”: [
{
“alias”: “tok_sandbox_bhtsCwFUzoJMw9rWUfEV5e”,
“format”: “UUID”
}
],
“created_at”: “2019-05-15T12:30:45Z”,
“storage”: “PERSISTENT”
}
]
}
NOTE: For more information about VGS tokenization API, please see https://www.verygoodsecurity.com/docs/vault/api/.
The following is a sample tokenization function designed for use with the VGS API. This function checks the authorization key in the user’s application context when inserting data into the database. If the authentication key is defined, tokenized data is inserted into the table. If the authentication key value is NULL, insert non-tokenized data. To get the tokenized value for the data, the VGS API is invoked by the function and the tokenized value is returned and inserted into the table. This enables customers to manage insert of sensitive data by storing the sensitive data value in the external tokenization service provider’s vault and returning tokenized data to insert into the table.
-- Tokenization Function for VGS API:
CREATE OR REPLACE FUNCTION vgs_tokenization (
value varchar2,
classifier varchar2,
format varchar2,
storage varchar2
) RETURN varchar2
IS
l_req_body JSON_OBJECT_T := new JSON_OBJECT_T;
l_data_arr JSON_ARRAY_T := new JSON_ARRAY_T;
l_data_jo JSON_OBJECT_T := new JSON_OBJECT_T;
l_classifier_arr JSON_ARRAY_T := NEW JSON_ARRAY_T;
l_resp DBMS_CLOUD_TYPES.resp;
l_resp_jo JSON_OBJECT_T;
l_auth VARCHAR2(128);
BEGIN
l_auth := SYS_CONTEXT('USER_CTX','VGS_AUTH');
-- When the authentication for VGS API is found,
-- data tokenization is executed; otherwise, the original value is returned.
IF l_auth IS NOT NULL AND length(l_auth) >= 1 THEN
-- construct the request body. The format is:
-- "\{"data":\[\{"value": value,"classifiers":\[classifier\],
-- "format":format,"storage": storage\]\}"
l_classifier_arr.append(classifier);
l_data_jo.put('value', value);
l_data_jo.put('classifiers', l_classifier_arr);
l_data_jo.put('format', format);
l_data_jo.put('storage', storage);
l_data_arr.append(l_data_jo);
l_req_body.put('data', l_data_arr)
-- Send request
l_resp := DBMS_CLOUD.send_request(
credential_name => NULL,
uri => 'https://api.sandbox.verygoodvault.com/aliases',
method => DBMS_CLOUD.METHOD_POST,
headers => JSON_OBJECT(
'Content-Type' value 'application/json',
'Authorization' value 'Basic ' || l_auth
),
BODY => UTL_RAW.cast_to_raw(l_req_body.to_string())
);
-- Get the response
l_resp_jo := JSON_OBJECT_T.parse(DBMS_CLOUD.get_response_text(l_resp));
RETURN (
JSON_OBJECT_T (
JSON_OBJECT_T(
l_resp_jo.get_Array('data').get(0))
.get_Array('aliases').get(0)
)
.get_String('alias')
);
ELSE
RETURN value;
END IF;
END;
/
Example of Bulk Load of Data using External Files
Ideally you want to tokenize sensitive data before inserting into the database. The following example leverages external files stored in OCI object store and, using external tables, insert tokenized data into the database.
An external table can be created by using either the SQL CREATE TABLE…ORGANIZATION EXTERNAL statement or calling the DBMS_CLOUD.CREATE_EXTERNAL_TABLE API.
For example, the syntax for the DBMS_CLOUD.CREATE_EXTERNAL_TABLE is shown below.
-- Create external table
DBMS_CLOUD.CREATE_EXTERNAL_TABLE (
table_name IN VARCHAR2,
credential_name IN VARCHAR2,
file_uri_list IN CLOB,
column_list IN CLOB,
field_list IN CLOB DEFAULT,
format IN CLOB DEFAULT);
Once the external table is created, then we tokenize the data from the external table and insert the data into the target database. In this example, col_2 is sensitive data.
-- Tokenize and load data into TARGET_TBL using external table EXT_TBL INSERT INTO target_tbl(col_1 col_2 ...) SELECT col_1 vgs_tokenization(col_2 ... ) ... FROM ext_tbl;
Using ad hoc SQL DML to Insert into the Table
If we just insert a single piece of data or a small number of data, we can directly use INSERT DML with the tokenization function. In this example, col_2_val is again the sensitive data.
-- Tokenize and load data with DML in to TARGET_TBL INSERT INTO target_tbl VALUES (col_1_val, vgs_tokenization(col_2_val...) ...);
Utilize View & INSTEAD OF Trigger
When inserting sensitive data or a small amount of sensitive data, instead of interacting directly with the table and calling the VGS_TOKENIZATION function for every insert, we can utilize a VIEW and an INSTEAD OF trigger to eliminate the need for database users to directly call the tokenization function. An INSTEAD OF trigger is defined on a view. It can control insert, update, merge, and delete operations on views, not tables, and can be used to make non-updateable views updateable and to override the default behavior of views that are updateable.
The specific steps for this process are outlined below:
- Create a view that is based on the table you want to work with. In this example, col_2 is again the sensitive.
-- Create TARGET_VIEW
CREATE OR REPLACE VIEW target_view
AS SELECT * FROM target_tbl;
or
-- If you want to allow the detokenization feature for the view at the same time.
CREATE OR REPLACE VIEW target_view (col_1 col_2 ...)
AS SELECT col_1 detokenization_func(col_2 ... FROM target_tbl;
NOTE the DETOKENIZATION_FUNC included in the second example. It is useful if you have a defined DETOKENIZATION_FUNC and would like to allow queries for decrypted data from the view. Details for this are included in the Steps for Data Decryption in ADB section below.
- Implement an INSTEAD OF trigger which allows to insert the data into the table and integrate the tokenization function.
-- Create INSTEAD OF trigger
CREATE OR REPLACE TRIGGER new_data_trg
INSTEAD OF INSERT ON target_view
FOR EACH ROW
BEGIN
INSERT INTO target_tbl
VALUES(:NEW.col_1 vgs_tokenization(:NEW.col_2..) ...);
END;
- Insert the data to the table via the view. Users don’t interact with the tokenization function directly now.
-- Insert Data via the View
INSERT INTO target_view
VALUES (col_1, col_2 ...);
Steps for Data Detokenization in ADB
Detokenization Function
Certain database users may be granted access to view the original data instead of the tokenized version. To enable the retrieval of detokenized data from the database, you can implement an additional detokenization function.
Details regarding VGS’s detokenization API:
- API:
https://api.sandbox.verygoodvault.com/aliases/{alias} (sandbox),
https://api.live.verygoodvault.com/aliases/{alias} (live).
note: ‘alias’ refers to the token.
- Method: GET
- Authorizations: BasicAuth
- No data needed for request body.
- Response sample (201)
— value: the detokenized data.
Response Body from VGS Detokenization API
{
“data”: [
{
“value”: 122105155,
“classifiers”: [
“bank-account”
],
“aliases”: [
{
“alias”: “tok_sandbox_bhtsCwFUzoJMw9rWUfEV5e”,
“format”: “UUID”
}
],
“created_at”: “2019-05-15T12:30:45Z”,
“storage”: “PERSISTENT”
}
]
}
NOTE: For more information about VGS tokenization API, please see https://www.verygoodsecurity.com/docs/vault/api/
The following is an example of detokenization function using the VGS API Solution. Data detokenization happens when the authentication information is found in the user’s application, otherwise, the tokenized data is returned. This enables customers to manage privilege for data detokenization.
-- Detokenize function for VGS solution
CREATE OR REPLACE FUNCTION vgs_detokenization (
tokenized_value varchar2
) RETURN varchar2
IS
l_auth VARCHAR2(128);
l_uri VARCHAR2(128);
resp DBMS_CLOUD_TYPES.resp;
resp_jo JSON_OBJECT_T;
BEGIN
l_auth := SYS_CONTEXT('USER_CTX','VGS_AUTH');
–- When the authentication for VGS API is found, data detokenization is executed
-- otherwise, the tokenized value is returned.
IF l_auth IS NOT NULL AND length(l_auth) >= 1 THEN
l_uri := 'https://api.sandbox.verygoodvault.com/aliases/' || tokenized_value;
-– Send request
resp := DBMS_CLOUD.send_request(
credential_name => NULL,
uri => l_uri,
method => DBMS_CLOUD.METHOD_GET,
headers => JSON_OBJECT (
'Content-Type' value 'application/json',
'Authorization' value 'Basic ' || l_auth
)
);
resp_jo := JSON_OBJECT_T.parse(DBMS_CLOUD.get_response_text(resp));
RETURN (
JSON_OBJECT_T(
resp_jo.get_Array('data').get(0)
)
.get_String('value')
);
ELSE
RETURN tokenized_value;
END IF;
END;
/
Create a View to Query Data & Detokenized Data
This last step is to create a view based on the table you want to work with and integrate with the detokenization function. Add WITH READ ONLY statement if you don’t want the database users to have the permission to modify the table. In this example, col_2 is sensitive data.
-- Wrapper VIEW for detokenizing data using VGS
CREATE OR REPLACE VIEW targeting_view (col_1, col_2..)
AS SELECT col_1, vgs_detokenization(col_2 ... FROM targeting_tbl
(WITH READ ONLY);
Query View to Get Corresponding Data
Once these steps are successfully complete, we can query the data from the view you just defined. The query should return the original sensitive data for authorized users and tokenized data for those who don’t have the privileges to access the sensitive data.
-- Query detokenized data SELECT * FROM target_view;
Summary
Data tokenization is a critical and useful technique to help safeguard your data, manage data access for different users and comply with regulatory standards. To apply this security measure to your sensitive data in the Oracle Autonomous Database, you must create the tokenization and detokenization functions which call a third-party data tokenization service API. The Oracle Autonomous Database supports all commonly used third-party data tokenization services. As describe, the Oracle Autonomous Database data tokenization / detokenization provides the flexibility to differentiate privileged users from non-privileged users to access sensitive data. Enforcing authentication with in-memory application context further ensures secure access, and, using an INSTEAD OF trigger with a defined VIEW enables updates through the VIEW rather than to underlying protected data. Protect your data!
This blog is a collaboration with Wen Liao, Software Engineer, Oracle Autonomous Database.
