The Oracle Autonomous Database (ADB) is genuinely a converged database, making it the ideal place to store and retrieve all types of data your business may use. In the past, I wrote a post about data loading, walking through examples of moving various types of unstructured and semi-structured data residing in the Oracle object store into your ADB. Some users had asked for similar examples of loading XML data into ADB via the object store, so here we go…
The steps for loading semi-structured XML-type data are straightforward and similar to our previous example for loading JSON data into an Autonomous Database using the DBMS_CLOUD package.
Before we get into the example, some prerequisites to follow the example below are:
- Ensure you have a running ADB instance with some storage space and a user with object store access. You can follow Lab 1 in the ADB Quickstart workshop if you haven’t done this already.
- Click here to download a sample XML data file we will use below, and upload this file to a bucket in your Object Store. If you need exact steps to upload files to the Oracle Object Store, follow Lab 3 Step 4 in the ADB Quickstart workshop. You may also use AWS or Azure object stores if you prefer and may refer to the documentation for more information on this.
- You will provide the URL of the XML file in your object store to the DBMS_CLOUD function call. If you already created your object store bucket’s URL in the lab, you may use that; otherwise, you may copy the URL from your “Object Details” in the Object Store bucket’s UI console. The format, if you would prefer to construct the URL yourself, is below; replace the placeholders <region_name>, <tenancy_name>, and <bucket_name> with your object store bucket’s region, tenancy, and bucket names.
https://objectstorage.<region_name>..oraclecloud.com/n/<tenancy_name>/b/<bucket_name>/o/
The easiest IDE ready-to-use with every Autonomous Database is SQL Developer Web, which makes it quick and easy to connect to your database and start running scripts. On your database’s UI console, go to the “Database Actions” menu and click on SQL Developer Web. You will automatically log in as user ADMIN, which is sufficient for this exercise. Alternatively, you can always log in as a different user with the appropriate privileges.
Step 1 – Create credential for Object Store access
We authenticate your database to connect to the object store with a user credential. We create one using the DBMS_CLOUD.CREATE_CREDENTIAL procedure. Please refer to this article for details on where to generate an auth token for your user.
--Please fill in your OCI Object Store username and auth token below begin DBMS_CLOUD.create_credential( credential_name => 'OBJ_STORE_CRED', username => 'your.username@oracle.com', password => 'm4F;.]:2JxJO..wepofwMUvg' ); end; /

Step 2 – Create an external table over your XML datafile
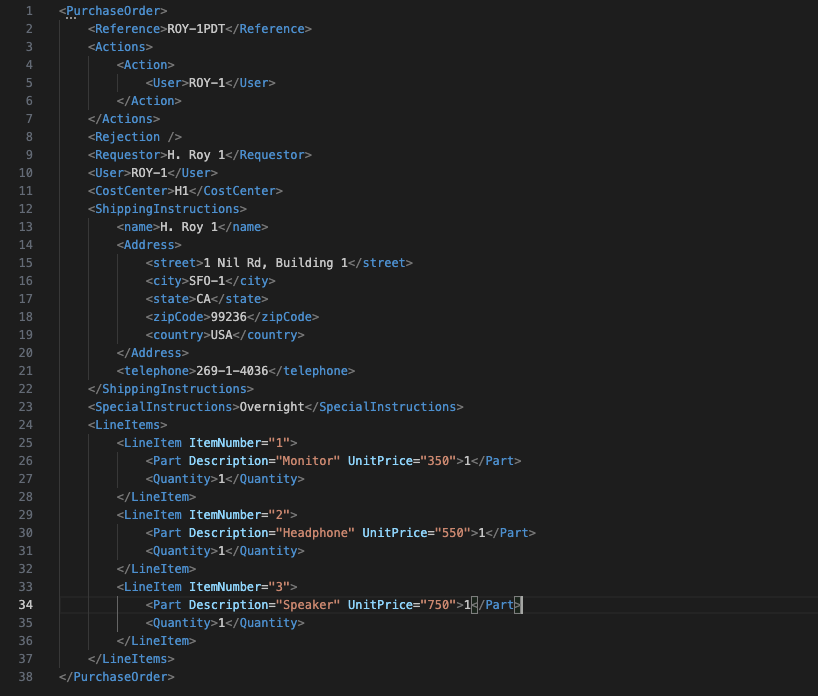
Look at the XML data file we uploaded to our object store bucket (in the pre-requisites above). It contains a user “Roy-1” purchase order document and several line items.
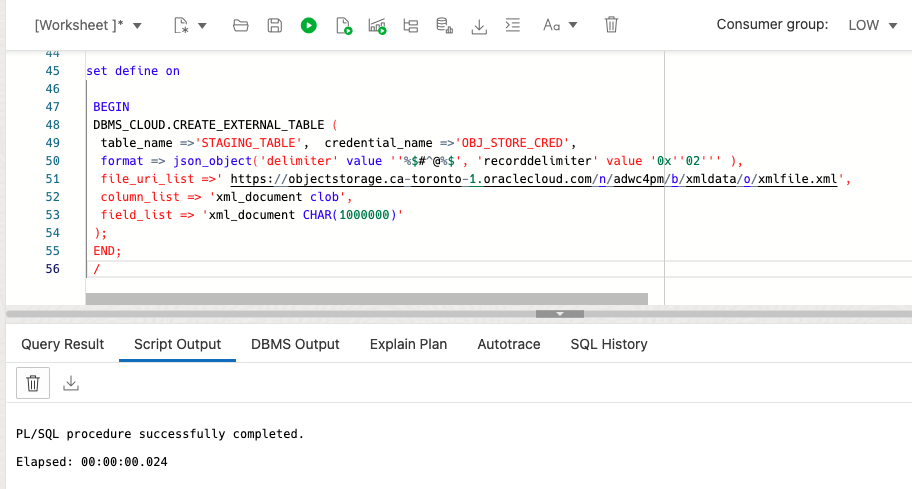
We use the DBMS_CLOUD package to create an external table (here we name it “STAGING_TABLE”), with a column of type CLOB, over our datafile in the object store. We are choosing this datatype because we have to deal with a potentially large document in the file we are accessing. (Note this is not the case for this example.) We input the object store URL in the “file_uri_list” parameter.
There are other important aspects when defining your external table on top of your file(s) containing one or multiple XML documents:
- Field delimiter: This parameter describes how the external table should detect the end of a field (column) of our external table. The default value in DBMS_CLOUD is the pipe (‘|’) delimiter. When Oracle finds that character in your data, it will stop reading more data and consider it part of your column. We want to load *everything* in our XML document as one CLOB column value, so you must set this to something you’ll never find in your data. I usually use something sensible as ‘%$#^@%$’, which has no meaning whatsoever other than not being in my data set.
- Recorddelimiter: If your file has multiple XML documents, each document should be separated by a unique delimiter, similar to what we did with the field delimiter above. Unlike the field delimiter, the recorddelimiter must be in your data set and deterministically define the boundaries of individual documents; if you set this to an arbitrary string, the external table will read as many lines in the document as needed, ignoring line breaks, until it finds the recorddelimiter. Our sample file only contains a single purchaseorder XML document, so we set this parameter to 0x03 (ascii, end of text).
- Field definition (field list): The field definition clause serves multiple purposes in external tables, but the most important one for us here is to define the length of the field that holds our XML document (basically the record). By default, fields are of data type CHAR with a maximum length of 255. We need more than this for our XML document, so we must adjust this.
(For an overview of all possible format parameters in DBMS_CLOUD, you can consult the documentation)
set define on
BEGIN
DBMS_CLOUD.CREATE_EXTERNAL_TABLE (
table_name =>'STAGING_TABLE', credential_name =>'OBJ_STORE_CRED',
format => json_object('delimiter' value ''%$#^@%$', 'recorddelimiter' value '0x''02''' ),
file_uri_list =>' https://objectstorage.yuour_region.oraclecloud.com/n/your_tenancy/b/your_bucket/o/your_file_name.xml',
column_list => 'xml_document clob',
field_list => 'xml_document CHAR(1000000)'
);
END;
/
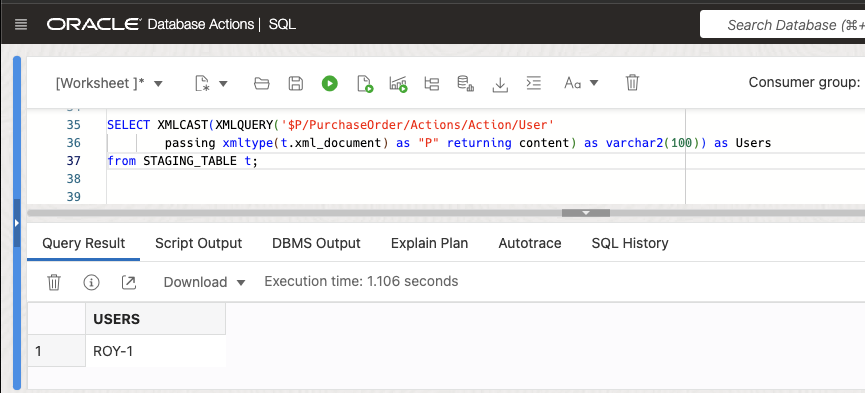
We can immediately query our XML file lying in the object store via the external table CLOB column, using native database XML features such as XPATH expressions.
SELECT XMLCAST(XMLQUERY('$P/PurchaseOrder/Actions/Action/User'
passing xmltype(t.xml_document) as "P" returning content) as varchar2(100)) as Users
from STAGING_TABLE t;
Note: While this is possible it is highly recommended not to do this against very large files. That’s an artifact of having a much better processing inside the database with the XMLTYPE as compared to CLOB data coming from external tables. So please read on.
Step 3 – Copy and convert data from the external table into a native XMLTYPE column
Lastly, move the XML data into a column in ADB, by simply extracting each XML document into a table with an XMLTYPE (or CLOB) column, and using the powerful XML features in the database to parse and query them.
--Saving the XML data into a into an XMLTYPE column
CREATE TABLE xml_table (xml_document xmltype);
INSERT INTO xml_table (SELECT XMLTYPE(xml_document) from STAGING_TABLE);
Note: We currently support XMLType columns, not tables, in ADB on Shared Infrastructure. Registering XML schema is not supported. Refer any XML DB restrictions here.
This example should give the steps to ingest and query your XML data in ADB quickly. The Autonomous Database also supports spatial data and Oracle Text, allowing you to full-text index, optimize, and analyze your semi-structured data and get the business value you want out of it.
There is one more thing ….
When you look closely at the details of the external table access parameters, you might have spotted another parameter that we have not touched or talked about. It’s the readsize parameter.
The readsize defines the size of the read buffer to process records and must be at least as large as the largest record (XML document) in the data set we’re reading. The default in Autonomous Database is set to 10MB, but can be adjusted if needed.
We have not used this parameter in our example. One reason is that we did not need it with our small sample file. The more important reason, however, is that we don’t want you to deal with extremely large single document files. It’s usually way more performant to deal with a bunch of smaller XML files containing fewer documents than dealing with a huge, single file. You can easily split your large document file using our sample XML split code on Git Hub to generate a bunch of smaller files to increase the performance significantly. How to do this sounds like a good topic for a future blog post …
See you in the next one!
Like what I write? Follow me on the Twitter! ?
