There is incredible value to being able to go to a single place and query data across relational, Hadoop, and object storage. When you access that data, you don’t need to be concerned about its source. You can have a single, integrated database to correlate information from multiple data stores.
It’s even better when that database you are querying is Autonomous Database on Shared Exadata Infrastructure (ADB-S); you get all of the great management, security and performance characteristics in addition to the best analytic SQL. ADB-S lets you query any data in Big Data Service’s Hadoop clusters. Big Data Service includes the Cloud SQL Query Server – which is an Oracle-based SQL on Hadoop query execution engine. From ADB-S, you simply create a database link to Query Server – and your ADB-S queries will be distributed across the nodes of the cluster for scalable, fast performance. This has been made easier with the latest release of Big Data Service. Kerberos is the authentication mechanism for Hadoop – which is highly secure but also a bit cumbersome. In addition to making a Kerberos connection to Query Server – you can now make a standard JDBC connection. This not only benefits ADB-S – but it also benefits any other client that wants to analyze data in Hadoop using Oracle SQL.
Here’s a step-by-step on how to set up ADB-S to access Query Server. There are a few steps – but this is because we’ll be showing you how to use network encryption between ADB-S and Query Server.
Prerequisite
As a prerequisite, a secure Big Data Service cluster is created and sample data is uploaded to HDFS and Hive. See this tutorial for steps in creating the environment. After creating the secure cluster, you will follow the steps below to:
- Add a user to the cluster and to Query Server.
- Add sample data to HDFS and Hive.
- Set up a secure connection between ADB-S and Query Server
- Create a database link and start running queries!
Let’s start. As root:
#
# Add an admin user to the cluster: OS & Kerberos
#
# OS user
dcli -C "groupadd supergroup"
dcli -C "useradd -g supergroup -G hdfs,hadoop,hive admin"
# Kerberos
kadmin.local
kadmin.local: addprinc admin
kadmin.local: exit
Add sample data to the cluster following the HDFS section of the data upload lab.
#
# Download Sample Data and Add to Hive
#
# get a kerberos ticket for the newly added "admin"user
kinit admin
# download and run the scripts required to create sample data and hive tables
wget https://objectstorage.us-phoenix-1.oraclecloud.com/n/oraclebigdatadb/b/workshop-data/o/bds-livelabs/env.sh
wget https://objectstorage.us-phoenix-1.oraclecloud.com/n/oraclebigdatadb/b/workshop-data/o/bds-livelabs/download-all-hdfs-data.sh
./download-all-hdfs-data.sh
chmod +x *.sh
Connect to the Query Server and add a new Database user – also called admin.Note – the name is case sensitive! If the name is lowercased when added as an OS user, then the database user should also be lowercased. Next, sync the hive database metadata with Query Server:
# Add a database user
# connect as sysdba to the query server
# Notice that the database username is lowercased in order to match the OS and kerberos user
sudo su - oracle
sqlplus / as sysdba
SQL> alter session set container=bdsqlusr;
Session altered.
SQL> exec dbms_bdsqs_admin.add_database_users('"admin"');
SQL> alter user "admin" identified by "your-password" account unlock;
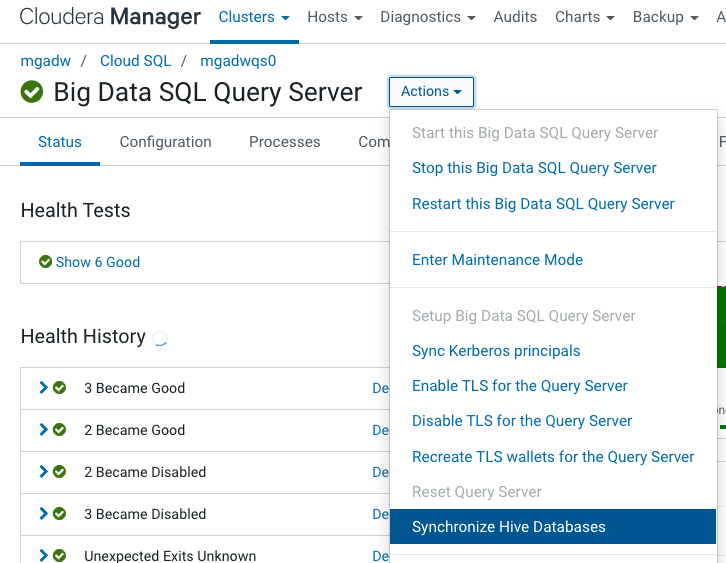
Make sure that Query Server is synchronized with Hive. From the CM Home page, select the Big Data SQL Query Server service. Next, select Synchronize Hive Databases from the Actions drop-down menu.
Accessing Query Server from Autonomous Database
Autonomous Database provides support for database links, a capability that allows queries to span multiple databases. You can use database links to query Big Data Service:
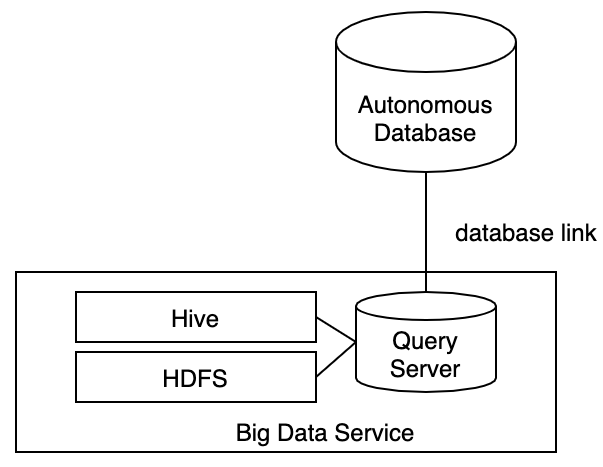
Although the query from ADB-S to Query Server is serial, the Query Server will parallelize the processing against Hadoop data – scanning, filtering and aggregating data. Only the filtered, aggregated results are returned to ADB-S.
Security Considerations
Set up the user that will authenticate ADB-S to Query Server and encrypt data traffic over the connection:
- Open port 1521 to access Query Server
- Make the Oracle wallet on Query Server available to ADB-S to enable TLS encryption
- Use DBMS_CLOUD.CREATE_CREDENTIAL to specify the user that will connect to Query Server
- Use DBMS_CLOUD_ADMIN.CREATE_DATABASE_LINK to create the connection
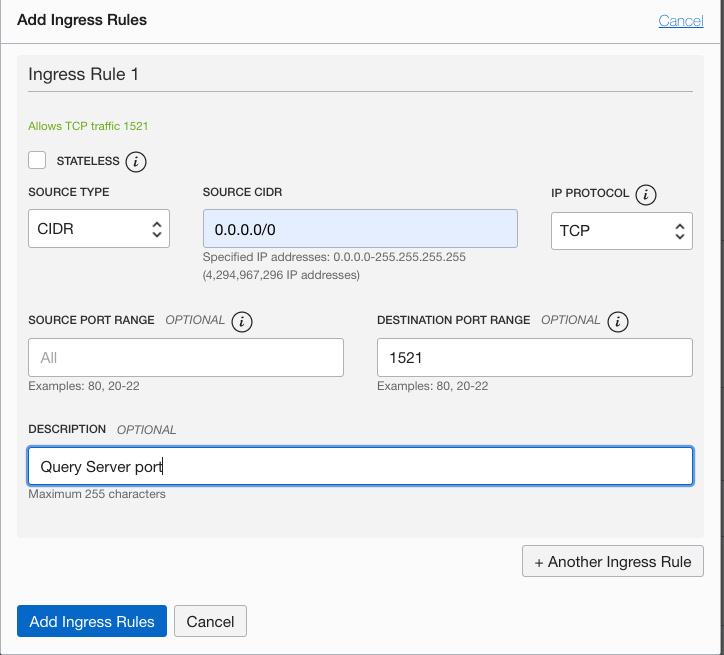
Open port 1521 to Access Query Server
In the subnet used by Big Data Service, ensure that an ingress rule is defined for port 1521:
Networking > Virtual Cloud Networks > your-network > Security List Details
Set Up Data Encryption
The connectivity between ADB-S and Query Server uses TLS encryption. You must copy the Query Server wallet to the ADB-S instance to set up the secure the connection.
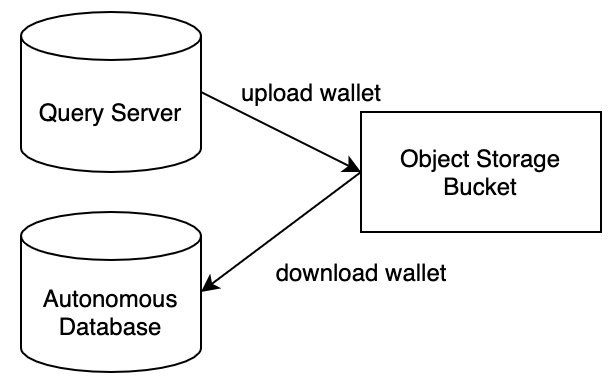
Upload the wallet file from Query Server to object storage. Then, download it to ADB-S
To copy the wallet:
- Upload the file from Query Server to an object storage bucket (we’ll call it wallet).
- Download the wallet to ADB-S.
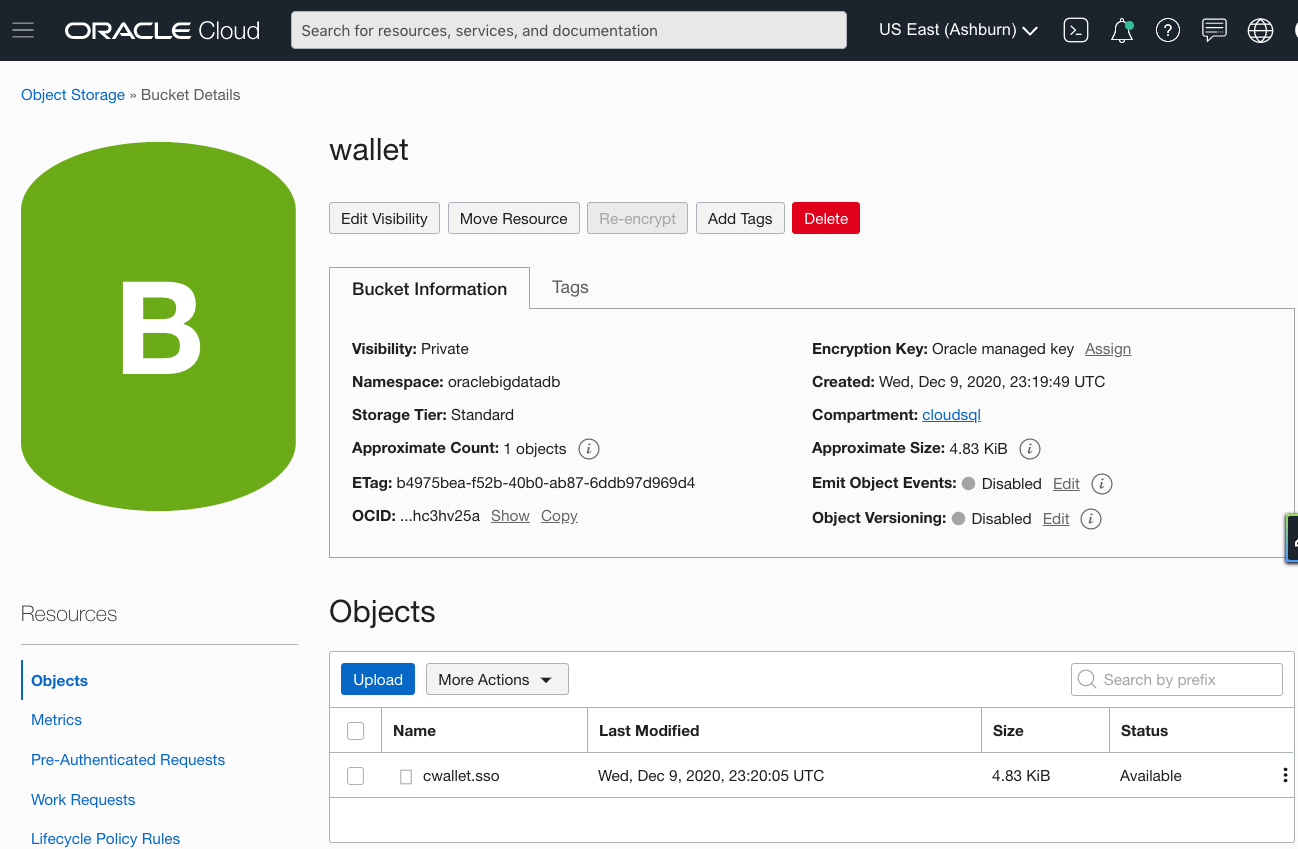
Wallet uploaded to object storage bucket called wallet
To access object storage from ADB-S create a credential. Below, the credential is using an AuthToken. After creating the credential, you can query the bucket containing the wallet file from ADB-S.
-- In ADB-S, create credential for accessing Object Storage
BEGIN
DBMS_CLOUD.CREATE_CREDENTIAL(
credential_name => 'OBJECT_STORE_CRED',
username => 'your-name',
password => 'your-password');
END;
/
-- View the contents of the wallet bucket
SELECT *
FROM DBMS_CLOUD.LIST_OBJECTS('OBJECT_STORE_CRED',
'https://objectstorage.us-ashburn-1.oraclecloud.com/n/oraclebigdatadb/b/wallet/o/');
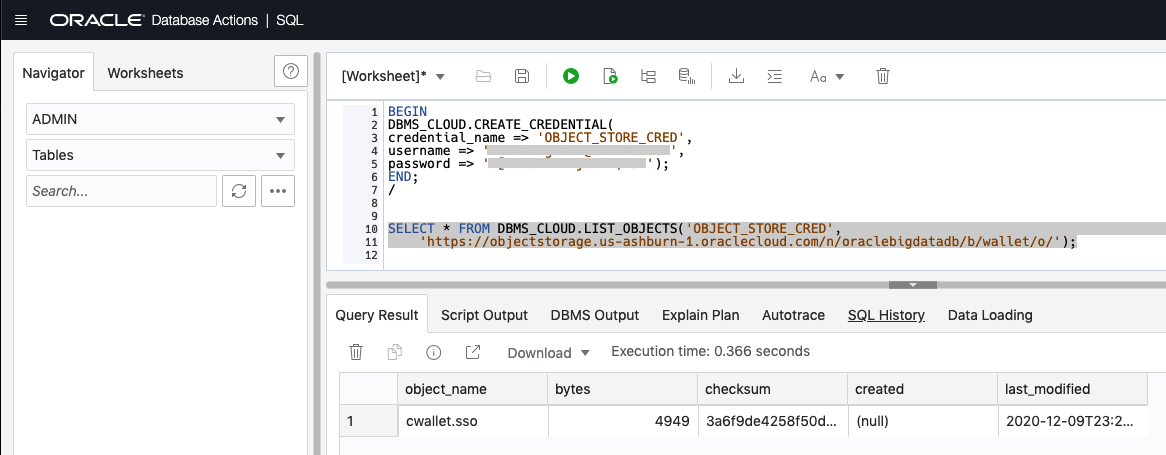
Use SQL Developer to output of the object listing in the wallet bucket
Then, create a directory to store the wallet and download the wallet to that directory. View the contents of the files in the local directory:
-- create a directory for storing the wallet
create directory QS_WALLET_DIR as 'qs_wallet_dir';
-- download the wallet from the object store
BEGIN
DBMS_CLOUD.GET_OBJECT(
credential_name => 'OBJECT_STORE_CRED',
object_uri => 'https://objectstorage.us-ashburn-1.oraclecloud.com/n/oraclebigdatadb/b/wallet/o/cwallet.ss',
directory_name => 'QS_WALLET_DIR',
file_name => 'cwallet.sso');
END;
/
show errors;
-- verify that the wallet was downloaded successfully
SELECT * FROM DBMS_CLOUD.LIST_FILES('QS_WALLET_DIR');
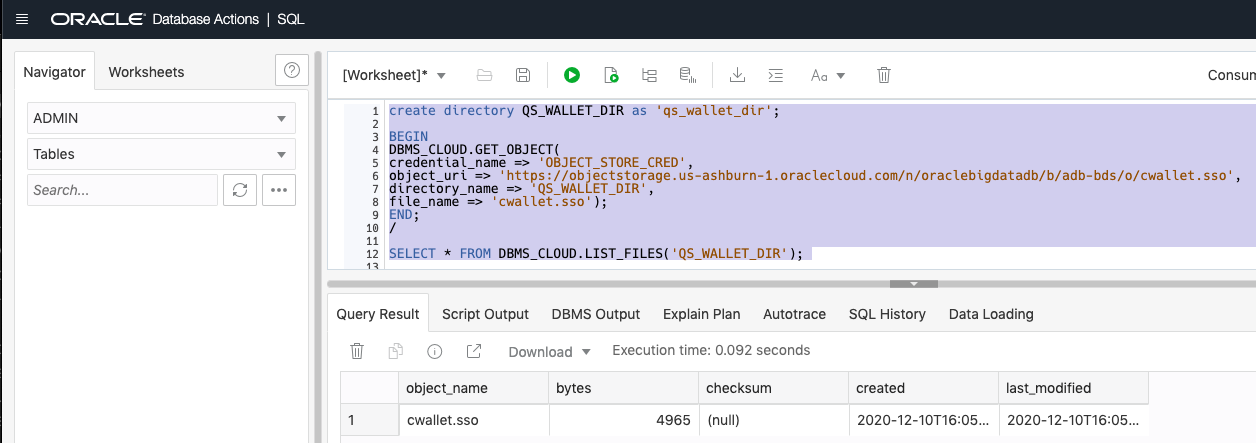
Create the Database Link
Set up the connection from ADB-S to Query Server. First, create the credential that captures the database user identity used for the connection to query server:
-- create credential
-- NOTE: The username is case sensitive.
BEGIN
DBMS_CLOUD.CREATE_CREDENTIAL(
credential_name => 'QS_CRED',
username => '"admin"',
password => 'ComplexPassword1234%');
END;
/
-- verify that the credential exists
SELECT * FROM ALL_CREDENTIALS WHERE CREDENTIAL_NAME='QS_CRED';
Then, create the Database link that use the credential. The bdsqlusr service name and the SSL distinguished name can be found at the query server node in /opt/oracle/bigdatasql/bdsqs/wallets/client/tnsnames.ora:
[oracle@mgadwqs0 ~]$ cat /opt/oracle/bigdatasql/bdsqs/wallets/client/tnsnames.ora
# tnsnames.ora Network Configuration File: /opt/oracle/bigdatasql/bdsqs/edgedb/product/199000/network/admin/tnsnames.ora
# Generated by Oracle configuration tools.
LISTENER_BDSQL =
(ADDRESS = (PROTOCOL=TCPS)(HOST = xyz.bdsdevclus01iad.oraclevcn.com)(PORT = 1521))
BDSQL =
(DESCRIPTION =
(ADDRESS = (PROTOCOL=TCPS)(HOST = xyz.bdsdevclus01iad.oraclevcn.com)(PORT = 1521))
(SECURITY=(SSL_SERVER_CERT_DN="CN=xyz.bdsadw.oraclevcn.com"))(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = xyz.bdsdevclus01iad.oraclevcn.com)
)
)
bdsqlusr=(DESCRIPTION=(ADDRESS=(PROTOCOL=TCPS)(HOST=xyz.bdsadw.oraclevcn.com)(PORT=1521))(SECURITY=(SSL_SERVER_CERT_DN="CN=xyz.bdsadw.oraclevcn.com"))(CONNECT_DATA=(SERVICE_NAME=xyz.bdsadw.oraclevcn.com)))
Use the information for the bdsqlusr entry to create the database link:
-- create database link
BEGIN
DBMS_CLOUD_ADMIN.CREATE_DATABASE_LINK(
db_link_name => 'QUERY_SERVER',
hostname => '129.159.99.999',
port => 1521,
service_name => 'xyz.bdsadw.oraclevcn.com',
ssl_server_cert_dn => 'CN=xyz.bdsadw.oraclevcn.com',
credential_name => 'QS_CRED',
directory_name => 'QS_WALLET_DIR');
END;
/
-- select the current user on the Query Server using the database link
select user from dual@query_server
USER
-----
ADMIN
Elapsed: 00:00:00.018
1 rows selected.
The database link was successful – the result of the query is showing the current database use.. You were able to connect to a Query Server on a kerberized cluster without a Kerberos client.
Run your query!
You can now query any of the tables available thru Query Server. Below, we’ll query the weather data sourced from Hive:
-- Query Weather data on Hive
select * from weather_ext@query_server where rownum < 10;
LOCATION REPORTED_DATE WIND_AVG PRECIPITATION SNOW SNOWDEPTH TEMP_MAX TEMP_MIN
------------------------- ------------- -------- ------------- ---- --------- -------- --------
NEWARK-NJ-LIBERTY-AIRPORT 2019-01-01 13 0.07 0 0 49 34
NEWARK-NJ-LIBERTY-AIRPORT 2019-01-02 7 0 0 0 39 33
NEWARK-NJ-LIBERTY-AIRPORT 2019-01-03 10 0 0 0 54 38
NEWARK-NJ-LIBERTY-AIRPORT 2019-01-04 8 0 0 0 50 32
NEWARK-NJ-LIBERTY-AIRPORT 2019-01-05 10 0.57 0 0 44 38
NEWARK-NJ-LIBERTY-AIRPORT 2019-01-06 13 0 0 0 43 26
NEWARK-NJ-LIBERTY-AIRPORT 2019-01-07 9 0 0 0 31 22
NEWARK-NJ-LIBERTY-AIRPORT 2019-01-08 2 0.13 0 0 39 30
NEWARK-NJ-LIBERTY-AIRPORT 2019-01-09 16 0.04 0 0 41 30
Elapsed: 00:00:01.098
9 rows selected.
