In this post we will show how to install and configure Oracle GoldenGate for Big Data in order to be able to receive trail files from a GoldenGate for Oracle classic architecture. Once the trail files will arrive on the machine hosting Oracle GoldenGate for Big Data we will show how to configure BigQuery handler and how to create a replication process that writes the transactions in real time from an Oracle Database to a Google BigQuery platform. There is yet another API for streaming ingestion, i.e BigQuery Job REST API, but for now we will test the BigQuery Streaming API. In the second part of this blog we will also show the “Stage and Merge” functionality that uses the aforemoentioned API.
Below you can find the architecture of the solution we are going to demonstrate.
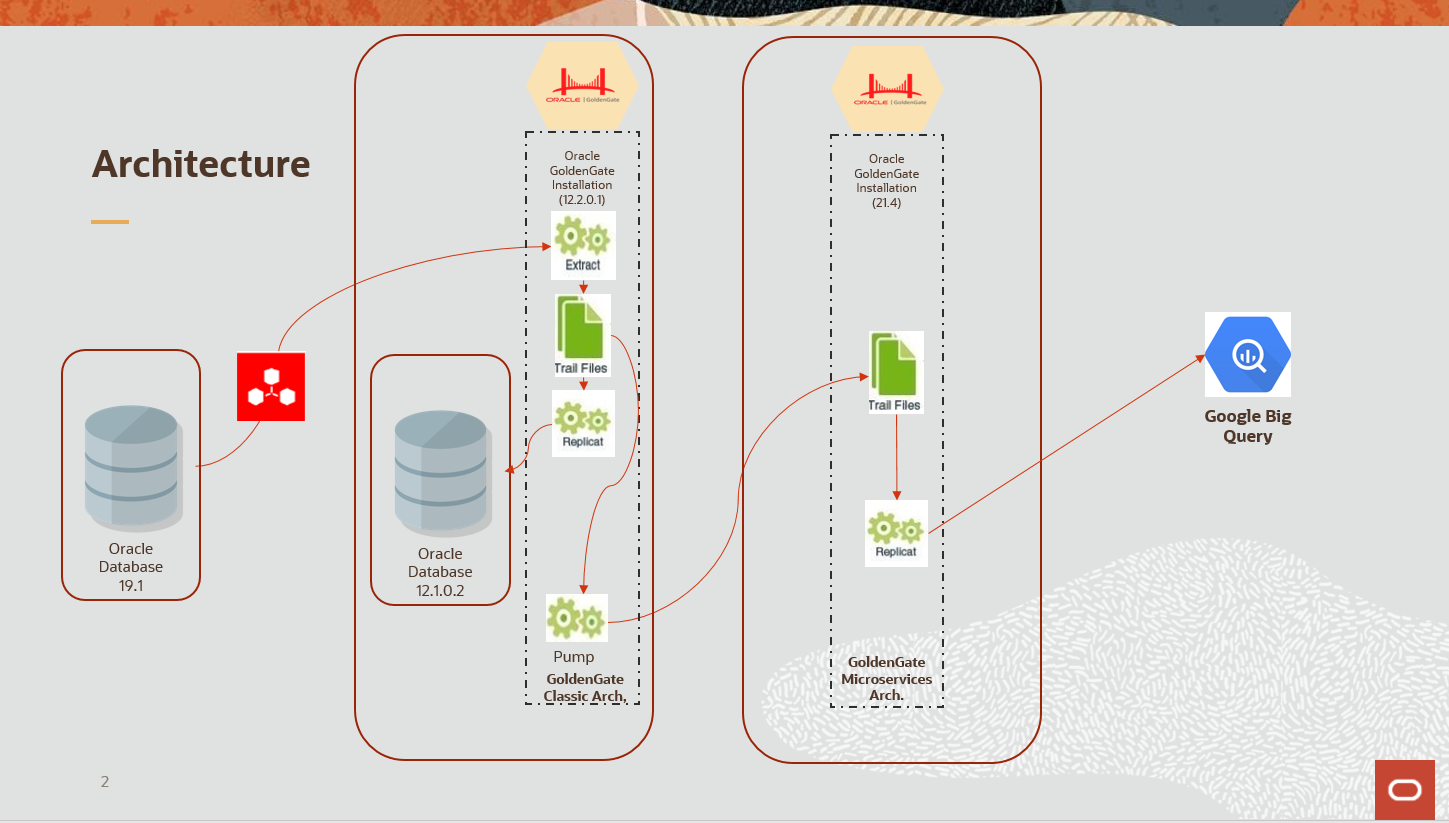
The bill of material you need to execute this architecture is the following:
- One Oracle Database used as source. We recommend using a 19c+ version of an Oracle DB.
- Two machines (VMs or Compute hosts), one for each GoldenGate installation ( classic and microservices)
- One machine to install the source database ( optional, you can install the database on the same server with the source GoldenGate distribution)
- One distribution of GoldenGate for Oracle classic architecture
- One distribution of GoldenGate for BigData Microservices architecture
- Oracle Database installation software (19c+)
- One Google Cloud account with a BigQuery Instance active
To download the required distributions of oracle software use: https://edelivery.oracle.com
The activities required in order to setup this solution are as follows:
- Source setup. Installation of Oracle Database used a s a source and the instantiation of the replicated schema ( this part is not covered by this guide but there are a lot of resources that show the creation and the population of an Oracle database).
- Target setup. Provisioning and instantiation of Google Big Query platform
- Replication software setup:
- Installation and configuration of Oracle GoldenGate core (for Oracle) – not covered in this guide. The installation guide can be found here:
-
- Installation and configuration of Oracle GoldenGate for Big Data (+ BigQuery handler configuration)
- Configuration of extraction process
- Configuration of replication process
- Configuration of the pump process (optional)
- Database instantiation. Initial load operation needed for the synchronization of all the transactions that exists in an Oracle Database before GoldenGate is installed.
- CDC synchronization setup
- Extract creation
- Pump creation
- Replicat creation
- Schema creation (in GCP). For testing purposes we will only replicate one table but the replication can be extended to an entire schema.
- Smoke test
Provisioning and instantiation of Google Big Query platform
First step is to create a Google cloud account or use your existing account to log in.
After login choose use the resource search bar to locate the required service (Big Query platform).
After the Big Query platform is open choose the already existing project or create a new one. I have create a project named “GGDemo”.
Open the project and create a new dataset in it. This dataset is the equivalent of an Oracle schema and will contain all the replicated tables.
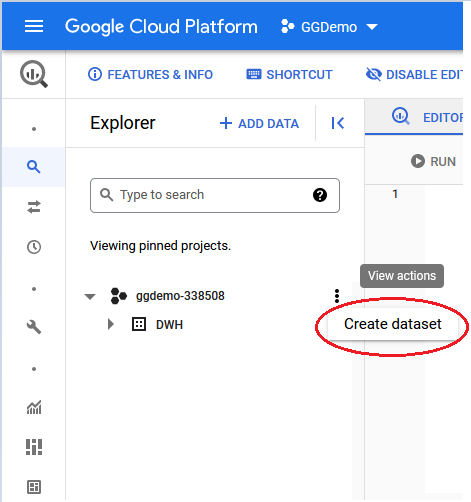
Create the structures you need for the replication. In this case I have replicated the data coming from one table named “Orders”. The query can be found in the Appendices.
Installation of Oracle GoldenGate for Big Data
Download the binaries for Oracle GoldenGate for Bug Data the latest release from edelivery.oracle.com and transfer them to the machine you have prepared to host the product.
- Login to the machine and unzip the files in the directory you have prepared, in this case I have pre-created the “/u01/Install”:
[opc@goldengate-ma Disk1]$ unzip V1018358-01.zip -d /u01/install
Navigate to /u01/install/ggs_Linux_x64_BigData_services_shiphome/Disk1 and locate the .runInstaller program.
- Execute the silent install script:
[opc@goldengate-ma Disk1]$ ./runInstaller -silent -showProgress -waitforcompletion -responseFile /home/opc/oggcore_ggbd21.3_ma.rsp
The response file I have used can be found in the Appendices section
After the execution a success message should be displayed:
Starting Oracle Universal Installer…
[…]
Finish Setup successful.
The installation of Oracle GoldenGate Services for BigData was successful.
Please check ‘/u01/app/oraInventory/logs/silentInstall2022-01-17_10-18-59AM.log’ for more details.
- As a root user, execute the following script(s):
/u01/app/oraInventory/orainstRoot.sh
The installation is now completed.
Configuration of Oracle GoldenGate for Big Data ( Microservices)
After the installation of the software, in microservices architecture we need to create the infrastructure of microservices that are responsible with the replication process.
The following will be created:
- Service Manager on port 7500. You can use any port you want.
- Administration service on port 7501
- Distribution service on port 7502
- Performance metrics service on port 7503
- Receiver service on port 7504
Note : all the port used have to be opened in the Security List for incoming traffic if you are using an OCI VCN infrastructure for the networking part. Also the firewall at the OS level has to allow TCP?IP connection on these ports.
Due to the fact that the data is coming from a classic data pump process we will not enable the SSL for this deployment.
Before creating the deployment create some standard locations :
For service manager login to the station and execute from shell:
[opc@goldengate-ma Disk1]$ mkdir -p /u01/app/oracle/gg_deployments/svmbd_ma
For the services under the service manager
[opc@goldengate-ma Disk1]$ mkdir –p /u01/app/oracle/gg_deployments/oggbd_ma
To create the deployment with all the aforementioned services enabled create a response file like the one attached in the Appendices and execute this script:
- Navigate to /u01/app/oracle/product/21.4/ggbd_ma/bin
[opc@goldengate-ma bin]$ cd /u01/app/oracle/product/21.4/ggbd_ma/bin
- Using the response file execute the script below. The response file can be found in the Appendices:
[opc@goldengate-ma bin]$ ./oggca.sh -silent –responseFile /home/opc/oggcore_ggbd21.3_ma_dep01.rsp
If the execution has completed with no errors the following message should be received:
Successfully Setup Software.
- In order to open the ports in the firewall of the station where the deployment has been instantiated use sudo command from your user if possible, otherwise run it without sudo from the root user itself:
[opc@goldengate-ma bin]$ sudo firewall-cmd –zone=public –add-port=7501-7505/tcp –permanent
[opc@goldengate-ma bin]$ sudo firewall-cmd –reload
- If the hosts are in cloud open the ports also from the security lists of your virtual network.
- Once created the service manager can be started and stopped using the followings scripts:
./startSM.sh
./ stopSM.sh
Scripts are located in the service manager home directory defined in the response file, under the bin subdirectory: /u01/app/oracle/gg_deployments/svmbd_ma/bin
Reverse proxy configuration
Reverse Proxy allows a single point of contact for various microservices associated with an Oracle GoldenGate Microservices Architecture deployment. You can configure a proxy server depending on your environment setup and network requirements.
You can configure Oracle GoldenGate Microservices Architecture to use a reverse proxy. Oracle GoldenGate MA includes a script called ReverseProxySettings that generates configuration file for only the NGINX reverse proxy server.
For example, the Administration Server is available on HTTPS://goldengate.example.com:9001 and the Distribution Server is on HTTPS://goldengate.example.com:9002. With reverse proxy, each of the microservices can simply be accessed from the single address. For example, https://goldengate.example.com/distsrvr for the Distribution Server.
To download and configure the NGINX follow the steps below. All the command are executed in shell script at the OS level of the host holding the GG for Big Data deployment:
- Download the software
[opc@goldengate-ma bin]$ sudo yum -y install nginx
- Navigate to the location of ./ReverseProxySettings script
[opc@goldengate-ma bin]$ cd /u01/app/oracle/product/21.4/ggbd_ma/lib/utl/reverseproxy
- Execute the following script to create a configuration file names ogg.congf. The name is at choice. Do not forget to replace the password with your own.
[opc@goldengate-ma bin]$ ./ReverseProxySettings -u oggadmin -P <your password> ogg.conf https://localhost:7500
- Place the configuration file in the NGINX conf.d directory:
[opc@goldengate-ma bin]$ sudo cp ogg.conf /etc/nginx/conf.d/nginx.conf
- Generate a certificate for the proxy server
[opc@goldengate-ma bin]$ sudo sh /etc/ssl/certs/make-dummy-cert /etc/nginx/ogg.pem
- Start or reload the NGINX server:
[opc@goldengate-ma bin]$ sudo nginx
[opc@goldengate-ma bin]$ sudo nginx –t
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
[opc@goldengate-ma bin]$ sudo nginx -s reload
- If not open already open the port 443 in the firewall
[opc@goldengate-ma bin]$ sudo firewall-cmd –zone=public –add-port=443/tcp –permanent
[opc@goldengate-ma bin]$ sudo firewall-cmd –reload
- You should be ready to connect to the newly deployed GoldenGate Microservices platform using the browser:
Error! Hyperlink reference not valid. or IP adress>/?root=account
The following login page should appear:
Enter the user and password you have defined in the response when you have created the deployment and click Sign in.
You should be able to see the home screen. From this screen you can visualize the services and their status and also navigate to each of the service you need.
Dependency configuration for Google Cloud Platform – Big Query handler
Starting with 21.3 Oracle GoldenGate comes with a dependency downloader that aims to simplify the complex task of installing libraries and solving dependencies for various technologies for which a handler will be configures in GoldenGate for Big Data.
There is a very nice blog post from Sydney Nurse on this topic:
In order to install the libraries for Google Big Query follow the steps:
- Navigate to {OGGBD install}/DependencyDownloader
[opc@goldengate-ma ~]$ cd /u01/app/oracle/product/21.4/ggbd_ma/opt/DependencyDownloader
- Execute the ./bigquery.sh script followed by the version of the libraries you wish to download
[opc@goldengate-ma DependencyDownloader]$ ./bigquery.sh 1.135.4
If the installation fails check the java location or set the bash_profile as follows:
[opc@goldengate-ma ~]$ cat .bash_profile
# .bash_profile
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
export JAVA_HOME=/u01/app/oracle/product/21.4/ggbd_ma/jdk
export OGG_HOME=/u01/app/oracle/product/21.4/ggbd_ma
export LD_LIBRARY_PATH=$JAVA_HOME/jre/lib/amd64/server
PATH=$JAVA_HOME/bin:$OGG_HOME:$PATH:$HOME/.local/bin:$HOME/bin
export PATH
After the execution of the script the output should render the result of the installation. An excerpt from the message I have received has been attached for example:
java version “1.8.0_291”
Java is installed.
Apache Maven 3.8.2 (ea98e05a04480131370aa0c110b8c54cf726c06f)
Maven is accessible.
Root Configuration Script
INFO: This is the Maven binary [../../ggjava/maven/bin/mvn].
INFO: This is the location of the settings.xml file [./docs/settings_np.xml].
INFO: This is the location of the toolchains.xml file [./docs/toolchains.xml].
INFO: The dependencies will be written to the following directory[../dependencies/bigquery_1.135.4].
INFO: The Maven coordinates are the following:
INFO: Group ID [com.google.cloud].
INFO: Artifact ID [google-cloud-bigquery].
INFO: Version [1.135.4]
[INFO] Scanning for projects…
[INFO] —————< oracle.goldengate:dependencyDownloader >—————
[INFO] Building dependencyDownloader 1.0
[INFO] ——————————–[ pom ]———————————
Downloading from central: https://repo.maven.apache.org/maven2/org/apache/maven/plugins/maven-clean-plugin/2.5/maven-clean-plugin-2.5.pom
[INFO] Copying gax-1.66.0.jar to /u01/app/oracle/product/21.4/ggbd_ma/opt/DependencyDownloader/dependencies/bigquery_1.135.4/gax-1.66.0.jar
[INFO] Copying google-http-client-gson-1.39.2.jar to /u01/app/oracle/product/21.4/ggbd_ma/opt/DependencyDownloader/dependencies/bigquery_1.135.4/google-http-client-gson-1.39.2.jar
[INFO] ————————————————————————
[INFO] BUILD SUCCESS
[INFO] ————————————————————————
[INFO] Total time: 16.047 s
[INFO] Finished at: 2022-01-24T13:18:33Z
[INFO] ————————————————————————
The gg.classpath parameter that needs to be configured as part of the java adapter for big data repplication has to point to the location where all the dependencies have been downloaded. In this case:
gg.classpath=/u01/app/oracle/product/21.4/ggbd_ma/opt/DependencyDownloader/dependencies/bigquery_1.135.4/*
Replication process configuration ( Audit Log Mode = false)
To configure the replication process we can use the browser based UI, the AdminClient utility or a cli client that has permissions to access the GoldenGate microservices deployment (i.e the admin service).
To create the process using the UI console open the browser and navigate to the address of the GG Service Manager like indicated above. Access the Administration Service by clicking its port number:
Once the Administration Service login window opens fill in the credentials and login.
Once the service UI opens click the plus sign in order to create a new Replicat:

Choose the classic Replicat or Coordinated replicat and click next:
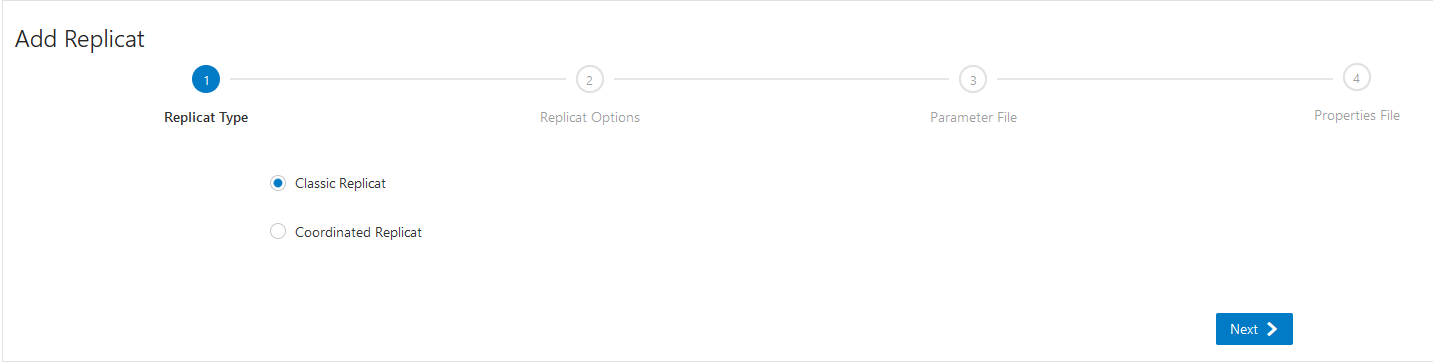
Fill in the following details:
Process Name: RBCP -> this fiels is mandatory and has to have at most five characters
Description: this is optional and can be left blanc
Source: Trail
Trail Subdirectory: can be left default. It will take the trais from the location of OGG_DATA_HOME specified in the response file.
Begin: You can choose where to start reading the trail from . In this case choose “Position in Trail”
Trail Sequence Number: 0 -> this indicates that you start from the first SCN in the trail
Trail RBA Offset: 0 -> read from the first RBA. Set no offset
Target: Choose Google Big Query from the dropdown list
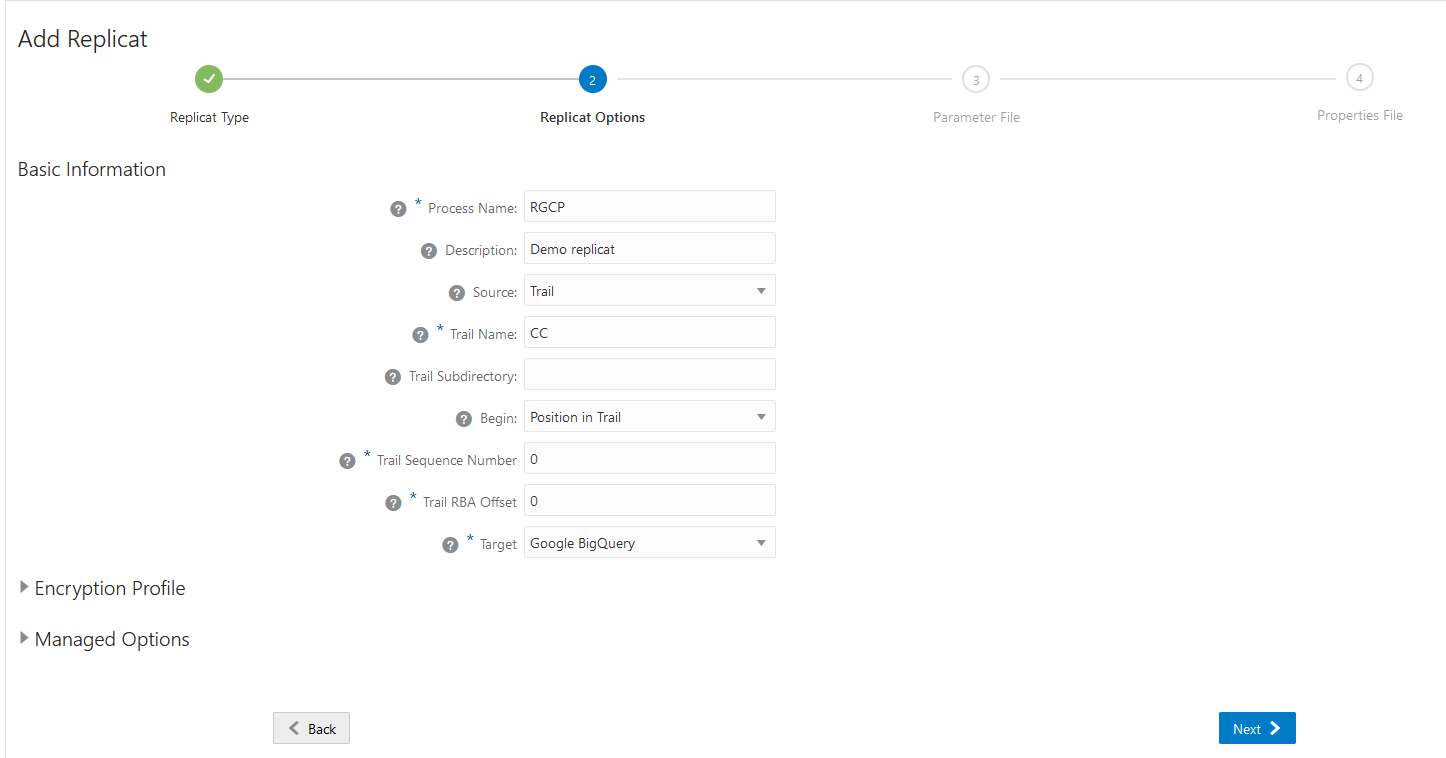
Optionally you can set also other details related to security and management options. Once you finished setting the parameters click Next.
Fill in the parameter file will all the required parameters. At minimum I have used a one to one mapping between table Orders coming from source schema Car_store and going to target data store DWH in Google Big Query.
REPLICAT repBQ
MAP car_store.orders, TARGET “DWH”.”Orders”;
Click Next to fill in the last page, the Properties file used by the Google Big Query handler.
First, a template for Google Big Query gets displayed. Fill in the details from the properties files attached in the Appendices.
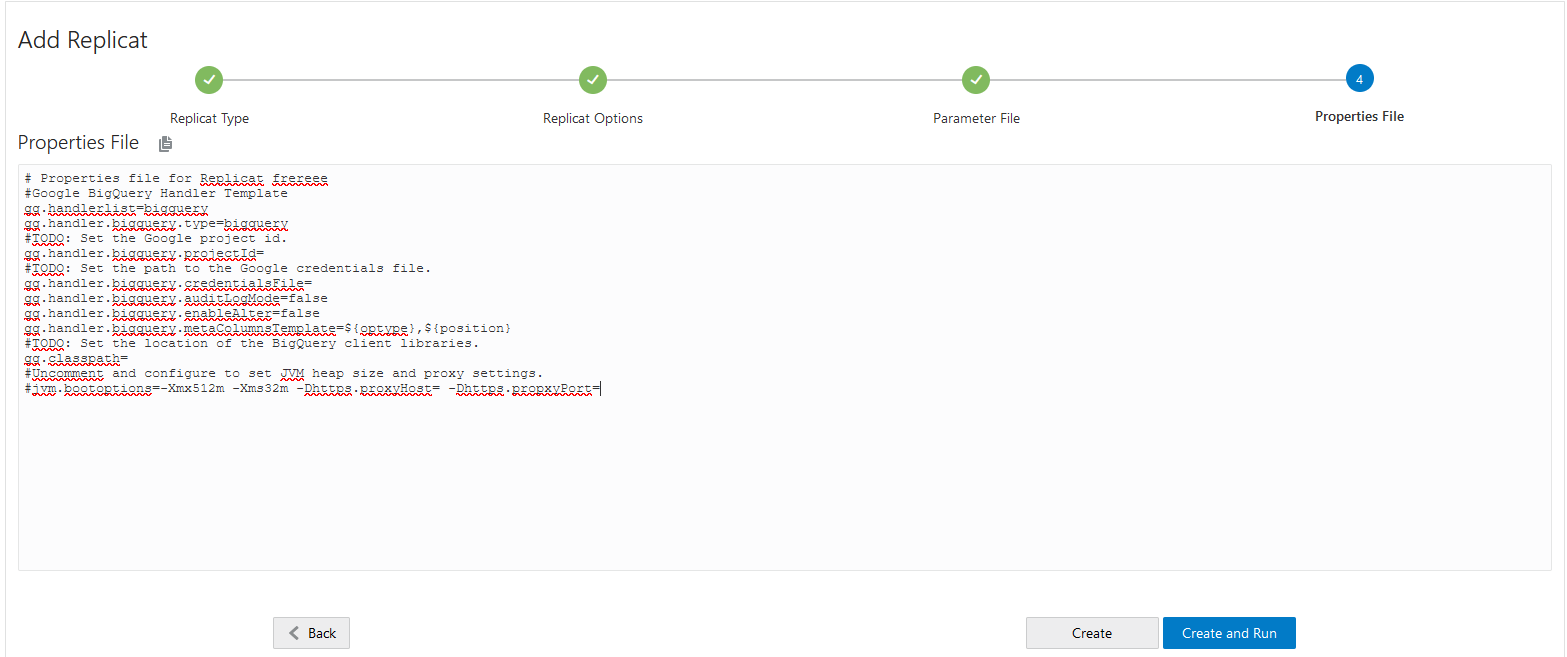
Click Create to create the process. Do not run it yet as we still need to create the extractor and the pump process.
What is outstanding here is the method used for authenticating against Big Query API. The authentication is done using a JSON file we have to create and download from Google Cloud Platform. We will show the process in detail in the next section.
You can configure the BigQuery Handler in two ways:
- Audit Log Mode = false
When the handler is configured to run with audit log mode false, the data is pushed into Google BigQuery using a unique row identification key. The Google BigQuery is able to merge different operations for the same row. However, the behavior is complex. The Google BigQuery maintains a finite deduplication period in which it will merge operations for a given row. Therefore, the results can be somewhat non-deterministic.
The trail source needs to have a full image of the records in order to merge correctly.
Example 1:
An insert operation is sent to BigQuery and before the deduplication period expires, an update operation for the same row is sent to BigQuery. The resultant is a single row in BigQuery for the update operation.
Example 2
An insert operation is sent to BigQuery and after the deduplication period expires, an update operation for the same row is sent to BigQuery. The resultant is that both the insert and the update operations show up in BigQuery.
This behavior has confounded many users, as this is the documented behavior when using the BigQuery SDK and a feature as opposed to a defect. The documented length of the deduplication period is at least one minute. However, Oracle testing has shown that the period is significantly longer. Therefore, unless users can guarantee that all operations for a give row occur within a very short period, it is likely there will be multiple entries for a given row in BigQuery. It is therefore just as important for users to configure meta columns with the optype and position so they can determine the latest state for a given row. To read more about audit log mode read the following Google BigQuery documentation:Streaming data into BigQuery.
Setting the Audit log mode to false should render the following behaviour.
As per my tests the behaviour is not totally true for updates. Another row is inserted for each update ( sometimes even two updates are merge if they are issued within the same deduplication period). My conclusion is that setting the audit log mode to false can render false results because of the API streaming interface used by BigQuery.
auditLogMode = false
insert – If the row does not already exist in Google BigQuery, then an insert operation is processed as an insert. If the row already exists in Google BigQuery, then an insert operation is processed as an update. The handler sets the deleted column to false.
update –If a row does not exist in Google BigQuery, then an update operation is processed as an insert. If the row already exists in Google BigQuery, then an update operation is processed as update. The handler sets the deleted column to false.
delete – If the row does not exist in Google BigQuery, then a delete operation has no effect. If the row exists in Google BigQuery, then a delete operation is processed as a delete. The handler sets the deleted column to true.
pkUpdate—When pkUpdateHandling property is configured as delete-insert, the handler sets the deleted column to true for the row whose primary key is updated. It is followed by a separate insert operation with the new primary key and the deleted column set to false for this row.
- Audit Log Mode = true
gg.handler.name.auditLogMode=true
When the handler is configured to run with audit log mode true, the data is pushed into Google BigQuery without a unique row identification key. As a result, Google BigQuery is not able to merge different operations on the same row. For example, a source row with an insert operation, two update operations, and then a delete operation would show up in BigQuery as four rows, one for each operation.
Also, the order in which the audit log is displayed in the BigQuery data set is not deterministic.
To overcome these limitations, users should specify optype and postion in the meta columns template for the handler. This adds two columns of the same names in the schema for the table in Google BigQuery. For example: gg.handler.bigquery.metaColumnsTemplate = ${optype}, ${position}
The optype is important to determine the operation type for the row in the audit log.
Configuring Handler Authentication
You have to configure the BigQuery Handler authentication using the credentials in the JSON file downloaded from Google BigQuery. Follow the steps below to get the file from Google BigQuery:
- Login into your Google account at cloud.google.com.
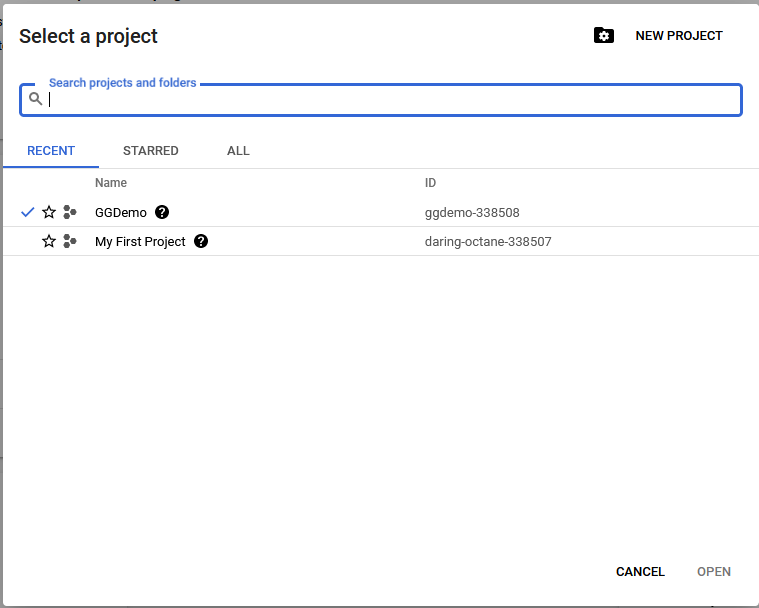
- Click Console and then go to the Dashboard and select your project.
- I have selected my project GGDemo:
- Click API & Services and choose Big Query API:
- Go to Credentials tab (figured by a small key) and click Create Credentials:
- Choose Service Account:
- Fill in the Name, Description and grant access to your project.
- Once created click Keys and create a key:
- Add a JSON Key

- Download and store this key securely.
Configuring the extraction
Preparing the source database ( Oracle) for the extraction
Login to the database server host and log to the database server (at CDB level in case the database is multitenant)
If the database is already in ARCHIVELOG mode go to the next step. Otherwise run:
SQL> shutdown immediate
SQL> startup mount
SQL> alter database archivelog;
SQL> alter database open;
SQL> select name, db_unique_name,log_mode from v$database;
Check if the replication is active. In case the result is false, activate it
SQL > select * from v$parameter where name = ‘enable_goldengate_replication’;
SQL > alter system set enable_goldengate_replication = true scope=both;
If you are using integrated extract and integrated replicat size the memory needed for the logmining server (for extract) and inbound server (for replicat). By default, one integrated capture Extract requests the logmining server to run with MAX_SGA_SIZE of 1GB. Thus, if you are running three Extracts in integrated capture mode in the same database instance, you need at least 3 GB of memory allocated to the Streams pool. As a best practice, keep 25 percent of the Streams pool available. For example, if there are 3 Extracts in integrated capture mode, set STREAMS_POOL_SIZE for the database to the following value:
3 GB * 1.25 = 3.75 GB
Configure minimum supplemental logging at the database level:
SQL> ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;
Create the user used by Oracle GoldenGate for extraction
SQL> create user C##OGGADMIN identified by <Your_password> default tablespace users;
Grant the following rights to this user:
SQL> grant create session, resource, alter system to C##OGGADMIN container=ALL;
[optional]SQL> GRANT SELECT ANY TRANSACTION TO C##OGGADMIN CONTAINER=ALL;
[optional]SQL > GRANT SELECT ANY DICTIONARY TO C##OGGADMIN CONTAINER=ALL;
[optional]SQL> GRANT FLASHBACK ANY TABLE TO C##OGGADMIN CONTAINER=ALL;
SQL > exec dbms_goldengate_auth.grant_admin_privilege(‘C##OGGADMIN’,container=>’ALL’);
Create the source table orders. The code can be found under paragraph one in the Appendices.
Creation of extraction process
Connect to the machine where Oracle GoldenGate Core ( for Oracle) resides. Log into the ggsci console and add the credential keys for the user created above in the source database.
GGSCI >> alter credentialstore add user <username>@<database_service> password <your_password> alias oggadmin domain OracleGoldenGate;
Example: alter credentialstore add user oggadmin@srcorcl password Demo12345# alias srcoggadmin domain OracleGoldenGate;
In order for the user to be able to connect you need to write the service details in the tnsnames.ora file from the Oracle client that resides on the GoldenGate machine. In my case I have added this service for example:
SRCORCL =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.0.6)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = ORCL)
)
)
Login to database from ggsci console and issue add trandata for the table that is in the scope of the replication:
GGSCI (ogg19cora) 1> dblogin useridalias srcoggadmin
Successfully logged into database.
GGSCI (ogg19cora as oggadmin@ORCL) 2> add trandata car_store.orders
Create the extract parameter file:
EXTRACT eorcl
USERIDALIAS srcoggadmin
LOGALLSUPCOLS
EXTTRAIL ./dirdat/es
–DDL INCLUDE ALL
TABLE car_store.orders;
Register the extract with the database by issuing the following command:
GGSCI>> register extract eorcl, database
Add the extract to the manager and associate it with the trail file to write the transactions in
GGSCI>> add extract eorcl, integrated tranlog, begin now
GGSCI>> add exttrail ./dirdat/es, extract eorcl
Creation of the pump process
The pump process is responsible of transferring the trail files over the network, possibly encrypted, to the host where GoldenGate for Big Data will have the replication process reading them and writing the data to BigQuery.
Create the parameter file as follows:
EXTRACT dpgcp
RMTHOST 192.168.0.85, PORT 7503
RMTTRAIL dp
PASSTHRU
table car_store.orders;
The port specified is the port of the receiver service from the GoldenGate for BigData platform. Because the classic pump cannot use TLS/mTLS for the communication the port used is directly the port used by the service itself and not port 443 that we have used to configure the reversed proxy.
Add the pump process:
GGSCI>> add extract dpgcp, exttrailsource ./dirdat/es
Set the remote trail path for GoldenGate for Big data and associate it with the pump process:
GGSCI>> add rmttrail dp, extract dpgcp
Smoke Test
Scenario 1:
For the first test we have configured the audit_log_mode to true. Also two metacolumns have been included in the table definition, op_type and position ( as of position in trail). The configuration parameters used:
gg.handler.bigquery.auditLogMode=true
gg.handler.bigquery.enableAlter=false
gg.handler.bigquery.metaColumnsTemplate=${optype},${position}
We have inserted 17 rows using a script in the source database ( Oracle Database). Then we have issued a delete where order_id=17.
Oracle Database:
SQL> select * from orders order by order_id;
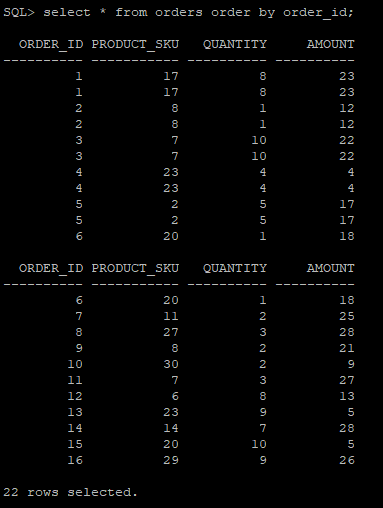
The output in Google Big Query is the following:
We have used also the unique identifier appended by Big Query for every row in our query:
SELECT *,row_number() over (order by order_id) as Entry_Key FROM `ggdemo-338508.DWH.Orders`
| Row |
optype |
position |
ORDER_ID |
product_sku |
quantity |
amount |
Entry_Key |
| 1 |
I |
00000000000000002075 |
1 |
17 |
8 |
23 |
1 |
| 2 |
I |
00000000000000002245 |
2 |
8 |
1 |
12 |
2 |
| 3 |
I |
00000000000000002414 |
3 |
7 |
10 |
22 |
3 |
| 4 |
I |
00000000000000002581 |
4 |
23 |
4 |
4 |
4 |
| 5 |
I |
00000000000000002748 |
5 |
2 |
5 |
17 |
5 |
| 6 |
I |
00000000000000002915 |
6 |
20 |
1 |
18 |
6 |
| 7 |
I |
00000000000000003082 |
7 |
11 |
2 |
25 |
7 |
| 8 |
I |
00000000000000003249 |
8 |
27 |
3 |
28 |
8 |
| 9 |
I |
00000000000000003417 |
9 |
8 |
2 |
21 |
9 |
| 10 |
I |
00000000000000003583 |
10 |
30 |
2 |
9 |
10 |
| 11 |
I |
00000000000000003750 |
11 |
7 |
3 |
27 |
11 |
| 12 |
I |
00000000000000003919 |
12 |
6 |
8 |
13 |
12 |
| 13 |
I |
00000000000000004085 |
13 |
23 |
9 |
5 |
13 |
| 14 |
I |
00000000000000004252 |
14 |
14 |
7 |
28 |
14 |
| 15 |
I |
00000000000000004419 |
15 |
20 |
10 |
5 |
15 |
| 16 |
I |
00000000000000004586 |
16 |
29 |
9 |
26 |
16 |
| 17 |
I |
00000000000000004753 |
17 |
26 |
6 |
16 |
17 |
| 18 |
D |
00000000000000005088 |
17 |
26 |
6 |
16 |
18 |
| 19 |
I |
00000000000000005088 |
17 |
26 |
6 |
20 |
19 |
The outcome reveals the fact that we have two operations with the same position in trail ( because the delete in the trail is one operation but in Big Query that is transferred to a insert and a delete. This can be problematic because the last version of the row cannot be found out unless we introduce a new metadata filed with the insertion timestamp:
$currenttimestampiso8601 [targettimestamp]
Scenario 2:
For the second test we have used another table in the source database ( Appendices script number 2) and a table for the target side ( Appendices script number 3). We have changed the following parameter :
gg.handler.bigquery.auditLogMode=false
gg.handler.bigquery.enableAlter=true
gg.handler.bigquery.includeDeletedColumn=true
we have eliminated the metacolumns:
gg.handler.bigquery.metaColumnsTemplate=${optype},${position}
We have created another replicat :
REPLICAT repgc
MAP gcp_src.product_hierarchy, TARGET “DWH”.”Product_hierarchy” keycols (product_code);
The difference from the first test is that we have set the audit log mode to false , we have enabled the capability of creating DDL on the target table and also we have enabled “Deleted colum” to be created on the target table for the processing of I/U/D opperations with audit log mode = false.
We have done the following operations on the source:
INSERT INTO product_hierarchy VALUES (1,NULL, 10,’Wood’);
INSERT INTO product_hierarchy VALUES (2,1, 100,’Wood for deck’);
INSERT INTO product_hierarchy VALUES (3,1, 300,’Wooden door’);
INSERT INTO product_hierarchy VALUES (100,NULL,NULL,’Steel’);
INSERT INTO product_hierarchy VALUES (4,100,50,’Steel Door’);
INSERT INTO product_hierarchy VALUES (5,100,500,’Armour coating’);
INSERT INTO product_hierarchy VALUES (6,100,10,’Double door’);
INSERT INTO product_hierarchy VALUES (7,100,10,’Test Update’);
UPDATE product_hierarchy SET product_description =’Real Description’ where product_code=7;
update product_hierarchy set PRODUCT_DESCRIPTION=’Test allcols 3′ where PRODUCT_CODE=6;
commit;
update product_hierarchy set PRODUCT_DESCRIPTION=’Test allcols 4′ where PRODUCT_CODE=6;
commit;
update product_hierarchy set PRODUCT_DESCRIPTION=’Test allcols 5′ where PRODUCT_CODE=6;
ALTER TABLE product_hierarchy add column Notes VARCHAR2(200);
INSERT INTO product_hierarchy VALUES (8,1,80,’Wooden cob’,’Not released’);
update product_hierarchy set Notes=’Released’ where PRODUCT_CODE=8;
commit;
update product_hierarchy set PRODUCT_DESCRIPTION=’Test allcols 4′ where PRODUCT_CODE=6;
commit;
On the source we have the following data set. We have filtered the amount_in_warehouse because we have used also a filter statement in the pump parameter file:

On the GCP target we have executed the following SQL to reveal the status of the table:
SELECT *, row_number() over (order by product_code) as Entry_Key FROM `ggdemo-338508.DWH.Product_hierarchy`
| Row |
product_code |
parent_product_code |
amount_in_warehouse |
product_description |
deleted |
NOTES |
Entry_Key |
| 1 |
4 |
100 |
50 |
Steel Door |
null |
null |
1 |
| 2 |
6 |
100 |
10 |
Double door |
null |
null |
2 |
| 3 |
6 |
100 |
10 |
Test allcols |
false |
null |
3 |
| 4 |
6 |
100 |
10 |
Test allcols 2 |
false |
null |
4 |
| 5 |
6 |
100 |
10 |
Test allcols 3 |
false |
null |
5 |
| 6 |
6 |
100 |
10 |
Test allcols 4 |
false |
null |
6 |
| 7 |
6 |
100 |
10 |
Test allcols 5 |
false |
null |
7 |
| 8 |
7 |
100 |
10 |
Test Update |
null |
null |
8 |
| 9 |
7 |
100 |
10 |
Test allcols |
null |
null |
9 |
| 10 |
7 |
100 |
10 |
Test allcols BQ |
null |
null |
10 |
| 11 |
7 |
100 |
10 |
Test allcols BQ 2 |
null |
null |
11 |
| 12 |
7 |
100 |
10 |
Test allcols BQ 2 |
true |
null |
12 |
| 13 |
8 |
1 |
80 |
Wooden cob |
false |
Not released |
13 |
| 14 |
8 |
1 |
80 |
Wooden cob |
false |
Released |
14 |
| 14 |
8 |
1 |
80 |
Wooden cob |
false |
Version 2 |
14 |
We have tested chronologically a couple of inserts (the first product ID was inserted before the extract process has been started so we have not inserted in it the target) with id 4, 6 and 7. Then we have performed some updates on products 6 and 7. At a specific point we have added :
gg.handler.bigquery.enableAlter=true
together with
gg.handler.bigquery.includeDeletedColumn=true
After adding the below parameters a new column has been added “deleted”. For the rows inserted prior to the enablement this value is automatically set to null.
At a point in time we have deleted product 7. In Google BigQuery the product is not deleted but the “deteled” column is set to true.
All the updates have not actually been treated as updates. But they have been inserted as new rows with the modified column plus a deleted flag set to false. It is impossible to know the order of the operations can only be tracked using the row_number function.
Also in the second test we added a column “notes” that has been replicated successfully.
Conclusions:
Google BigQuery uses the streaming API to stream data in real time. Oracle GoldenGate uses Big Query handler to interact with this API. Note that using audit log mode false may render unexpected results due to deduplication period. Also there is no other way to track the order of the results rather than using row_number analytical function over the primary key of the table, logically declared as BQ does not support primary keys.
It seems like using audit log true together with metacolumns and local apply timestamp gives the best results with the possibility of using the timestamp to filter the latest version of a row based on operation type and position in trail file.
The DDL operations are supported unidirectional.
Oracle has just release Oracle GoldenGate for Big Data 21.5 ( see the announcement made by product management here). Among other great new features like Autonomous JSON Database (AJD) Delivery, Mongo DB Capture we have also Google BigQuery Stage & Merge.
BigQuery Stage & Merge uses stage and merge data flow to ingest data into Google Cloud Platform BigQuery. The changed data is staged in Google Cloud Storage (GCS) buckets temporarily and merged into target tables in micro batches.
In the second part of this blog we will see how stage and merge works and what are the differences between the ingestion with BigQuery Streaming API (presented in this first part) and BigQuery job API used by “Stage and Merge” data flow in Oracle GoldenGate for Big Data.
