Oracle Cloud Infrastructure (OCI) Data Integration is a fully managed, serverless, native cloud service that helps you with common extract, load, and transform (ETL) tasks. These tasks include ingesting data from various sources, cleansing, transforming, and reshaping that data, and then efficiently loading it to target data sources on OCI. A main feature in an ETL includes loading the incremental data from different source systems. Incremental load loads only new or updated records from the source systems into the target systems. Incremental loads are useful because they run efficiently when compared to full loads, particularly for large data sets.
You can achieve an incremental load in several ways. You can use change-data-capture (CDC) tools, such as Oracle GoldenGate, use audit dates and apply filter conditions, use triggers, or compare sources and targets. The following method compares the sources and the target to get the incremental data using OCI Data Integration. To get the incremental data in this example, we load from different tables and do a full outer join at the end with the target table. Also in this example, to maintain history we identify the logical deletes by deleting what happened on the source side and maintain the delete flag in the target.
Prerequisites
- Based on the previous blogs on Oracle Cloud Infrastructure Data Integration and Oracle Documentation, you should have set up a workspace, projects, and applications and understand the creation and execution of a data flow using an integration task.
- Corresponding data assets, such as sources and targets, have been defined in the workspace.
- If you’re using the Autonomous Data Warehouse schema as the target, you need the necessary DBMS_CLOUD privilege.
In this example, we use the following source and target tables:
- Employees
- Departments
- Jobs
- Employee_Details
The tables used in this example are from the HR schema and can be referred from Oracle livesql
Mapping of target table – Employee_Details:
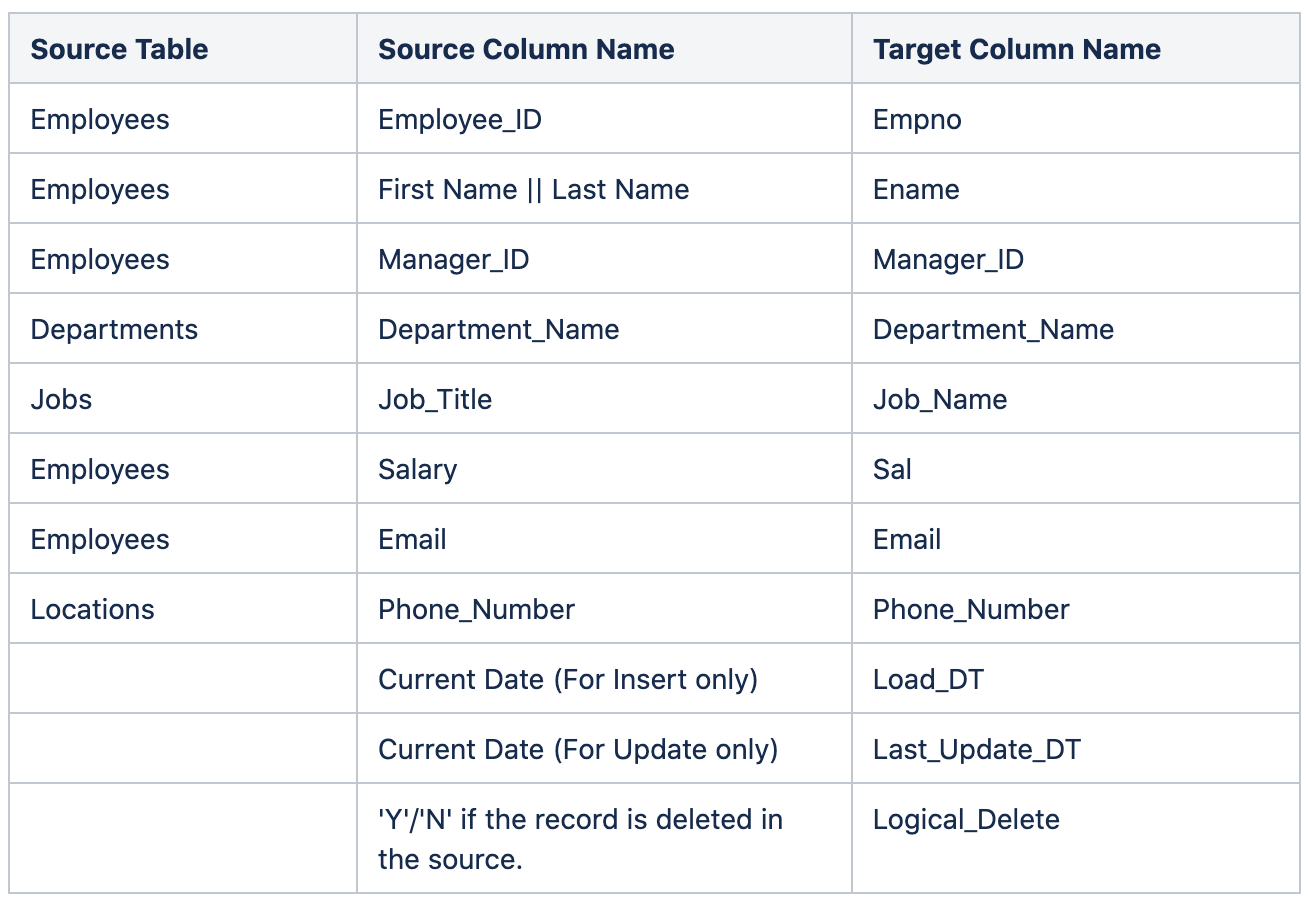
DDL for Employee_Details –
CREATE TABLE EMPLOYEE_DETAILS ( EMPNO NUMBER(10,0), MANAGER_ID NUMBER(10,0), DEPARTMENT_NAME VARCHAR2(255), ENAME VARCHAR2(255), JOB_NAME VARCHAR2(255), SAL NUMBER(10,0), EMAIL VARCHAR2(255), PHONE_NUMBER VARCHAR2(255), LOAD_DT DATE, LAST_UPDATE_DT DATE, LOGICAL_DELETE VARCHAR2(1), PRIMARY KEY (EMPNO) );
Implementation
The following graphic shows the data flow implemented in OCI Data Integration. Here, with the help of full outer join, we compare the source and target records and filter only the changed records. This process gives us the incremental data from the sources.

The following screenshot shows the join and filter conditions used for the current example. With a full outer join between the source tables and the target table, you can identify all rows that were either inserted or deleted in the source table since the last load and all existing rows that differ in at least one column.

One method to handle null values is the usage of the NVL function. When a column is null, a default value is returned instead. The default values should use constants that don’t exist in the table.
NVL(FILTER_1.EXPRESSION_1.EMP_NAME,'-999') != NVL(FILTER_1.EMPLOYEE_DETAILS.ENAME, '-999') OR NVL(FILTER_1.EMPLOYEES.MANAGER_ID,-999) != NVL(FILTER_1.EMPLOYEE_DETAILS.MANAGER_ID,-999) OR NVL(FILTER_1.DEPARTMENTS.DEPARTMENT_NAME,'-999') != NVL(FILTER_1.EMPLOYEE_DETAILS.DEPARTMENT_NAME,'-999') OR NVL(FILTER_1.JOBS.JOB_TITLE,'-999') != NVL(FILTER_1.EMPLOYEE_DETAILS.JOB_NAME,'-999') OR NVL(FILTER_1.EMPLOYEES.SALARY,-999)!= NVL(FILTER_1.EMPLOYEE_DETAILS.SAL,-999) OR NVL(FILTER_1.EMPLOYEES.EMAIL,'-999')!=NVL(FILTER_1.EMPLOYEE_DETAILS.EMAIL,'-999') OR NVL(FILTER_1.EMPLOYEES.PHONE_NUMBER,'-999') != NVL(FILTER_1.EMPLOYEE_DETAILS.PHONE_NUMBER,'-999')

We use the following expression for populating LOAD_DT, LAST_UPDATE_DT, and LOGICAL_DELETE.
-
LOAD_DT - We only set the load date when we have an employe_id in the source that doesn't exist in the target yet. CASE WHEN EXPRESSION_2.EMPLOYEES.EMPLOYEE_ID is not null and EXPRESSION_2.EMPLOYEE_DETAILS.EMPNO is null THEN CURRENT_DATE ELSE EXPRESSION_2.EMPLOYEE_DETAILS.LOAD_DT END -
LAST_UPDATE_DT - We only set the last update date when we have an employe_id in the source and that exist in the target. CASE WHEN EXPRESSION_2.EMPLOYEES.EMPLOYEE_ID is not NULL AND EXPRESSION_2.EMPLOYEE_DETAILS.EMPNO is NOT NULL THEN CURRENT_DATE ELSE EXPRESSION_2.EMPLOYEE_DETAILS.LAST_UPDATE_DT END
-
LOGICAL_DELETE - Flagging of record as deleted in a target table, instead of actually being deleting the record from target but has been deleted from the source. CASE WHEN EXPRESSION_2.EMPLOYEES.EMPLOYEE_ID IS NULL AND EXPRESSION_2.EMPLOYEE_DETAILS.EMPNO IS NOT NULL THEN 'Y' ELSE 'N' END

We create an integration task to configure the data flow and then run it. After the first run, complete source data is populated into the target with LOAD_DT as the inserted date and the delete flag as “N.”

Now, we update, insert, and delete a few records in the source.

Before running the same task for completing the second run, let’s look at the Data Xplorer for the expression operator. In the expression operator, we can see only incremental data moving into the target.

After the second run, we can see the changes reflected in the target table “EMPLOYEE_DETAILS.”

Here, we conclude our overview of implementing incremental loads with Oracle Cloud Infrastructure Data Integration.
Have you seen some of our other blogs? Check out all the blogs related to Oracle Cloud Infrastructure Data Integration. To learn more, see the Oracle Cloud Infrastructure Data Integration tutorials and documentation.
