Welcome back! Let’s learn more about Oracle Cloud Infrastructure Data Integration. To get the list of previous blogs related to Oracle Cloud Infrastructure Data Integration, refer to – https://blogs.oracle.com/dataintegration/oracle-cloud-infrastructure-data-integration. Tasks guide users towards implementing typical data integration solutions. Oracle Cloud Infrastructure Data Integration includes two guided Tasks: the Data Loader Task which we will cover in a future blog and the Integration Task which is used to apply a Data Flow to a specific context e.g. for a specific source and target systems. The Integration Task is the one we are covering today. You can create an Integration Task using the Console or by using the API. Thus, Tasks helps simplify the development process for users. Let’s learn more!
The Integration Task enables us to run the Data Flows that are already created under Projects/Folders. With the help of Oracle Cloud Infrastructure Data Integration Tasks, We can create multiple Tasks with distinct configurations for the same Data Flow. Distinct configurations can be like having different join conditions for different Tasks, defining different sources and targets for different Tasks, etc. Let us consider an example of how to implement the Integration Task, Publish, and Run the Task. To understand more about Data Flow in Oracle Cloud Infrastructure Data Integration, refer to – https://blogs.oracle.com/dataintegration/data-flow-overview-in-oracle-cloud-infrastructure-oci-data-integration
Pre-requisites–
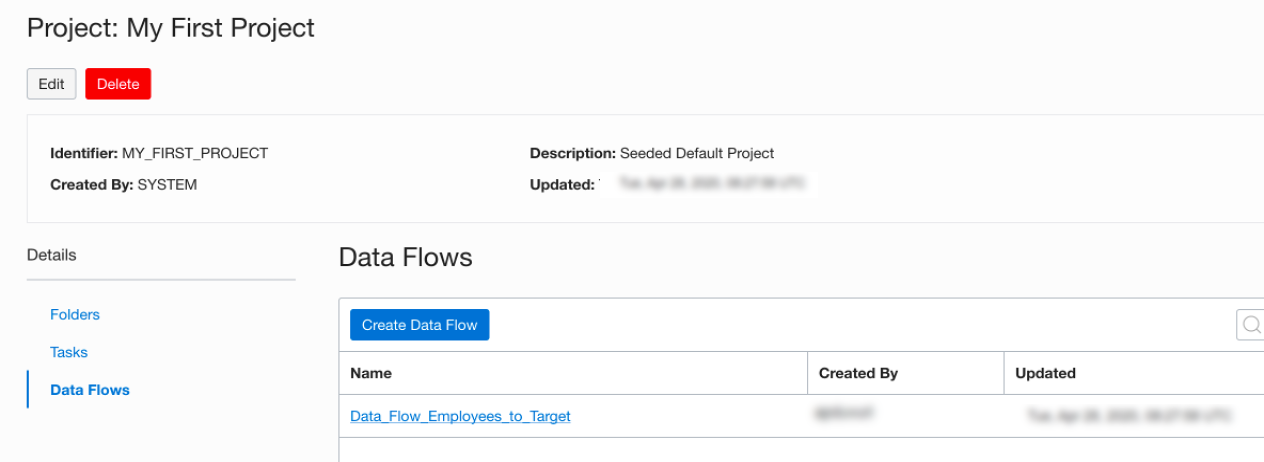
- At least one Data Flow needs to be present in one of the Projects/Folder. In this example, we have created one Data Flow with the name “Data_Flow_Employees_To_Target”.
- Data Flow should be in the Valid state
Integration Tasks in OCI Data Integration > image2020-6-17_17-46-15.png” data-mce-src=”https://confluence.oci.oraclecorp.com/download/thumbnails/259934815/image2020-6-17_17-46-15.png?version=1&modificationDate=1592396176036&api=v2″ data-unresolved-comment-count=”0″ src=”/wp-content/uploads/sites/121/2025/11/image2-5.png” style=”width: 300px; height: 150px; border-width: 1px; border-style: solid;” title=”Data Integration Service > Integration Tasks in OCI Data Integration > image2020-6-17_17-46-15.png”>
- <<Optional>> – If you need to externalize some of the Data Flow configurations then parameters have to be created in your Data Flow. We will be covering Parameters in a future blog, for more information about them please refer to –https://docs.cloud.oracle.com/en-us/iaas/data-integration/using/parameterization.htm
Creating Integration Task –
Integration Task can be created from Workspace –→ Quick Actions tile (or) by clicking on Create Integration Task within Project/Folder

Configuring Integration Task –
Data Flow and Parameters need to be configured as shown in the below image –

After selecting the Data Flow by clicking on the “Select” button. If Parameters are defined at the Data Flow level then it can be assigned at Task level as well as during the run time. Once you have selected a Data Flow the Integration Task panel will refresh and look like this:

Once the Data Flow is configured we can see the Tasks in the Project/Folder

Publish Integration Task –
For any Task i.e. Data Loader or Integration to run in Oracle Cloud Infrastructure Data Integration, it needs to be published under Application and then the corresponding Task can be executed. An Application is a container for published Tasks and their dependencies. Data Integration includes one default Application where you can publish Tasks. You can create additional Applications if needed. Click the Actions (three dots) menu for the Task and select Publish then pick your Application.


Once the Task is published, go to the Application –→ “Default Application” within the workspace, and under Patches, the published Tasks can be seen. Click on View Details next to a particular patch to open up the Patch Details panel and view the content of the Patch along with error messages (if any).


Go to the Applications and then run the Task

If Parameters are defined at the Data Flow level, a new screen appears asking users to configure new or select the existing parameters. We will be covering more about Parameters in future blogs.

After running the task the executed jobs can be seen under Task Runs with the number of processed records, Duration, Executed By, Execution Date, etc.

As shown above, the Integration Task is used for completing the configuration of Data Flows using optional Parameters and then running Data Flows in Applications. Now, the user can implement such an end-to-end scenario without needing deep expertise.
We hope this helps as you learn more about Oracle Cloud Infrastructure Data Integration. For more information, check out the Tutorials and Documentation.
