OCI Data Integration (OCIDI) is a powerful Oracle Cloud Infrastructure service for seamless data movement, transformation, and integration across diverse sources. One of its key capabilities is incremental extraction, which processes only new or updated data—reducing resource usage, time, and costs while ensuring fresh insights.
In this blog, I’ll show how to implement incremental loading of monthly timestamp-based Parquet files stored in date-partitioned folders, and ingest them into Oracle Autonomous Database for optimized and efficient data synchronization.
Solution Architecture
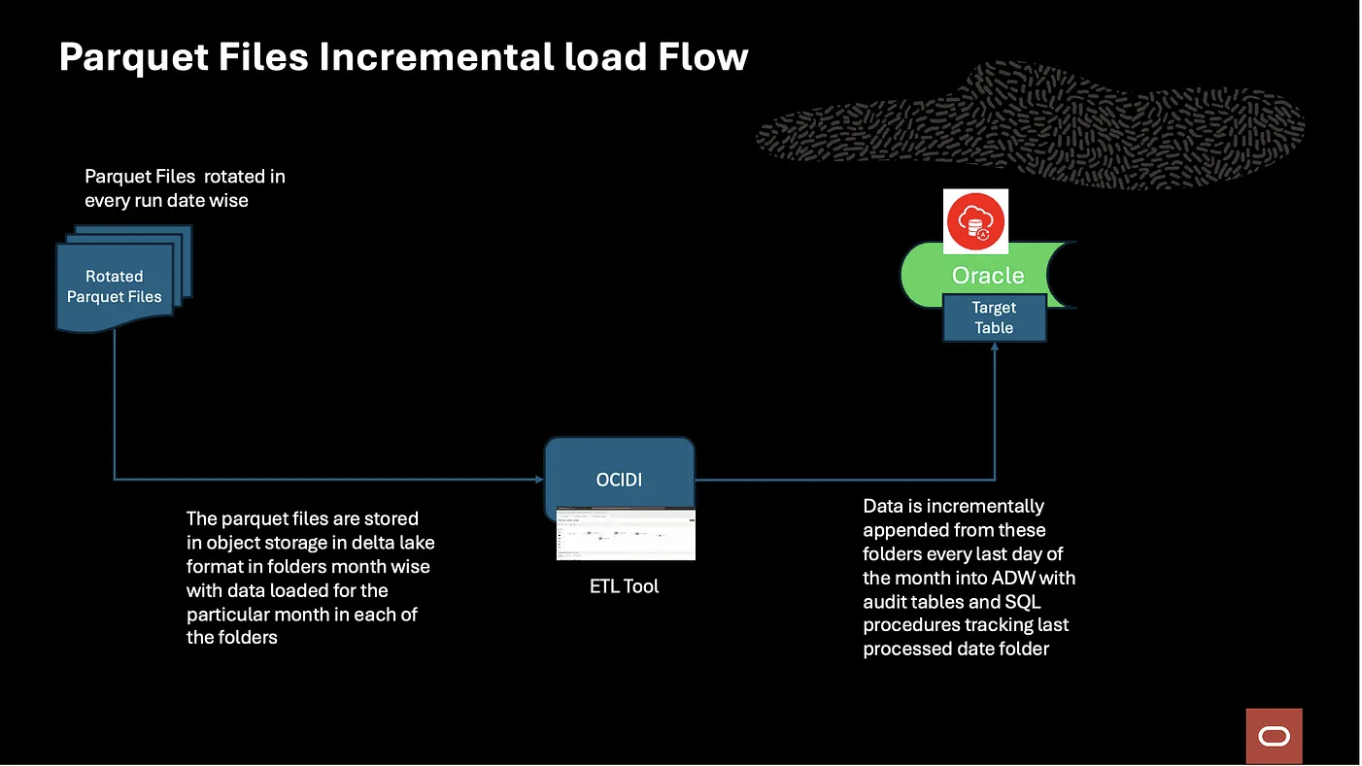
Solution Prerequisites
- Oracle Cloud Infrastructure data integration workspace with policies. Refer here.
- Autonomous Database
- Object Storage Bucket
What we need to configure?
- Audit Table with necessary columns to track last extracted date and folder and target table
- PL/SQL stored procedures
- Date wise generated folders in object storage bucket
Configuration Setup
Step 1: Create the target table and audit table in ADW.
CREATE TABLE "TGT"."TEST_PAR_LOAD" ( "MONTH_VALUE" VARCHAR2(4000 CHAR) COLLATE "USING_NLS_COMP", "YEAR_VALUE" VARCHAR2(4000 CHAR) COLLATE "USING_NLS_COMP", "DAY_OF_YEAR_VALUE" VARCHAR2(4000 CHAR) COLLATE "USING_NLS_COMP", "DAY_OF_WEEK_VALUE" VARCHAR2(4000 CHAR) COLLATE "USING_NLS_COMP", "DATE_VALUE" VARCHAR2(4000 CHAR) COLLATE "USING_NLS_COMP" ) DEFAULT COLLATION "USING_NLS_COMP" ; CREATE TABLE "TGT"."AUDIT_FOLDER_NAME" ( "TARGET_TABLE" VARCHAR2(100 BYTE) COLLATE "USING_NLS_COMP", "FOLDER_NAME" VARCHAR2(200 BYTE) COLLATE "USING_NLS_COMP", "CURR_DATE_VALUE" DATE ) DEFAULT COLLATION "USING_NLS_COMP" ;
Step 2: Create the PL/SQL stored procedures to update the audit table(Post we insert initial month’s data in audit table to configure initial load)
PL/SQL procedures to get the file pointer from latest folder and update the audit table values for the incremental load to be executed for next month
create or replace PROCEDURE TGT.GET_FOLDER_NAME(p_TARGET_TABLE VARCHAR2, p_folder_name OUT VARCHAR2)
AS
BEGIN
SELECT folder_name
INTO p_folder_name
FROM TGT.AUDIT_FOLDER_NAME
WHERE TARGET_TABLE = p_TARGET_TABLE
AND CURR_DATE_VALUE = (SELECT MAX(CURR_DATE_VALUE) FROM TGT.AUDIT_FOLDER_NAME WHERE TARGET_TABLE = p_TARGET_TABLE);
END;
create or replace PROCEDURE TGT.UPDATE_folder_name_monthly(p_TARGET_TABLE VARCHAR2)
AS
v_new_folder_name VARCHAR2(2000); -- Increased size to accommodate the new folder format
v_curr_date_value DATE;
v_next_month_last_day DATE;
BEGIN
-- Retrieve the current date value from the audit table
SELECT MAX(curr_date_value) INTO v_curr_date_value
FROM TGT.AUDIT_FOLDER_NAME
WHERE TARGET_TABLE = p_TARGET_TABLE;
-- Get the last day of the next month
v_next_month_last_day := LAST_DAY(ADD_MONTHS(v_curr_date_value, 1));
-- Generate the new folder name using the last day of the next month and append the wildcard for .parquet files
v_new_folder_name := 'LOAN_DATA_LOAD/process_date=' || TO_CHAR(v_next_month_last_day, 'DD-MM-YYYY') || '/*.parquet';
-- Insert the new folder name into the audit table with the updated month
INSERT INTO TGT.AUDIT_FOLDER_NAME (TARGET_TABLE, folder_name, curr_date_value)
VALUES (p_TARGET_TABLE, v_new_folder_name, v_next_month_last_day);
END;
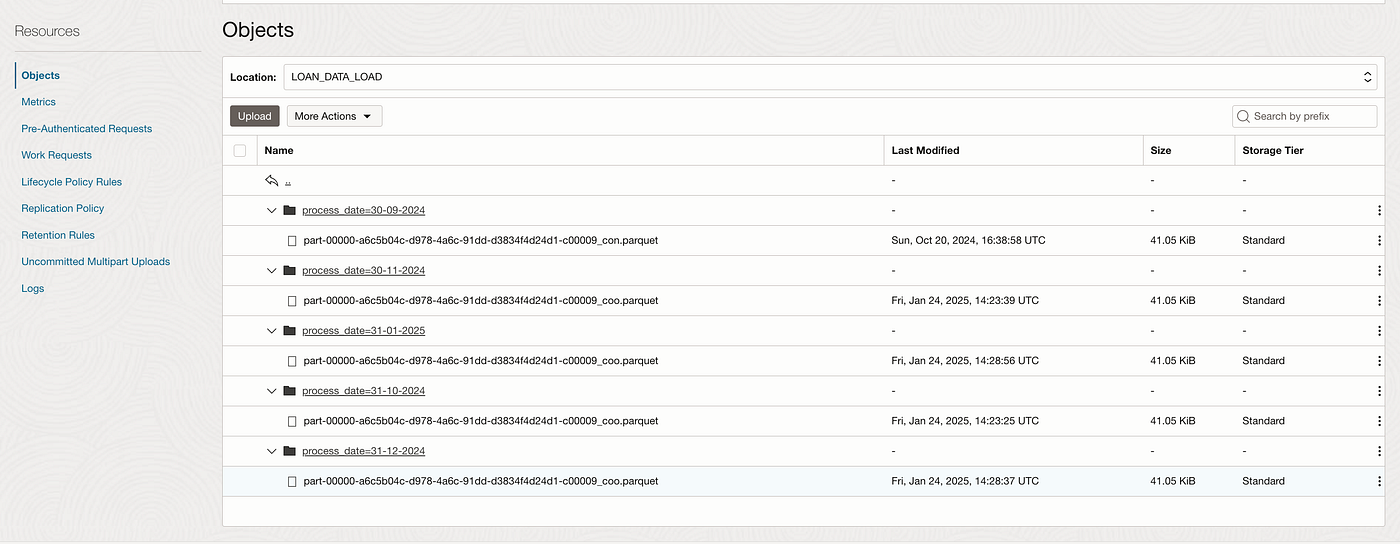
Now you can see Object Storage bucket folders in above format as shown in the image and new folders will be created in this format.(process_date=date_value) with the files uploaded in it.
Solution configuration in OCI Data Integration
In OCI Data Integration (OCIDI), we can create a data flow with a parameter that has a default value set to the first month’s folder or object entity. By using a wildcard pattern such as *.parquet, the data flow is designed to process only parquet files from the specified folder initially. The parameter is then passed into the data flow entity for dynamic execution from object storage folders within OCIDI.
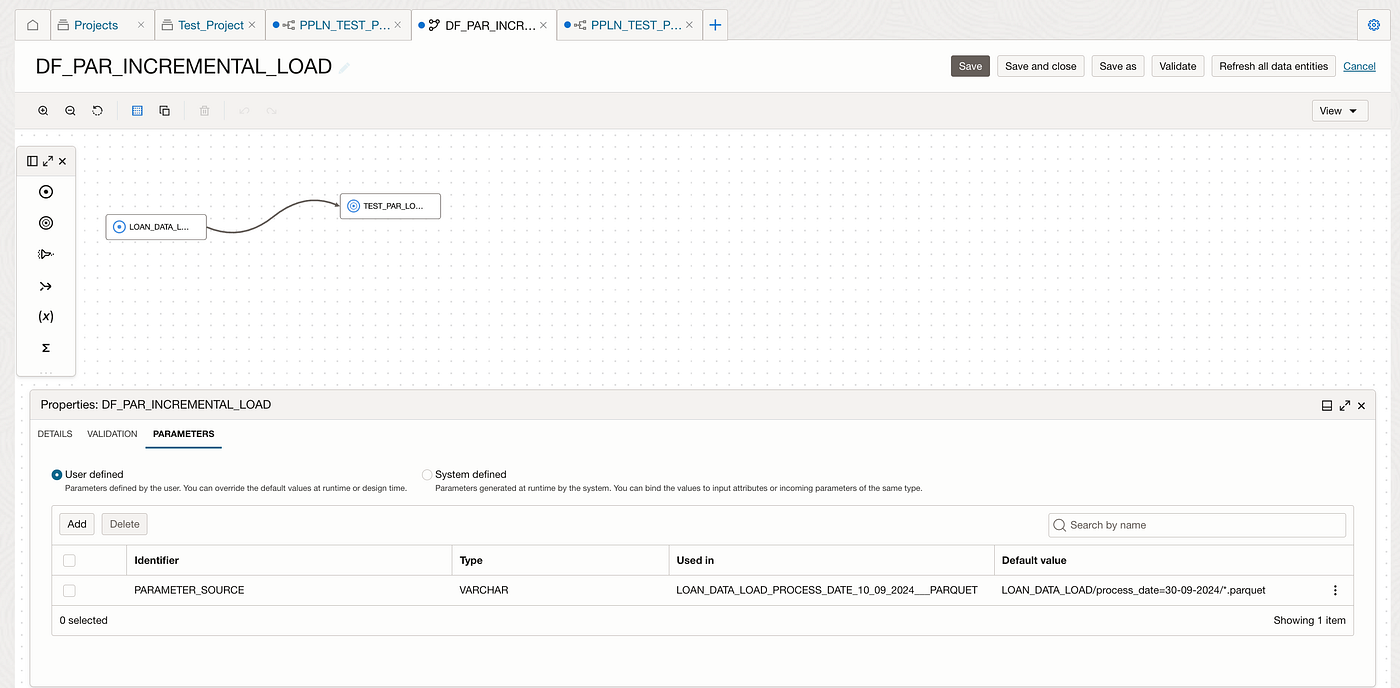
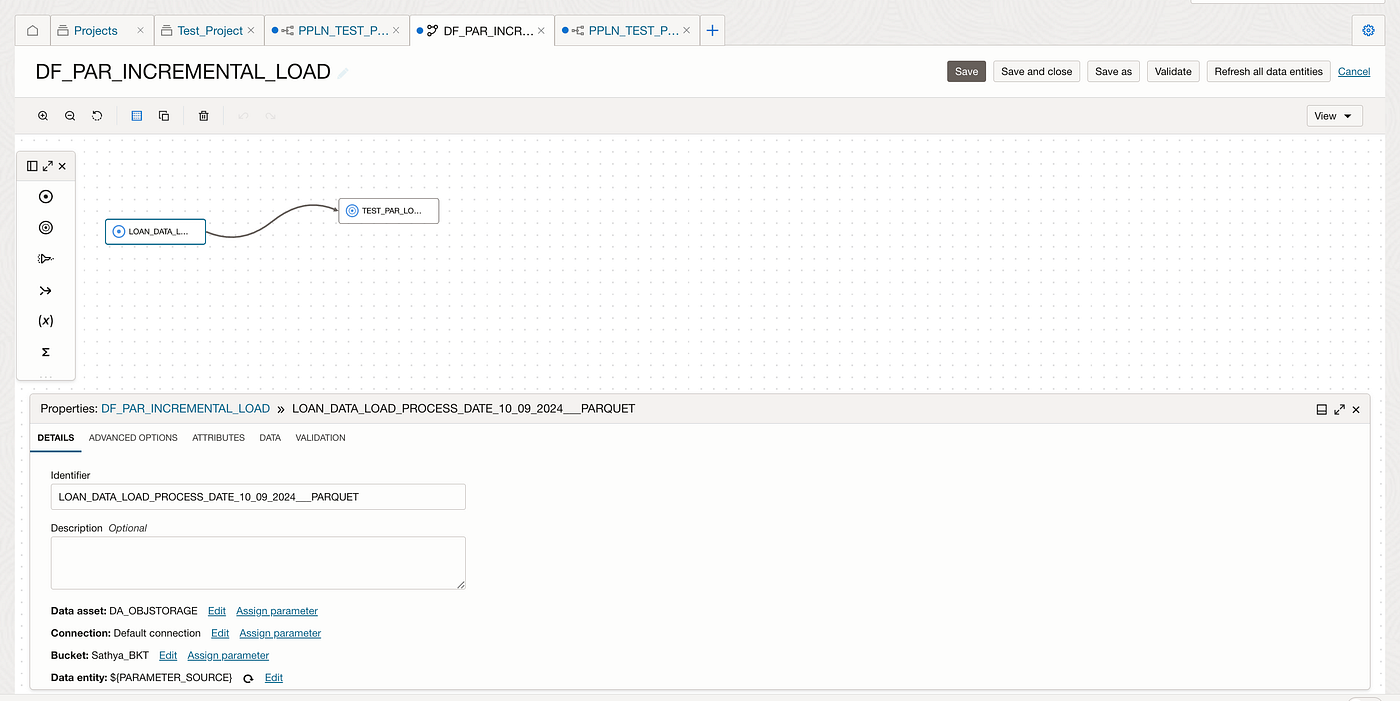
Invoke the PL/SQL stored procedures using OCIDI SQL tasks
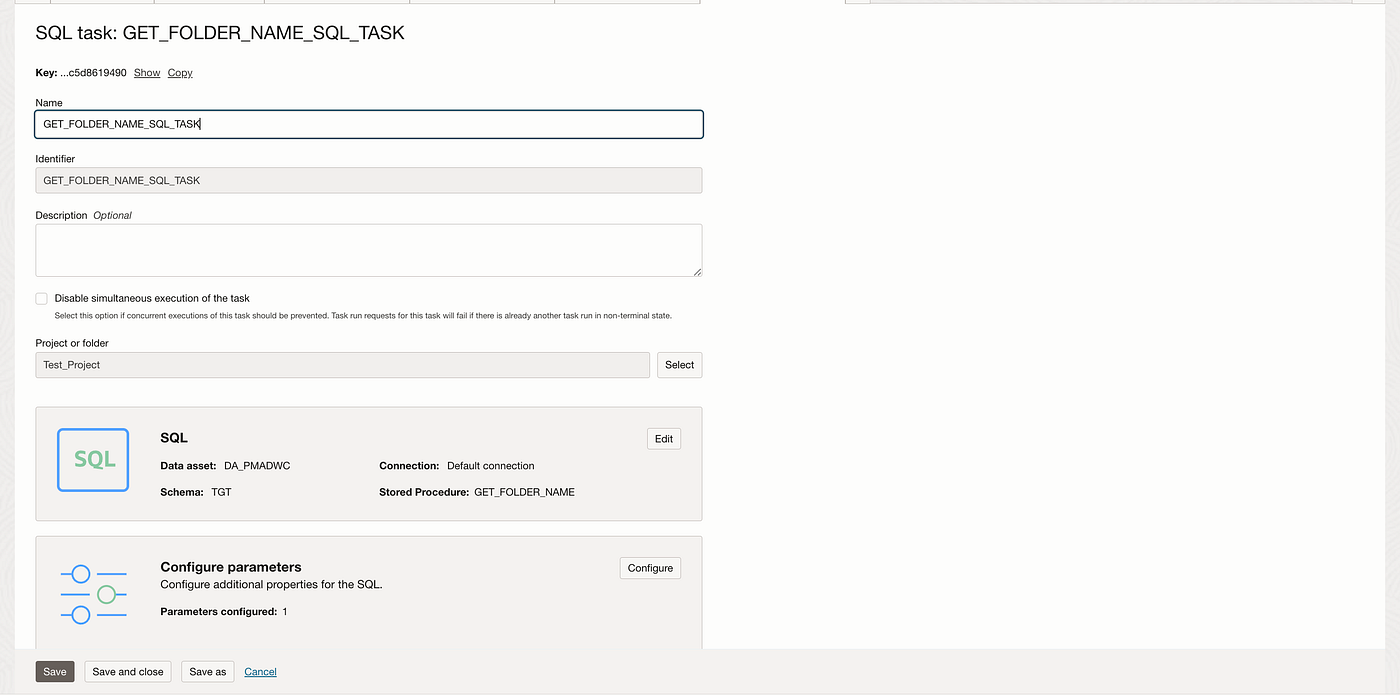
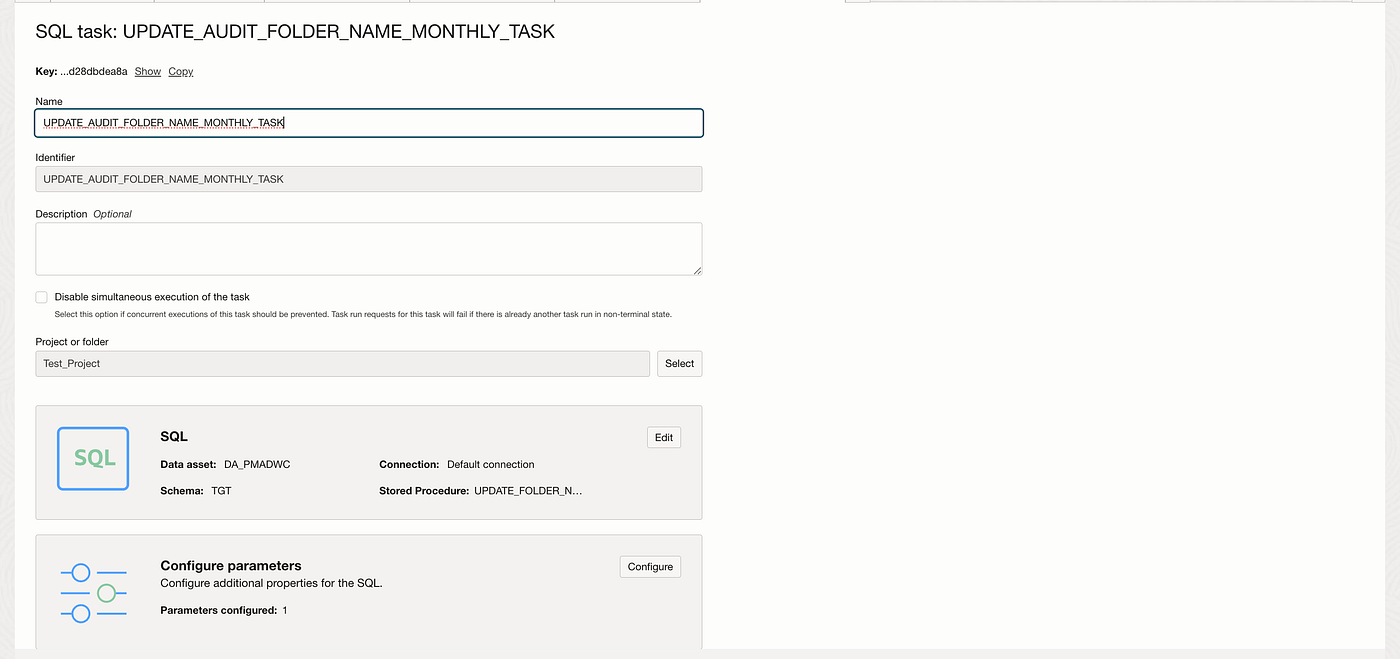
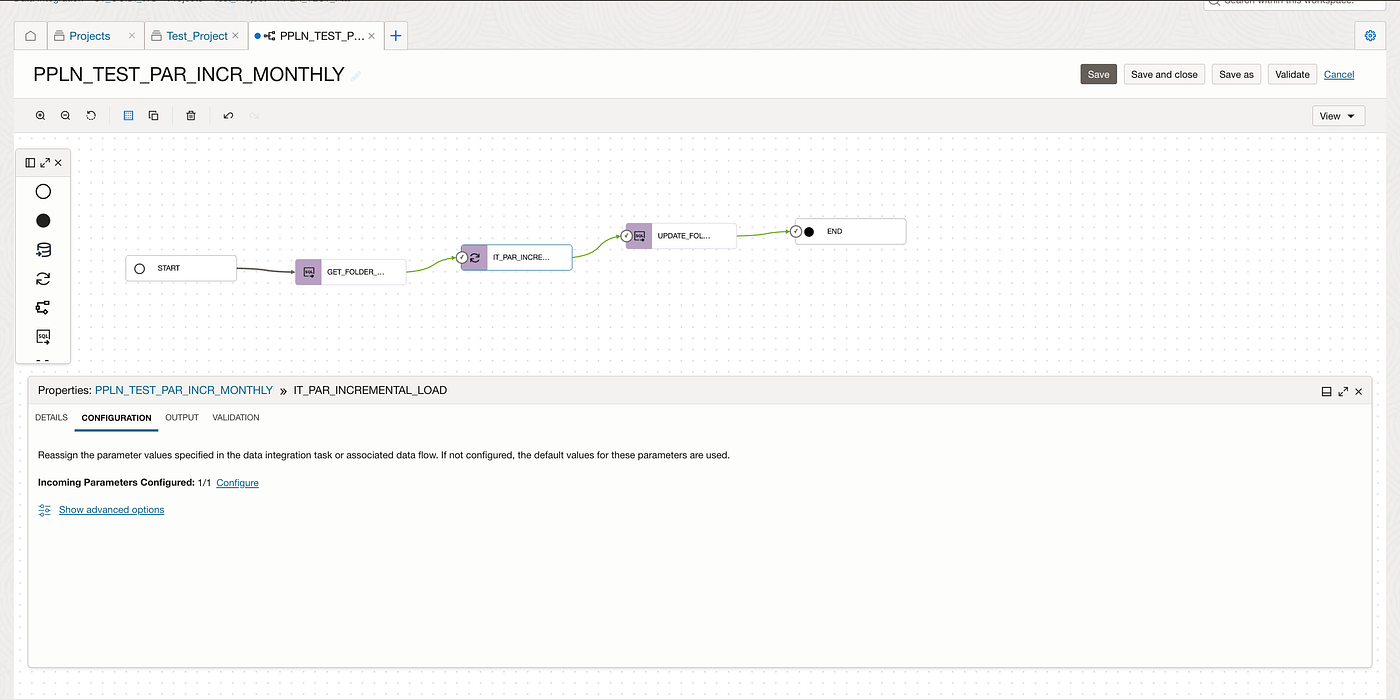
Create a pipeline task to invoke the stored procedures SQL tasks and data flow task and pass the output parameter from GET_FOLDER_NAME_SQL_TASK into the data flow parameter.
Execute the pipeline task to test the results.
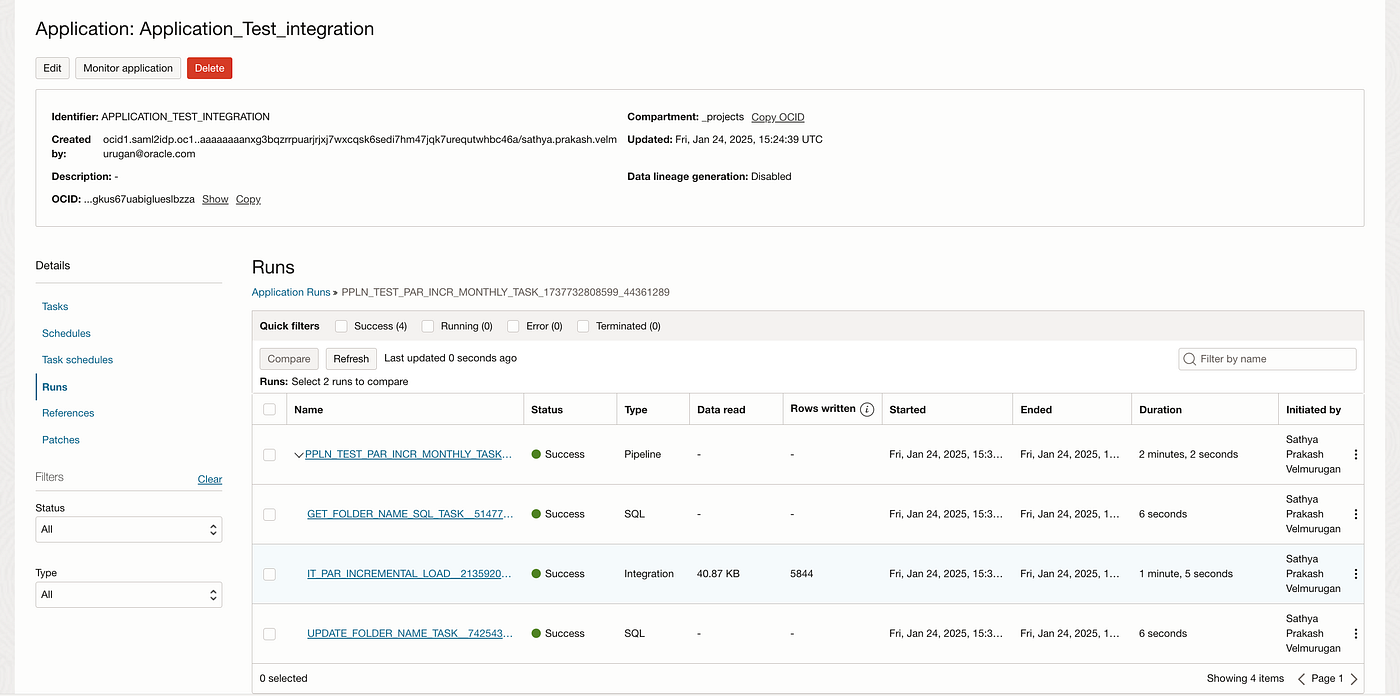
Once executed the AUDIT_FOLDER_NAME table will be updated with the latest date value the folder name as well for subsequent extraction.This architecture is widely adopted for loading data from monthly date-partitioned files stored in dynamically created structured folders.
One of the key considerations when executing the solution is understanding the frequency at which new files are generated within the folders.
I hope that this blog helps as you learn more about Oracle Cloud Infrastructure Data Integration’s unique capabilities on incremental data load. For more information, check out the documentation.
