In my previous blog ,which you can see here, I wrote about what GoldenGate for Big Data Pluggable Formatters are and how JSON formatter can be used in various event handlers.
In this blog, I’ll continue with Pluggable Formatters focusing on DelimitedText Formatter.
As discussed earlier, GoldenGate for Big Data is made of different pieces that can be used together. File Writer Handler is used to generate files from trail files and various event handler can be used to load these files to desired target systems. You can find more details about how File Writer Handler works in my previous blog.
Pluggable Formatters help us with enhancing the file generated by File Writer Handler. Their usage is not only limited to File Writer Handler. They can be used with Kafka Handler, Kafka Connect Handler, HDFS Handler and Kinesis Streams Handler.
For this blog post, I’ll continue using File Writer Handler. It only generates delimitedtext files on a local directory in GoldenGate for Big Data node and I’m not going to load them to any target. Each insert, update, delete or truncate operation coming from the source trail file is written as an individual delimitedtext message.
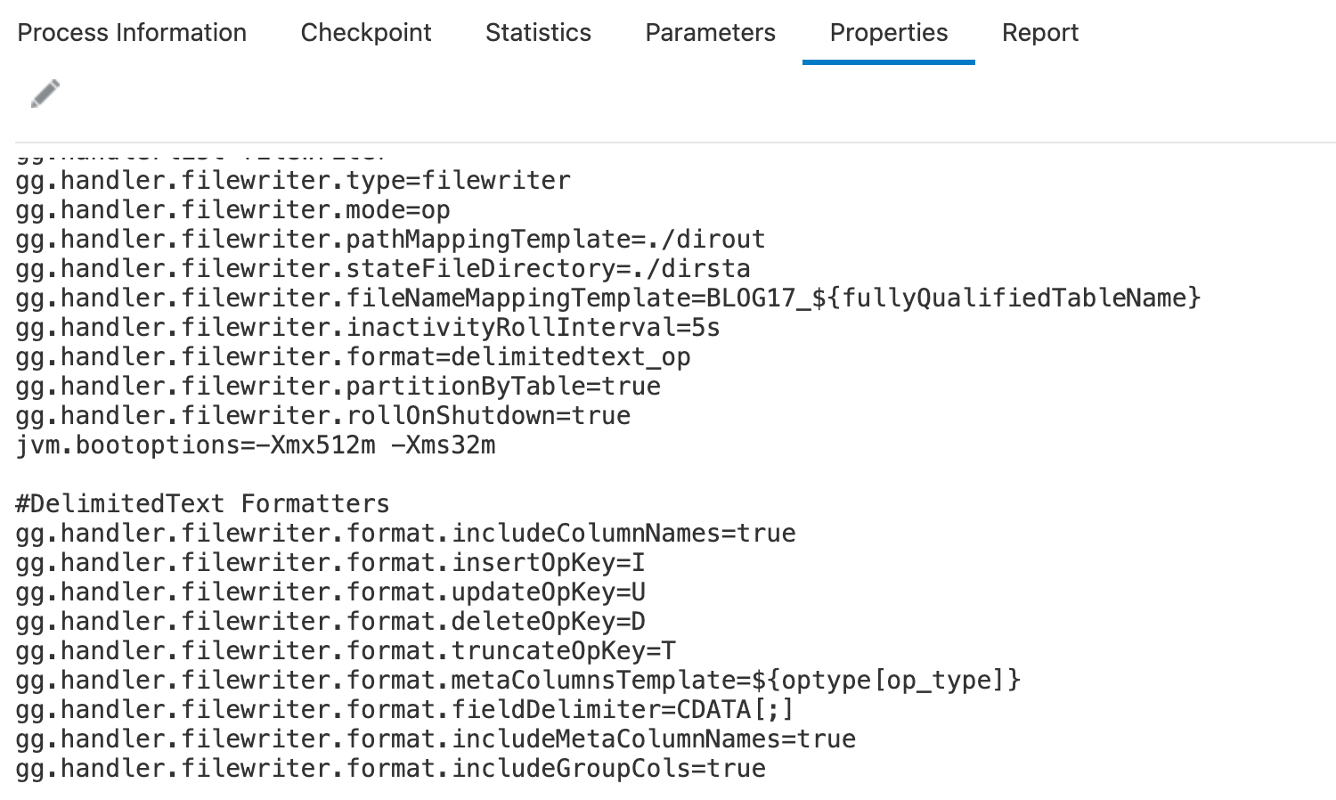
Let’s configure File Writer Handler for delimitedtext and see how it looks before any formatters are applied.
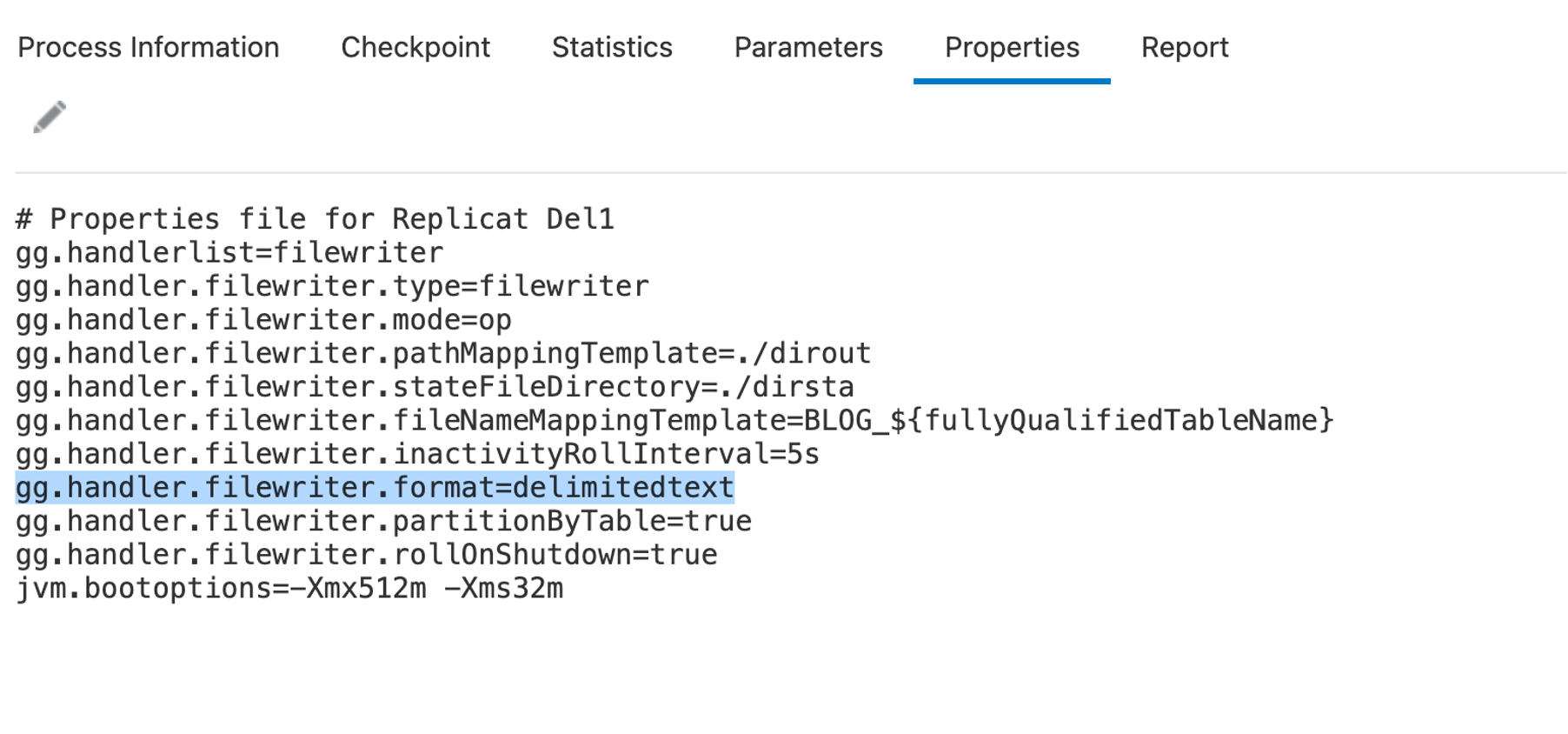

Adding column values to output messages
“includeColumnNames” property helps with including the column names to the messages. By default, it is set to false and to be activated, it needs to be set to true.
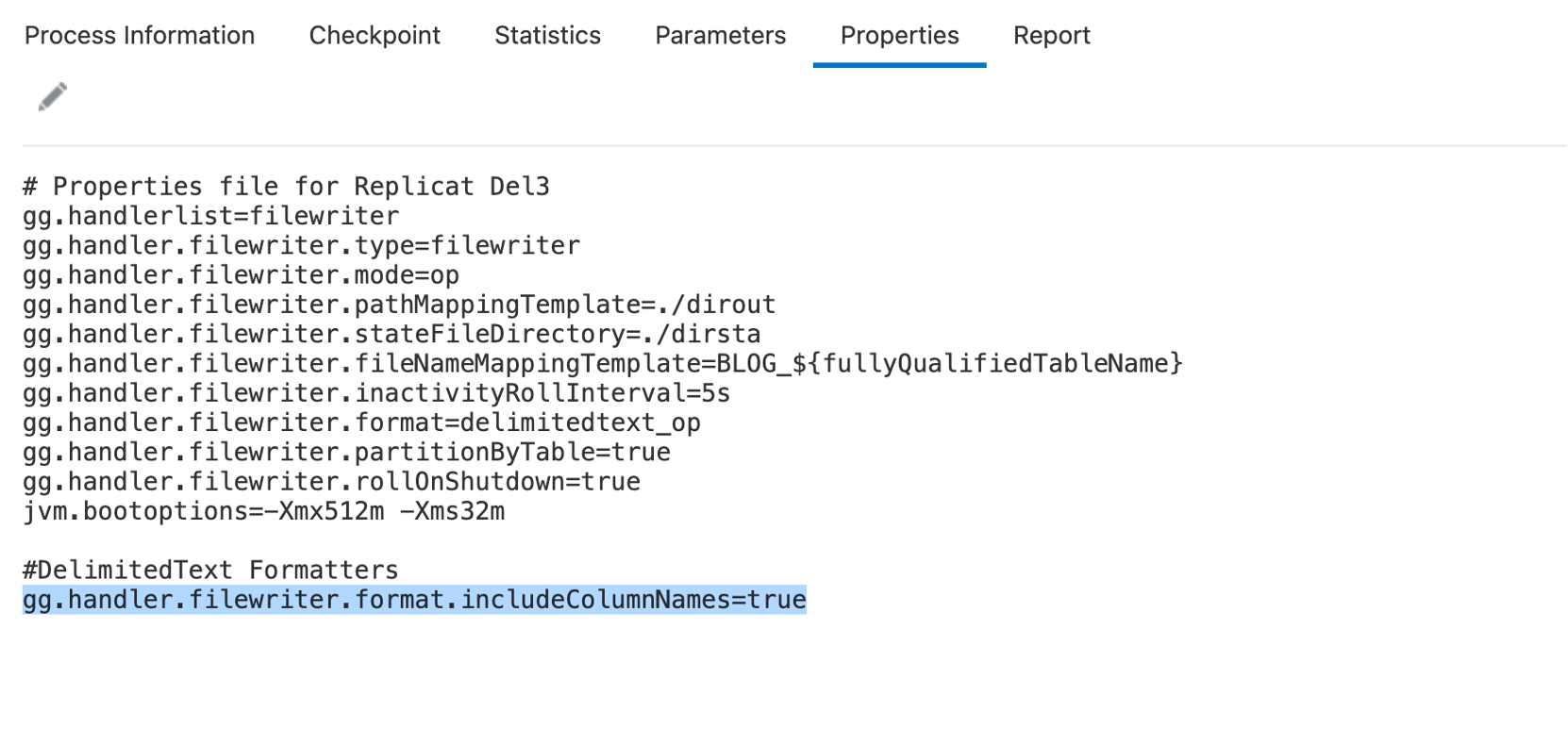

Adding source operation indicators
“delimitedtext_op” format gives the ability of writing both before and after images in the same output message. Using the “opKey” properties, delimitedtext_op formatter can also output the type of the source operation. Let’s add these properties into our sample and see how they change the output message.
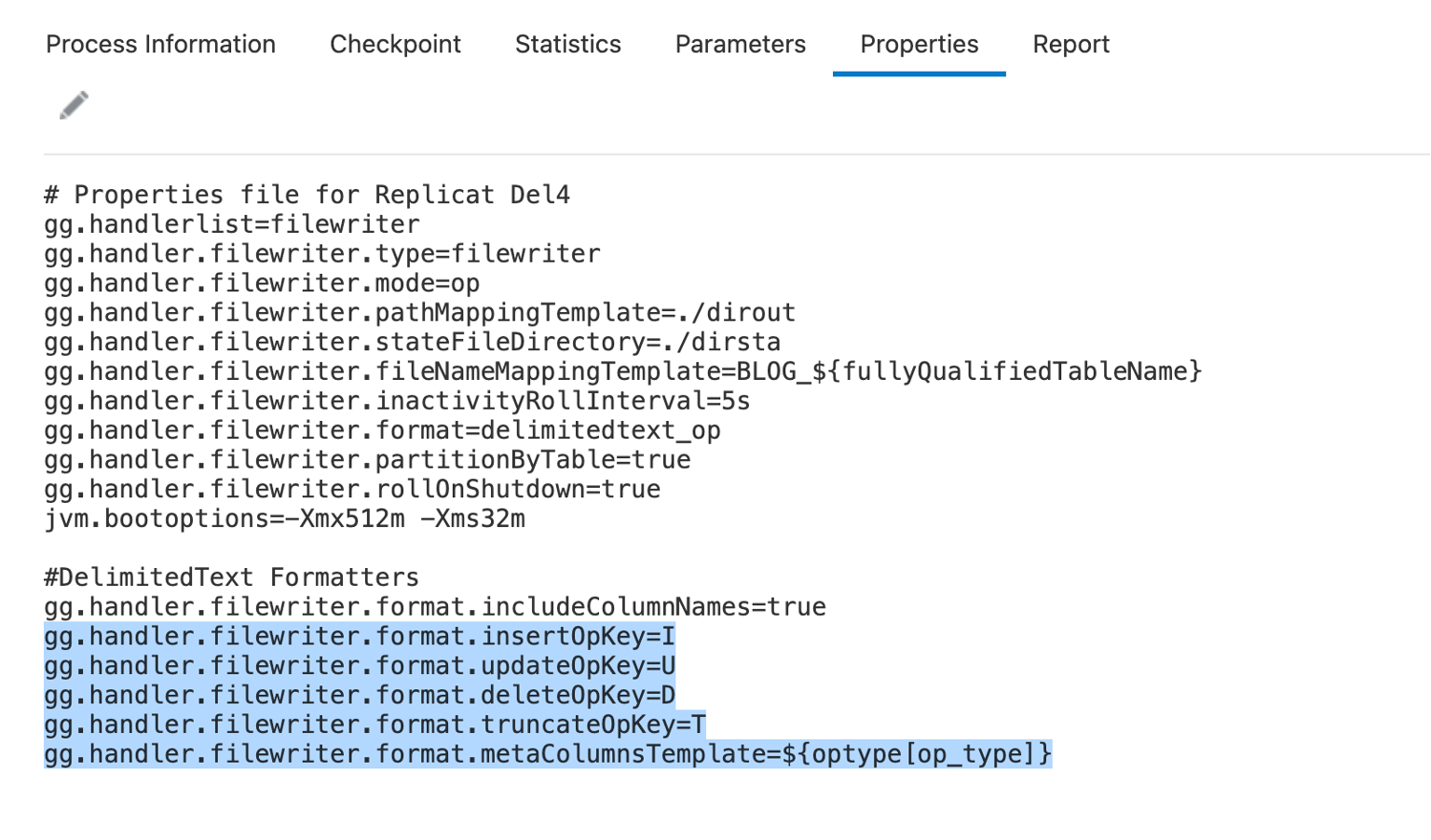

In this example, you can see how insert & update operations are reflected on last 2 messages. You can also notice that in the last message, both before & after images are written in the same message after an update operation. When “includeColumnNames” set to true, output resembles the following format: “OpType|COL1_Name|COL1_Before_Value|COL1_After_Value”.
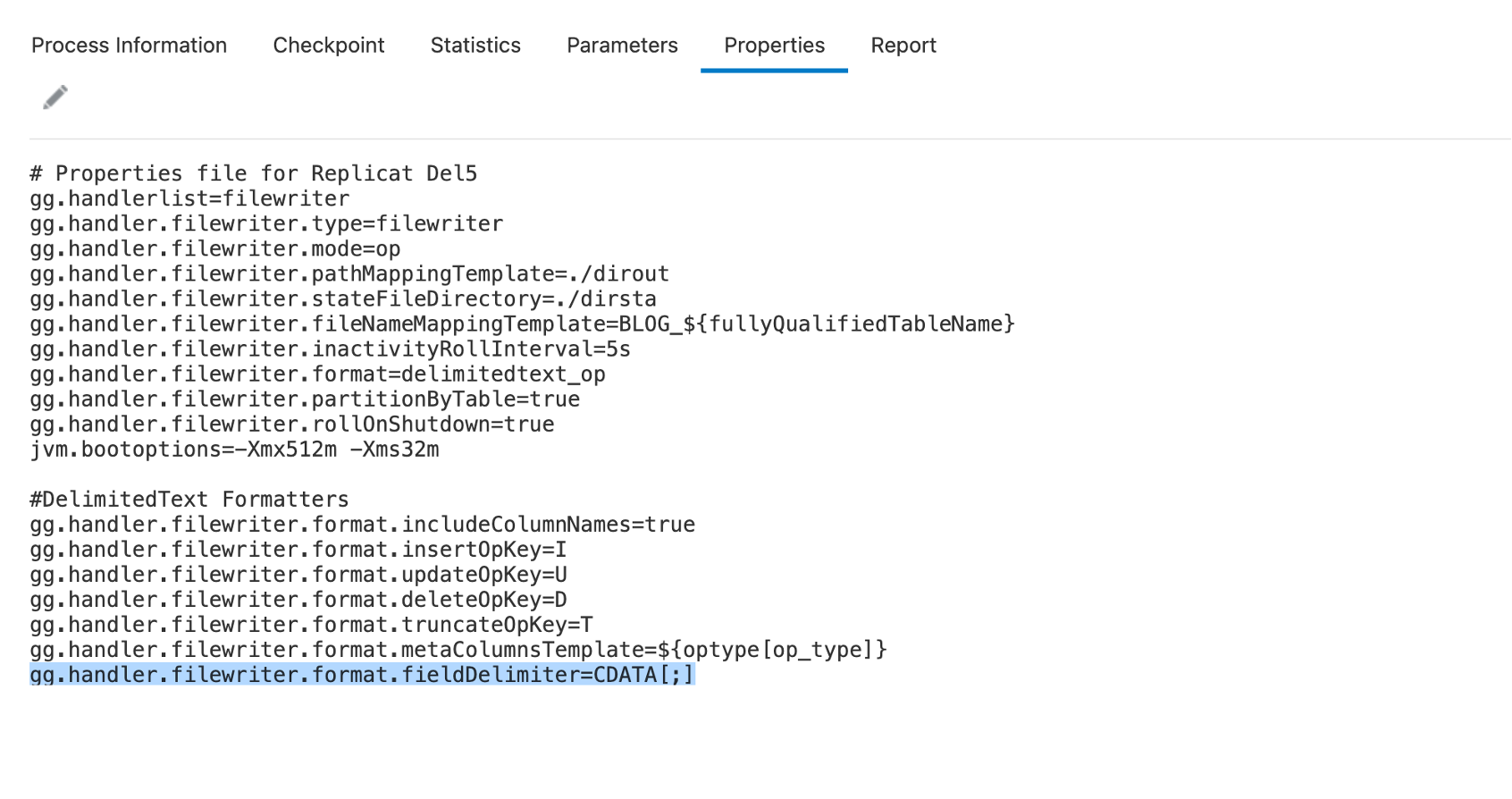
Adding column delimiters:
“fieldDelimiter” property helps with setting the delimiter between the fields in an output message. By default, it is set to ASCII 001. “fieldDelimiter” can be used with “CDATA[]” wrapper to set the desired delimiter. For example, if I set fieldDelimiter as CDATA[;], it will output the messages with a semi column field delimiter.

What about whitespace as field delimiters? The Java Adapter configuration trims leading and trailing characters from configuration values when they are determined to be whitespace. In these cases, you must employ specialized syntax in the Java Adapter configuration file to preserve the whitespace. To preserve the whitespace, when your configuration values contain leading or trailing characters that are considered whitespace, you can wrap the configuration value in a CDATA[] wrapper. For example, if i use CDATA[] whith a single space, it woıuld add spce as the column delimiter. I can set it as gg.handler.filewriter.format.fieldDelimiter=CDATA[ ]. In this case, if the data contains the delimiter, the formatter will escape the delimiter with a backslash(\). This will enable downstream parsers to detect if the character is part of data or if it is a delimiter. Also, please note that this escaping logic works only with single character delimiters.
In tthe above scenario, the output would look like:
U CHARACTER_ID 6 6 CHARACTER_NAME THOMAS\ ANDERSON Guido\ Orefice CITY ZION Rome
In the same above example, let’s assume that I want to represent whitespaces with “s” in my output file. To achieve that, I set gg.handler.filewriter.format.fieldDelimiter=CDATA[\s]. And the output message would look like:

In this example, you can notice that “s” is written as “ss” time to time. It’s because of delimitedtext_op output format which is “OpType|COL1_Name|COL1_Before_Value|COL1_After_Value”. In an insert operation, there will be no before images and COL1_Before_Value field will be represented as “s” as well. If we check an updated operation, it becomes clearer:
![]()
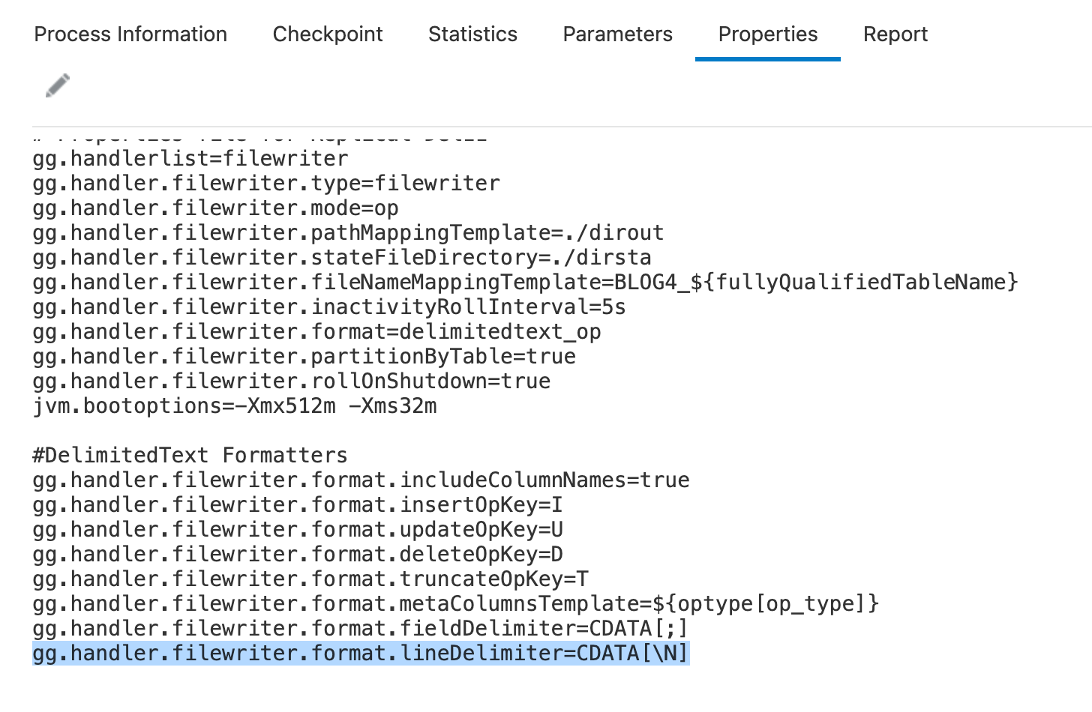
Adding line delimiters:
By default, delimitedtext formatter adds a new line in the output; but this behaviour can be controlled with “lineDelimiter” property. “lineDelimiter” property can be used with CDATA wrapper. Let’s see how output changes when it is set. In my example, I set lineDelimiter=CDATA[\N].
![]()
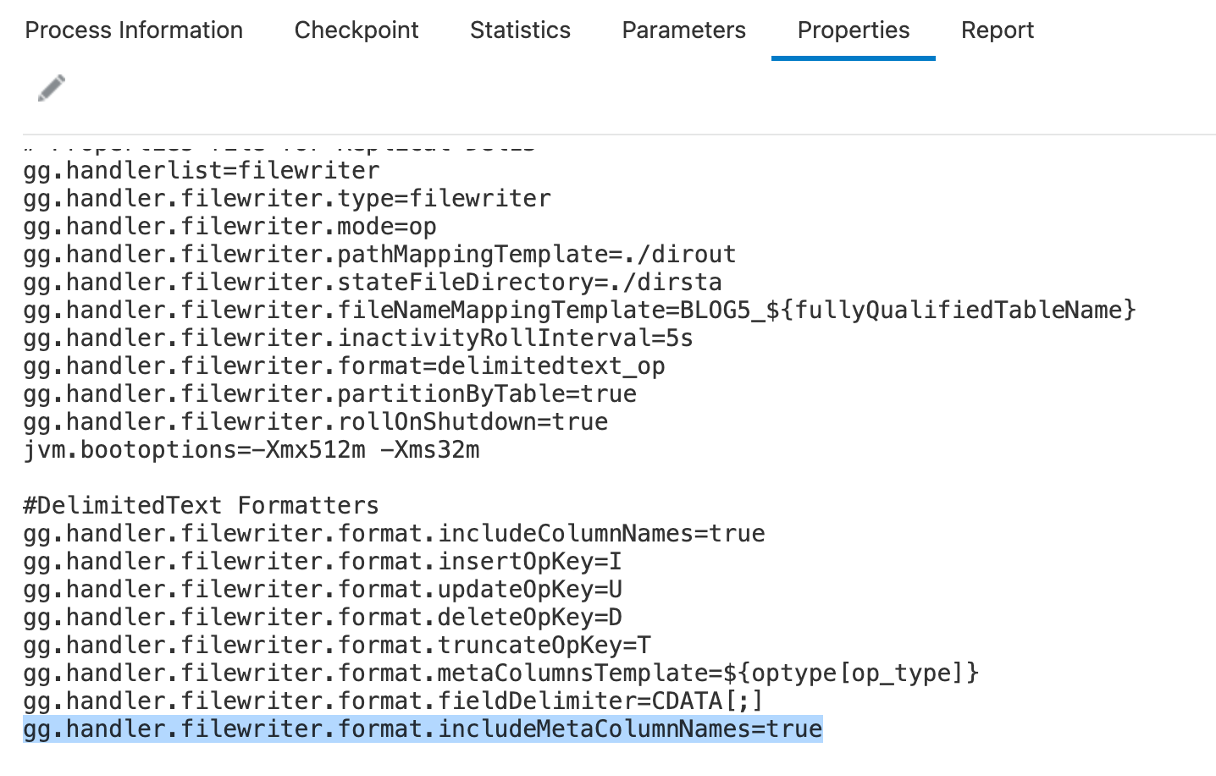
Including MetaColumn in the output:
To make delimited messages more self-describing, you can set “includeMetaColumnNames” property to true. Once set, it will insert column names in the output messages.

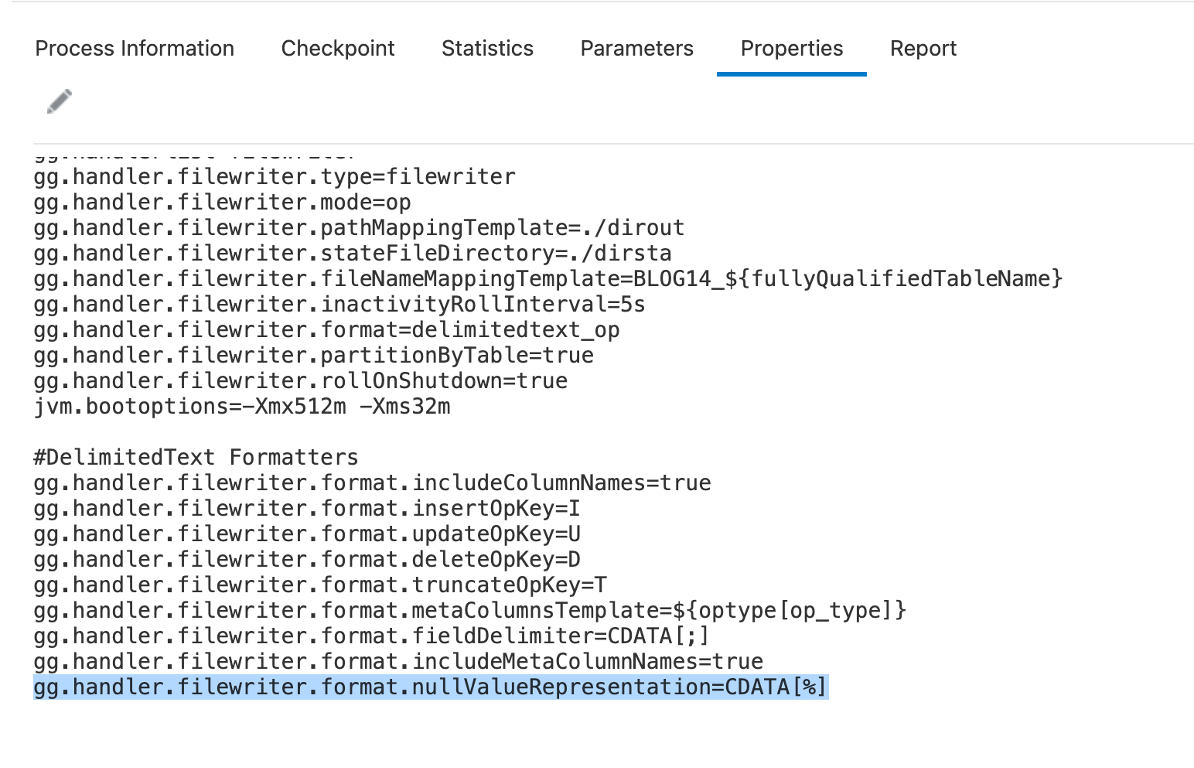
Null Value Representation:
Null values are represented as string “null” by default. This behaviour can be changed by using “nullValueRepresentation” property of delimitedtext formatter. “nullValueRepresentation” can be used with CDATA[] wrapper.
![]()
![]()
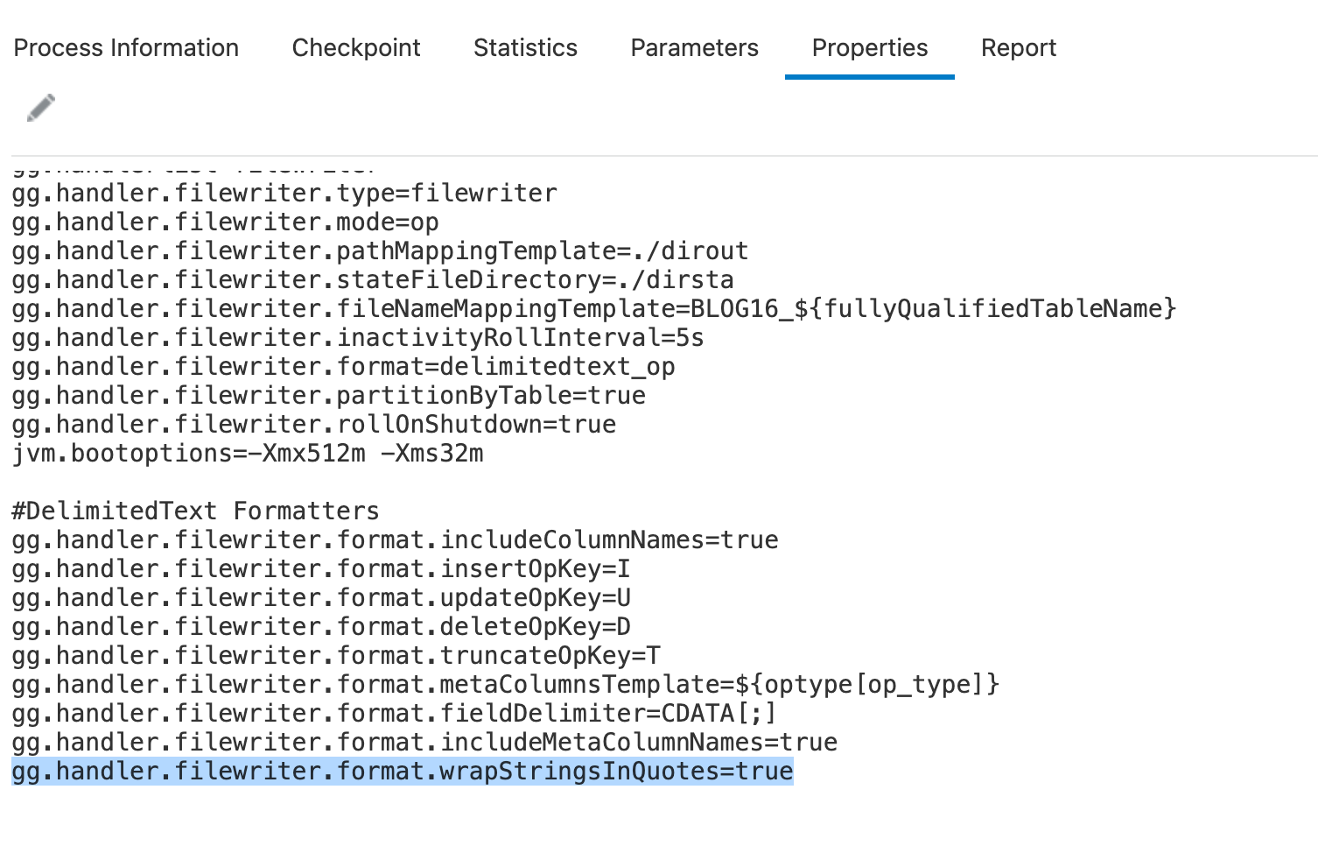
Output strings in quotes:
When set to true, “wrapStringsInQuotes” property outputs string values in double quotes.

Grouping Column Names
When “includeGroupCols” property is set to true, all column names and before&after values are grouped together.
![]()
Conculusion:
GoldenGate for Big Data Pluggable Formatters is a very powerful and flexible tool to enhance various message formats. Pluggable Formatters can be used with various GoldenGate for Big Data Event handlers and enhances the messages depending on their types. In this blog, we’ve seen DelimitedText Formatter details; but, there are pluggable formatters available for Avro_Row, Avro_Operation, Avro_Object_Container, JSON and XML as well. You can get details about these formatters from the GoldenGate for Big Data documentation and apply in your replicats where applicable.
