Oracle GoldenGate is a comprehensive software package for real-time data integration and replication. It enables high availability solutions, real-time data integration, transactional change data capture, data replication, transformations, and verification between operational and analytical enterprise systems.
Oracle GoldenGate for Big Data supports real-time data ingestion into more then 25 different big data and cloud technologies.
In GoldenGate for Big Data, there are different “handlers” which enables loading data/ files to various target systems. For example, you can use “Kafka Handler” to stream messages into a Kafka node or “S3 Event Handler” to load files into AWS S3 or “Oracle Cloud Infrastructure Event Handler” to load files into Oracle Cloud Infrastructure Object Storage. And there are many more examples possible.
One of the most common GoldenGate for Big Data use cases is real-time data ingestion into data lakes, data lakehouses or delta lakes. GoldenGate for Big Data accomplishes this use case in two steps: first it generates a file and then loads that file to the desired target system.
GoldenGate for Big Data “File Writer Handler” is used to generate the files from the trail files and “Event Handlers” loads these files to the target systems. File Writer Handler creates a file in the local file system and keeps it open till file rolls over. File roll overs are triggered by a metadata change event and/ or they can be configured based on some rules.
There are 4 cases here:
1. Reaching Max File Size: By default, file sizes are configured to 1gb; but, it can be configured as needed by “gg.handler.name.maxFileSize” property. In this case, File Writer Handler opens the file and keeps it open till Max File Size is reached (assuming there are no metadata changes). When the size is reached, file is closed, and a new file is generated.
2. Reaching File Roll Interval: By default, roll interval is not active; but, it can be configured by “gg.handler.name.fileRollInterval” property. When configured, it starts a timer when file is created. When the interval timing is reached, if the files is still open, it closes the file and rolls over to a new one. Let’s assume that you set the Max File Size as 5gb and File Roll Interval as 30 minutes. At the end of the 30 minutes, if the file still open, it will close and roll over to a new one. If Max File Size is reached earlier, it will be the trigger for roll over action.
3. Reaching Inactivity Roll Interval: By default, inactivity roll is not active; but, it can be configured by “gg.handler.name.inactivityRollInterval” property. When configured, it starts a timer for tracking the inactivity period. Here, inactivity means there are no operations coming from the source system. In other words, there are no CDC data being written to the file. When set, it starts the count down when the last operation is written to a file. At the end of the count down, if there are no incoming operations, file is closed. It can be used together with the previous 2 properties. For example, you set the file size as 5gb, roll interval as 30 minutes and inactivity roll interval as 5 minutes. In this case, file is closed when one of these rules is fulfilled.
4. Roll on Shutdown: By default, roll on shutdown is set to false; but can be configured by “gg.handler.name.rollOnShutdown” property. When configured, it shuts the open file when replicat process is stopped. By default, file writer handler keeps the file open even if the replicat stops and continues writing to the same file when the replicat restarts. This behaviour may change if any previous roll over rules is set.
Once an open file is closed, selected event handler picks that file and loads into the desired target system. GoldenGate for Big Data has event handlers for HDFS, ORC, Parquet, AWS S3, OCI Object Storage, Azure Data Lake, Azure BLOB Storage and Google Cloud Storage.
For this blog, I’m not using any event handler. I’m locally generating the files by using only File Writer Handler.
File Writer Handler has more properties that can be configured for fulfilling different scenarios; but, for this blog, I’ll focus on file formats. “gg.handler.name.format” is used to set the format of the file. Overall, it supports delimitedtext, XML, JSON and Avro; but, you can check the detailed list of supported formatters from the product documentation.
Pluggable Formatters
“Pluggable Formatters” formats the file generated by the File Writer Handler depending on the type of the file. For example, the way null values are managed by formatters in a JSON message and in a delimitedtext message might be different. Pluggable Formatters can be used with GoldenGate for Big Data event handlers and that’s another reason why they’re so powerfull.
If you check the GoldenGate for Big Data JSON Formatter documentation, you’ll notice that pluggable formatter properties are listed without any handler names added. For example as “gg.handler.name.format”. If I want to use this property with File Writer Handler, I need to define it as “gg.handler.filewriter.format”. If I want to use the same property with Kafka Handler, I can just define it as “gg.handler.kafkahandler.format”.
In this blog, I’ll detail the pluggable formatters for File Writer Handler; but, at the end, I’ll also mention how pluggable formatters can be used with Kafka Handler.
I’ll continue with JSON type and File Writer Handler for this blog. In my replicat, I’m using the File Writer Handler and selected format as JSON. The replicat will read the operations from the trail file and create a json file in “./dirout” directory in deployment home.
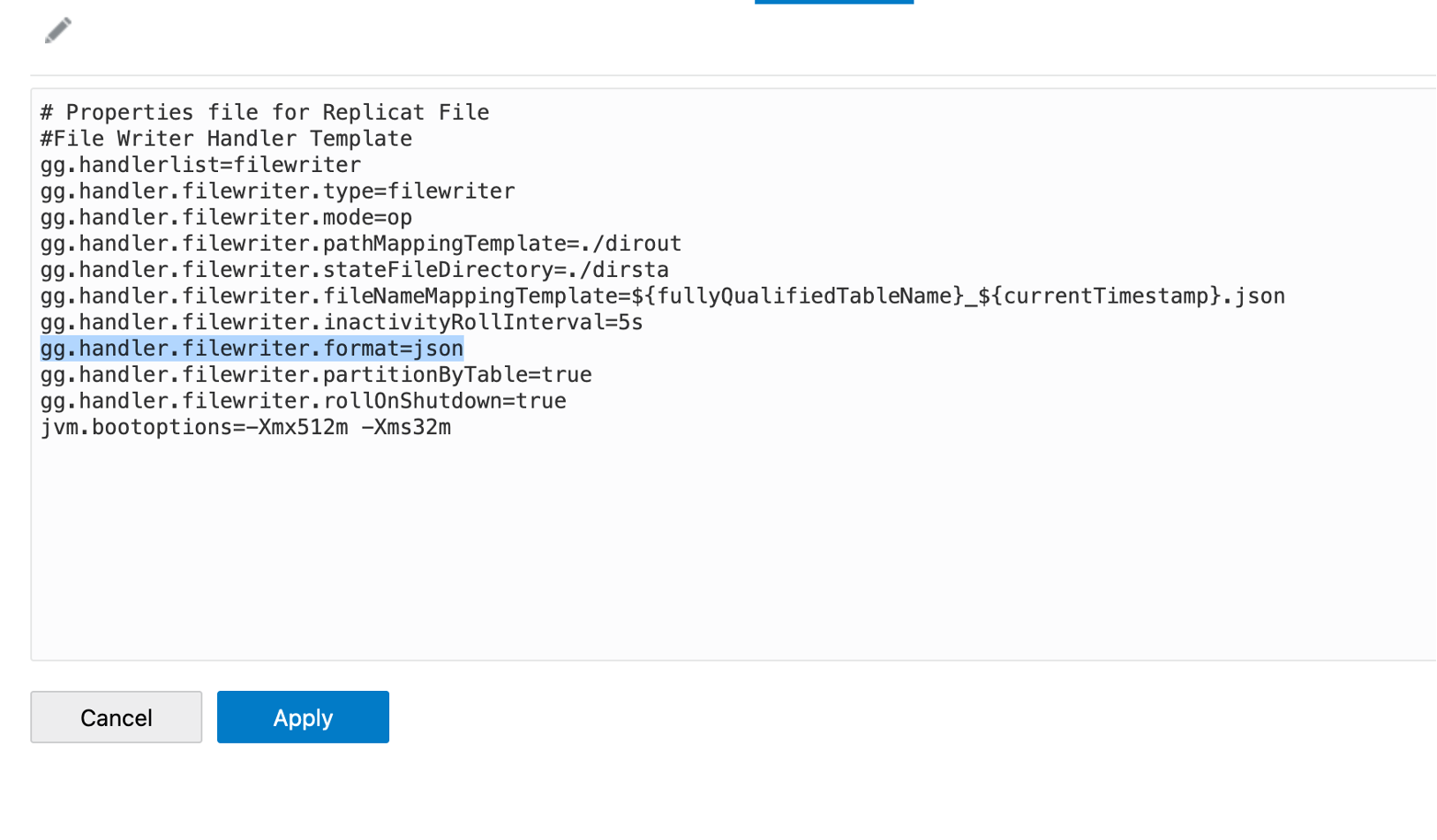


As I’ve selected the file writer format as JSON, I’ll use “JSON Formatters” from the pluggable formatters of GoldenGate for Big Data. You can use File Writer Handler together with JSON Formatters in the same replicat. You can get more details about them from the product documentation (File Writer Handler & Pluggable Formatters)
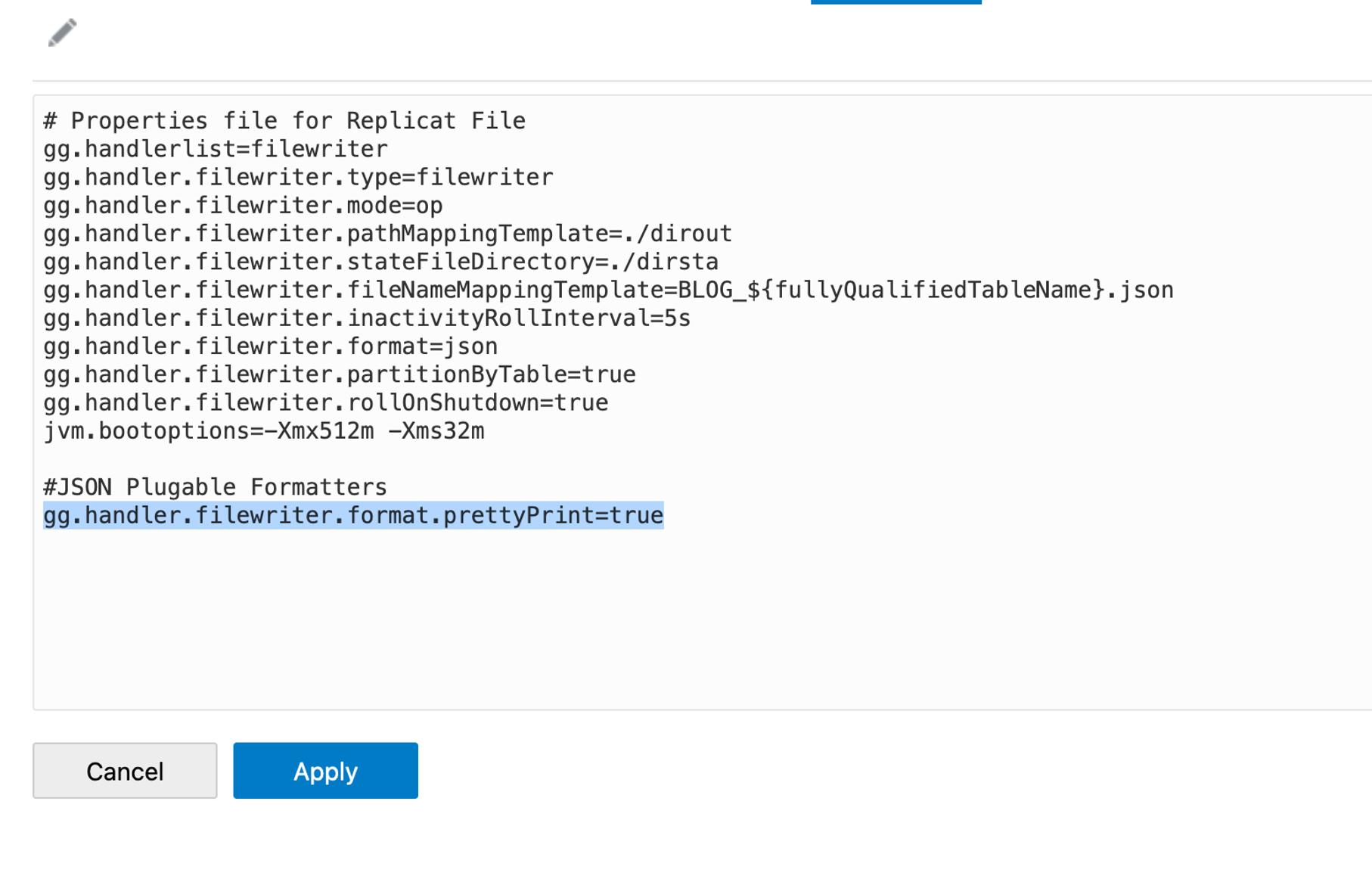
The first thing I want to do is to be able to view the file in a more readable format. To do that, I’m using a json formatter property named “gg.handler.filewriter.format.prettyPrint”. When set to true, it formats the data with space for easy reading. Let’s add it to our replicat, set to true and run. Now my messages will be reformatted and will be more readable.

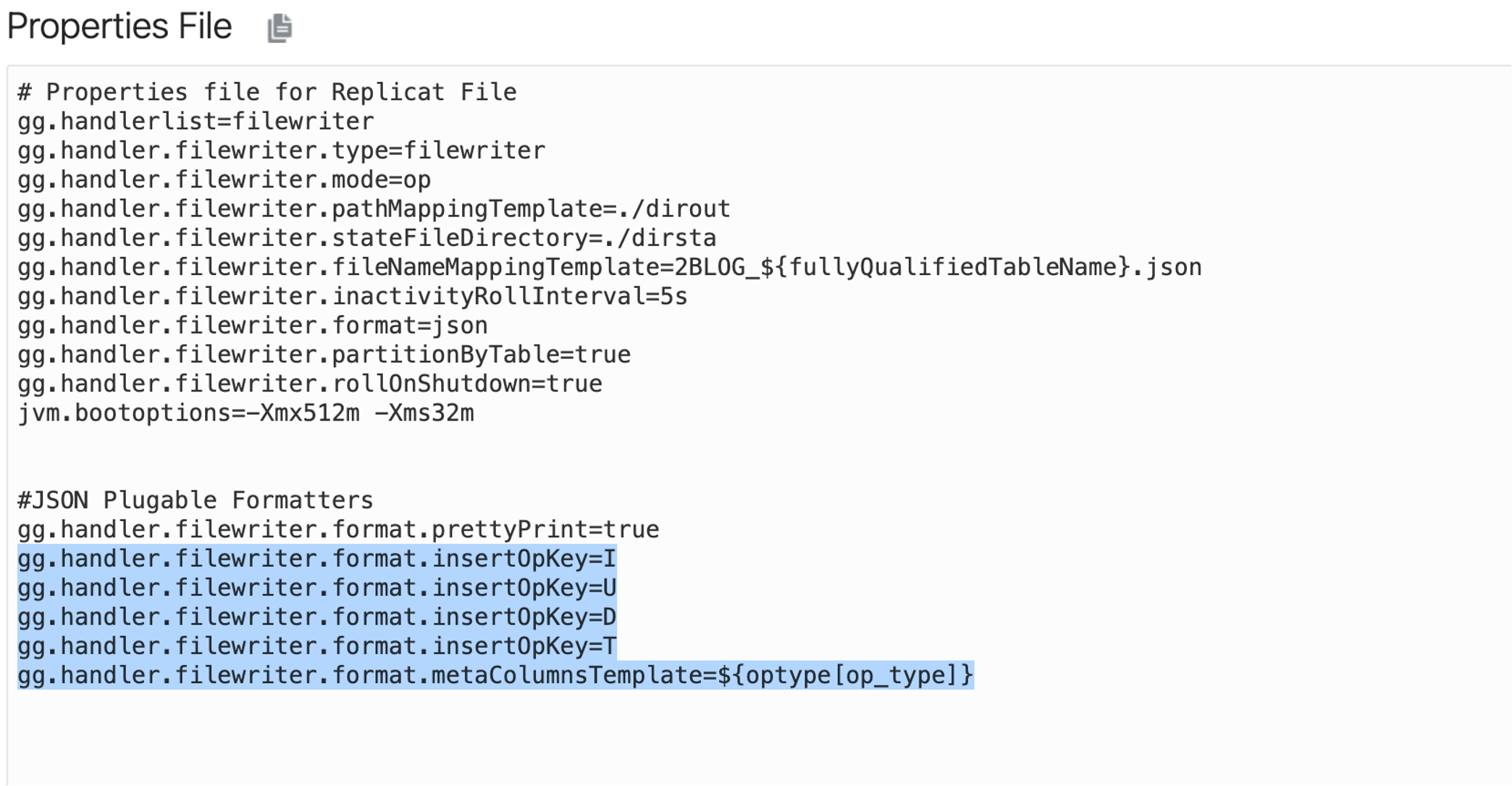
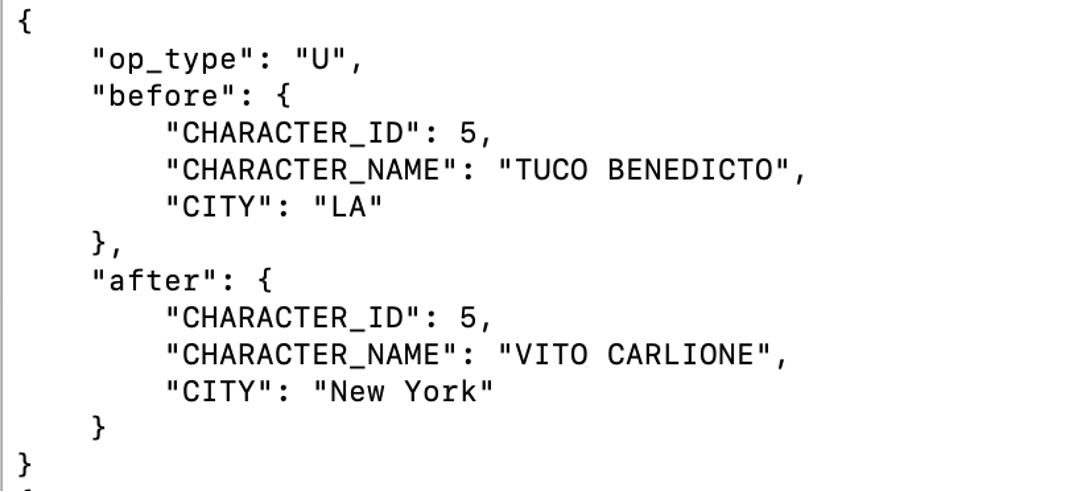
The next thing I want to do is to add operation types to the messages to be able to see what type of source operations generated these messages. JSON Formatter provides a property called “insertOpKey” covering each insert, update, delete and truncate operation. If I want to see only insert operations, I can add only that one. If I need to see all of them, I need to add all. For this blog, I’ll add all and run the replicat. I will also need another property called “gg.handler.filewriter.format.metaColumnTemplate”. Meta Columns can be used to enrich the message with different metadata field information coming from the source database. Meta Columns are dynamic; but, there is also a static one available. I’ll set metaColumnTemplate to operation type; but there are more choices that can be used. You can get more details on meta column template here.
JSON formatters can be used for flattening JSON messages as well. There is a specific nesting property named “gg.handler.name.format.flatten” and it should be set to true. In flattened messages, another json formatter property that can be used is “jsonDelimiter”. It inserts a delimiter between generated JSONs and they can be parsed more easily. In addition, it can be used with a CDATA[] wrapper. CDATA[] preserves the whitespace. For example, if you set the property as “gg.handler.filewriter.format.jsonDelimiter=CDATA[/n]”, it would use “/n” as the delimiter.
Let’s run the previous example as flattened and use “/n” as delimiter.
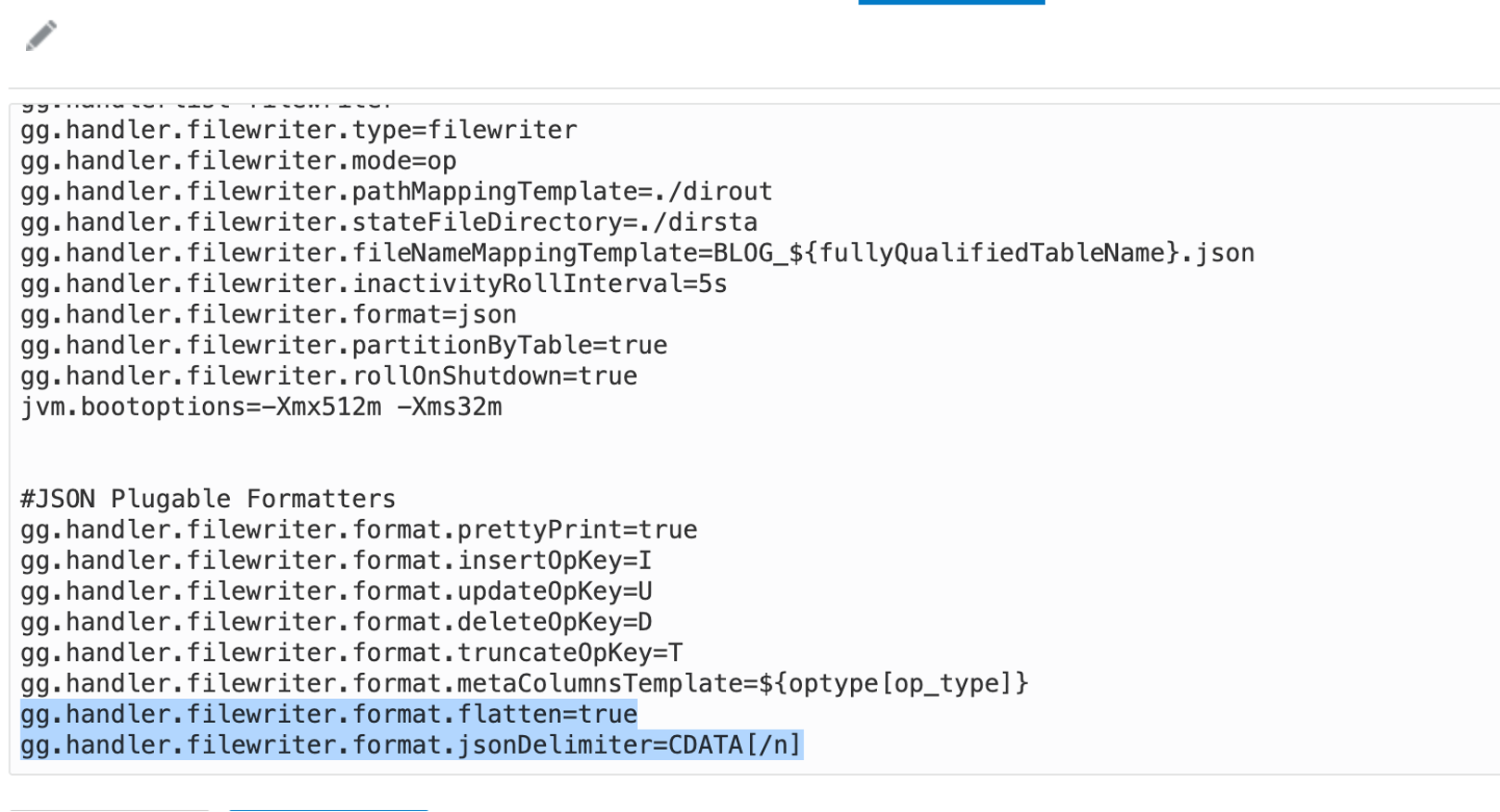

Now, let’s see how “null” values are represented in JSON messages generated by the JSON Formatter. By default, a null value is published as string “null”. Below is a sample JSON message with a default null field.

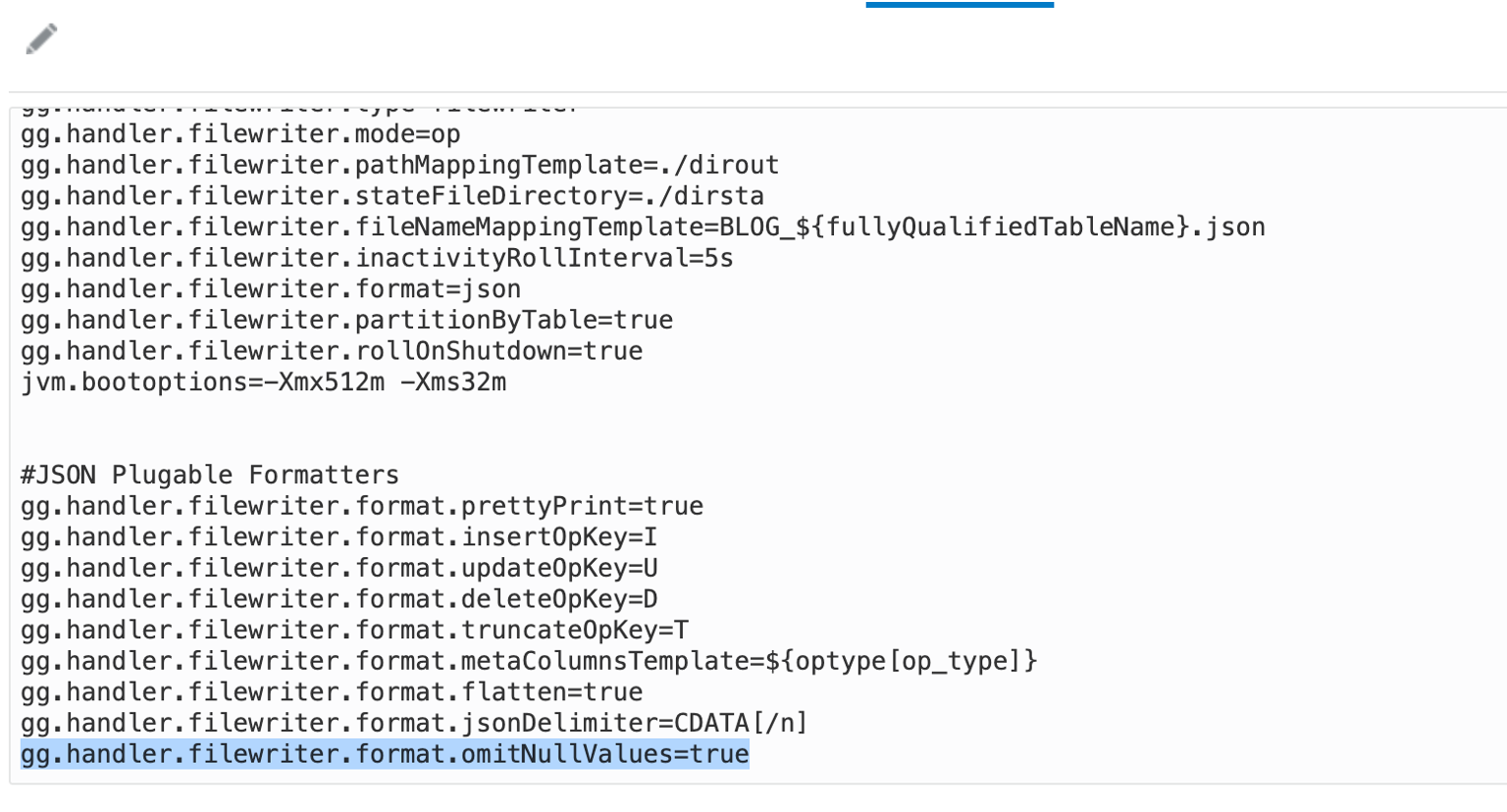
One option with the null values is using “gg.handler.filewriter.format.omitNullValues” property in the JSON Formatter. When set to “true”, null value will be omitted in the json message.

Pluggable Formatters & Kafka
As I mentioned earlier in the blog, Pluggale Formatters can be used together with different event handlers. Kafka Handler is another GoldenGate for Big Data handler where Plugable Formatters can be used. Kafka Handler is designed to stream CDC operations to Kafka topics. For more details about GoldenGate for Big Data Kafka Handler, you can check the documentation from this link.
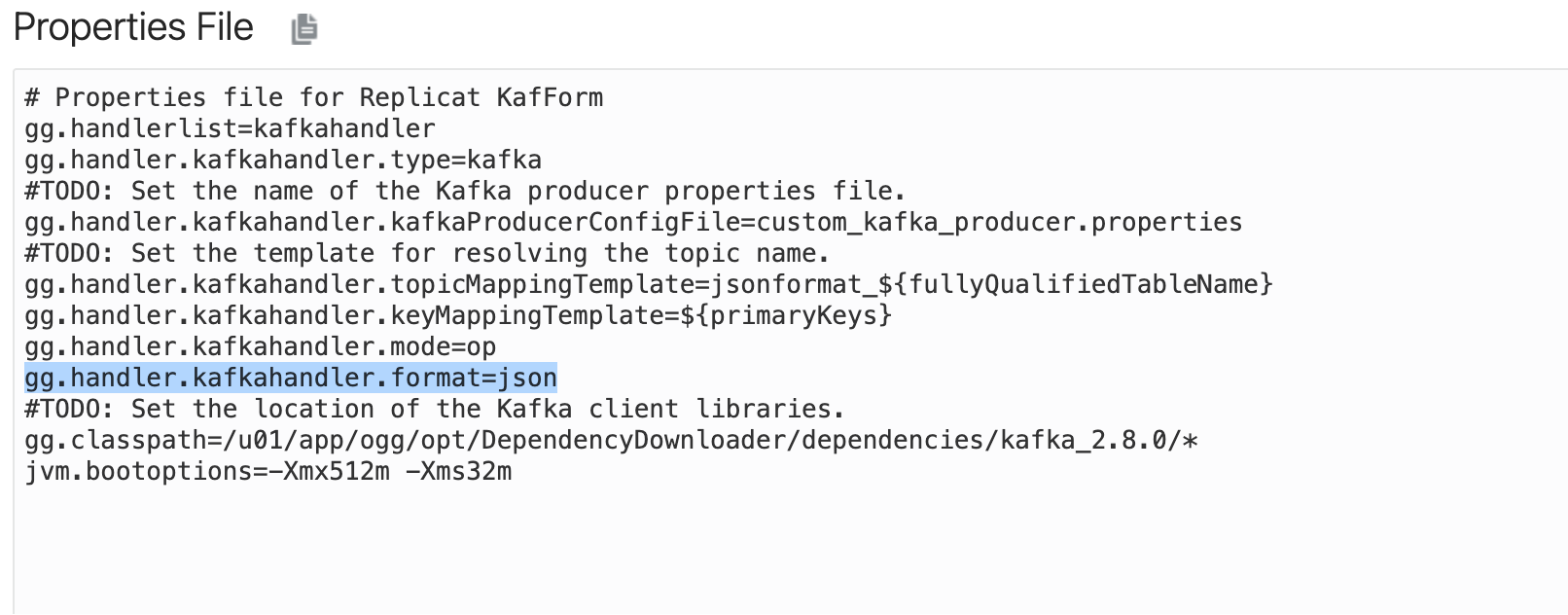
GoldenGate for Big Data Kafka Handler supports xml, delimitedtext, json, json_row, avro_row and avro_op payload formats. Pluggable Formatters can be applied to these payloads generated by Kafka Handler. In GoldenGate for Big Data, there are pluggable formatters available for XML, delimitedtext, Avro and JSON payloads. Depending on the payload type configured in Kafka Handler, an appropriate pluggable formatter can be used within the kafka replicat properties with Kafka Handler. As I focus on JSON in this blog, I’ll share an example where Kafka Handler is used to produce a JSON payload from a source trail file.
First, let’s see how GoldenGate for Big Data Kafka Handler produces a JSON payload without any formatters.

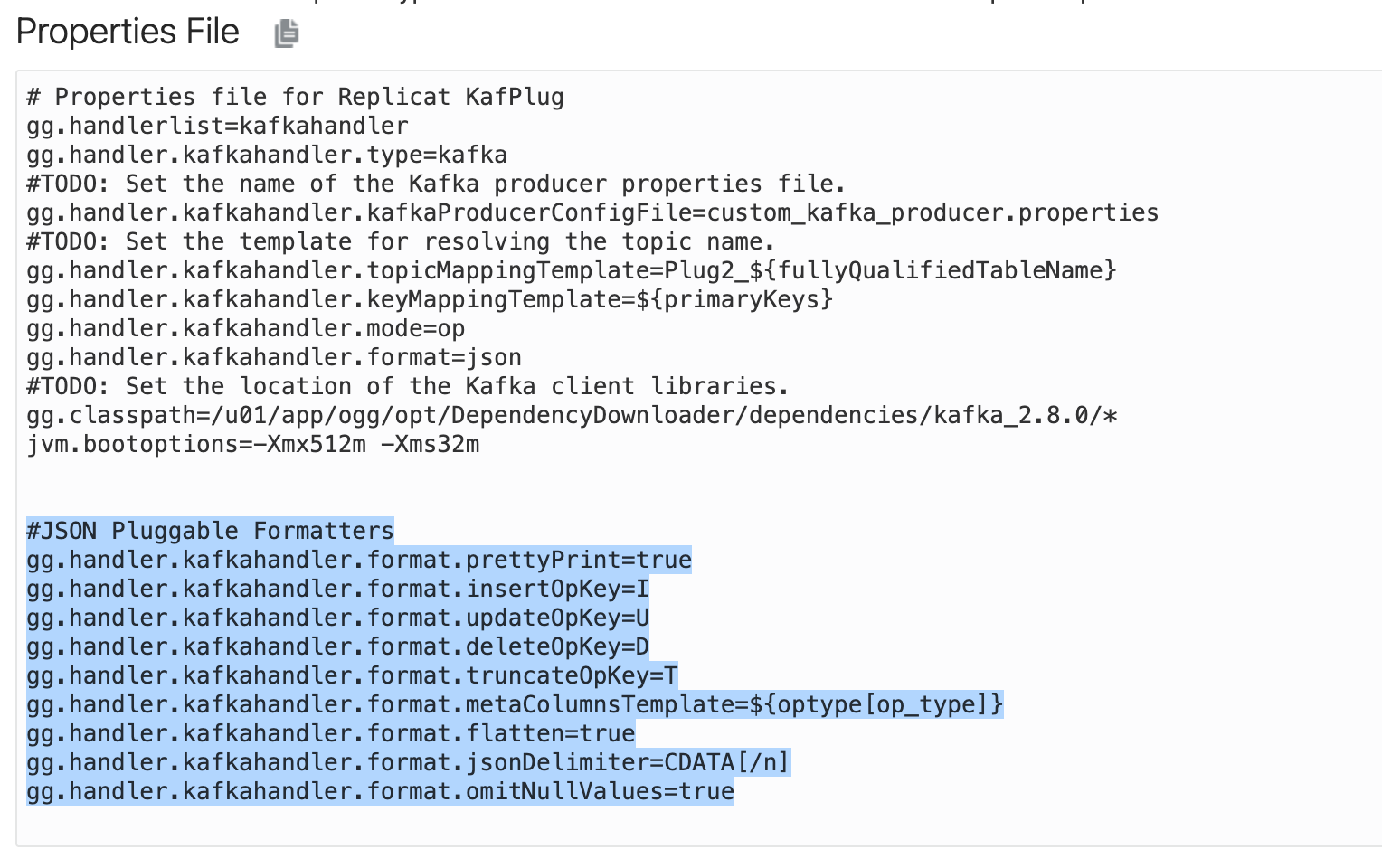
We can apply the same JSON Formatter properties to GoldenGate for Big Data Kafka Handler as well. To use JSON Formatter with Kafka Handler, I need to name the properties as “kafkahandler”.

Conclusion:
GoldenGate for Big Data Pluggable Formatters is a very powerful and flexible tool to enhance various message formats. Pluggable Formatters can be used with various GoldenGate for Big Data Event handlers and enhances the messages depending on their types. In this blog, we’ve seen JSON Formatter details; but, there are pluggable formatters available for Avro_Row, Avro_Operation, Avro_Object_Container, DelimitedText and XML as well. You can get details about these formatters from the GoldenGate for Big Data documentation and apply in your replicats where applicable.
