Contributed by: Shrinidhi Kulkarni, Staff Solutions Engineer, Oracle
Use case: Replication of data trails present on AWS AMI Linux instance into Kinesis Data Stream (AWS Cloud) using Oracle GoldenGate for Big Data.
Architecture:
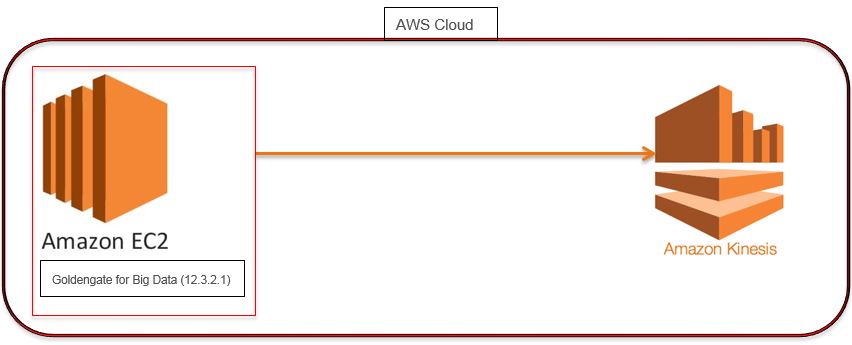
- GoldenGate For Big Data: Oracle GoldenGate 12.3.2.1
- AWS EC2 Instance: AMI Linux
- Amazon Kinesis
Highlights:
- How to configure GoldenGate for Big Data(12.3.2.1)
- How to configure GoldenGate Big Data Target handlers
- How to create AWS Kinesis Data Stream
Connecting To Your Linux Instance from Windows Using PUTTY
- Please refer to the following link & the instructions in it that explain how to connect to your instance using PUTTY.
- And also on how to Transfer files to your instance using WinSCP. https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/putty.html
Download the GoldenGate for Big Data Binaries, Java (JDK or JRE) version 1.8 & Amazon Kinesis Java SDK
- Download and install GoldenGate for Big Data 12.3.2.1.1, Here is the link: http://www.oracle.com/technetwork/middleware/goldengate/downloads/index.html
- The Oracle GoldenGate for Big Data is certified for Java 1.8. Before installing and running Oracle GoldenGate 12.3.2.1.1, you must install Java (JDK or JRE) version 1.8 or later. Either the Java Runtime Environment (JRE) or the full Java Development Kit (which includes the JRE) may be used.
- The Oracle GoldenGate Kinesis Streams Handler uses the AWS Kinesis Java SDK to push data to Amazon Kinesis. The Kinesis Steams Handler was designed and tested with the latest AWS Kinesis Java SDK version 1.11.429 and for creating streams/ shards.
- Create a Kinesis data stream(not included under Free-tier)on your AWS Instance, Follow the link for reference-
https://docs.aws.amazon.com/streams/latest/dev/learning-kinesis-module-one-create-stream.html
- It is strongly recommended that you do not use the AWS account root user or ec2-user for your everyday tasks, even the administrative ones. You need to create a new user with access key & secret_key for AWS, use the following link as reference to do the same :
https://docs.aws.amazon.com/general/latest/gr/managing-aws-access-keys.html
- Attach the following policies to the newly created user to allow access and GET/Put Operations on Kinesis data stream:
- AWSLambdaKinesisExecutionRole-Predefined Policy in AWS
- You need to attach the following inline policy as json:
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "kinesis:*",
"Resource": [
"arn:aws:kinesis:<your-aws-region>:<aws-account-id>:stream/<kinesis-stream-name>"
]
}
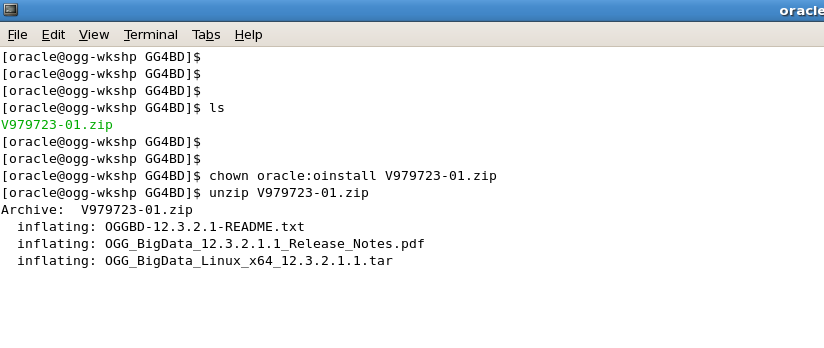
- Unzip the GoldenGate for big data (12.3.2.1) zip file :
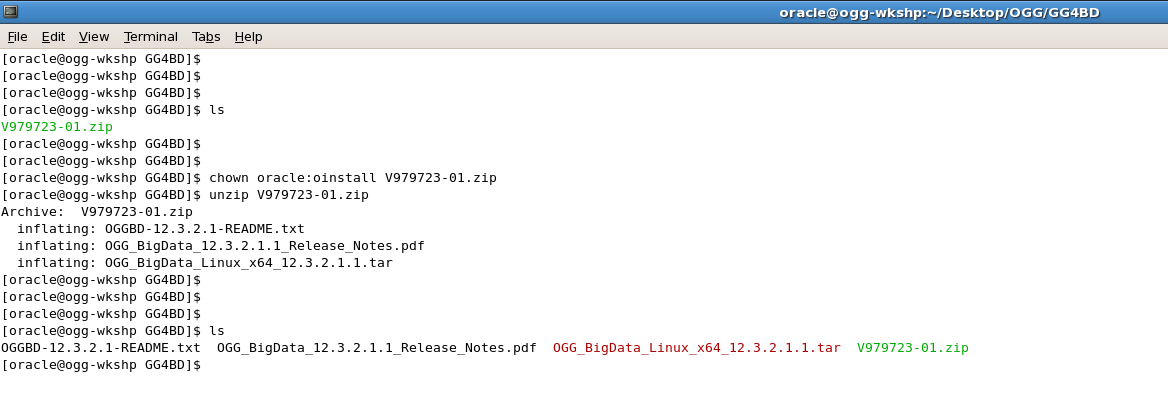
- After you Unzip the Downloaded GoldenGate for Big Data Binary, the directory structure looks like this:
- Now extract the GoldenGate 12.3.2.1.1 .tar file using “tar -xvf” command.
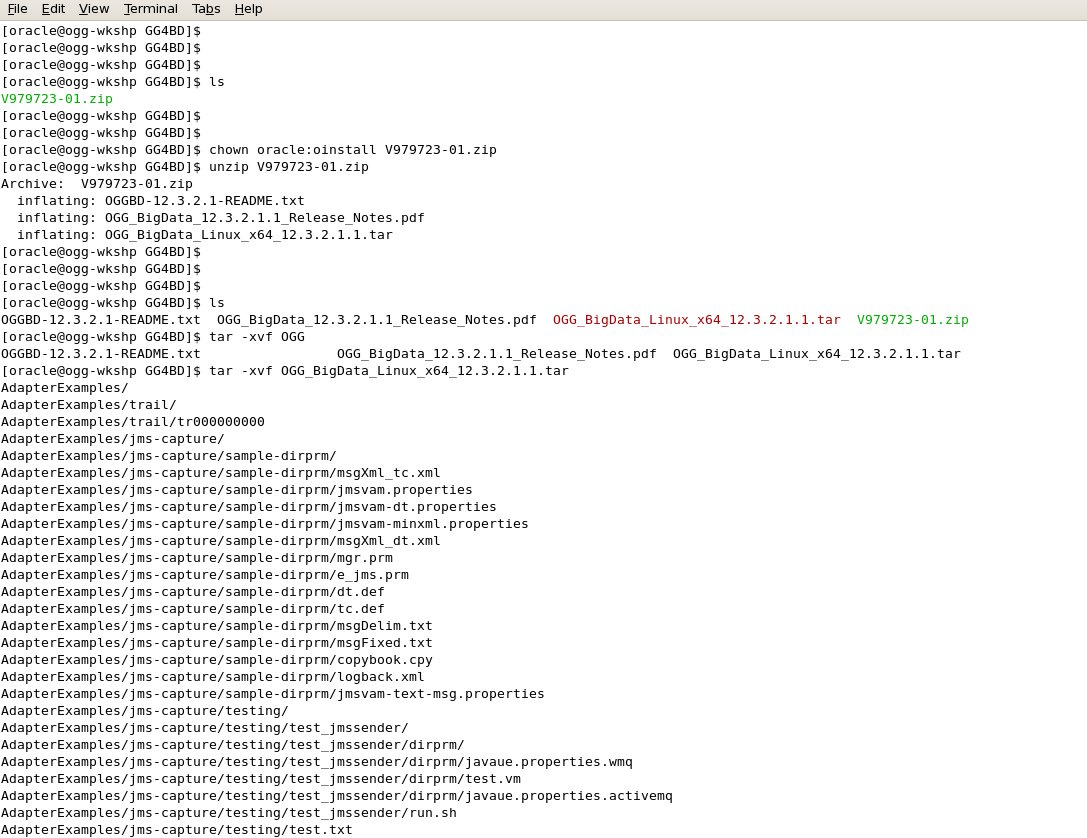
- After the “tar –xvf” operation finishes, the following Big-Data target handlers are extracted:

- You can have a look on the directory structure( files extracted) and then go to “AdapterExamples” directory to make sure kinesis streams handler is extracted:
- The Kinesis_Streams directory under big-data contains Kinesis Replicat parameter file(kinesis.prm) and kinesis properties file (kinesis.props).

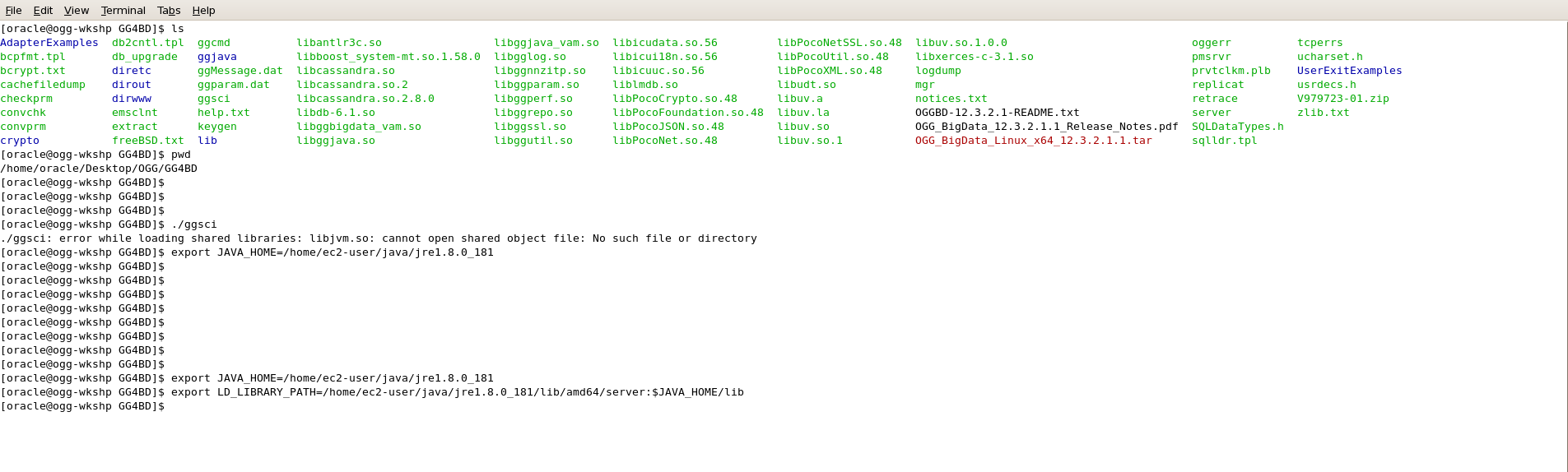
- Before you log into GoldenGate instance using GGSCI, set the JAVA_HOME & LD_LIBRARY_PATH to the JAVA 1.8 directory otherwise it would show up an error as following:

- Export the JAVA_HOME & LD_LIBRARY_PATH as shown below:
export JAVA_HOME=<path-to-your-Java-1.8>/jre1.8.0_181
export LD_LIBRARY_PATH=<path-to-your-Java-1.8>/lib/amd64/server:$JAVA_HOME/lib
- Once you’re done, log into GoldenGate Instance using ./ggsci command and issue create subdir command to create the GoldenGate specific directories:
- Configure the Manager parameter file and add an open PORT to it:
Example: edit param mgr
PORT 1080
- Traverse back to GoldenGate Directory, execute ./ggsci and Add replicat in the GoldenGate instance using the following command:
add replicat kinesis, exttrail AdapterExamples/trail/tr
[NOTE: A demo trail is already present at the location: AdapterExamples/trail/tr]
- Copy the parameter file of the replicat (mentioned above) to ./dirprm directory of the Goldengate Instance.
- Copy the properties file (kinesis.props) to dirprm folder after making the desired changes.
Replicat Param File & kinesis properties file:
REPLICAT kinesis -- Trail file for this example is located in "AdapterExamples/trail" directory
-- Command to add REPLICAT
-- add replicat kinesis, exttrail AdapterExamples/trail/tr
TARGETDB LIBFILE libggjava.so SET property=dirprm/kinesis.props
REPORTCOUNT EVERY 1 MINUTES, RATE
GROUPTRANSOPS 1
MAP QASOURCE.*, TARGET QASOURCE.*;
Kinesis Properties File(kinesis.props):
gg.handlerlist=kinesis
gg.handler.kinesis.type=kinesis_streams
gg.handler.kinesis.mode=op
gg.handler.kinesis.format=json
gg.handler.kinesis.region=<your-aws-region>
#The following resolves the Kinesis stream name as the short table name
gg.handler.kinesis.streamMappingTemplate=<Kinesis-stream-name>
#The following resolves the Kinesis partition key as the concatenated primary keys
gg.handler.kinesis.partitionMappingTemplate=QASOURCE
#QASOURCE is the schema name used in the sample trail file
gg.handler.kinesis.deferFlushAtTxCommit=true
gg.handler.kinesis.deferFlushOpCount=1000
gg.handler.kinesis.formatPerOp=true
#gg.handler.kinesis.proxyServer=www-proxy-hqdc.us.oracle.com
#gg.handler.kinesis.proxyPort=80
goldengate.userexit.writers=javawriter
javawriter.stats.display=TRUE
javawriter.stats.full=TRUE
gg.log=log4j
gg.log.level=DEBUG
gg.report.time=30sec
gg.classpath=<path-to-your-aws-java-sdk>/aws-java-sdk-1.11.429/lib/*:<path-to-your-aws-java-sdk>/aws-java-sdk-1.11.429/third-party/lib/*
##Configured with access id and secret key configured elsewhere
javawriter.bootoptions=-Xmx512m -Xms32m -Djava.class.path=ggjava/ggjava.jar
##Configured with access id and secret key configured here
javawriter.bootoptions=-Xmx512m -Xms32m -Djava.class.path=ggjava/ggjava.jar -Daws.accessKeyId=<access-key-of-new-created-user> -Daws.secretKey=<secret-ke-new-created-user>
- Make sure you edit the classpath, accessKeyId & Secret Key (of newly-created-user) correctly.
- After making all the necessary changes you can start the kinesis replicat, which would replicate the trail data to kinesis Data stream.
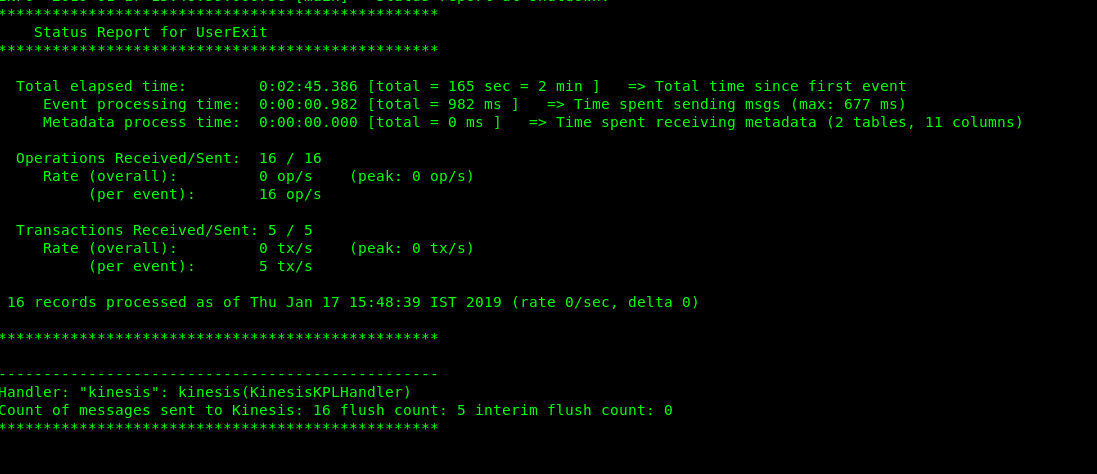
- Crosscheck for kinesis replicat’s status, RBA and stats.
- Once you get the stats, you can view the kinesis.log from. /dirrpt directory which gives information about data sent to kinesis data stream and operations performed.
- You can also monitor the data that has been pushed into Kinesis data stream through AWS CloudWatch. Amazon Kinesis Data Streams and Amazon CloudWatch are integrated so that you can collect, view, and analyze CloudWatch metrics for your Kinesis data streams. For example, to track shard usage, you can monitor the following metrics:
- IncomingRecords: The number of records successfully put to the Kinesis stream over the specified time period.
- IncomingBytes: The number of bytes successfully put to the Kinesis stream over the specified time period.
- PutRecord.Bytes: The number of bytes put to the Kinesis stream using thePutRecord operation over the specified time period.
