Modern data architectures are rapidly evolving toward open, interoperable ecosystems. Enterprises increasingly store data in open formats such as Apache Iceberg on cloud object storage while leveraging multiple compute engines for analytics.
In this article, we demonstrate a complete end-to-end solution to query Apache Iceberg tables created in Snowflake and stored in Amazon S3, read directly from Oracle Autonomous AI Database (ADB) using the Polaris Open Catalog and Oracle’s DBMS_CATALOG package — with zero data movement, no ETL, no replication and enables seamless cross-platform analytics using open standards.
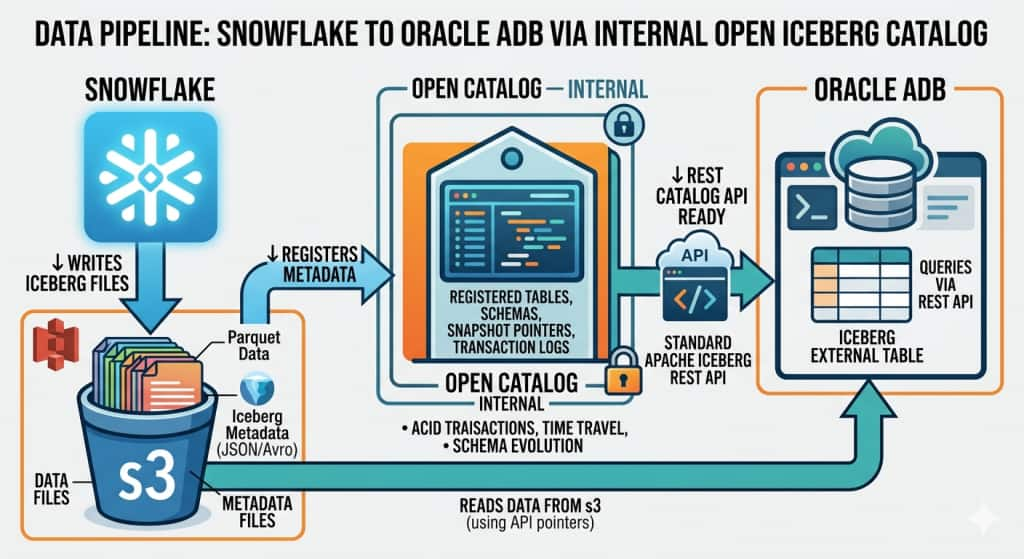
The architecture leverages the following:
- Apache Iceberg as the open table format stored on S3
- Snowflake Polaris Open Catalog as the REST-based Iceberg catalog
- Autonomous AI Database’s
DBMS_CATALOGpackage to mount and query the catalog directly
Apache Iceberg — And Why Does It Matter? – Apache Iceberg is an open table format designed for large-scale analytic datasets stored in cloud object stores like Amazon S3, Azure Data Lake, or Google Cloud Storage. It brings database-like reliability and performance to data lakes.
Open Catalog (Polaris) — Snowflake Open Catalog, built on the Apache Polaris project, is an open-source, REST-compliant Iceberg catalog implementation. It implements the Iceberg REST Catalog specification, meaning any Iceberg-compatible engine can discover and read catalog metadata through a standard HTTP API — without proprietary protocols. It enables multi-engine access (Snowflake, Autonomous AI Database, Spark, etc.) This openness allows Autonomous AI Database to query Iceberg tables without needing native Snowflake connectivity.
Overview of Layers
| Layer | Component | Role |
| Catalog | Snowflake Open Catalog (Polaris) | Iceberg REST catalog — manages namespace & table metadata |
| Storage | AWS S3 (us-west-2) | Stores Iceberg data (Parquet) & metadata (JSON) files |
| Write Operation | Snowflake | Creates & Manages Iceberg tables |
| Read Operation | Autonomous AI Database | Reads Iceberg data via DBMS_CATALOG |
| Auth — Catalog | OAuth2 client_credentials | Autonomous AI Database authenticates to Polaris REST API |
| Auth — Storage | AWS Static Access Key | Autonomous AI Database reads S3 files directly |
Data Flow
- Snowflake writes Iceberg tables (data as Parquet + metadata as JSON) into S3.
- Polaris Open Catalog tracks the namespace, table schema, and snapshot metadata via its REST API.
- Autonomous AI Database mounts the Polaris catalog using
DBMS_CATALOG.MOUNT_ICEBERG, authenticating via OAuth2. - When a query runs in Autonomous AI Database, it resolves table metadata from Polaris, then reads Parquet files directly from S3 using static AWS credentials.
- Rows are returned to the Oracle session — no data ever leaves S3 or gets copied into Oracle.
Architecture – Data Pipe Line
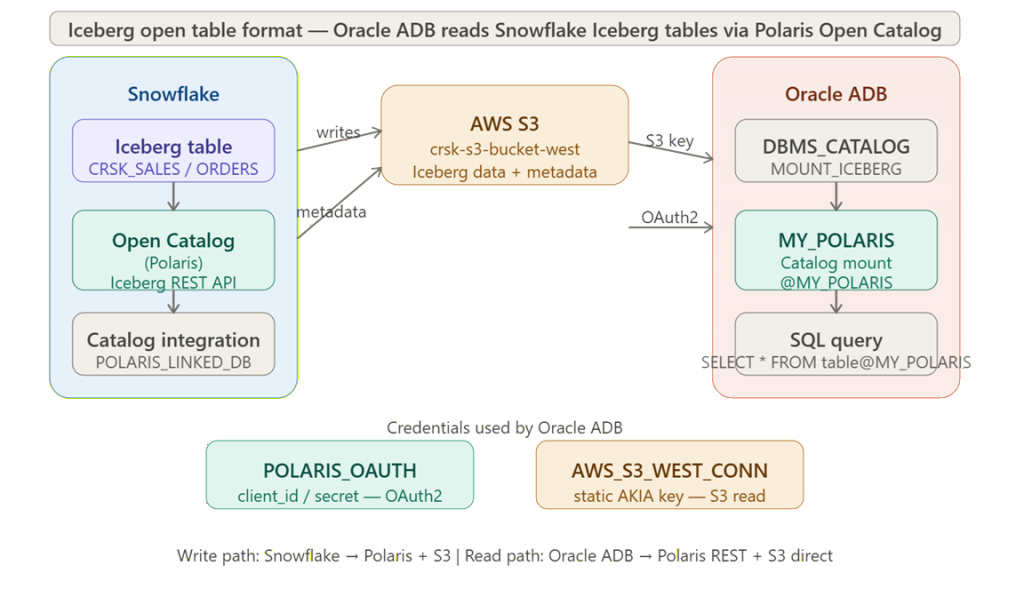
Implementation
Note: For easy reference, I have shown my examples of Polaris Catalog Name, Linked DB, Namespace, Tables, S3 Bucket ( and associated endpoints ) in italics. You need to use your values appropriately.
Environment Values
| My Snowflake Account | mdlfbgh-crsk_polaris_catalog |
| Polaris Catalog Name | crsk_polaris_int_catalog |
| CATALOG INTEGRATION | crsk_polaris_int |
| Polaris Linked DB | crsk_polaris_db |
| Namespace / Schema | sales_ns |
| Tables | crsk_sales,crsk_orders |
| S3 Bucket | crsk-s3-bucket-west (us-west-2) |
| Region | Snowflake main account : us-west-2Open Catalog account : us-west-2S3 bucket :us-west-2 ( oregon) : |
Section A : AWS
- Create S3 bucket and appropriate access level rights in policies and IAM ROLE at AWS.
Section B : Snowflake
B1. Create internal catalog
An Internal Catalog is where Autonomous AI Database will connect. It is configured with VENDED_CREDENTIALS access delegation:
- Catalog Name:
<catalog_name> - Type: Internal
- Storage Provider: S3
- Default Base Location:
<yours AWS S3 bucket location> - Access Delegation Mode:
VENDED_CREDENTIALS
B.2 — Create a Service Connection
Within the internal catalog, a Service Connection was created via the Polaris UI. This generates an OAuth2 client_id and client_secret, which is used later in Autonomous AI Database to authenticate to the Polaris REST API.
B.3 — Create Catalog Integration in Snowflake
This step links Snowflake to the Polaris internal catalog so that Iceberg tables created in Snowflake are registered in Polaris:
Here is my example
CREATE OR REPLACE CATALOG INTEGRATION crsk_polaris_int
CATALOG_SOURCE = POLARIS
TABLE_FORMAT = ICEBERG
REST_CONFIG = (
CATALOG_URI = 'https://<org>-<account>.snowflakecomputing.com/polaris/api/catalog'
CATALOG_NAME = 'crsk_polaris_int_catalog'
ACCESS_DELEGATION_MODE = VENDED_CREDENTIALS )
REST_AUTHENTICATION = (
TYPE = OAUTH
OAUTH_CLIENT_ID = '<your_client_id>'
OAUTH_CLIENT_SECRET = '<your_client_secret_key>'
OAUTH_ALLOWED_SCOPES = ('PRINCIPAL_ROLE:ALL'))
ENABLED = TRUE;B4. Create Catalog-Linked Database
Link Snowflake database to Polaris Catalog.
CREATE OR REPLACE DATABASE crsk_polaris_db
LINKED_CATALOG = (
CATALOG = 'crsk_polaris_int'
NAMESPACE_MODE = IGNORE_NESTED_NAMESPACE
SYNC_INTERVAL_SECONDS = 30
);B5. Create namespace & Tables
USE DATABASE crsk_polaris_db;
CREATE SCHEMA sales_ns;
USE SCHEMA sales_ns;CREATE ICEBERG TABLE crsk_sales (
sale_id INT,
customer_id INT,
product STRING,
amount NUMBER(10,2),
sale_date DATE );
CREATE ICEBERG TABLE crsk_orders (
order_id INT,
customer_id INT,
status STRING,
total NUMBER(10,2),
order_date DATE);B6. Insert records
INSERT INTO crsk_sales VALUES
(1, 101, 'Laptop', 1200.00, '2024-01-15'),
(2, 102, 'Phone', 800.00, '2024-01-16'),
(3, 103, 'Tablet', 450.00, '2024-01-17'),
(4, 101, 'Monitor', 350.00, '2024-01-18');
INSERT INTO crsk_orders VALUES
(1001, 101, 'SHIPPED', 1200.00, '2024-01-14'),
(1002, 102, 'DELIVERED', 800.00, '2024-01-15'),
(1003, 103, 'PENDING', 450.00, '2024-01-16'),
(1004, 101, 'PROCESSING', 350.00, '2024-01-17');Note: As soon table created, Snowflake has written Iceberg-format Parquet files to S3 , Polaris has registered the table metadata and reflects in open catalog under SALES_NS schema The data is now accessible to any REST Catalog-compatible engine.
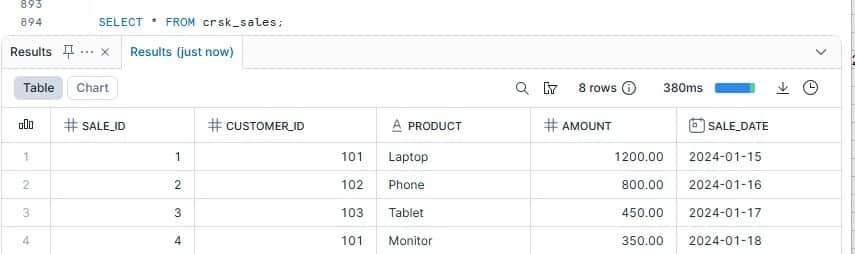
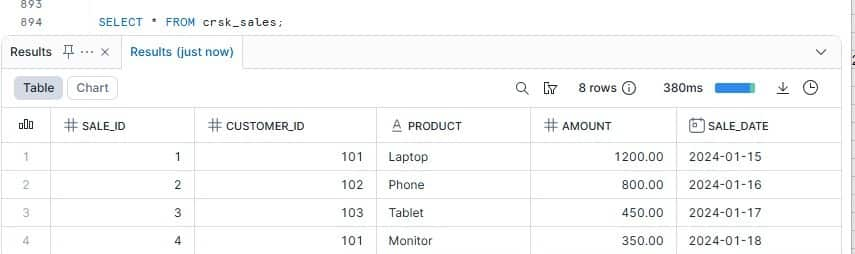
Snapshot from Snowflake – Catalog
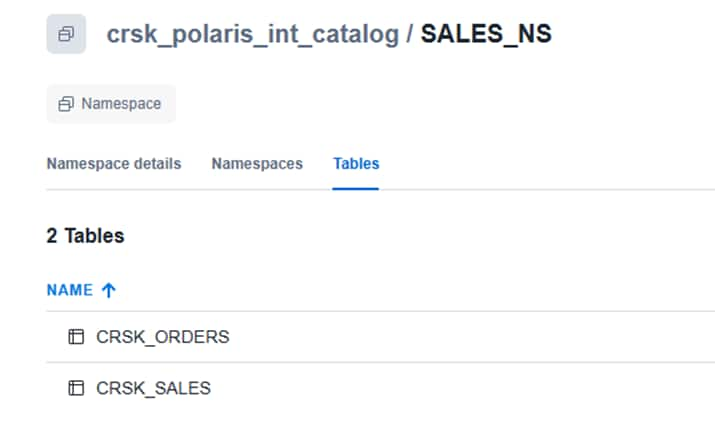
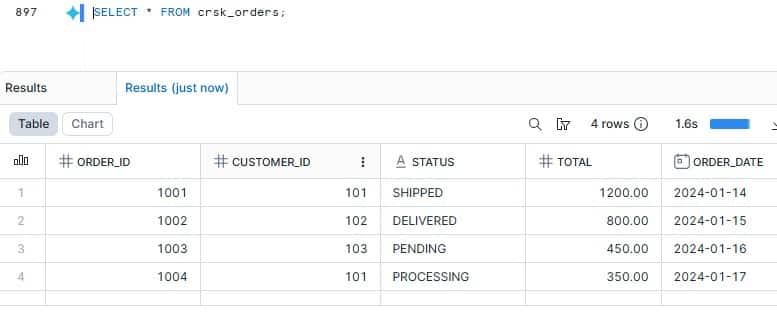
B7. Query the data in Snowflake
SELECT * FROM crsk_sales;
SELECT * FROM crsk_orders;
Section C : Autonomous AI Database
C1. Ensure privileges and Network ACL’s are granted
1.1 Ensure DWROLE is granted to ADMIN
1. 2 Provide Network_ACL’s to all endpoints like Polaris endpoint, S3 regional and bucket endpoint
My Example:
-- Polaris endpoint
BEGIN
DBMS_NETWORK_ACL_ADMIN.APPEND_HOST_ACE(
host => 'mdlfbgh-crsk_polaris_catalog.snowflakecomputing.com',
lower_port => 443,
upper_port => 443,
ace => xs$ace_type(
privilege_list => XS$NAME_LIST('http', 'http_proxy'),
principal_name => 'ADMIN',
principal_type => xs_acl.ptype_db));
END;
/
Similar to above, you need to grant network ACL for S3 regional endpoint and bucket specific endpoint host. Here is my endpoints for reference
-- S3 regional endpoint host=> 's3.us-west-2.amazonaws.com',
-- S3 bucket-specific endpoint host=> 'crsk-s3-bucket-west.s3.us-west-2.amazonaws.com',
Note: ⚠ CRITICAL: DBMS_CATALOG requires ‘http’ and ‘http_proxy’ privileges — not just ‘connect’ and ‘resolve’. Missing http_proxy causes silent failures.
Cross-Check:
SELECT HOST, LOWER_PORT, UPPER_PORT, PRIVILEGE, PRINCIPAL FROM DBA_HOST_ACES WHERE PRINCIPAL = 'ADMIN' ORDER BY HOST;Ref dbms_network_acl_admin documentation for reference
C2. Generate Polaris OATH Token
Example
$> export TOKEN=$(curl -s -X POST \
"https://mdlfbgh-crsk_polaris_catalog.snowflakecomputing.com/polaris/api/catalog/v1/oauth/tokens" \
-H "Content-Type: application/x-www-form-urlencoded" \
-d "grant_type=client_credentials&client_id=<yourclientid>=&client_secret=<yourclientsecret>=&scope=PRINCIPAL_ROLE:ALL" \
| python3 -c "import sys,json; print(json.load(sys.stdin)['access_token'])")
$> echo $TOKEN - holds token value, valid for 3600 secC3. Create Polaris OAUTH Credential
Copy the access_token value from the previous response
BEGIN
DBMS_SHARE.CREATE_BEARER_TOKEN_CREDENTIAL(
credential_name => 'POLARIS_OAUTH',
bearer_token => '<TOKEN>', # Initially it is required
token_endpoint => 'https://mdlfbgh-crsk_polaris_catalog.snowflakecomputing.com/polaris/api/catalog/v1/oauth/tokens',
client_id => '<your_client_id>',
client_secret => '<your_client_secret>',
token_refresh_rate => 3600,
token_scope => 'PRINCIPAL_ROLE:ALL',
grant_type => 'client_credentials'
);
END;
/Cross-check:
SELECT CREDENTIAL_NAME, USERNAME, ENABLED FROM ALL_CREDENTIALS WHERE CREDENTIAL_NAME IN ('POLARIS_OAUTH');C4. Create AWS S3 Storeage Credential
Must use a STATIC AWS Access Key. Autonomous AI Database needs a cloud credential to read the Iceberg data + metadata files from S3.
BEGIN
DBMS_CLOUD.CREATE_CREDENTIAL(
credential_name => 'AWS_S3_WEST_CONN',
username => '<aws_access_key_id>',
password => '<aws_secret_access_key>'
);
END;C5. Mount the Polaris Open Catalog
BEGIN
DBMS_CATALOG.MOUNT_ICEBERG(
catalog_name => 'MY_POLARIS',
endpoint => 'https://mdlfbgh-crsk_polaris_catalog.snowflakecomputing.com/polaris/api/catalog/v1/crsk_polaris_int_catalog',
catalog_credential => 'POLARIS_OAUTH',
data_storage_credential => 'AWS_S3_WEST_CONN',
catalog_type => 'ICEBERG_POLARIS'
);
END;
/Ref DBMS_CATALOG documentation for additional information
Cross-check:
SELECT CATALOG_NAME, CATALOG_TYPE, IS_ENABLED, IS_SYNCHRONIZED, OWNER, catalog_details FROM ALL_MOUNTED_CATALOGS ;
SELECT JSON_QUERY(DBMS_CATALOG.GET_LOCAL_CREDENTIAL_MAP('MY_POLARIS'),'$' PRETTY) FROM DUAL;Expected Output: IS_ENABLED=YES. Credential map shows POLARIS_OAUTH and AWS_S3_WEST_CONN ⚠ IS_SYNCHRONIZED=NO is expected and normal.
C6. Query Iceberg Tables via Oracle Catalog
-- Fetch schema
SELECT * FROM TABLE(DBMS_CATALOG.GET_SCHEMAS(catalog_name => 'MY_POLARIS'));
-- Test metadata query
SELECT owner, table_name FROM all_tables@MY_POLARIS;
-- Query iceberg Tables
SELECT * FROM "SALES_NS"."CRSK_SALES"@MY_POLARIS;
SELECT * FROM "SALES_NS"."CRSK_ORDERS"@MY_POLARIS;Here is the output of iceberg tables queried from sqldeveloper
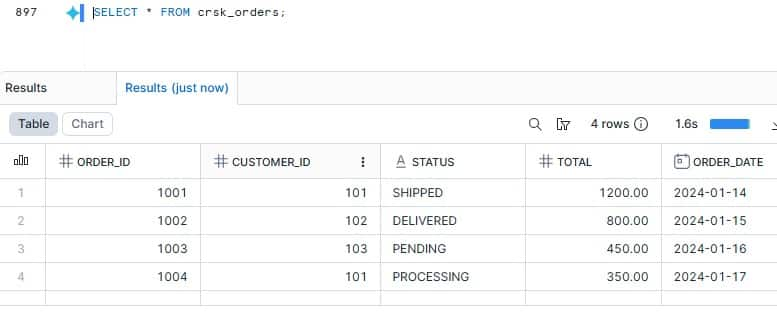
Result: Data stored in S3 via Snowflake is successfully queried from Autonomous AI Database
Advantages of This Approach
1. Zero Data Movement: Iceberg data files stay in S3. Autonomous AI Database resolves metadata from Polaris and reads Parquet files directly. There is no copy, no replication pipeline, and no sync job to maintain.
2. Open Standards Throughout: The entire integration uses open protocols — the Iceberg REST Catalog specification for catalog access and standard AWS S3 APIs for storage. No proprietary formats or connectors are required on either side.
3. Real-Time Reads: Autonomous AI Database reads the current Iceberg snapshot every time a query runs. Any new data inserted in Snowflake is immediately visible in Oracle without any refresh step.
4. Governance in One Place: Polaris Open Catalog is the single source of truth for schema, namespace, and table metadata. Whether Snowflake or Oracle (or a future engine) queries the data, they all see the same catalog state.
5. Engine Flexibility: Because Iceberg is an open standard and Polaris implements the open REST catalog spec, the same tables can be queried by Spark, Trino, Flink, or any other Iceberg-compatible engine — alongside Autonomous AI Database — without format conversion.
6. Separation of Concerns:
Storage, catalog, and compute are independently scalable
Conclusion
This solution demonstrates how modern data platforms can interoperate using open standards. By combining Snowflake Iceberg tables, Polaris Open Catalog, and Oracle Autonomous AI Database, organizations can build flexible, scalable, and vendor-neutral analytics architectures.
As enterprises adopt lakehouse patterns, this integration pattern provides a powerful foundation for unified analytics across cloud ecosystems without data duplication.
