Introduction
With Oracle AI Database 26ai, vector data types and embeddings are natively supported, enabling semantic search directly within the database. Customers can now not only store but also generate embeddings using ONNX models, making it easy to combine relational and semantic search in one system. By combining these capabilities with Oracle Globally Distributed Database, customers can create highly scalable vector search for their applications, powering use cases like semantic search, Retrieval-Augmented Generation (RAG), and agentic AIs. The vector data types work as is with sharded tables, enabling horizontal scalability for both queries and ingestion.
Using AI Vector Search with Globally Distributed Database
In this post we will walk you through some of the aspects of creating a vector store with Oracle Globally Distributed Database, providing examples of a sharded schema, loading the data into sharded tables, creating embeddings using ONNX model within the database and efficiently querying over mutiple shards. Below visual shows an overview of the system context and workflow which is used in this particular demonstration.
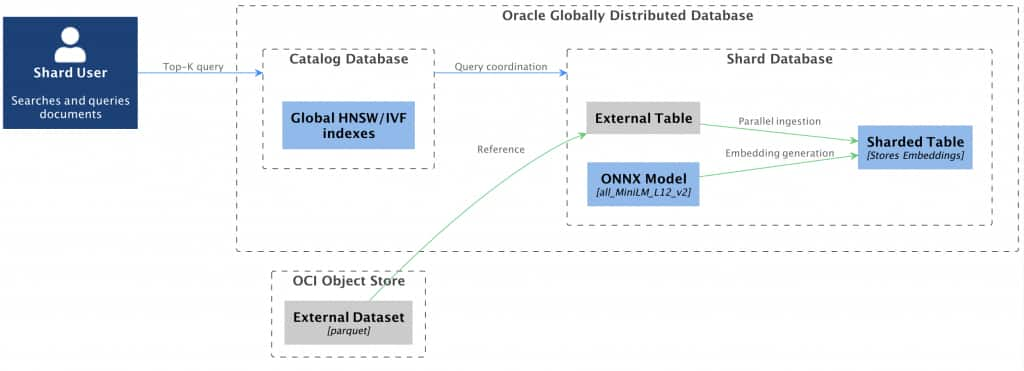
Loading ONNX Model for Sharded Database
We generate vector embedding using all_MiniLM_L12_v2 encoder model. This model is also prebuild and managed by Oracle and is available to download from OCI object store and can be directly loaded into the database. For the embedding generation and query, we load the model into the shard databases as well as the catalog database. Please go through the linked blog entry to know the list of permissions to be assigned to the shard user. These permissions can be assigned to the shard user via the catalog database post enabling shard ddl in the database session.
DECLARE
ONNX_MOD_FILE VARCHAR2(100) := 'all_MiniLM_L12_v2.onnx';
MODNAME VARCHAR2(500);
LOCATION_URI VARCHAR2(200) := 'https://adwc4pm.objectstorage.us-ashburn-1.oci.customer-oci.com/p/eLddQappgBJ7jNi6Guz9m9LOtYe2u8LWY19GfgU8flFK4N9YgP4kTlrE9Px3pE12/n/adwc4pm/b/OML-Resources/o/';
BEGIN
DBMS_OUTPUT.PUT_LINE('ONNX model file name in Object Storage is: '||ONNX_MOD_FILE);
--------------------------------------------
-- Define a model name for the loaded model
--------------------------------------------
SELECT UPPER(REGEXP_SUBSTR(ONNX_MOD_FILE, '[^.]+')) INTO MODNAME from dual;
DBMS_OUTPUT.PUT_LINE('Model will be loaded and saved with name: '||MODNAME);
-----------------------------------------------------
-- Read the ONNX model file from Object Storage into
-- the Autonomous Database data pump directory
-----------------------------------------------------
BEGIN
DBMS_DATA_MINING.DROP_MODEL(model_name => MODNAME);
EXCEPTION WHEN OTHERS THEN NULL; END;
DBMS_CLOUD.GET_OBJECT(
credential_name => NULL,
directory_name => 'DATA_PUMP_DIR',
object_uri => LOCATION_URI||ONNX_MOD_FILE);
-----------------------------------------
-- Load the ONNX model to the database
-----------------------------------------
DBMS_VECTOR.LOAD_ONNX_MODEL(
directory => 'DATA_PUMP_DIR',
file_name => ONNX_MOD_FILE,
model_name => MODNAME);
DBMS_OUTPUT.PUT_LINE('New model successfully loaded with name: '||MODNAME);
END;Schema Creation
For the demonstration we used Oracle Globally Distributed Autonomous Database and a dataset which contains news items from BBC, publicly available in hugging face (https://huggingface.co/datasets/permutans/fineweb-bbc-news). The dataset is in parquet format which is stored in an OCI bucket. We make use of DBMS_CLOUD package to ingest data in bulk and in parallel across shards via .
We use following schema for sharded table family, the NEWS table defines the parent table and the NEWS_EMBEDDING sharded table contains the embeddings for the news text and reference the NEWS table as parent, therefore is sharded in the same way with respect to data being distributed. Here we are using a system-defined data distribution method that evenly and uniformly spreads the data and workload across shards.
ALTER SESSION ENABLE SHARD DDL;
CREATE TABLESPACE SET news_ts;
CREATE SHARDED TABLE NEWS
(
N_URL VARCHAR2(32767) NOT NULL,
N_TEXT VARCHAR2(32767) NOT NULL
)
TABLESPACE SET news_ts
PARTITION BY CONSISTENT HASH (N_URL)
PARTITIONS AUTO;
CREATE SHARDED TABLE NEWS_EMBEDDING
(
NE_URL VARCHAR2(32767) NOT NULL,
NE_EMBEDDING VECTOR NOT NULL
)
PARENT NEWS
TABLESPACE SET news_ts
PARTITION BY CONSISTENT HASH (NE_URL)
PARTITIONS AUTO;Parallel Data Ingestion
Loading large volumes of documents sequentially into the shard databases can be slow. To maximize throughput, we ingest data in bulk and in parallel across all shards. We stage the Parquet data in OCI Object Storage and create an external table to drive parallel load into the sharded tables enabling significantly higher ingestion rates.
For the external table we use DBMS_CLOUD and infer the schema automatically from parquet files in OCI bucket. We can execute the following shard SQL to load data across shards in parallel from the external tables. Data ingestion for high volumes/rate can further be optimized with parallel DML and direct path inserts.
ALTER SESSION DISABLE SHARD DDL;
ALTER SESSION ENABLE PARALLEL DML;
BEGIN
DBMS_CLOUD.CREATE_EXTERNAL_TABLE(
table_name => 'NEWS_EXT',
credential_name => 'MY_OCI_CRED',
file_uri_list => 'https://<tenancy-namespace>.objectstorage.eu-frankfurt-1.oci.customer-oci.com/n/<tenancy-namespace>/b/ds-datasets/o/hf/news/*.parquet',
format => '{"type": "parquet", "schema": "first"}'
);
END;
/
ALTER SESSION ENABLE PARALLEL DML;
INSERT /*+ APPEND PARALLEL(8) */ INTO news(n_url, n_text)
(SELECT url,text FROM news_ext WHERE SHARD_CHUNK_ID('news', url) IS NOT NULL AND text IS NOT NULL);
COMMIT;Embedding Generation and top-k Query
For the demonstration we are generating embeddings using the sentence-transformer model all_MiniLM_L12_v2 we loaded in the previous step. We can execute the following shard DMLs to generate and load vectors into the corresponding embeddings table. Both data ingestion and embedding generation for sharded database can be done in parallel across all shards for this example and users can expect a speed up of the order of the number of shards when compared to a single database. Each shard itself can make use of certain DoP(Degree of Parallelism) during the execution to further speed up ingestion and embedding generation.
ALTER SESSION ENABLE PARALLEL DML;
INSERT /*+ APPEND PARALLEL(8) */ INTO news_embedding(ne_url, ne_embedding)
(SELECT n_url,vector_embedding(all_MiniLM_L12_v2 using n_text as data) FROM news);Note: For simplicity, this demonstration generates one embedding per document and does not cover document chunking. In production, chunking may often be required to meet the context window limits for the embedding models and to improve search quality and efficiency. See the Oracle AI Database 26ai documentation on vector chunks for recommended approaches: https://docs.oracle.com/en/database/oracle/oracle-database/26/vecse/vector_chunks.html
For the canonical vector search query of finding top-K matches based on cosine distance, the query executed from catalog pushes appropriate join predicate to the shards and aggregates the results back to client. Without any index this query would need to do a full scan of embedding table for distance calculations as can be seen in the plan statistics of the query pushed to the shards from the co-ordinator SQL on catalog.
-- top-K query from catalog database
SELECT vector_distance(ne_embedding, :V, COSINE) AS score, n_text
FROM NEWS_EMBEDDING, NEWS
WHERE ne_url = n_url
ORDER BY score ASC
FETCH FIRST 50 ROWS ONLY;
Accelerating Vector Search with IVF and HNSW Indexes
Oracle AI Database 26ai supports Hierarchical Navigable Small World (HNSW) and Inverted File (IVF) indexing for vector fields, which can significantly speed up Approximate Nearest Neighbor (ANN) searches when the number of embeddings is large. Let’s use the IVF index and see how the execution plan for a top-k query changes. We will start by defining a global vector index via the catalog database. Vector indexes are well suited for sharded databases and are supported as global indexes without any limits on sharding or subpartitioning keys. Looking at the plan statistics for a shard query, both the IVF index and stop key predicates are used by the plan to efficiently fetch relevant embeddings from the shards and are combined at the catalog database.
-- Index creation on catalog database
CREATE VECTOR INDEX news_ivf ON news_embedding (ne_embedding)
ORGANIZATION NEIGHBOR PARTITIONS
WITH TARGET ACCURACY 95
DISTANCE COSINE;
-- Top-K query pushes the following SQL to shards
SELECT /*+ MONITOR */ VECTOR_DISTANCE("A2"."NE_EMBEDDING", VECTOR(:1, *, *, * /*+ USEBLOBPCW_QVCGMD */ ), COSINE),"A1"."N_TEXT"
FROM "NEWS_EMBEDDING" "A2","NEWS" "A1"
WHERE "A2"."NE_URL"="A1"."N_URL"
ORDER BY VECTOR_DISTANCE("A2"."NE_EMBEDDING", VECTOR(:1, *, *, * /*+ USEBLOBPCW_QVCGMD */ ), COSINE)
FETCH APPROX FIRST 50 ROWS ONLY /* coord_sql_id=am304nvzgurad */ 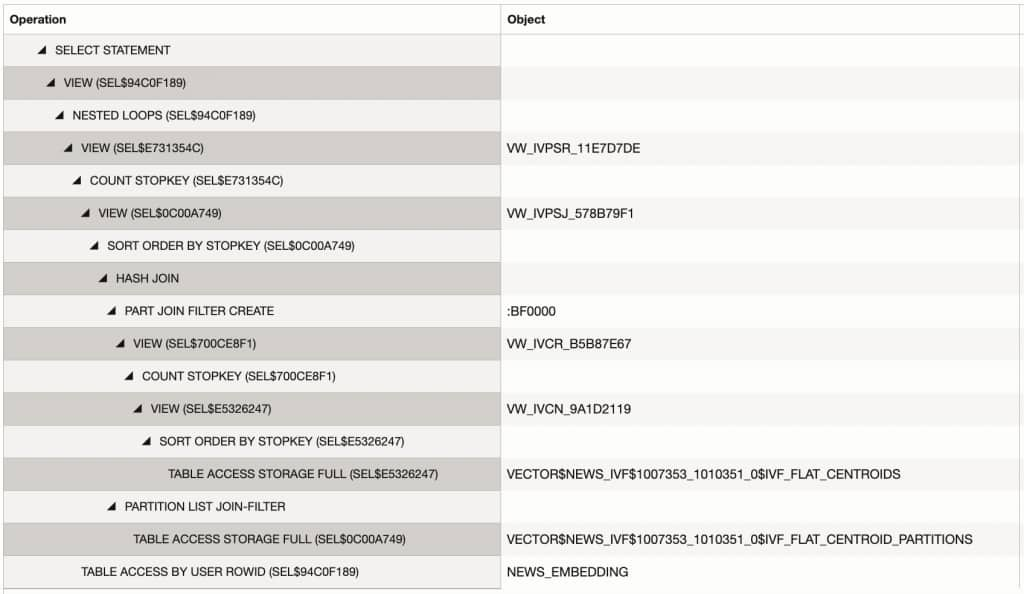
HNSW Indexing
HNSW indexes are great fit with Oracle Globally Distributed Database because the high memory footprint for HNSW can be partitioned over multiple shards. This enables the construction of a scalable, high-performance vector store that supports low-latency, high-recall similarity search at global scale. In the example below, we define an HNSW index on the embedding column and examine the query execution plan across distributed shards to evaluate performance characteristics.
-- Index creation on catalog database
CREATE VECTOR INDEX news_hnsw ON news_embedding (ne_embedding)
ORGANIZATION INMEMORY NEIGHBOR GRAPH
DISTANCE COSINE
WITH TARGET ACCURACY 95;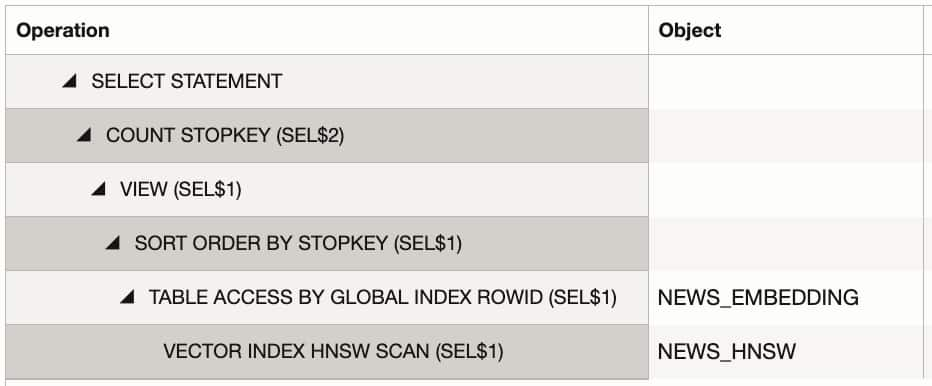
There are differences in query plans between both indexes which is due the way they work internally, the details on optimizer plans are available in documentation as well.
Summary
Oracle Globally Distributed Database offers unique capabilities to create highly scalable vector search solutions for customers. Vector data types and vector indexes are fully supported in Oracle Globally Distributed Database, enabling users to build sophisticated data models and query patterns that combine relational queries with semantic searches of vector embeddings. The database can scale up and scale out to meet a linear increase in vector searches while keeping latencies flat. To learn more about Oracle Globally Distributed Database, please visit https://www.oracle.com/in/database/distributed-database/ and explore the LiveLabs, demos, and latest documentation.


