Many organizations run critical workloads on-premises due to data sovereignty concerns, regulatory requirements, or architectural preferences. In these environments, it is essential to reduce exposure of sensitive data, especially in non-production systems. Data Masking and Subsetting provides a scalable and flexible on-premises solution to discover and replace original sensitive data with realistic, anonymized values, as shown below.
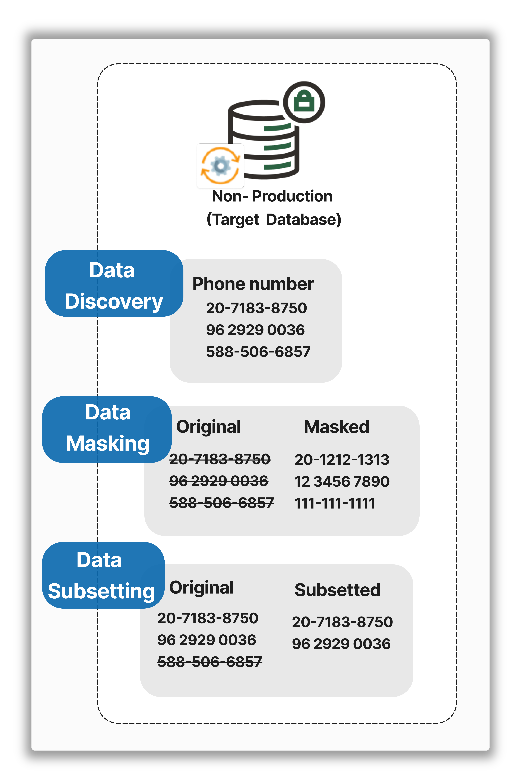
Since its release with Enterprise Manager 24ai, we have continued to enhance Data Masking and Subsetting through subsequent release updates. This blog covers post-24ai enhancements that align our on-premises solution with evolving business needs, highlighting a use case and how the updates streamline data discovery and masking in non-production environments.
Here’s what’s new:
-
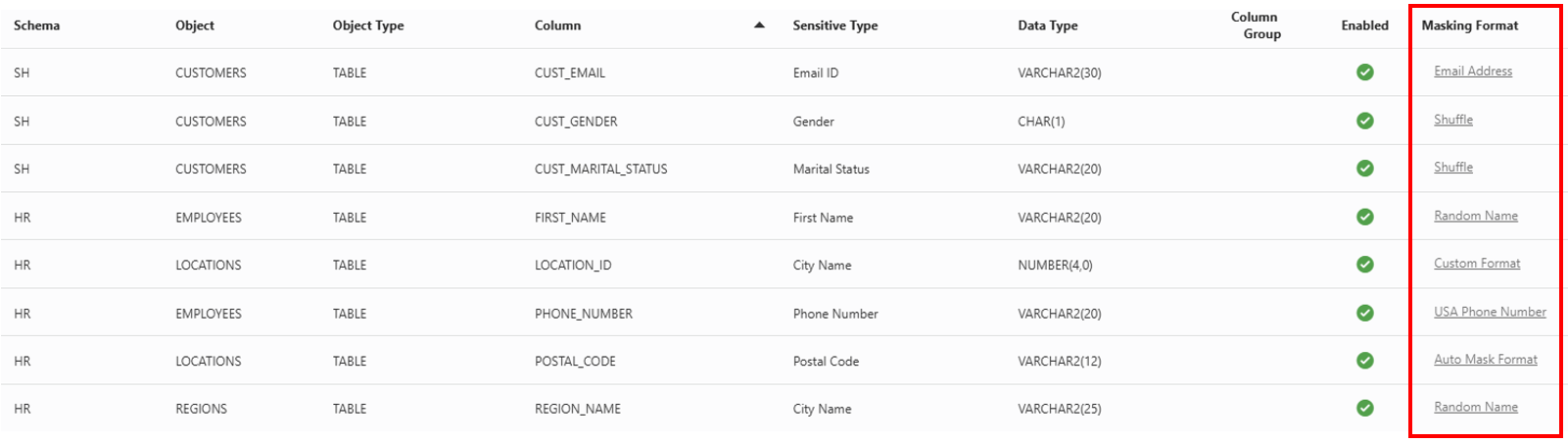
Expanded Sensitive Types library with categorization: Before searching for sensitive data, you must define sensitive data types to guide the discovery process. A broader library of sensitive types leads to better coverage and more accurate detection. With the latest update, the library has grown to 187 sensitive types, with 158 new sensitive types across different industries and geographies. The updated library includes numerous country-specific sensitive types for Australia, China, Germany, India, and more, enabling precise detection of local identifiers. With the new expanded library, customers can accelerate their discovery process with high accuracy.
In addition, these sensitive types are now organized into eight categories: Academic, Biographic, Employment, Financial, Healthcare, Identification, Information Technology, and User-defined. This structure makes it easy to find the type you need. If your sensitive type doesn’t fit any of these categories, you can create your own and assign it to the “User-defined” category. This approach simplifies scanning data across diverse business and industry contexts, including custom sensitive types.
- Expanded Masking Formats library: Once sensitive data types are discovered, masking formats define how the data would be masked. We have added 44 new masking formats, including masking formats for national identifiers (e.g., Mexico, Netherlands), leading credit-card types (Visa, Mastercard), and healthcare fields (e.g., Healthcare insurance number and provider number). Data Masking and Subsetting now offers 66 built-in formats, greatly broadening coverage for the most commonly used formats and minimizing the need for custom development.
-
Auto-assignment of Masking Formats: In large environments with thousands of columns containing sensitive data, determining how each column should be masked can be time-consuming. Earlier, customers had to manually select the masking format or type of masking (such as shuffle, encryption, etc.) for every sensitive column.
The new auto-assignment capability automatically maps the appropriate masking type and format to each sensitive column based on predefined rules. This streamlines the process, reduces manual effort, lowers the risk of human error, and makes it easier for you to apply consistent masking policies at scale.
- Simplified security configuration with least-privilege script. Granting database privileges for data discovery, masking, and subsetting used to be a manual process. You had to determine which privileges were required, often through trial and error, which could lead to over-granting (creating security risks) or under-granting (causing job failures). We now provide a ready-to-use least-privilege script tailored for each of the discovery, masking, and subsetting operations. It grants the minimal set of privileges needed, removing the guesswork, speeding up setup, and reducing security risks.
Real-world application: AI model training with masked data
A leading healthcare provider running on-premises databases is building AI models to predict which patients are most likely to be readmitted based on patients’ prior history. This demands strict data privacy controls, especially in the non-production environments used for model training, so that the recommendations cannot be linked back to identified patients. With Data Masking and Subsetting, the organization can help protect sensitive patient information without compromising data integrity and statistical distribution. Data discovery automatically flags sensitive attributes, such as patients’ personal identification details (e.g., full name, gender, phone number, address), under the Biographic category.
Auto-assigned masking formats eliminate the need for manual configuration, helping to maintain consistency and reduce setup effort. The result is a dataset that retains its statistical patterns by preserving formats, distributions, and relationships between data values. This makes it suitable for reliable model training, enabling healthcare professionals to identify high-risk patients and intervene early without compromising the privacy of prior patients.
Discovery and masking for databases in the cloud
Data Masking and Subsetting is designed for databases managed through Oracle Enterprise Manager. Organizations that prefer a cloud-native option can use Oracle Data Safe, a fully managed OCI service that offers data discovery and masking capabilities across Oracle Cloud and hybrid environments, delivering centralized security controls without infrastructure overhead.
Upgrade to Enterprise Manager 24ai Release 1 Update 4 today
Download the latest update from My Oracle Support using OMS Patch 37996845. Updating now gives you access to the latest features, improved usability, and optimal performance. Stay tuned for more exciting updates ahead!
Learn more about Data Masking and Subsetting
Visit the Data Masking and Subsetting product page to learn more about the solution. For hands-on experience, try our free, interactive Oracle Data Masking and Subsetting on EM 24ai LiveLab.
For additional learning resources:
- Previous announcement blog on Oracle Data Masking and Subsetting in the EM 24ai base release
- Oracle Data Safe product page
- Chapter 10 of Securing the Oracle Database, a Technical Primer
