We’re thrilled to announce a new release of Oracle Cloud Infrastructure (OCI) Data Integration. This release introduces code backup and versioning capabilities with the copy projects feature. We’re also launching solution templates that cut down on development time by allowing you to create templates and reuse repeatable extract, transform, load (ETL) patterns through parameterization. You can opt to create your own template or use one of OCI Data Integration’s prebuilt templates.
Cloud native, serverless Data Integration
OCI Data Integration is a cloud native, fully managed serverless ETL service on Oracle Cloud. Organizations building data lakes for Analytics and Data Science, artificial intelligence (AI) and machine learning (ML) on OCI with Object Storage, and Autonomous Data warehouses can quickly deliver insights by simplifying, automating, and accelerating the consolidation of data from multiple data silos.
Data Integration provides a graphical, no-code design interface, with interactive data preparation and profiling. It also helps data engineers design data pipelines using patterns and rules to handle schema evolution. It supports both Spark ETL and ELT push-down processing to the database. If you’re not familiar with this new service, check out this blog to find out more: What is Oracle Cloud Infrastructure Data Integration?
Data Integration is available in all OCI commercial regions and is part of OCI Integration services.
Versioning and CI/CD using copy projects
Continuous integration and deployment (CI/CD) aims to ensure that any update to the source code doesn’t generate errors, such as regressions or anomalies. One of the key pillars of CI/CD is version or source control, which is the practice of tracking and managing changes to source code over time. Source code versioning enables development teams to innovate faster and maximize productivity by helping them work faster and smarter. Versioning keeps track of modifications to the code, and if mistakes happen, developers can undo the changes and revert to the previous version of the code to help remediate the error while minimizing disruption to team members. With the latest release of OCI Data Integration service, you can now copy existing projects to the same workspace or a different workspace, with the required permissions. This key feature allows you to version, backup, and restore your source code.
The following sections describe how OCI Data Integration helps data engineers copy projects to manage design time objects changes within a project. For example, if a project uses Enterprise Resource Planning (ERP) data flows, tasks, and Human Capital Management (HCM), any changes to the design time objects within those folders trigger a copy project activity for versioning the projects for backup and restore purposes. When a new data flow or task is created or modified or a bug fix requires a code change, a new version of the project is created so that a full history of all the changes made to the ERP and HCM projects exists.
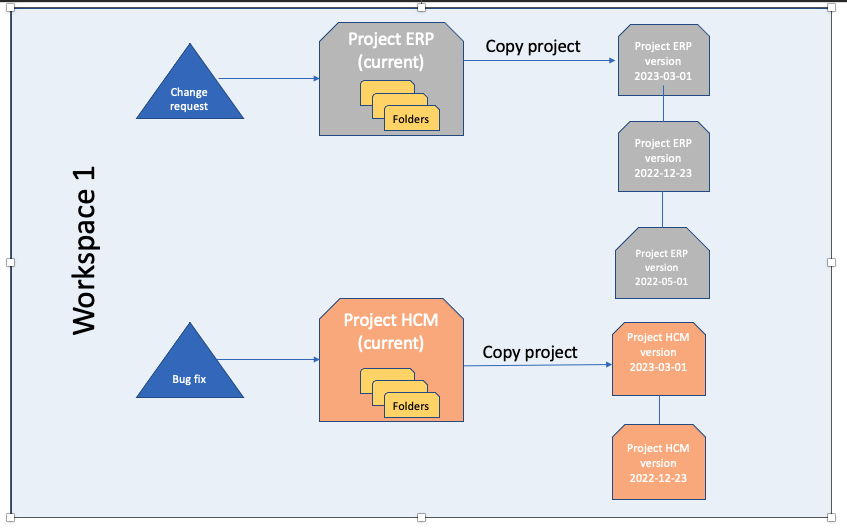
Figure 1: Copy project flow
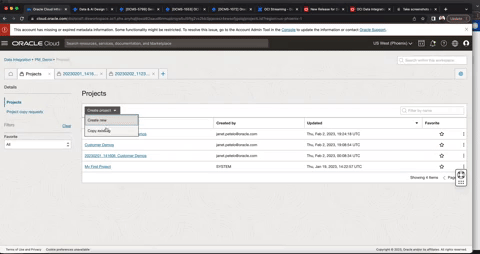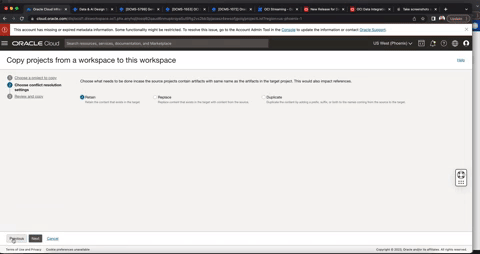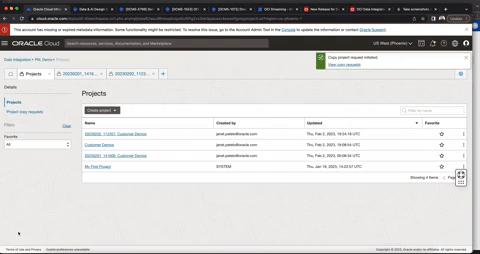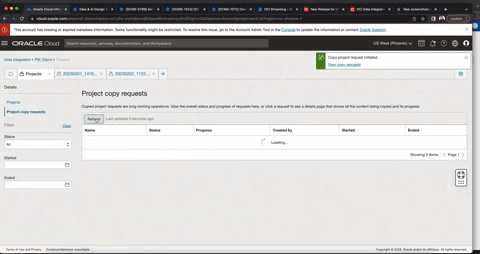
Figure 2: Copy projects
You can use copy projects to save a point in time version of the design time objects within a project. For example, if you make changes to the project “Customer_Demo” on February 27, 2023, you can use the copy project mechanism accordingly and rename the project “Customer_Demo_20230227” to denote the origin project name and the snapshot date. During the copy process, you can configure how conflicts are handled. If the source project contains artifacts with same name as the artifacts in the target project, you have the following options:
-
Retain the content that exists in the target
-
Replace the content that exists in the target with content from the source
-
Duplicate the content by adding a prefix, suffix or both to the names coming from source to target
In conjunction with application copy, this powerful new feature provides key lifecycle management features.
Maximize developer productivity with templates
To further improve developer productivity, we’re introducing solution templates in this release of OCI Data Integration.
A solution template serves as a blueprint that provides predefined entities and field mappings to enable the flow of data from source to destination. Often, the schema between the source and destination is different. The template with the predefined entity and field mappings serves as a great starting point for a data integration project. The type of transform for different ETL pipelines can differ, depending on what type of data comes from the source system and the nature of destination fact or dimension in a data warehouse.
The overall data flow of reading data from multiple sources, joining, merging, or transforming this data, and loading it in the data warehouse repository remains the same. An ETL pipeline template or data flow template that provides the most basic or most frequently used functions in this style of pipelines can become a reusable asset for an ETL team where developers can simply clone the template of the data flow or data pipeline and start customizing it instead of starting from scratch.
OCI Data Integration templates are predefined data flows, tasks, or pipelines that enable you to create a specific workflow quickly, without the need to spend time designing and developing from scratch especially. Parameterization support further enhances this process and improves reusability.
For example, say you have multiple source systems writing daily files to different OCI Object Storage buckets, and the data needs to be loaded into Oracle Autonomous Data Warehouse. You can use the solution template, “Load files from OCI Object Storage to Autonomous Data Warehouse” to create applications for each bucket containing daily files that need to be loaded into Autonomous Data Warehouse. This application creates four different tasks for the different supported file types (JSON, Parquet, CSV, and Avro). Each task is parameterized for the following specifications:
-
Source data asset
-
Source connection
-
Source compartment and bucket
-
Source file name (By precise name such as “source_file.avro” or by pattern such as “.avro”)
-
Target data aaset
-
Target connection
-
Target schema
-
Target entity
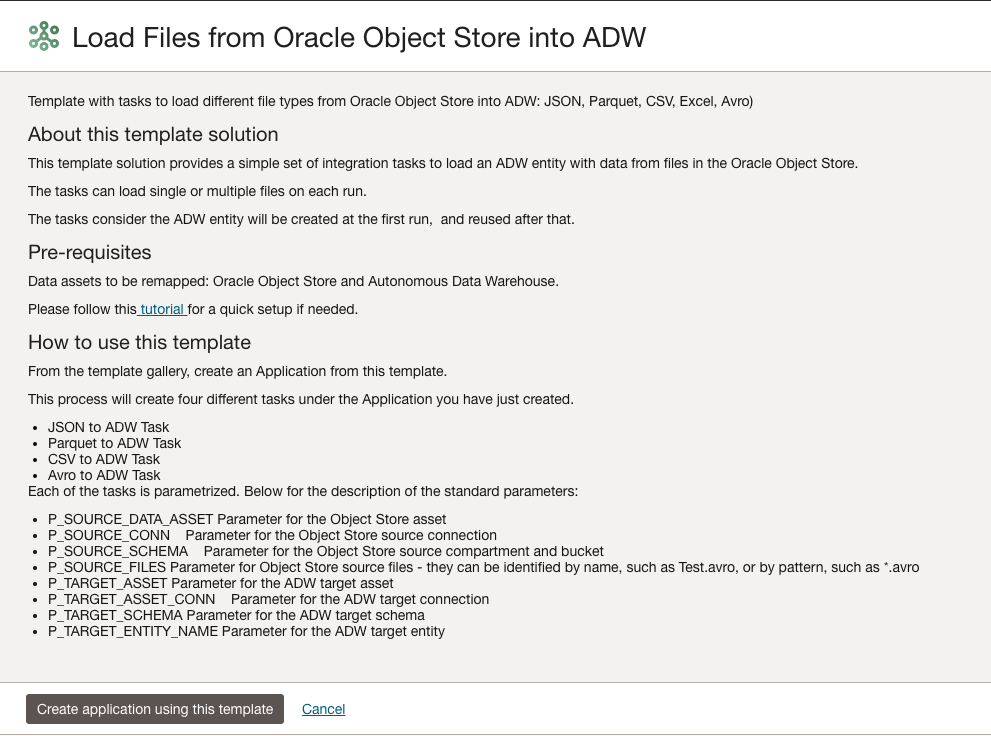
Figure 3: Load files from OCI Object Storage to Autonomous Data Warehouse template description
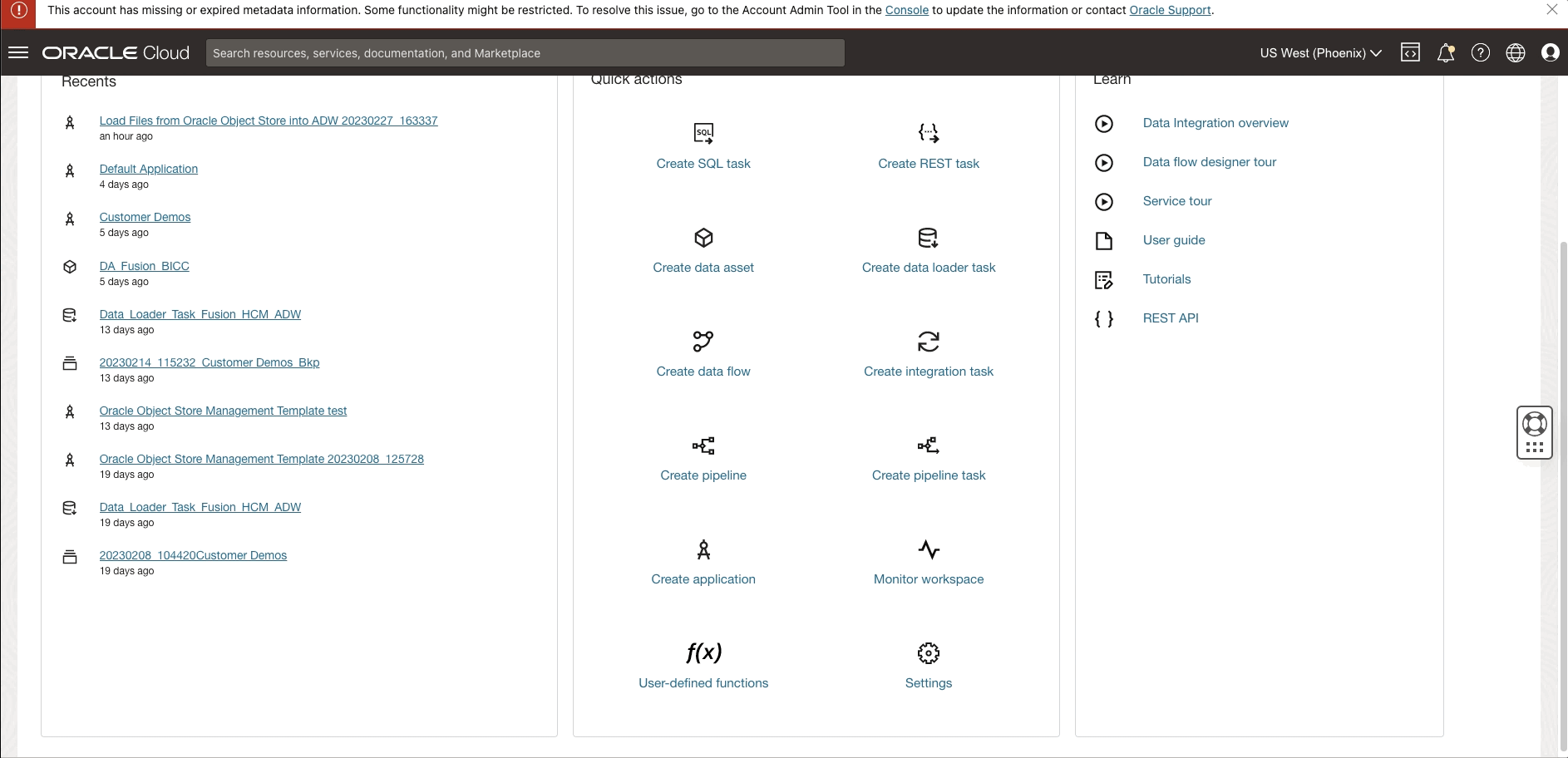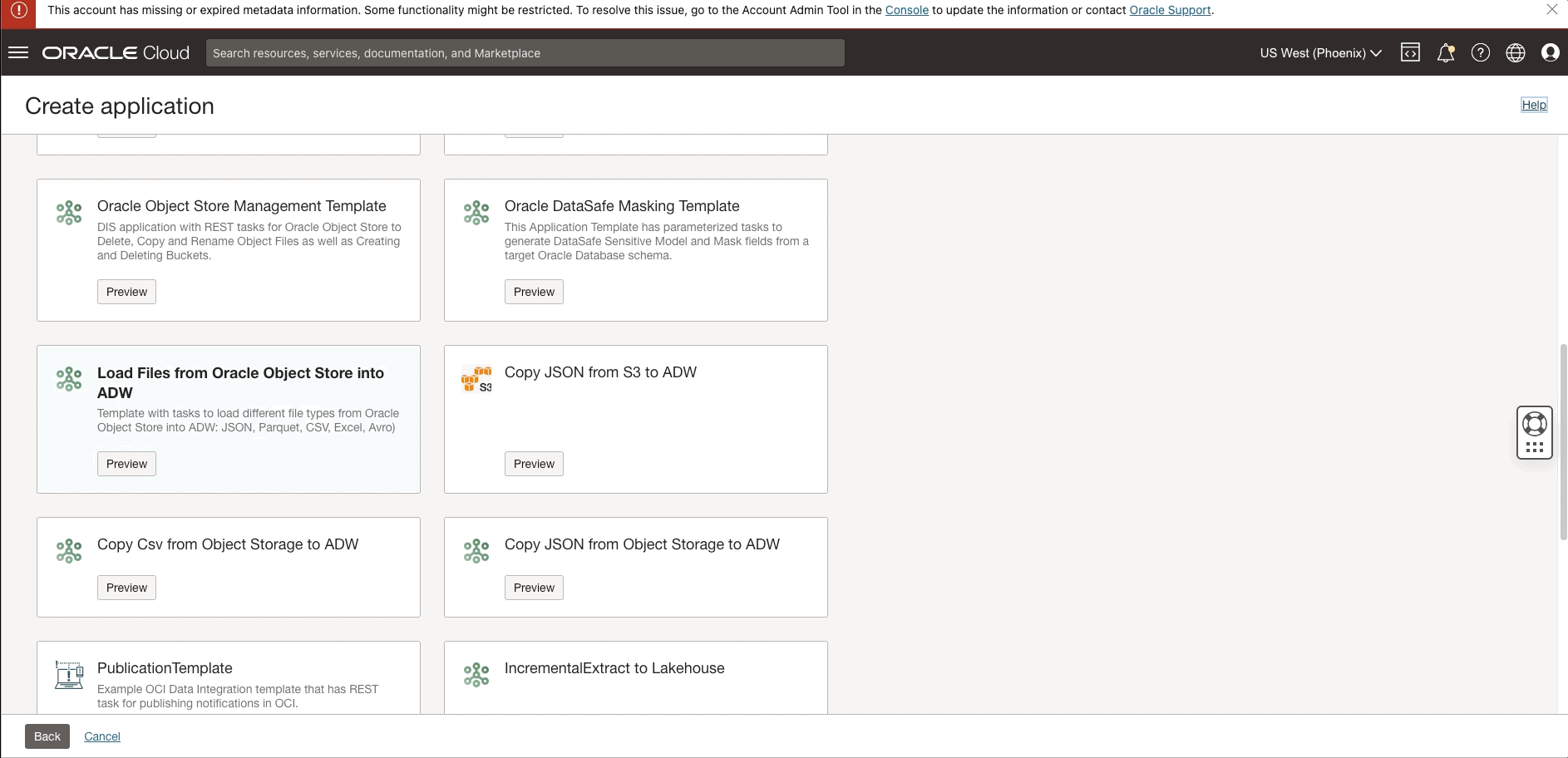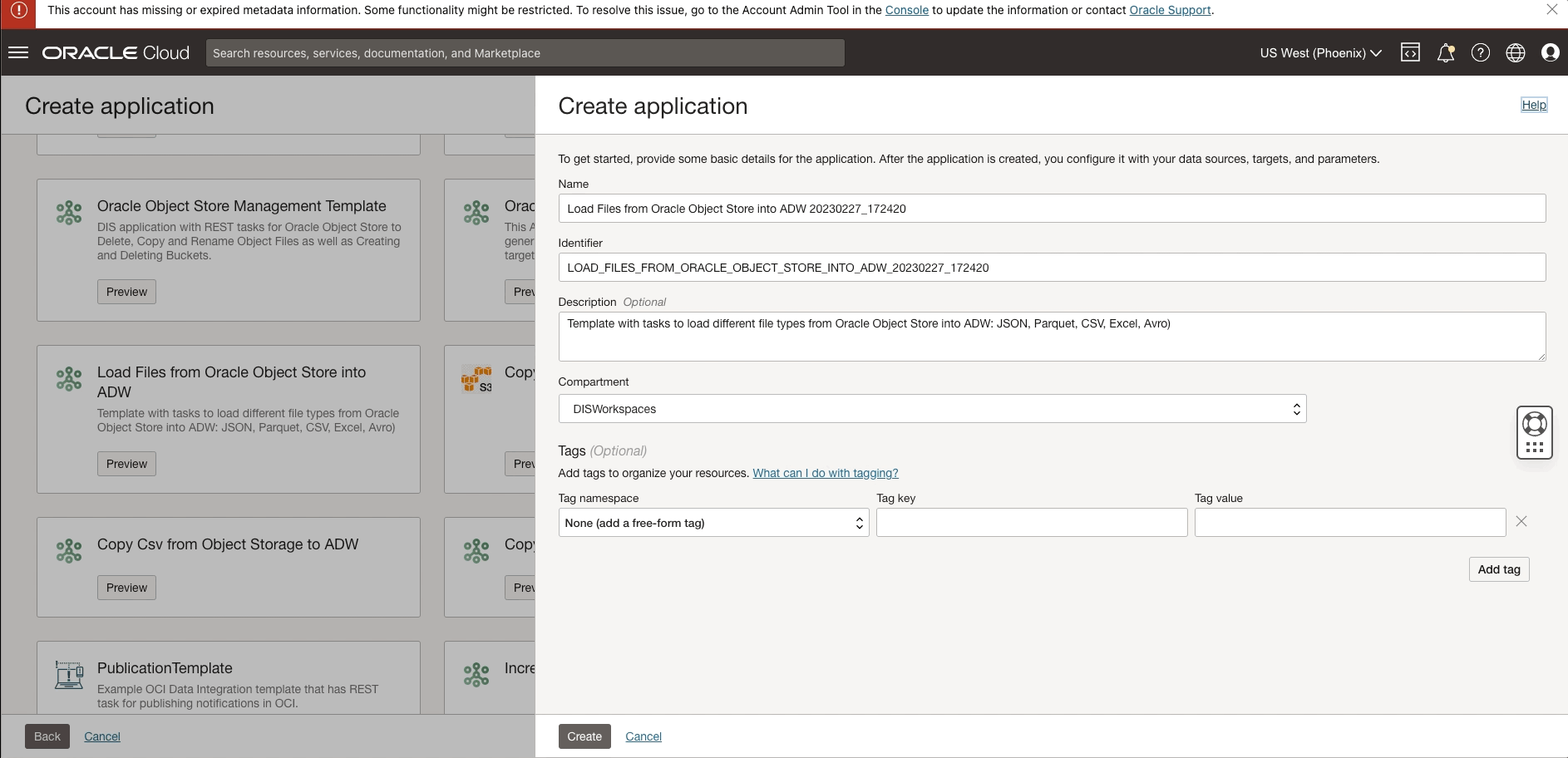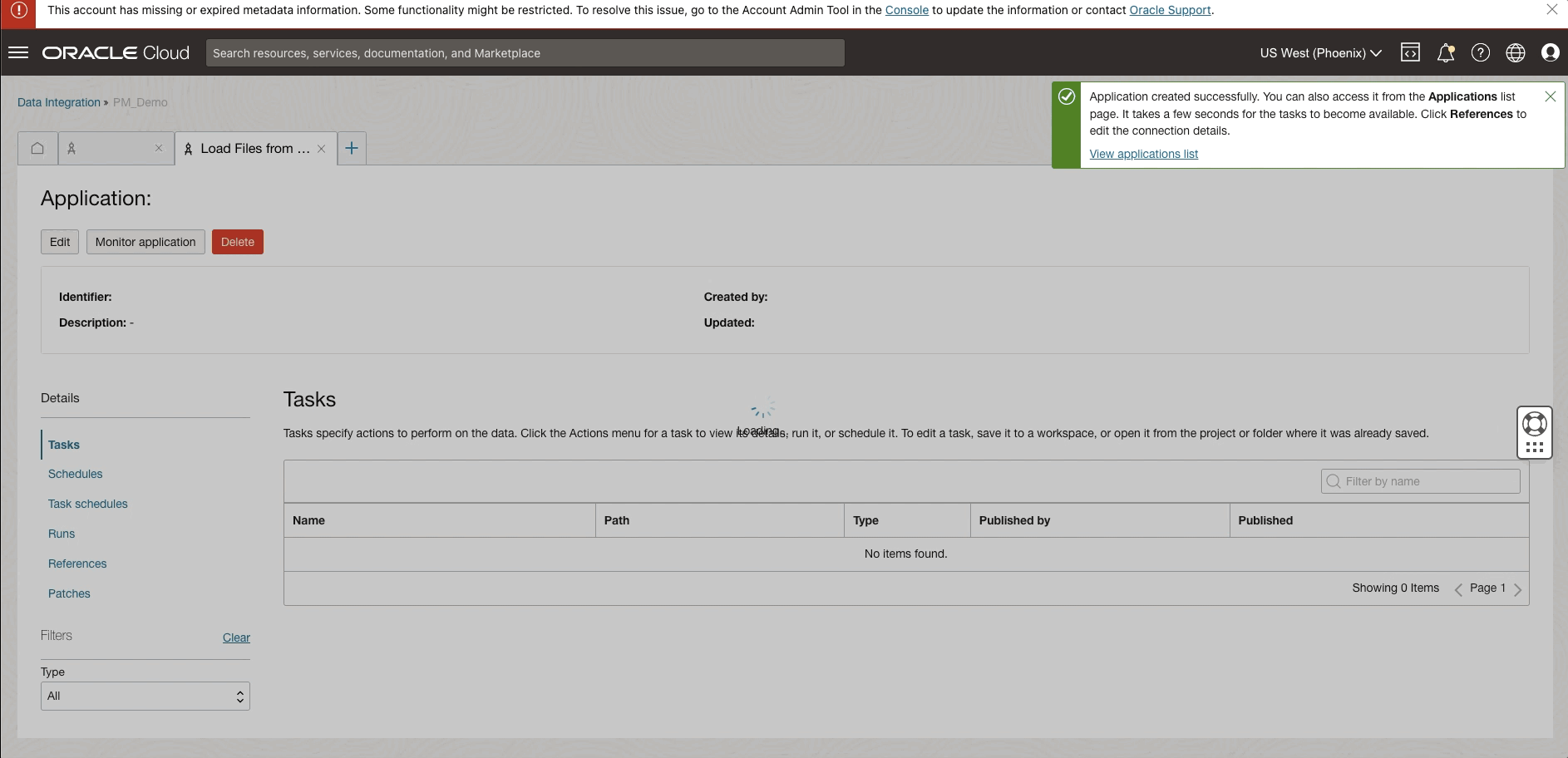
Figure 4: Creating an application template
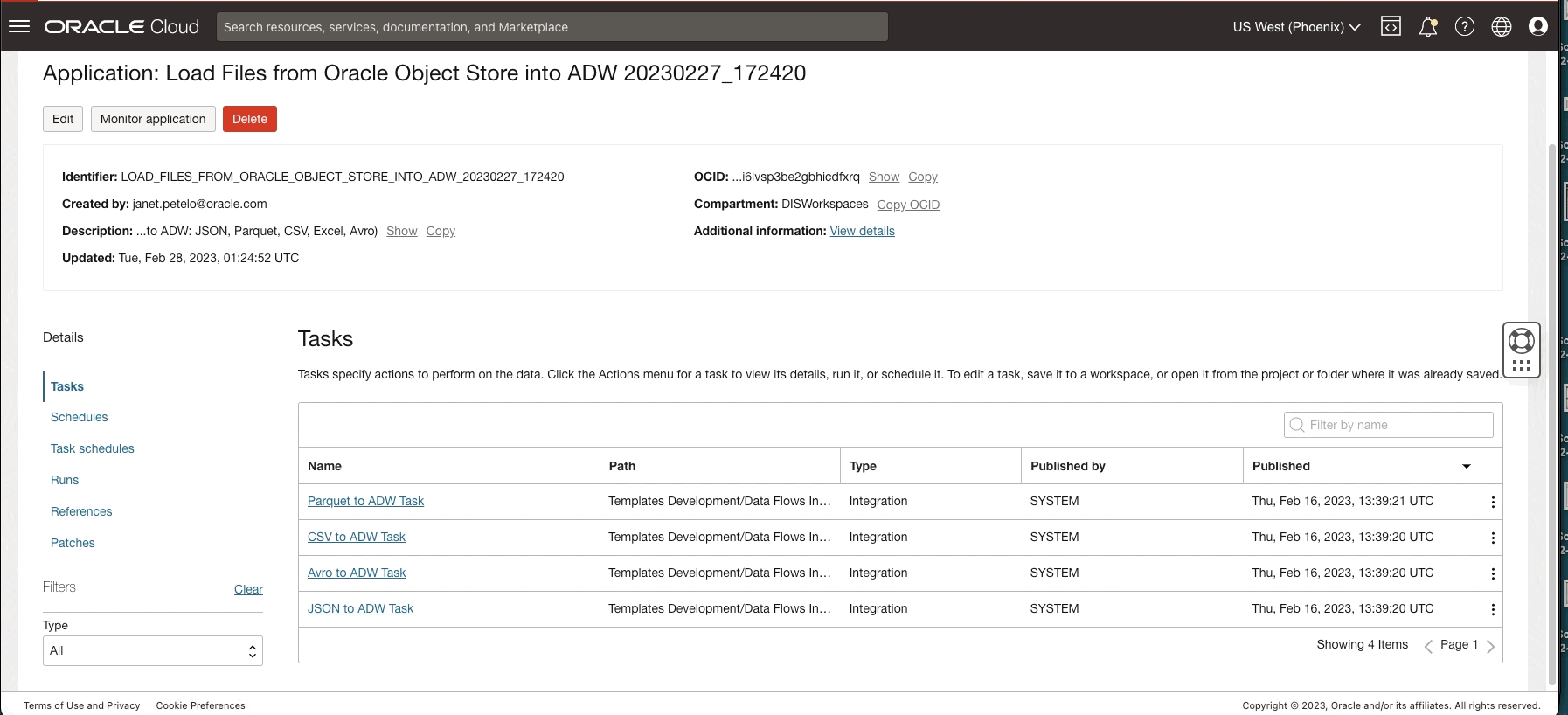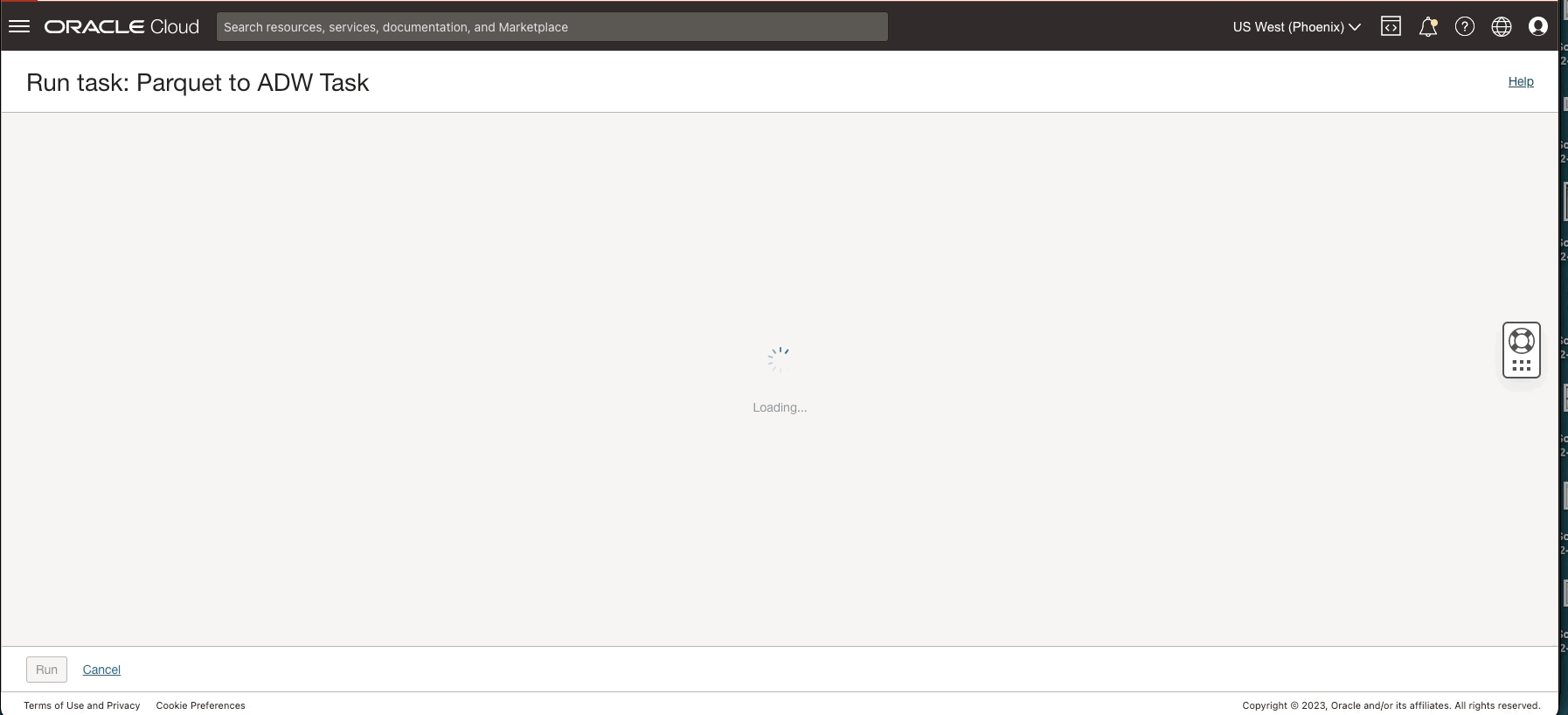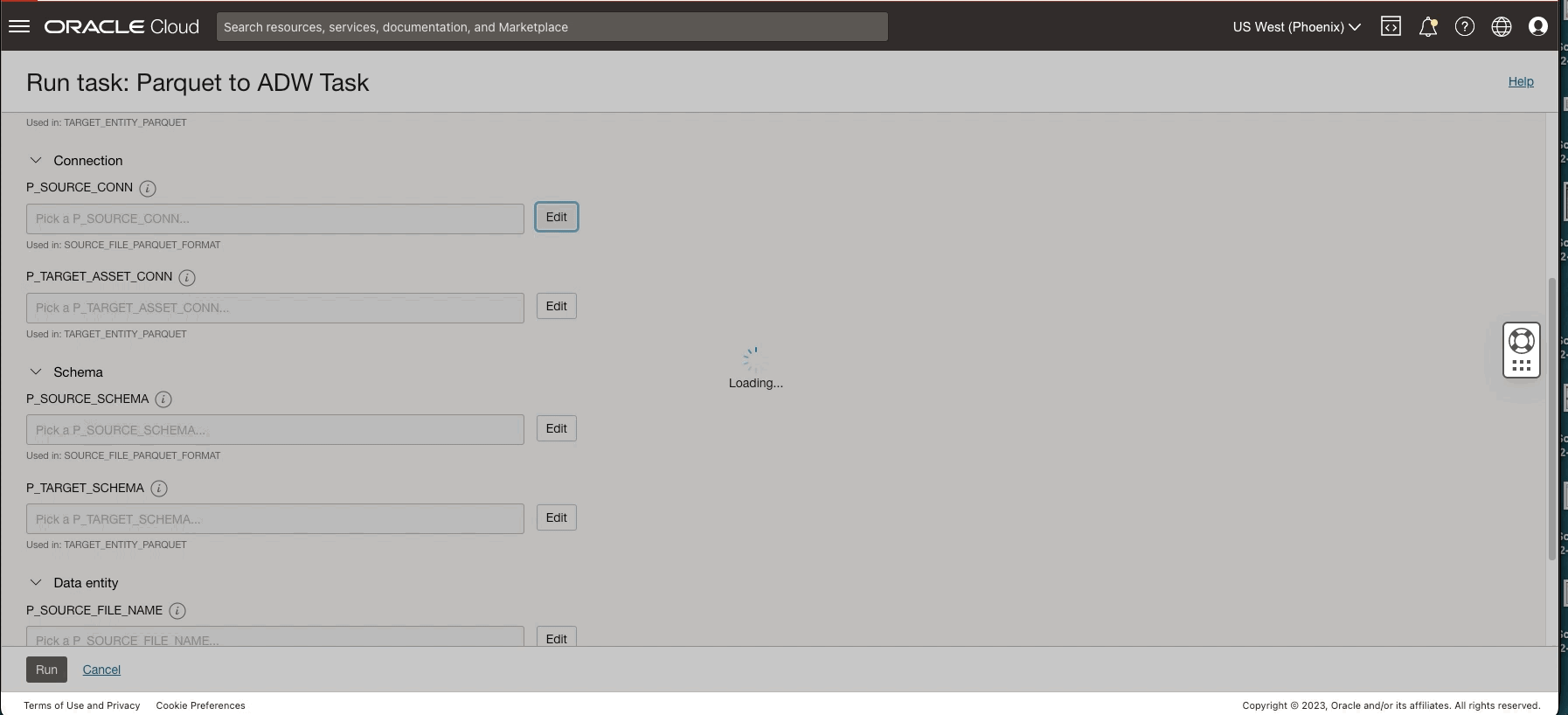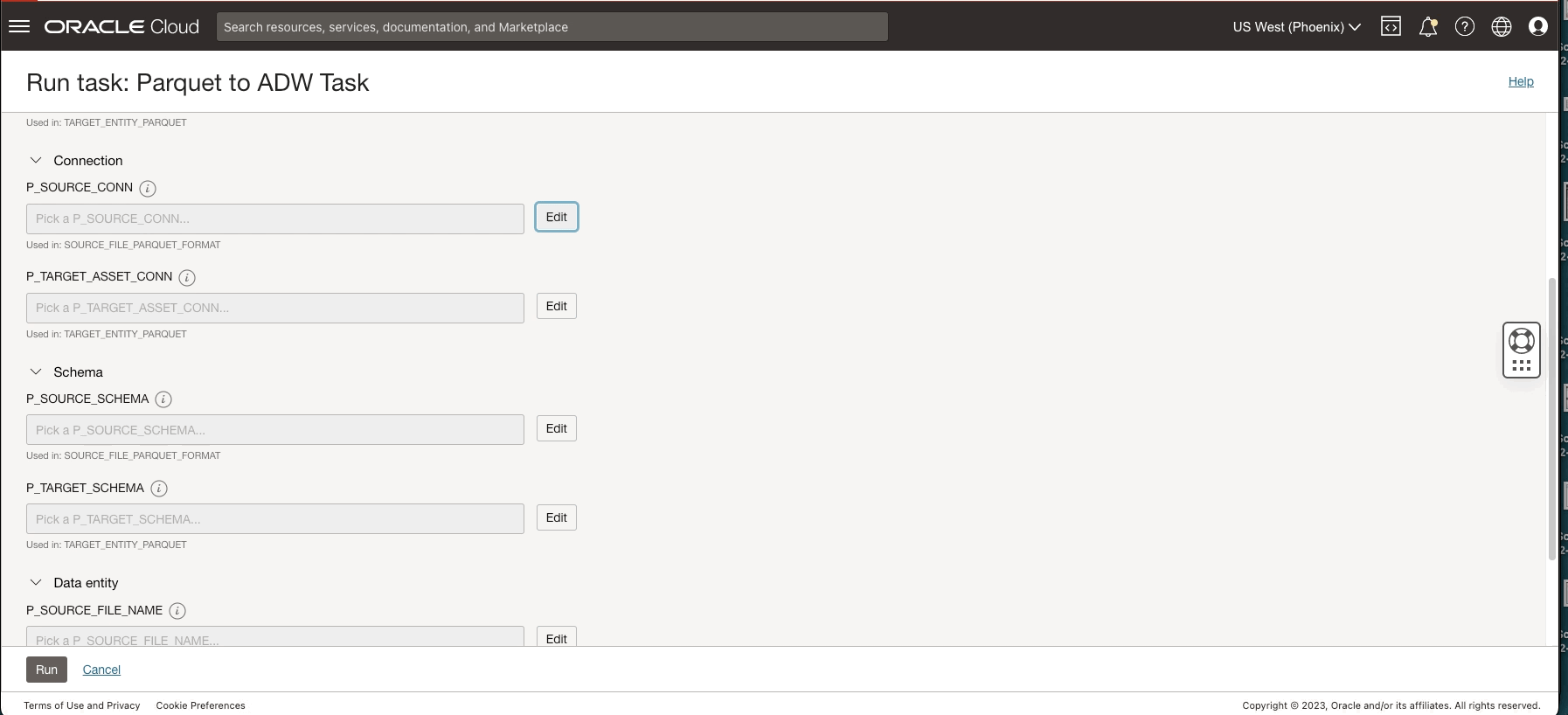
Figure 5: Configuring parameters in the application created from template
For more detailed information on templates, see the Templates blog.
Want to know more?
Organizations are embarking on their next-generation analytics journey with data lakehouses and advanced analytics with artificial intelligence and machine learning in the cloud. For this journey to succeed, they need to ingest, prepare, transform, and load their data with OCI Data Integration quickly and easily. Try it out today!
For more information, review the OCI Data Integration documentation, associated tutorials, and the OCI Data Integration blog. Check out Oracle Cloud Infrastructure Integration services for all your integration use cases.
