Migrating to a public cloud isn’t an easy task. Sometimes, we need to migrate decades worth of data in form of application logs and private documents to a cloud object storage. We often want to maintain the same directory structures that we have on our on-premises environments, while migrating to object storage for better maintainability and manageability.
What is object storage?
Oracle Cloud Infrastructure (OCI) Object Storage service is an internet-scale, high-performance storage platform that offers reliable and cost-efficient data durability. The Object Storage service can store an unlimited amount of unstructured data of any content type, including analytic data and rich content, like images and videos.
Traditional integration use cases rely heavily on file servers and SFTP access as a harbor for files. Object Storage and similar services are picking up fast in replacing them. We see more customers applying the benefits of these services for the handling of all different types of content that need to be stored and moved.
In this blog post, I show you how to upload your on-premises directories to OCI Object Storage with the help of a simple Python script that utilizes the Python SDK to upload the files, while maintaining the original directory structures.
Set up OCI CLI
Set up OCI command line interface (CLI) on your local server where these files are located. Follow the steps in the Install and Configure OCI CLI guide. When you have your CLI configured, you can test it by running the command, oci os ns get, in your terminal.
Create a bucket
Create a bucket in OCI Object Storage. We upload all our files and directories here. To create the bucket, follow the guide Create an Oracle Object Storage Bucket. I created a bucket named bucket-directory-upload where I’m uploading my directories.
Get the compartment ID and bucket name
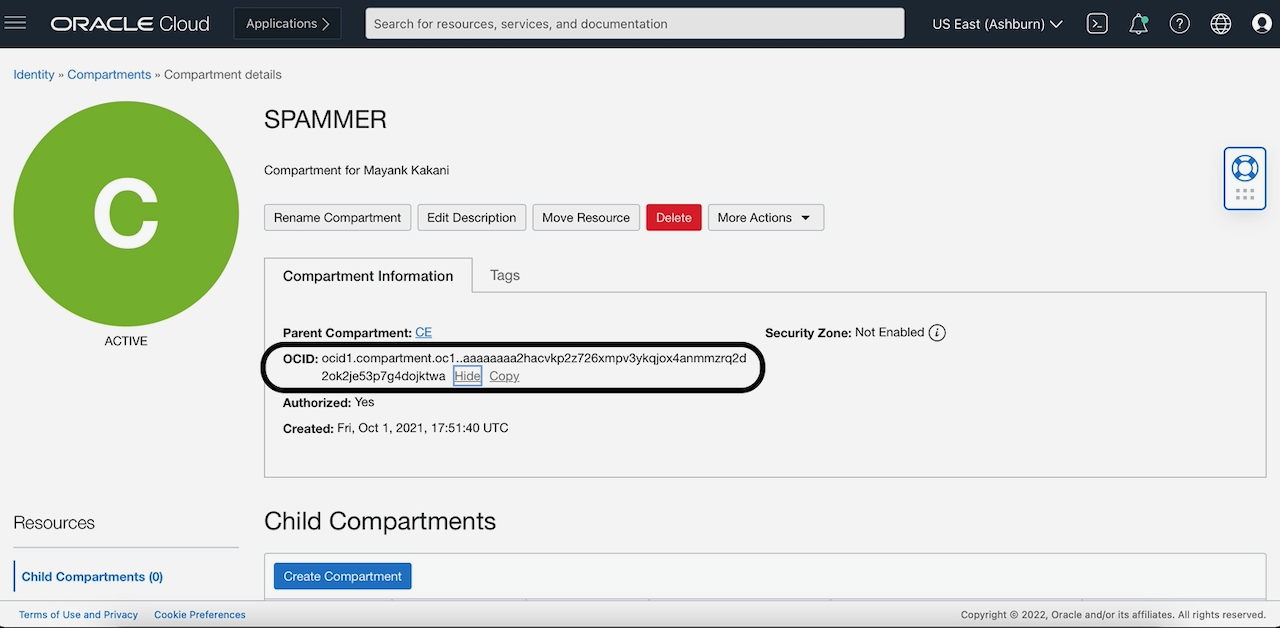
Next, we need some info on the bucket that our script is using. We need the Compartment ID where the bucket is created and the name of the bucket. If you’re new to OCI compartments and want to learn more about them, see Oracle Cloud Infrastructure Compartments. You can get the compartment ID from the bucket that you created.

In the bucket information tab, you can see the associated compartment. Clicking it brings you to the compartment details page. On this page, from the compartment details tab, you can get OCID for this compartment.
Write the script
The script we’re going to write needs the root directory that we’re going to upload as input. The script utilizes the Python SDK. Here’s the link to the Python SDK in case you are playing along at home and want more info.
To run this script, you need the following prerequisites:
-
The root directory with necessary permissions for access
-
Basic understanding of Python (I’m using Python 3.6)
-
Process and concurrency in Python
The following diagram shows how our script works:
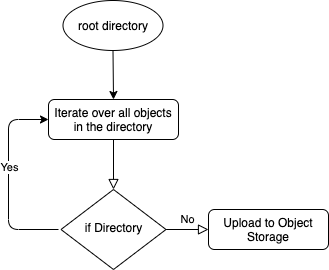
Let’s dive into the code. Our code replicates the workflow in four functions.
processDirectory
This function iterates over the directory, calls the process directory if the current item is a directory, and calls processDirectoryObjects if the current item is a file.
"""
processDirectory will process the current directory
:param path: the path of the current directory
:param object_storage_client: The object storage sdk client
:param namespace: The namespace of the bucket
:proc_list: The client list, The client iscreated with each invocation so that the separate processes do not have a reference to the same client.
"""
def processDirectory(path:Path,object_storage_client,namespace,proc_list):
if path.exists():
print("in directory ---- " + path.relative_to(p).as_posix())
for objects in path.iterdir():
if objects.is_dir():
processDirectory(objects,object_storage_client,namespace,proc_list)
else:
processDirectoryObjects(object,object_storage_client,namespace,proc_list)processDirectoryObjects
This function checks if the item with the current path is a file. If it is, it calls the createUploadProcess function.
"""
processDirectoryObjects will check if the current object path is a file or not, if yes it will create a upload process
:param object: The path of the object to upload
:param object_storage_client: The object storage sdk client
:param namespace: The namespace of the bucket
:param proc_list: The client list, The client is created with each invocation so that the separate processes do not have a reference to the same client.
"""
def processDirectoryObjects(object:Path,object_storage_client,namespace,proc_list):
if object.is_file():
createUploadProcess(object,object_storage_client,namespace,proc_list)createUploadProcess
This function gets the complete name of the item relative to the root directory, acquires the semaphore for concurrency, and creates a process. After the process is created, it adds the process to a list and starts it.
"""
createUploadProcess will create a concurrent upload process and put it in proc_list.
:param object: The path of the object to upload
:param object_storage_client: The object storage sdk client
:param namespace: The namespace of the bucket
:param proc_list:The client list, The client iscreated with each invocation so that the separate processes do not have a reference to the same client.
"""
def createUploadProcess(object:Path,object_storage_client,namespace,proc_list):
name = object.relative_to(p).as_posix()
sema.acquire()
process = Process(target=upload_to_object_storage, args= (object.as_posix(),name,object_storage_client,namespace))
proc_list.append(process)
process.start()upload_to_object_storage
This function reads the file and uploads it to Object Storage. After uploading, it releases the semaphore.
"""
upload_to_object_storage will upload a file to an object storage bucket. This function is intended to be run as a separate process. The client is created with each invocation so that the separate processes do not have a reference to the same client.
:param path: The path of the object to upload
:param name: The name of the object to upload
:param object_storage_client: The object storage sdk client
:param namespace: The namespace of the bucket
"""
def upload_to_object_storage(path:str,name:str,object_storage_client,namespace):
with open(path, "rb") as in_file:
object_storage_client.put_object(namespace,bucket_name,name,in_file)
print("Finished uploading {}".format(name))
sema.release()Let’s put all the code together with a main block in a file called uploadToOSS.py.
from array import array
from pathlib import Path
import oci
from multiprocessing import Process
from multiprocessing import Semaphore
# Number of max processes allowed at a time
concurrency= 5
sema = Semaphore(concurrency)
# The root directory path, Replace with your path
p = Path('/Users/mkakani_in/Documents/blockchain')
# The Compartment OCID
compartment_id = "ocid1.compartment.oc1..aaaaaaaa2hacvkp2z726xmpv3ykqjox4anmmzrq2d2ok2je53p7g4dojktwa"
# The Bucket name where we will upload
bucket_name = "bucket-directory-upload"
"""
upload_to_object_storage will upload a file to an object storage bucket. This function is intended to be run as a separate process. The client is created with each invocation so that the separate processes do not have a reference to the same client.
:param path: The path of the object to upload
:param name: The name of the object to upload
:param object_storage_client: The object storage sdk client
:param namespace: The namespace of the bucket
"""
def upload_to_object_storage(path:str,name:str,object_storage_client,namespace):
with open(path, "rb") as in_file:
print("Starting upload {}", format(name))
object_storage_client.put_object(namespace,bucket_name,name,in_file)
print("Finished uploading {}".format(name))
sema.release()
"""
createUploadProcess will create a concurrent upload process and put it in proc_list.
:param object: The path of the object to upload
:param object_storage_client: The object storage sdk client
:param namespace: The namespace of the bucket
:param proc_list:The client list, The client is created with each invocation so that the separate processes do not have a reference to the same client.
"""
def createUploadProcess(object:Path,object_storage_client,namespace,proc_list):
name = object.relative_to(p).as_posix()
sema.acquire()
process = Process(target=upload_to_object_storage, args=(object.as_posix(),name,object_storage_client,namespace))
proc_list.append(process)
process.start()
"""
processDirectoryObjects will check if the current object path is a file or not, if yes it will create a upload process
:param object: The path of the object to upload
:param object_storage_client: The object storage sdk client
:param namespace: The namespace of the bucket
:param proc_list: The client list, The client is created with each invocation so that the separate processes do not have a reference to the same client.
"""
def processDirectoryObjects(object:Path,object_storage_client,namespace,proc_list):
if object.is_file():
createUploadProcess(object,object_storage_client,namespace,proc_list)
"""
processDirectory will process the current directory
:param path: the path of the current directory
:param object_storage_client: The object storage sdk client
:param namespace: The namespace of the bucket
:proc_list: The client list, The client is created with each invocation so that the separate processes do not have a reference to the same client.
"""
def processDirectory(path:Path,object_storage_client,namespace,proc_list):
if path.exists():
print("in directory ---- " + path.relative_to(p).as_posix())
for objects in path.iterdir():
if objects.is_dir():
processDirectory(objects,object_storage_client,namespace,proc_list)
else:
processDirectoryObjects(objects,object_storage_client,namespace,proc_list)
if __name__ == '__main__':
config = oci.config.from_file()
object_storage_client = oci.object_storage.ObjectStorageClient(config)
namespace = object_storage_client.get_namespace().data
proc_list: array = []
sema = Semaphore(concurrency)
if p.exists() and p.is_dir():
processDirectory(p,object_storage_client,namespace,proc_list)
for job in proc_list:
job.join()
Here, we use process and semaphores for multiprocessing, which allows us to upload up to five files to Oracle Object Storage concurrently. We have defined the concurrency to five, but you can change it.
Now, we’re ready to run the script with the command, python3 uploadToOSS.py.
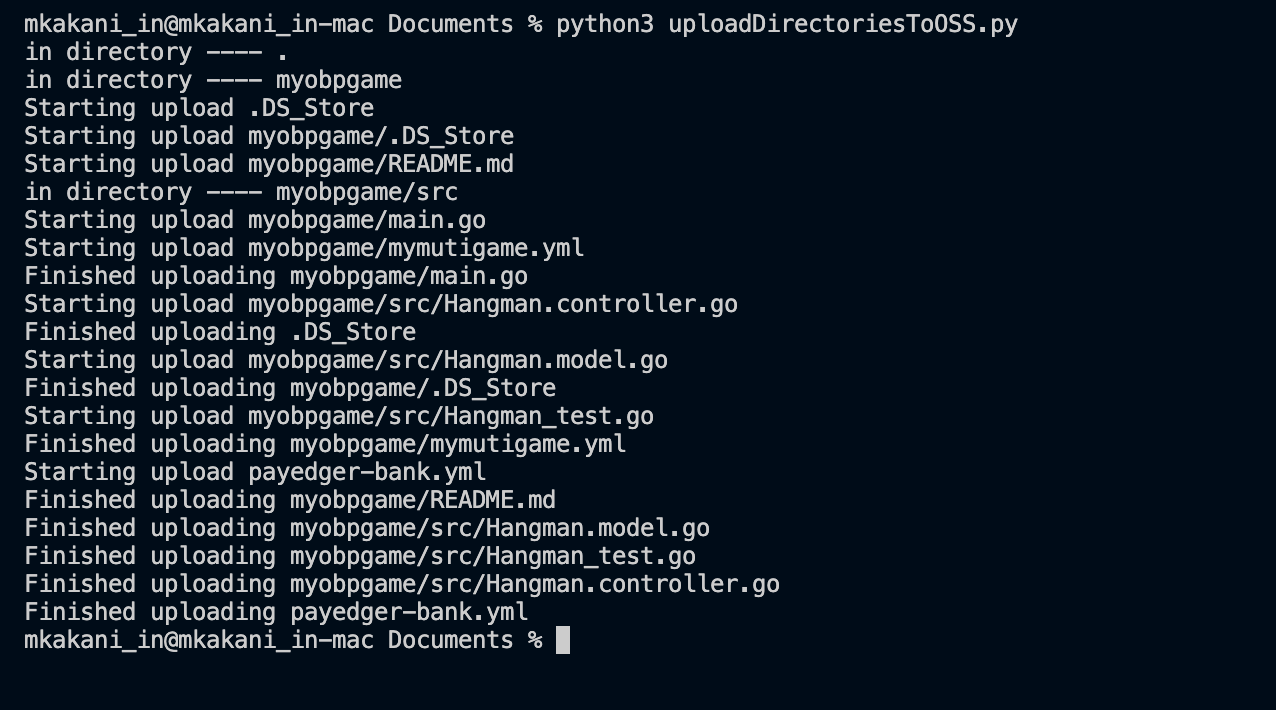
Our script was successful. Let’s check the Object Storage bucket through the Console to see if the files are uploaded.
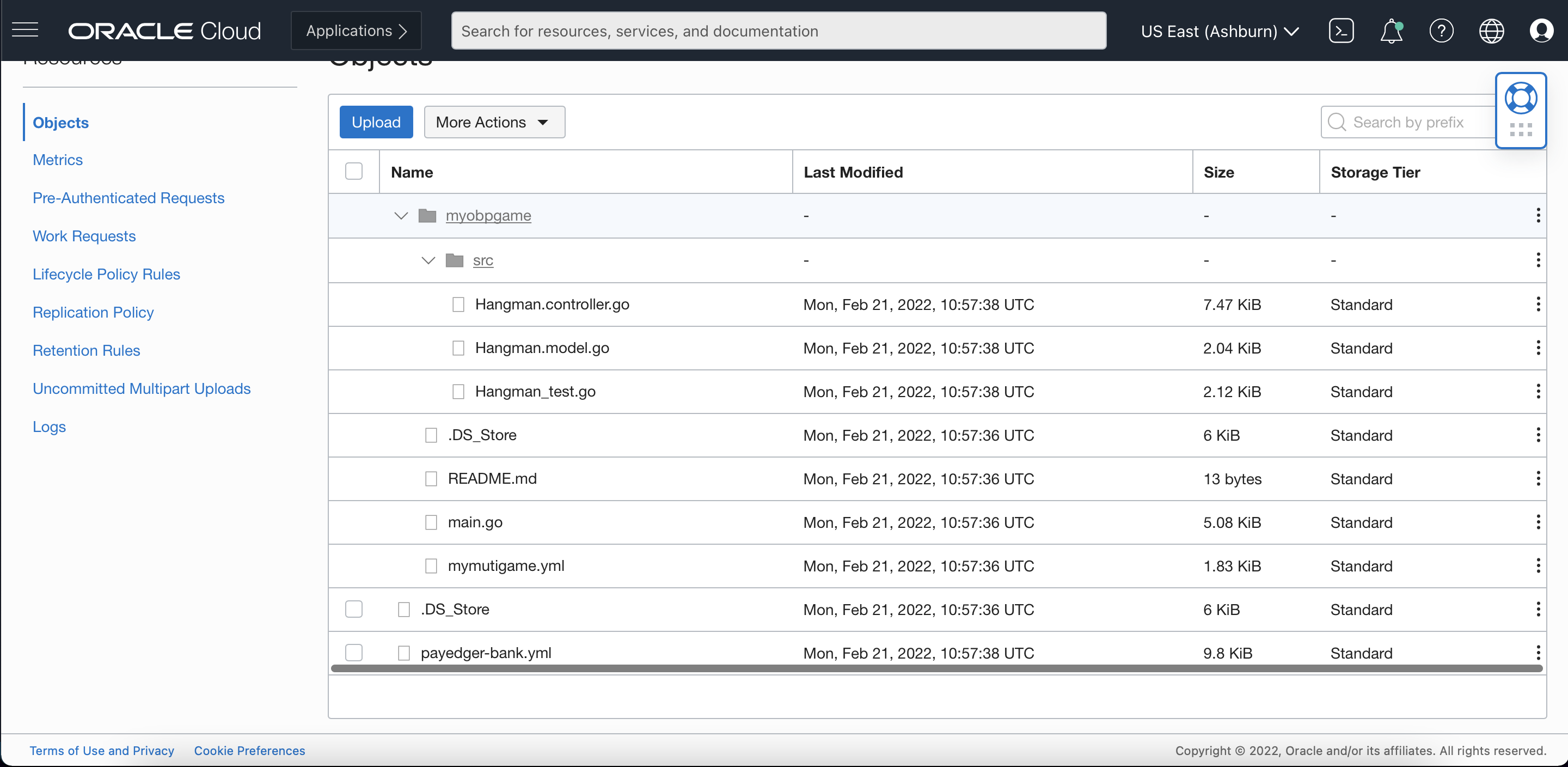
Looks like all my files are uploaded to OCI Object Storage with the same directory structure that I had on my local machine.
Tools Available?
In case your want to use pre built tools to accomplish the same results, try RCLONE.
Conclusion
In this post, we learned about Object Storage and how you can upload your on-premises data to OCI Object Storage while maintaining the original on-premises directory structures with the help of a simple Python script.
Oracle Cloud Infrastructure provides enterprise features for developers to build modern cloud applications. If you want to try out this blog for free, I recommend the Oracle Cloud Free Tier with US$300 credits for a 30-day free trial. Free Tier also includes several Always Free services that are available for an unlimited time, even after your free credits expire.