One of the solutions that many customers look for is how to move Oracle Cloud Infrastructure (OCI) Logging data to third-party tools for getting actionable insights. You might have third-party tools in place for various operational activities. We want to be compatible with those tools to enable you to quickly adopt OCI with minimal tweaks regarding rearchitecture, training, or process changes. With OCI, we want to meet you wherever you are.
In this blog, we talk about the integration of OCI with Splunk, a popular observability and security platform using OCI Streaming and Kafka Connect.
Benefits of this solution
Using Oracle Streaming, Kafka Connect, and Splunk, you get the following benefits:
-
Scalability: Overall architecture is highly scalable and based on growth of volume of data you can quickly scale.
-
Actionable logging insights: You get near-real-time logging insights about the issues and trends, which helps to take quick decisions.
-
Highly configurable: Highly configurable so that you can tweak this pipeline to meet your organization needs.
-
No coding required: This solution doesn’t require any code changes.
Prerequisites
This solution requires the following dependencies:
Architecture
OCI Streaming has built-in support for Kafka connect using Connect Harness. The Kafka Connect framework allows moving data from various systems to Kafka topics or the reverse. Kafka Connect uses sink and source connectors to move data from Kafka topics or send data to Kafka topics.
We use Splunk Connect for Kafka plugin to move data from Oracle Streaming to Splunk. This sink connector allows us to connect to a Kafka topic (In this case, Oracle Streaming) and stream data to Splunk’s http event collector.
This architecture also uses OCI Service Connector Hub to move logging data from the OCI Logging service to the OCI Streaming service.
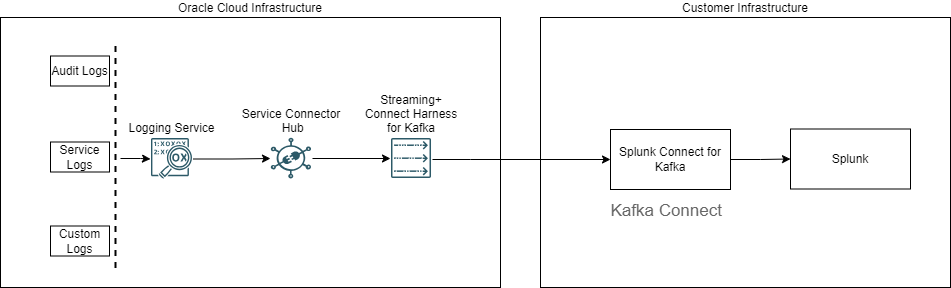
Setting up OCI Service Connector Hub
Using Service Connector Hub, we can move logging data to Streaming where Logging is the source and Oracle Streaming is the target. For more details, see Creating a Connector with a Logging Source.
Creating the Kafka Connect configuration
To create your Kafka Connect configuration, see Managing Kafka Connect Configurations.
After creation, you use the names of configuration, status, and storage topics. Save them because we use them while configuring Splunk connect for Kafka.
Setting up Splunk Connect for Kafka
Follow this developer friendly guide to install Splunk Connect for Kafka. For more information, see Install and Administer Splunk Connect for Kafka. Update with the following properties to work with OCI streaming:
#OCI Settings for OCI Stream, for this example we are using phoneix region
bootstrap.servers=cell-1.streaming.us-phoenix-1.oci.oraclecloud.com:9092
group.id=kafka-connect-splunk-hec-sink
config.storage.topic=<connect_configuration_ocid>-config
offset.storage.topic=<connect_configuration_ocid>-offset
status.storage.topic=<connect_configuration_ocid>-status
security.protocol=SASL_SSL
sasl.mechanism=PLAIN
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="<tenancy>/<user>/<stream_pool_ocid>" password="<auth_code>";
producer.buffer.memory=4096
producer.batch.size=2048
producer.sasl.mechanism=PLAIN
producer.security.protocol=SASL_SSL
producer.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="<tenancy>/<user>/<stream_pool_ocid>" password="<auth_code>";
consumer.sasl.mechanism=PLAIN
consumer.security.protocol=SASL_SSL
consumer.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="<tenancy>/<user>/<stream_pool_ocid>" password="<auth_code>";
access.control.allow.origin=*
access.control.allow.methods=GET,OPTIONS,HEAD,POST,PUT,DELETENext, you can run the command,.$KAFKA_HOME/bin/connect-distributed.sh $KAFKA_HOME/config/connect-distributed.properties, to start Kafka Connect and create the sink Splunk connector using the REST API. The topic name is the OCI stream name.
curl localhost:8083/connectors -X POST -H "Content-Type: application/json" -d '{
"name": "kafka-connect-splunk",
"config": {
"connector.class": "com.splunk.kafka.connect.SplunkSinkConnector",
"tasks.max": "3",
"splunk.indexes": "<SPLUNK_INDEXES>",
"topics":"<YOUR_TOPIC>",
"splunk.hec.uri": "<SPLUNK_HEC_URI:SPLUNK_HEC_PORT>",
"splunk.hec.token": "<YOUR_TOKEN>"
}
}'
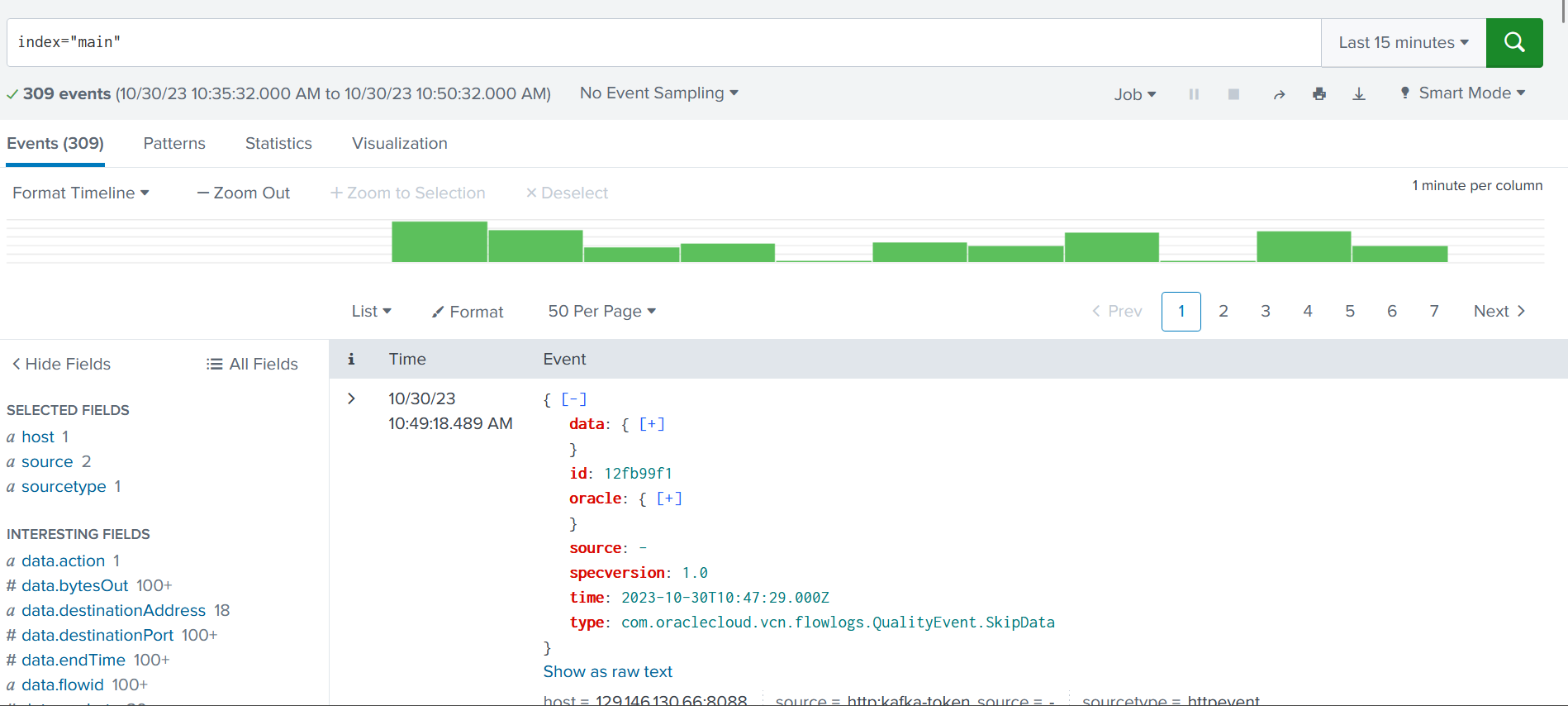
After you create the connector, you can check the log data in Splunk by searching the index (splunk.indexes in the connector configuration), which you have configured while creating the connector. This data matches the OCI logs. Check the following snapshot:
Conclusion
Setting up a log data pipeline using Oracle Streaming, Kafka Connect, and Splunk is a scalable, configurable, reliable solution for near-real-time logging insights. The Kafka Connect ecosystem has many connectors that you can use to build data pipelines. To enable this capability, Oracle Cloud Infrastructure Streaming provides the platform to run your Kafka Connect runtime.
Try out the solution yourself! Sign up for the Oracle Cloud Free Tier or sign in to your account.

